
Paper: Dilated Neighborhood Attention Transformer
Key-word
- Local-Attention
- Self-Attention
- Neighborhood-Attention
- Dilated Convolution
0. 한줄 요약
Local Attention의 단점을 해결한 DiNA를 적용한 DiNAT 모델을 제안한다.

⬆️ Single Pixel의 Attention 범위를 dilation 비율에 따라 나타낸 그림
- Dilated Conv처럼 Dilation이 1일때는 DiNA와 NA는 같음
- Dilation이 커질수록 RF(Receptive Field)가 넓어짐
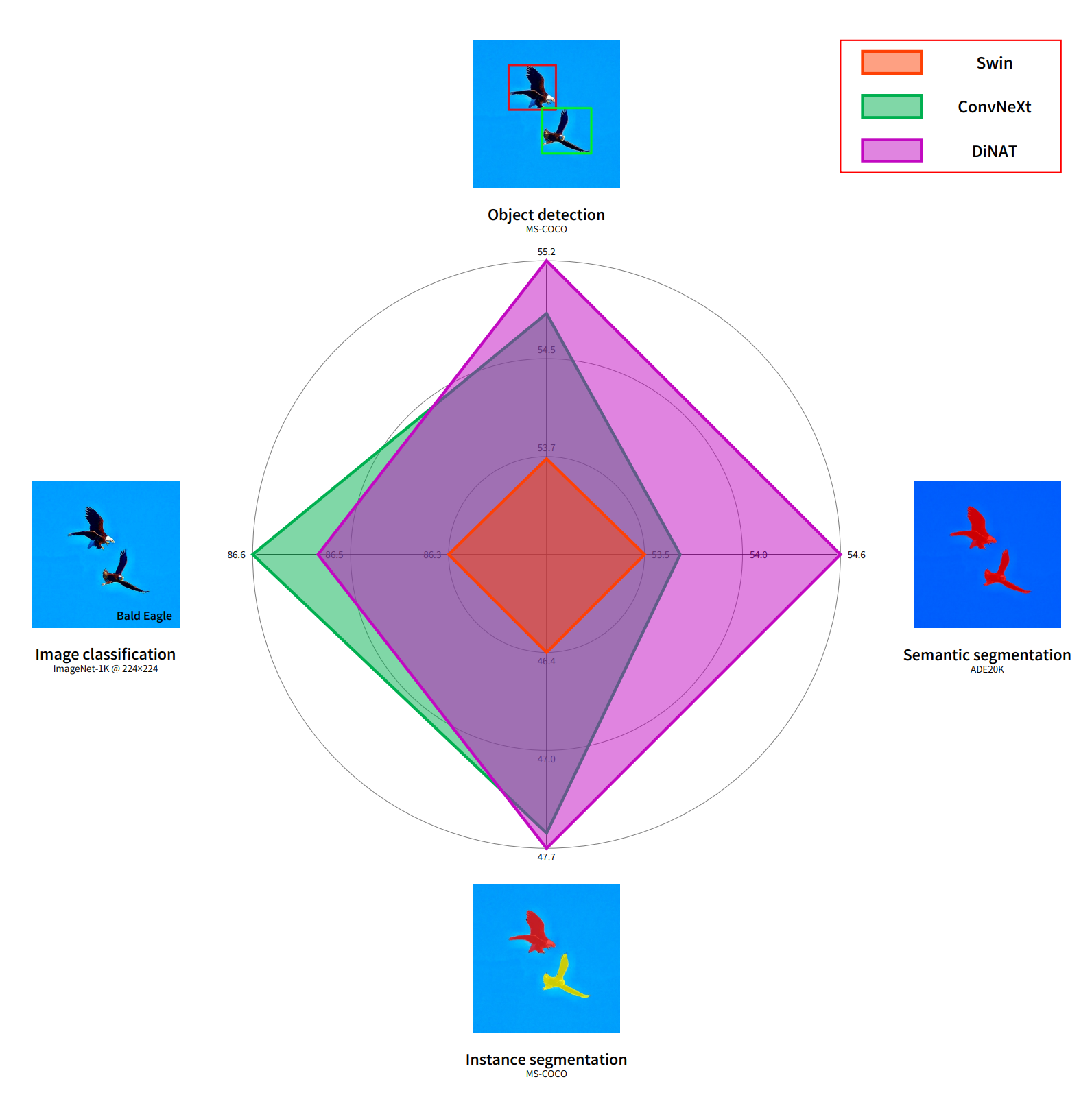
⬆️ Swin, ConvNeXt, DiNAT 성능 비교
- Swin은 DiNAT, ConvNeXt보다 성능이 모든 Task에서 좋지 않음
- Classification을 제외한 Task에서는 DiNAT이 ConvNeXt보다 성능이 우수함
1. Motivation
- Vision 분야에서는 Hierarchical Transformer가 주목받고 있고 주로 Local-Attention 사용
ex) Neighborhood Attention, Shifted-Window Self-Attention(Swin) - Local-Attention은 Self-Attention의 Complexity를 줄이는데 효과적이라서 사용
