
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 소비자 profile 데이터를 분석하여 플랫폼 이탈 여부를 예측하는 모델링 실습을 해보았습니다. 어느 비즈니스든 이탈율을 막는 것은 중요한 과업 중 하나일 것입니다. 때문에 이번 미니 프로젝트도 관심을 가지며 어떤 분석 과정을 통해 이탈율을 막을 수 있을지 실습을 해보았습니다.
데이터를 보면서 '이런 변수도 수집을 하여 이탈율 예측을 하는 구나'라는 생각이 들었습니다. 해당 데이터는 핸드폰 요금제를 사용하는 유저의 이탈율을 분석하는 것이었는데, 'suv 소유 여부', '컴퓨터 소유 여부' 등등의 데이터도 처음 수집된 데이터에 포함이 되어있었습니다. 물론 이후에 EDA 과정을 거치며 feature selection을 하는 단계에서 여러 개의 변수가 필터링되었지만, 수집하는 데이터는 가설 및 풍부한(?) 상상력으로 필요하다고 싶은건 우선 다 가져오는 건가 싶기도 했습니다.
이번 글에서 중점적으로 다루어 볼 부분은 결측치 처리 (Data Imputation) 입니다.
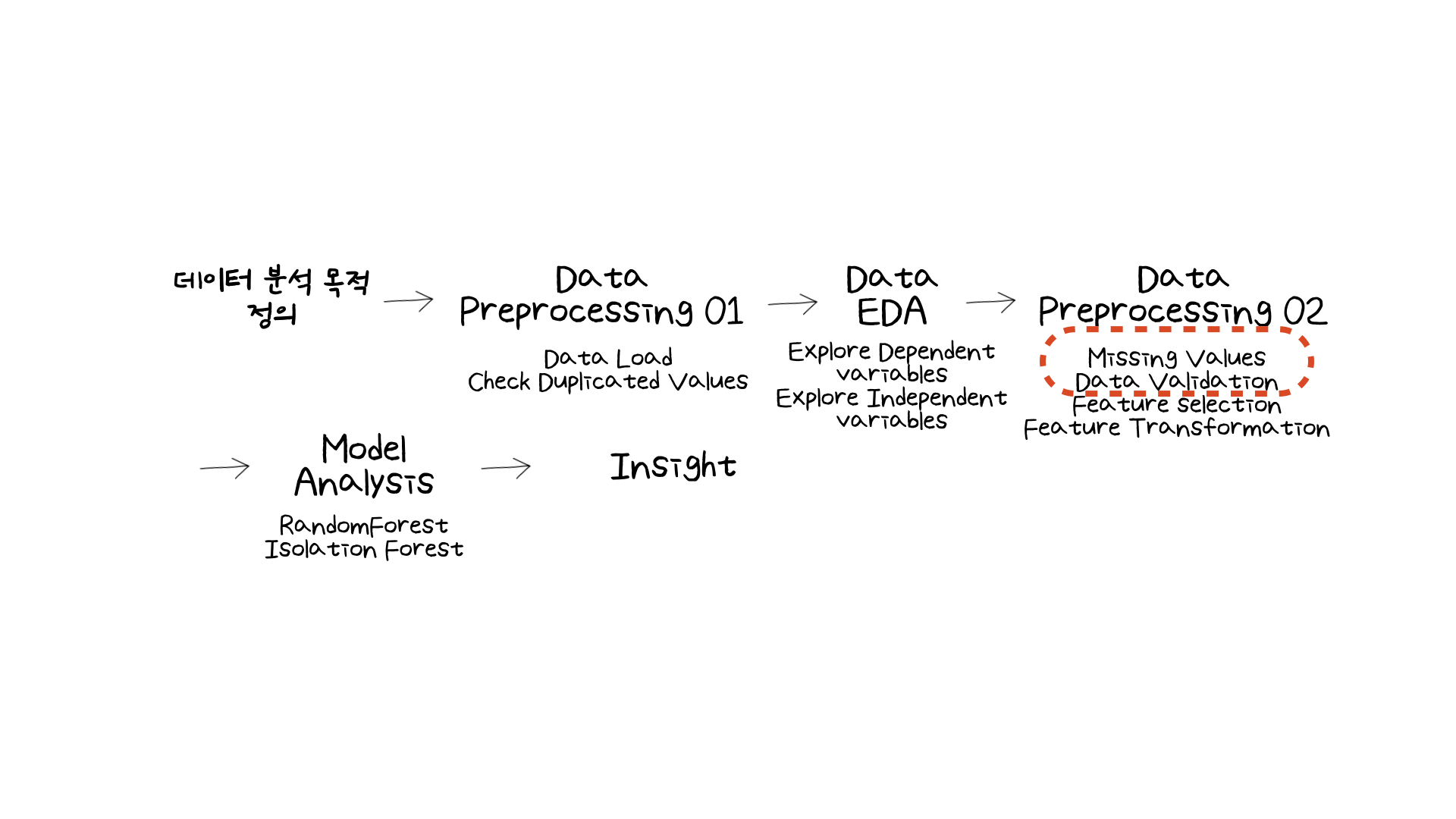
이번 미니 프로젝트 실습에서 결측치 KNNImputer를 통해 채워넣었습니다. 이전 미니 프로젝트에서는 결측치 (missing values)가 있으면 제거하거나 혹은 시계열 데이터의 경우 보간법 (interpolation)을 사용하여 채워넣었습니다. 하지만 처음으로 알고리즘으로 통해 결측치를 채울 수 있다는 것을 알게되었습니다. 그래서 결측치를 채우는 다른 방법들은 어떤게 있을까 궁금해졌습니다. 즉, 결국 모델링의 성능은 데이터의 품질에 따라 성능의 차이가 생기게 될텐데, 데이터의 품질을 높이기 위해 어떤 결측치 처리 방법을 사용해야 할지 더 알아보는 것의 필요성을 느꼈습니다.
