
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 각색하여 복습을 위해 작성하였습니다.
01. 개요
이번 6번째 미니 프로젝트에서의 메인 takeaway는 Feature Engineering에 대한 부분이었습니다.
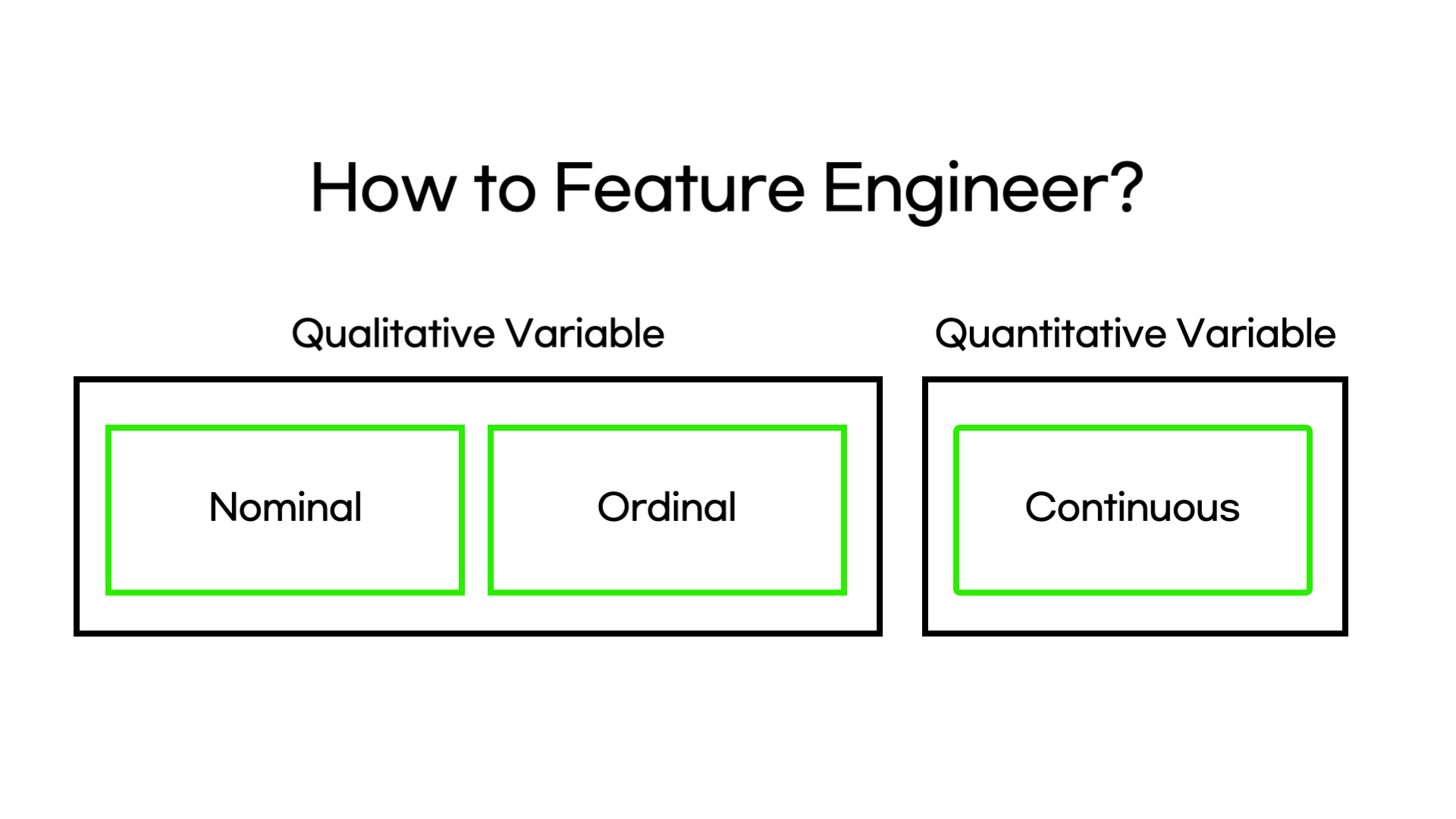
그래서 이번 글에서는 여러 feature들을 어떻게 변형했는지 소개해드리고자 합니다.
02. 미니 프로젝트 진행과정
Feature Engineering을 어떻게 했는지 소개해드리기에 앞서, 이번 미니 프로젝트는 전체적으로 어떻게 진행했는지 소개해드리겠습니다.