- But Self-Attention 장점을 해침
- Long Range Inter-Dependency Modeling
- Global RF
- 최고의 시나리오는 Linear Complexity를 유지하면서, Self-Attention의 장점을 살리는 것
- 이를 충족하는 DiNAT을 제안하고 기준 모델과 비교실험을 통해 DiNA의 효과 입증
2. Related Work
- ViT
- Self-Attention
- Local-Attention (Localized Self-Attention)
- Sparse-Attention
3. Method
Local-Attention
Sparse-Attention
Dilated Neighborhood Attention
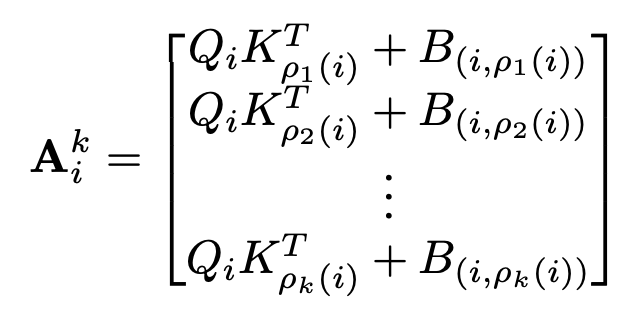
⬆️ Neighborhood 크기가 이고 번째 토큰에 대해서 NA 가중치 벡터
는 query, key
는 Token 간의 Relative Positional Biases를 의미
는 Token 의 번째 가까운 Neighbor
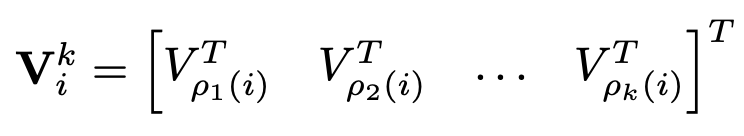
Neighboring Value를 Token 의 개의 Neighboring Value Projections로 정의