그래서 이번 글에서는 여러 블로그 글에서 읽은 내용을 토대로 결측치를 채워넣은 방법에 대해 다루어보려고 합니다. 참조한 포스팅 글들은 맨 하단에 정리해놓도록 하겠습니다!
02. What Have I Learned?
6개의 블로그 글들을 보며 느낀 것은 결측치 처리 방법이 굉장히 많다는 것이었습니다. 단순히 평균값, 중앙값, 최빈값으로 채우는 것으로 알고 있던 저는 아직도 갈길이 멀다라는 것을 느끼는 시간이었습니다. 블로그 글들을 보며 정리한 내용은 아래와 같습니다.


위와 같이 정말 많은 내용이 있다는 것을 배울 수 있었습니다. 위 첫번째 이미지에서 밑줄이 되어있는 부분은 이번 미니 프로젝트에 해당되는 부분이었습니다. 카테고리 변수 중 결측치가 50% 이상인 데이터가 있었습니다. 하지만 결측치가 너무 많았고 범주형 변수로서 결측치를 채워주게 된다면 데이터 왜곡이 생길 수 있어 해당 컬럼을 제거해주었습니다.
이번 미니 프로젝트에서는 K-NN을 통해서 결측치를 채웠습니다. 하지만 그 이후 해당 방법들을 배웠기 때문에 이후에 결측치를 채워야 한다면 위의 여러가지 방법들을 활용하여 결측치를 채워봐야 할 것 같습니다. 결국 데이터에 맞는 방법은 그때그때마다 다르기 때문에, 한개의 결측치 처리 방법만 사용하는 것은 최대한 지양해보려고 합니다!
03. 마무리하며
참조 포스팅 (도움을 주신 저자분들에게 감사를 드립니다)
부족한 글 읽어주셔서 감사합니다:)