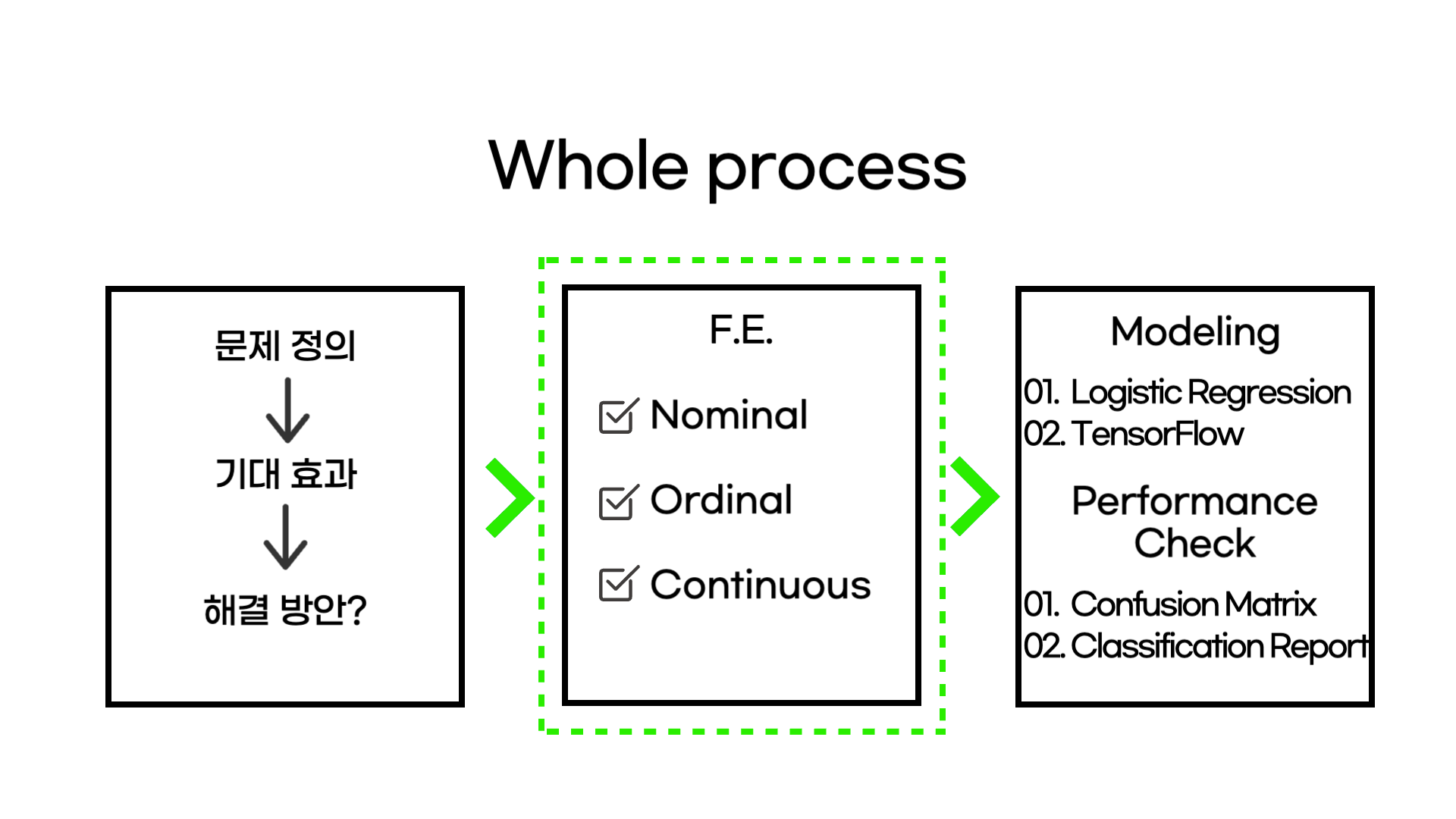
첫번째로 문제 해결 프로세스를 정의하여, 문제 정의를 하였습니다. 즉, 유기된 동물들을 구조하여 새로운 가족을 찾아주고자 하는데 어떠한 특성을 가진 동물들이 입양이 잘 되는지 분석하고자 하는 것입니다. 기대 효과로는 통제 가능한 변수 (유기동물 사진 수)와 통제 불가능한 변수 분석을 통해 더 많은 유기동물 빠르게 새로운 가족을 찾을 수 있도록 도와주는 것입니다. 해결 방안으로는 수집된 데이터 변형 후 모델링을 통한 유기동물 입양 분석입니다.
