Kornia를 통해 Inference 더 빠르게 하는 방법

이슈 상황
부스트캠프 AI Tech 4기 Semantic Segmentation 대회에서 생긴 이슈에 대해 자세히 적은 글입니다.
- Semantic Segmentation 대회이기 때문에 이미지에 대해 Model을 돌려 Mask 이미지를 만들고 제출하면 됩니다.
- 대회에서 제공된 Test 이미지 사이즈는 512x512였지만 채점을 하기 위해서 256x256으로 Resize를 해야 했습니다.
정리하면 Test Image에 Segmentation을 한 Mask 이미지를 256x256으로 Resize를 해야 하는 것이죠.
대회에서 제공된 Baseline code 중 resize 하는 부분을 참고해보면
size = 256
transform = A.Compose([A.Resize(size, size)])
model.eval()
preds_array = np.empty((0, size*size), dtype=np.long)
with torch.no_grad():
for step, (imgs, image_infos) in enumerate(tqdm(test_loader)):
# inference (512 x 512)
outs = model(torch.stack(imgs).to(device))['out']
oms = torch.argmax(outs.squeeze(), dim=1).detach().cpu().numpy()
# resize (256 x 256)
temp_mask = []
for img, mask in zip(np.stack(imgs), oms):
transformed = transform(image=img, mask=mask)
mask = transformed['mask']
temp_mask.append(mask)
oms = np.array(temp_mask)
oms = oms.reshape([oms.shape[0], size*size]).astype(int)
preds_array = np.vstack((preds_array, oms))
이런 식으로 사용했습니다.
저는 Detectron2 기반으로 위 코드를 참고해 아래의 코드를 사용했습니다.
predictor = DefaultPredictor(cfg)
size = 256
transform = A.Compose([A.Resize(size, size)])
image_id = []
preds_array = np.empty((0, size * size), dtype=np.long)
for index, image_info in enumerate(tqdm(images, total=len(images))):
file_name = image_info["file_name"]
image_id.append(file_name)
path = Path("/opt/ml/input/data") / file_name
img = read_image(path, format="BGR")
# inference (512 x 512)
pred = predictor(img)
output = torch.argmax(pred["sem_seg"],dim=0).detach().cpu().numpy()
# resize (256 x 256)
temp_mask = []
temp_img = np.zeros((3, 512, 512))
mask = transform(image=temp_img, mask=output)["mask"]
temp_mask.append(mask)
oms = np.array(temp_mask)
oms = oms.reshape([oms.shape[0], size * size]).astype(int)
preds_array = np.vstack((preds_array, oms))(사실 제가 작성한 건 아니고 github에 있는 코드를 가져온 것입니다.)
위 코드를 사용했을 때 걸리는 시간은 약 15분이였고
GPU 사용량은 약 32Gib 중 약 2700Mib 정도 사용합니다.
Test 이미지가 총 819장인 것에 비해서 너무 오래 걸려서 이상하다고 느꼈고
바로 원인 분석에 들어갔습니다.
제가 생각한 원인은 2가지 였습니다.
- Model이 이미지 1장 씩 Predict하기 때문에 비효율적이다.
- Albumentations을 통한 Resize가 느리다.
따라서 제가 생각해본 해결방법은 아래와 같았습니다
- Batch 단위로 이미지를 Predict하자
- albumentations보다 빠른 라이브러리를 사용하자
Batch 단위로 Predict
Detectron2는 공식적으로는 Batch Inference를 지원하지 않습니다..🥲
Detectron2 이슈탭에서 다행히 Batch Inference 관련 글을 발견했습니다.
이를 토대로 코드를 작성했습니다.
Albumentations보다 빠른 라이브러리를 사용
Augmentation 라이브러리 중에서 Albumentations보다 빠른 라이브러리가 있을까요?
정답은 "있다" 입니다
바로 Kornia 입니다.
- GPU를 사용해 연산을 하기 때문에 빠릅니다.
- Batch size를 키울 수록 속도가 빠릅니다.
- 반대로 GPU를 그만큼 사용하기 때문에 리소스가 듭니다.