여기서 는 Input X의 Linear Projection
정리하면

⬆️ 크기의 Neighborhood를 갖는 토큰 의 NA
( 는 scale 파라미터 )
DiNA는 NA에 dilation value 를 더해줌
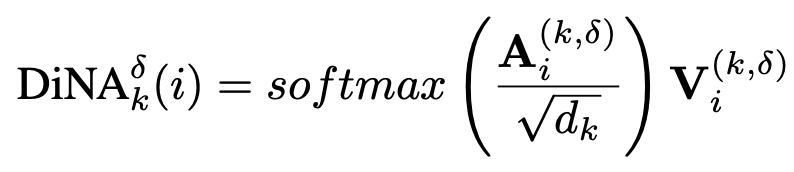
- 전체적인 구조가 Attention의 식과 비슷함을 알 수 있음
Dilated Neighborhood Attention Transformer
특징
- 더 많은 Global Context를 잡음
- RF를 더 폭발적으로 키움
- 추가 비용 ❌
- 기존 NAT보다 좋고 ConvNeXt같은 강력한 CNN 계열 모델보다 성능이 더 좋음
- NA의 Dilated and Non-Dilated Variants로 구성됨
- Gradual Dilation Change을 활용하는데 이것이 RF를 최적화해서 키워주고 Feature를 잘 학습함

- DiNAT의 평가를 위해서 기존 NAT와 Architecture와 Configuration이 동일하게 설계
- DiNAT과 NAT의 가장 큰 차이점은 NA-DiNA 구조를 사용 (DiNAT Block)
- Dilation Value는 Task와 Input Resolution에 따라 다르게 설계
Choice of Dilation
- DiNA는 Per Layer Dilation Value 라는 새로운 파라미터를 제안함