두번째로는, Feature engineering을 통해 데이터를 모델링에 활용할 수 있도록 변형을 해주었습니다. 이번 글의 메인으로서 명목형 변수, 순서형 변수, 연속형 변수를 어떻게 변형했는지 소개해드리고자 합니다.
마지막으로 두가지 모델을 통해 모델링을 진행하고 성능을 확인하며 애완 동물 입양 가능 확률을 측정하였습니다. (binary classification으로 진행했습니다)
03. Feature Engineering
그러면 이번 미니 프로젝트를 진행하며 Feature Engineering을 어떻게 했는지 소개해드리겠습니다.
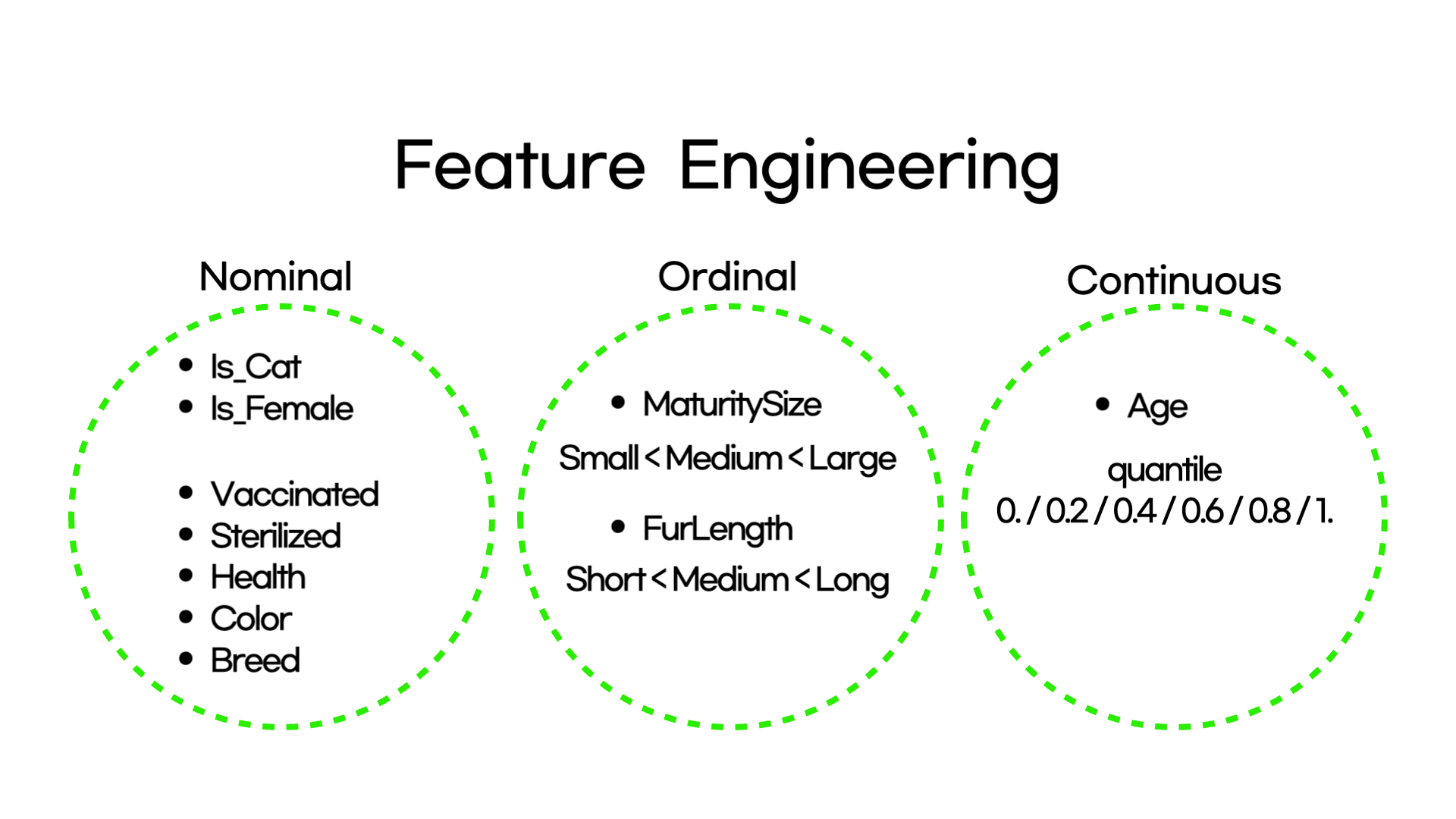
03-01. Nominal Variable
명목 변수의 경우 두가지 종류가 있었습니다.