코드 구현
위 두 가지 해결책을 적용해 코드로 구현했습니다.
class BatchPredictor(DefaultPredictor):
"""Run batch inference with D2"""
def __collate(self, batch):
data = []
for image in batch:
# Apply pre-processing to image.
if self.input_format == "RGB":
# whether the model expects BGR inputs or RGB
image = image[:, :, ::-1]
height, width = image.shape[:2]
image = self.aug.get_transform(image).apply_image(image)
image = image.astype("float32").transpose(2, 0, 1)
image = torch.as_tensor(image)
data.append({"image": image, "height": height, "width": width})
return data
def __call__(self, img_infos: List[dict]) -> List[dict]:
"""Run d2 on a list of images.
Args:
images (list): BGR images of the expected shape: 512x512
"""
images = []
image_id = []
for img_info in img_infos:
path = Path("/opt/ml/input/data") / img_info["file_name"]
img = read_image(path, format="BGR")
images.append(img)
image_id.append(img_info["file_name"])
dataset = ImageDataset(images)
loader = DataLoader(
dataset,
batch_size=32,
shuffle=False,
num_workers=4,
collate_fn=self.__collate,
pin_memory=True,
)
size = 256
transform_k = nn.Sequential(K.geometry.Resize((size, size)))
preds_array = np.empty((0, size**2), dtype=np.long)
with torch.no_grad():
for batch in tqdm(loader, total=len(loader)):
outs = self.model(batch)
outs = torch.cat(
[out["sem_seg"].unsqueeze(0) for out in outs], 0
).argmax(1)
masks = transform_k(outs.type(torch.FloatTensor)).detach().cpu().numpy()
oms = masks.reshape([len(batch), -1]).astype(int)
preds_array = np.vstack((preds_array, oms))
del masks, oms, outs
torch.cuda.empty_cache()
return image_id, preds_array
기존 코드는 Single 이미지를 처리하기 때문에 for loop을 썼는데
이번에는 BatchPredictor 내에서 전부 다 처리되도록 구현을 했습니다.
위 코드로 Batch Size 32로 Inference를 했을 때 약 1분 30초로 시간을 많이 줄일 수 있었고
GPU또한 약 32GiB 중 약 26GiB를 사용했습니다.
Batch Size 별 속도 비교
Kornia가 Batch Size를 키울수록 속도도 빠른지 비교도 해보겠습니다.
(V100 기준)
| Batch Size | 최대 GPU util | Time |
|---|---|---|
| 1 | 약 2,700 | 약 4분 53초 |
| 4 | 약 3,700 | 약 2분 8초 |
| 8 | 약 5,200 | 약 1분 40초 |
| 16 | 약 8,200 | 약 1분 28초 |
| 32 | 약 14,300 | 약 1분 25초 |
- Batch Size를 더 키울 수록 속도가 빠름
- Batch Size를 많이 키운다고 해서 가파른 상승이 있는 것은 아님
- V100 대신 A6000 환경에서 Batch 32로 실험 시 57초 걸림
새로운 문제
이렇게 해서 속도는 빨라졌지만 또다른 문제를 발견했습니다.
기존 albumentations을 적용했을 때보다 리더보드 기준 점수가 떨어진 것이죠.
mIoU기준 0.7763 ➡️ 0.7472
문제를 파악하고자 mask를 시각화해봤습니다.