첫번째는 'Is_Cat'과 'Is_Female' 두가지가 있는데 두 변수의 경우 개인지 고양이인지, 남성인지 여성인지를 구분해주는 변수였습니다. 그래서 'Is_Cat'의 경우 고양이이면 1, 개이면 0으로 값을 변경하였고 'Is_Female'의 경우 여성이면 1, 남성이면 0으로 값을 변형했습니다.
두번째로 'Vaccinated' (백신접종 여부), 'Sterilized' (중성화 여부), 'Health' (건강 상태), 'Color' (동물 색깔), 'Breed' (품종) 변수들을 숫자형으로 데이터로 변환했습니다. 각각 아래와 같은 방식으로 변형을 했습니다.
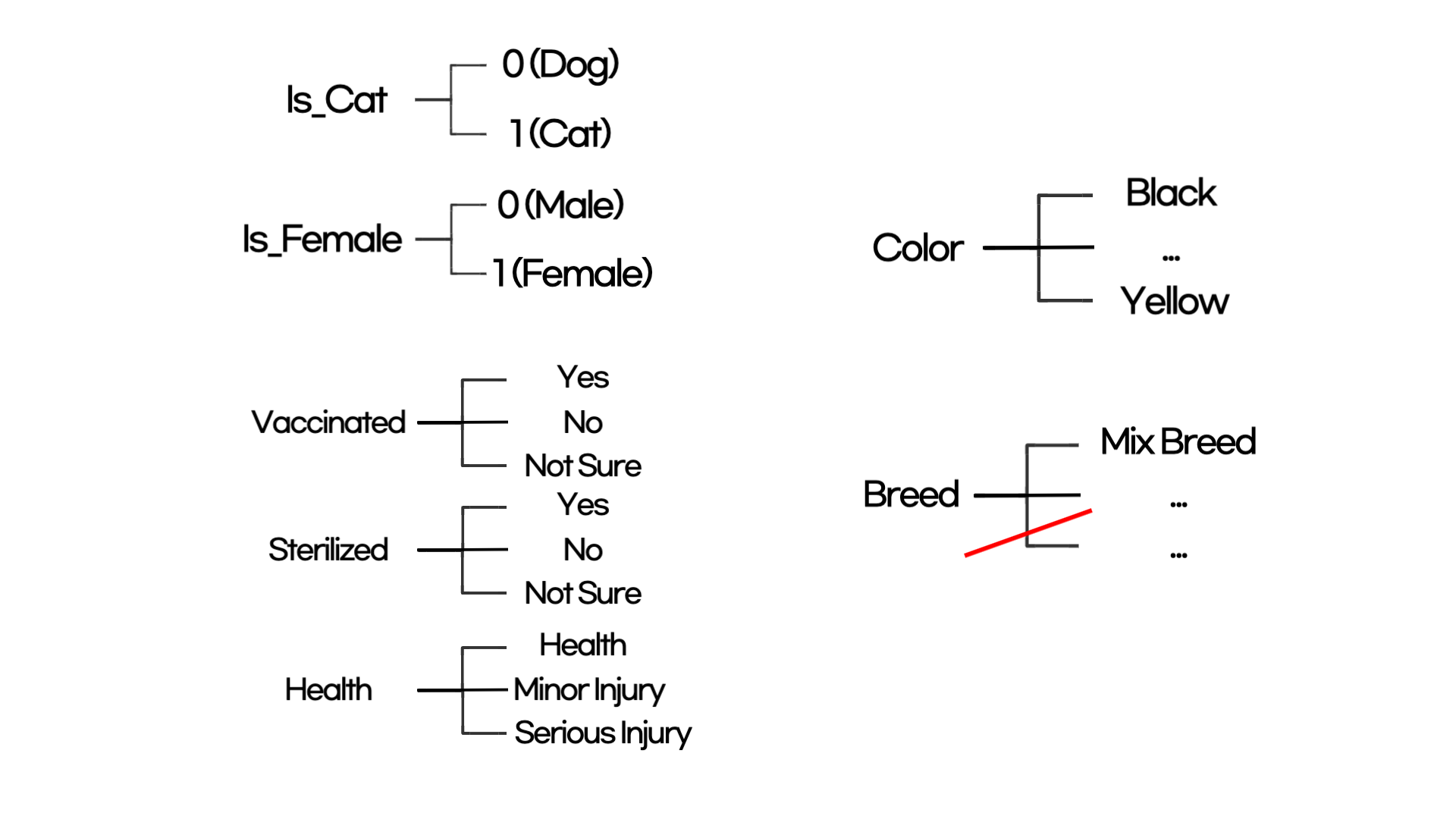
- 'Vaccinated'
- 백신접종 여부의 경우 ['Yes', 'No'] 가 아닌 ['Yes', 'No', 'Not Sure']로 구분이 되어있었습니다.
- 때문에 첫번째 경우와 같이 0, 1로 구분하는 것이 아니라 pandas의 get_dummies를 활용하여 원핫 인코딩을 진행했습니다.
- 'Sterilized'
- 중성화 여부의 경우도 ['No', 'Yes', 'Not Sure'] 3가지로 나누어져 있어 pandas의 get_dummies를 활용하여 원핫 인코딩을 진행했습니다.
- 'Health'
- 건강 상태도 마찬가지로 ['Healthy', 'Minor Injury', 'Serious Injury'] 3가지로 나누어져 있어 pandas의 get_dummies를 활용하여 원핫 인코딩을 진행했습니다.
- 'Color'
- 색깔의 경우 7가지의 색깔이 있었습니다.
- 그래서 동일하게 원핫 인코딩을 진행했습니다.
- 'Breed'
- 품종의 경우 166가지의 경우가 있었습니다.
- 모든 품종을 원핫 인코딩을 하는 경우에는 피처의 수가 너무 늘어나기 때문에, value_counts()를 통해 상위 12개의 품종을 제외한 나머지 품종은 'Other'로 처리했습니다.
- 그렇게 해서 13가지 품종으로 원핫 인코딩을 진행했습니다.
03-02. Ordinal Variable
데이터 셋에는 2개의 순서형 변수가 있었습니다.
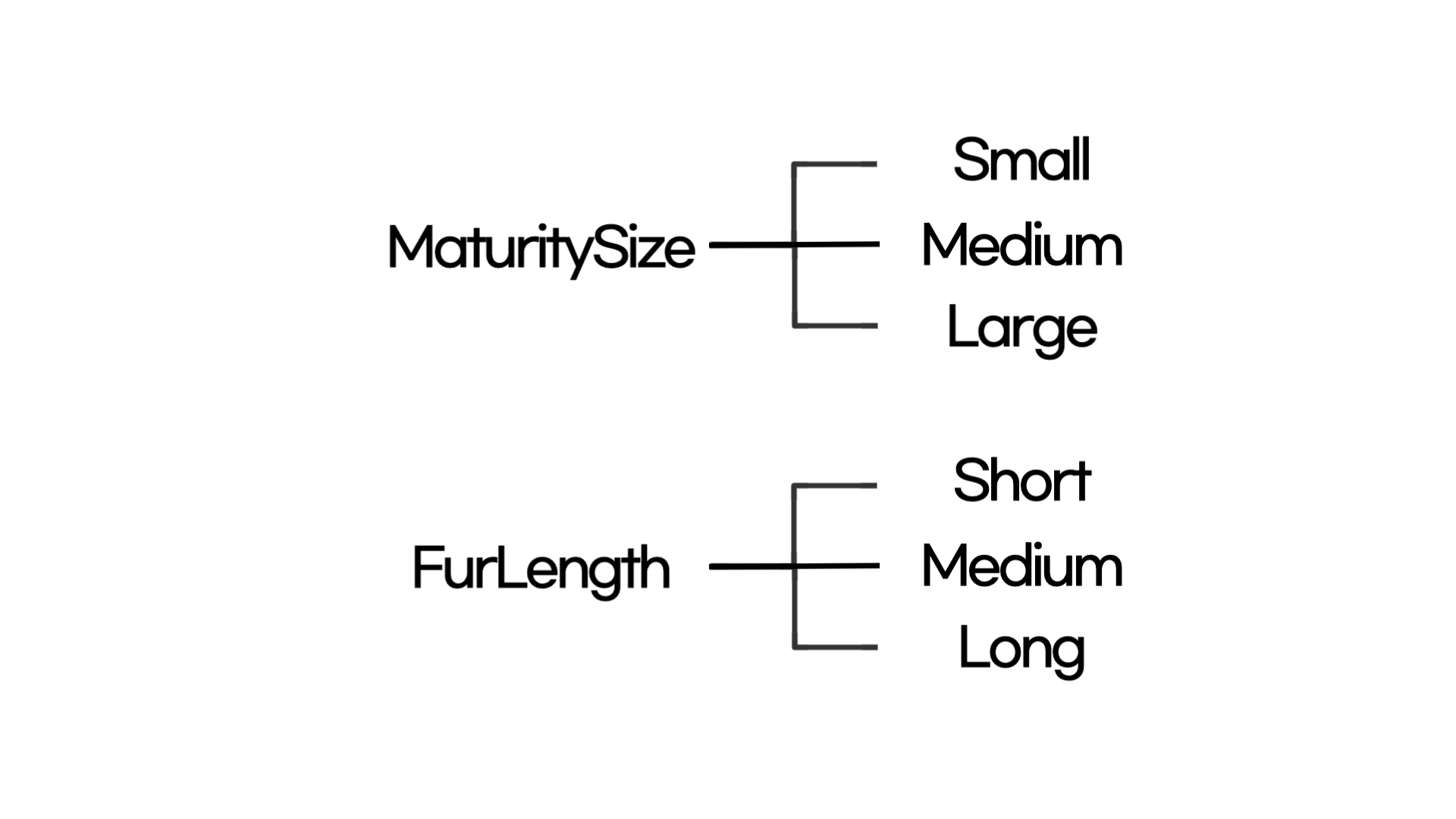