⬇️ Albumentation 적용 이미지

⬇️ Kornia 적용 이미지
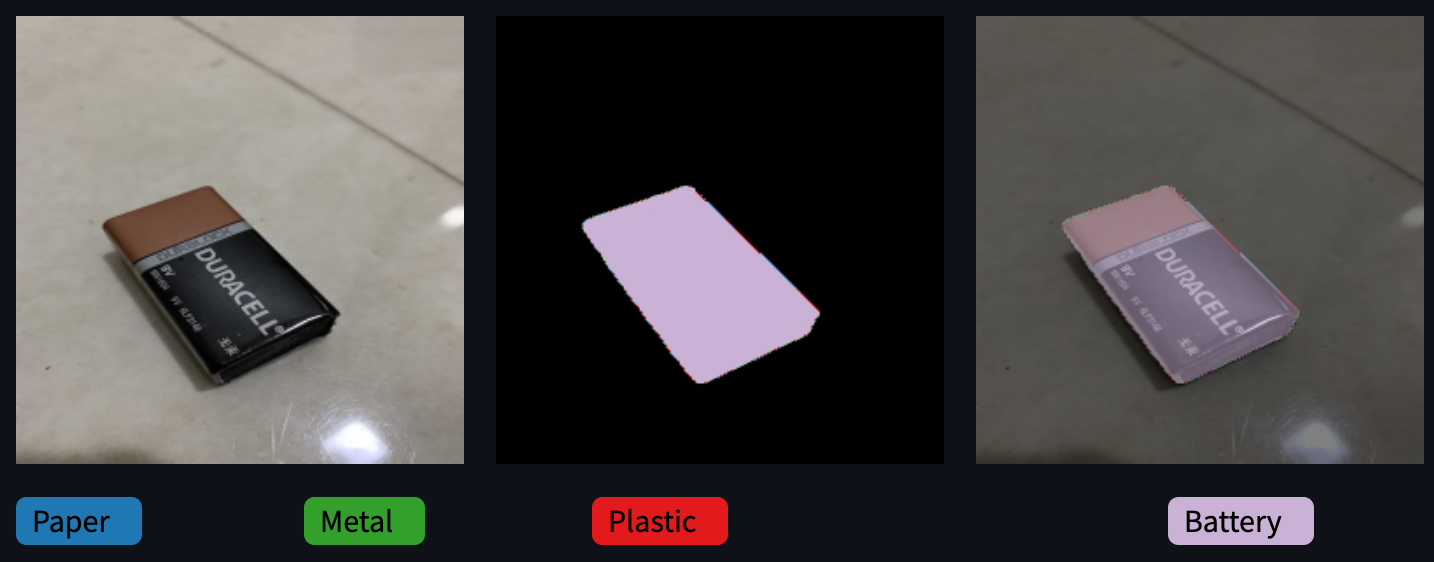
두 이미지의 차이가 느껴지시나요? 레이블 표시가 없었다면 잘 모를거라 생각합니다.
Kornia 적용 이미지를 자세히 보면 Object 경계에 Battery가 아닌 레이블들이 껴있는 것을 볼 수 있습니다.
왜 이럴까요?
저는 처음에 Kornia의 성능 문제라고 생각했지만 결론적으로 Interpolation 문제였습니다.
Resize시 image와 mask에 들어가는 Interpolation이 다릅니다.
Base 코드를 리마인드해보면 아래처럼 사용했죠.
transform = A.Compose([A.Resize(size, size)])
transformed = transform(image=img, mask=mask)⬇️Albumentations Resize 소스 코드를 뜯어보면 정답을 알 수 있습니다.

apply는 interpolation이 cv2.INTER_LINEAR이고
apply_to_mask를 보면 interpolation이 cv2.INTER_NEAREST알 수 있습니다.
그러면 Kornia는 어땠을까요?
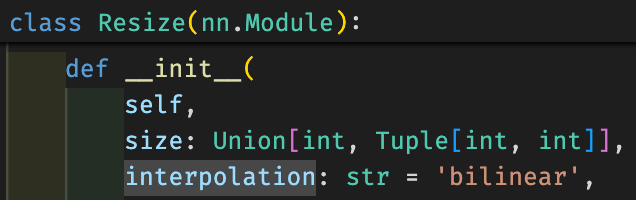
interpolation default값이 bilinear임을 알 수 있죠.
실제로 mask 이미지를 transform할 때 Interpolation을 NEAREST로 하는게 중요하다고 합니다.(참고 글)
왜 Mask에는 NEAREST Interpolation을 사용할까요?
Semantic Segmentation은 이미지의 모든 픽셀의 레이블을 예측하는 Task입니다.
여기서 레이블은 실수값이 아니라 정수값이여야 합니다.
Nearest neighbor Interpolation은 아래와 같이 픽셀값을 그대로 사용합니다.