첫번째로는 'MaturitySize' (성장 수준) Feature가 'Small < Medium < Large'순으로 카테고리를 이루고 있었습니다. 그래서 먼저 pandas의 pandas.api.types.CategoricalDtype을 사용하여 먼저 해당 Feature를 범주형 변수로 변경해주었습니다. 그 다음 동일하게 pandas의 get_dummies를 활용하여 원핫 인코딩을 진행했습니다.
두번째 변수 'FurLength' (털 길이) 도 비슷하게 'Short < Medium < Long'으로 되어있어 'MaturitySize' 변수와 동일하게 진행했습니다.
03-03. Continuous Variable
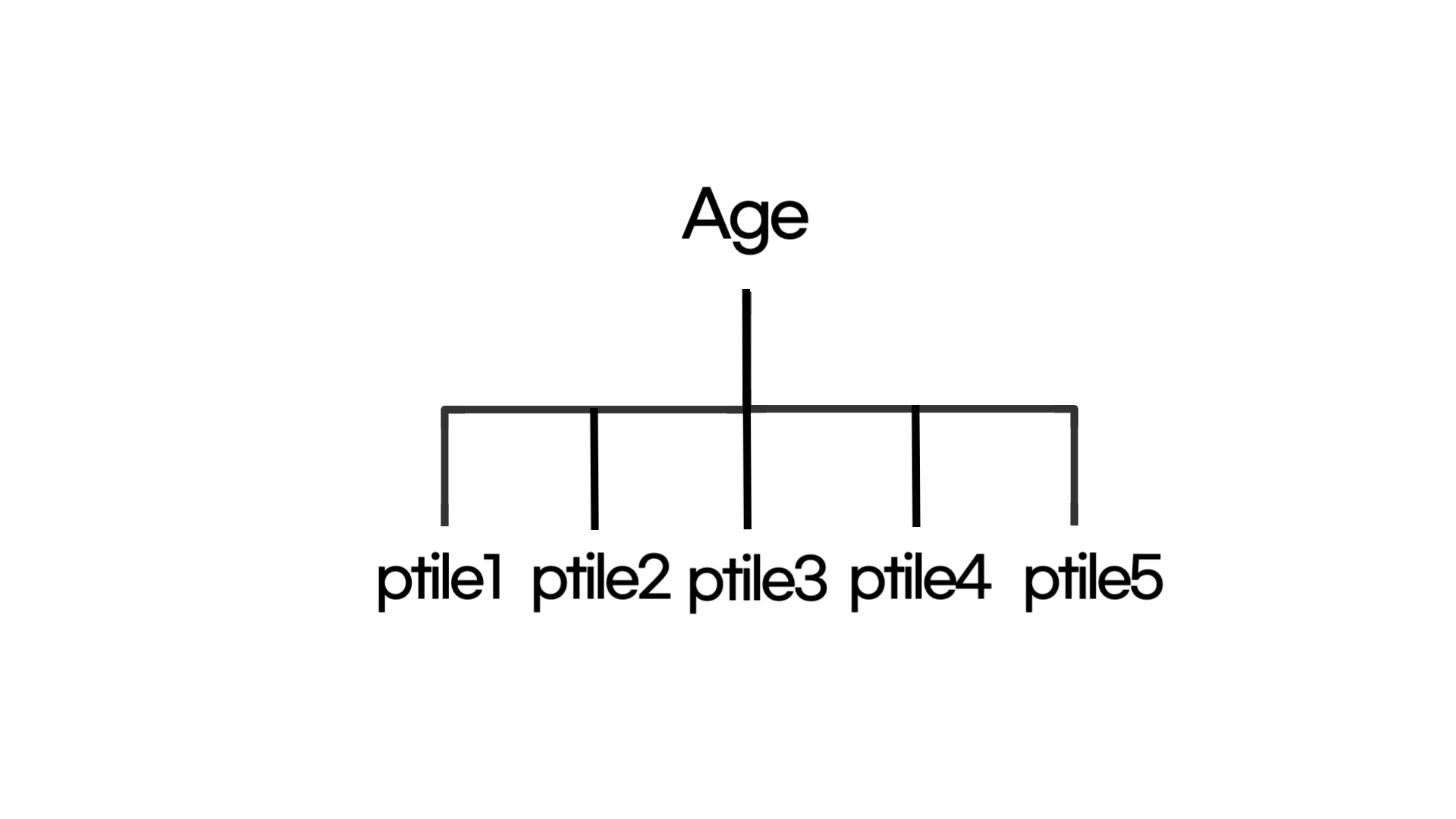
마지막으로, 연속형 변수인 Age (나이)의 경우 5개의 quantile 범위로 나누었습니다. pandas의 qcut을 이용하여 [0., .2, .4, .6, .8, 1.] 범위로 나눈 후, 동일하게 get_dummies()를 사용하여 원핫 인코딩을 진행했습니다.
04. 정리
Feature Engineering 이후에는 모델링을 하고 scikit-learn의 confusion matrix와 classification report를 보며 성능을 측정하였습니다.
이번 Feature Engineering을 부분이 저에게 크게 다가왔던 이유는 각 유형의 데이터별로 어떻게 변형을 해야할지에 대한 감을 잡을 수 있었기 때문입니다. 그전에는 모델링에 집중하여 공부를 하다보니 대부분 이미 정제된 데이터를 사용하여 Feature Engineering을 어떻게 해야할지에 대한 지식정도만 가지고 있었습니다.
하지만, 이번 기회로 Nominal, Ordinal, Continuous 변수에 따라 어떻게 Feature Engineering을 해야하는지 배웠기 때문에 다음 미니 프로젝트 혹은 다른 프로젝트에서 활용할 수 있는 스킬셋을 얻는 좋은 경험을 할 수 있었습니다.
마지막으로 이외의 배운 내용 정리를 하며 마무리하도록 하겠습니다.
<Summary>
- 모델링을 하는 다양한 목적이 있지만, 최근에는 단순히 레이블을 잘 맞추는 것보다 잘 맞추면 왜 잘 맞추는지, 통제가능한 변수를 핸들링 했을 때 어떻게 바뀌는지에 대해 궁금해하는 경우가 많음
- 때문에 이런 부분을 잘 설명할 수 있어야 함
- Deep Learning 알고리즘은 성능은 좋을 수 있으나 만능은 아니기 때문에, 모델 학습을 하는데 충분히 학습이 되지 않을 경우에 Deep Learning을 활용해 비교 분석을 하는 것이 좋음
- 데이터 분석은 속해있는 회사에 완전히 녹아들지 않으면 할 수 없음
- 때문에 머리로만 회사를 이해하는 것이 아니라 직접 상품도 사보는 등 여러 경험을 하며 회사에 녹아드는 것이 필요!
부족하지만 여기까지 읽어주셔서 감사합니다! 피드백 무한 환영입니다!