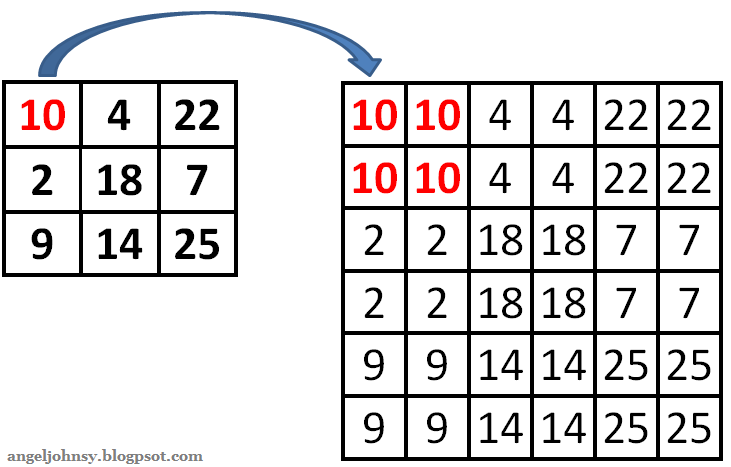
반면 Bilinear Interpolation은 두 점의 거리에 따라 선형적으로 계산해서 두 점 사이 값을 추정하기 때문에
소수값을 사용하게 됩니다.
그러면 다시 문제의 이미지를 보겠습니다.
대충 감이 오시나요?
여기서 Kornia는 Mask Interpolation을 Bilinear를 사용했습니다.
아마 배터리 테두리의 픽셀값은 소수값이였고 정수로 변환하는 과정에서 Battery와 관련없는 레이블이 생겼을 것입니다.
결론적으로 Mask 이미지에는
Interpolation을NEAREST로 적용하는게 키포인트였습니다! 👀
Interpolation 변경
Mask 이미지에 노이즈끼는 이유가 라이브러리 문제가 아니라 Interpolation이 문제였다는 것을 파악했습니다.
이제 이를 적용해볼 수 있는 방법은 두가지입니다.
- Albumentations에 Mask만 Resize하고 Interpolation은
NEAREST로 한다. - Kornia에 Interpolation을
NEAREST로 한다.
Albumentations에 Mask Interpolation을 NEAREST로 변경
⬇️똑같이 BatchPredictor를 사용하는 대신에 transform만 변경한 코드입니다.
transform = A.Resize(
size, size, p=1.0, always_apply=True, interpolation=cv2.INTER_NEAREST #👀👀👀
)
preds_array = np.empty((0, size**2), dtype=np.long)
with torch.no_grad():
for batch in tqdm(loader, total=len(loader)):
outs = self.model(batch)
outs = torch.cat(
[out["sem_seg"].unsqueeze(0) for out in outs], 0
).argmax(1)
outs = outs.detach().cpu().numpy()
for out in outs:
out = out.astype(np.uint8)
mask = transform(image=out)["image"] #👀👀👀
oms = mask.reshape([1, -1]).astype(int)
preds_array = np.vstack((preds_array, oms))
del mask, oms, outs
torch.cuda.empty_cache()Kornia에 Interpolation을 NEAREST로 변경
transform = nn.Sequential(K.geometry.Resize((size, size),interpolation='nearest'))기존 코드에서 이 부분만 변경해주면 됩니다.
비교
Batch Size: 32
Batch 단위로 Predict
| Method | 라이브러리 | Time |
|---|---|---|
| transform(image=img,mask=mask)["mask"] | Albumentations | 약 13분 30초 |
| transform(image=mask)["image"] Interpolation-NEAREST | Albumentations | 약 4분 |
| Interpolation-NEAREST | Kornia | 약 1분 24초 |
- Albumentations 기준 Mask만 넣어서 Resize하는 것이 둘다 넣는 것보다 더 빠름
- Kornia가 압도적으로 빠름
- 모든 Method의 결과는 동일함
마무리
- BatchPredictor와 Kornia를 이용해 기존 대비 약 9.6배 속도 향상
- Mask 이미지에 Augmentation을 적용할 때는 Interpolation은 NEAREST 알고리즘을 적용해야 함
- Inference 할 때 Augmentation 라이브러리로 Kornia를 고려해보자