- Dilation Value 의 최대치를 로 정의하고 n은 토큰의 개수, k는 Kernel / Neighborhood Size
- 각 토큰마다 Dilated Neighbor k 개가 있도록 하는 장치 - Dilation Value 의 최소치는 1로 NA와 동일함
- 모델에 각 layer에 있는 Dilation Value 는 input에 달라지는 파라미터 (1~)
- Flexible한 RF를 제공함
Receptive Fields
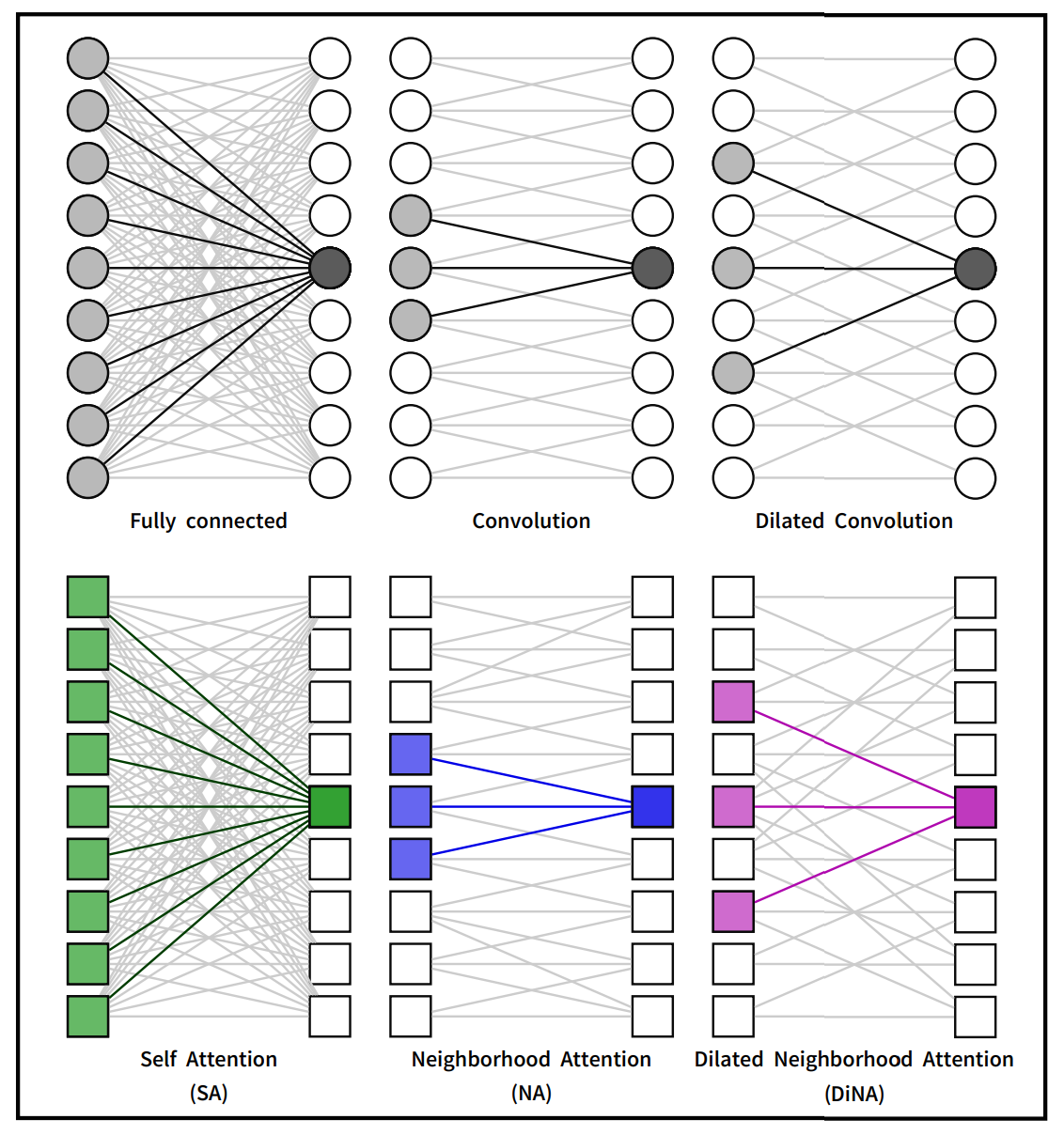
각 Mechanism 별 Receptive Field
- CNN과 Attention 비슷한 양상
- Dilated mechanism 적용 시 RF가 더 넓고, 추가 비용 X
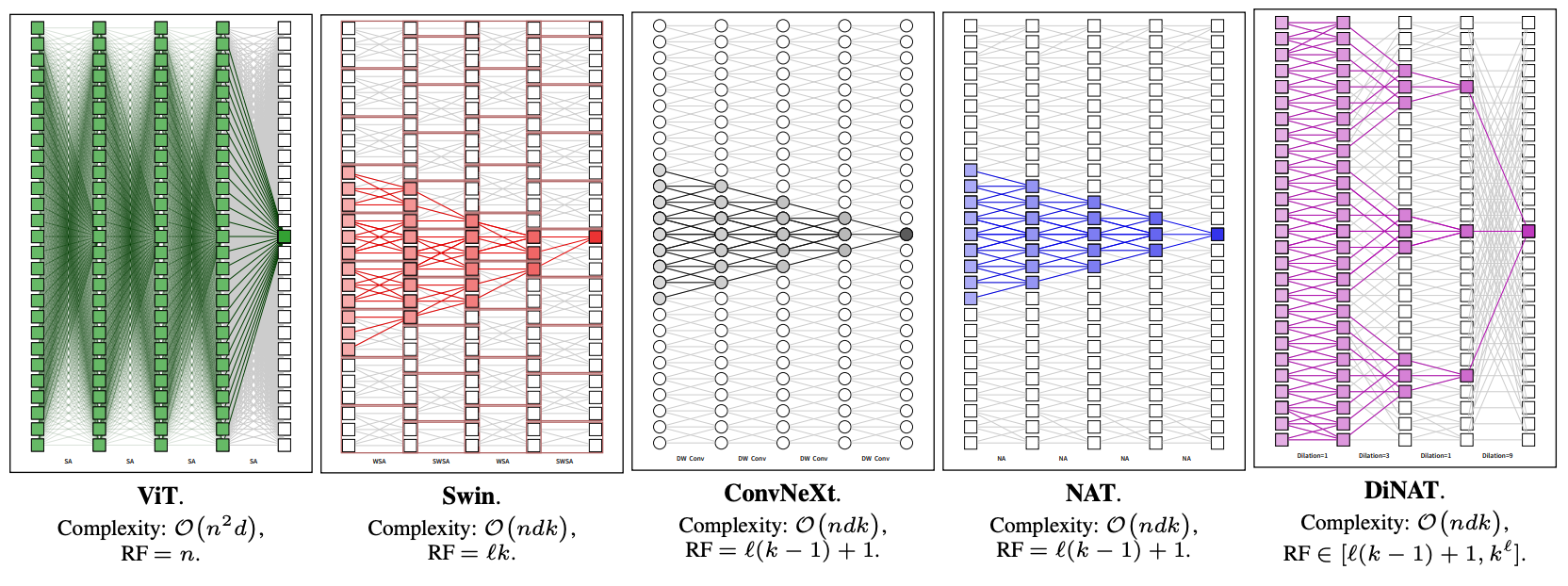
모델 별 Receptive field ( 는 임베딩 차원)
- ViT는 RF가 가장 넓지만 계산량이 가장 많음
- Swin은 ConvNeXt, NAT보다 RF가 더 넓지만 비대칭임
- DiNAT은 적은 Complexity로 flexible한 RF를 가짐
(DWSConv = ConvNeXt의 Key Component)
Layer 개수 , Kernel Size , Token 개수 과 관련해서 RF Size를 계산
Swin의 WSA의 RF는 고정된 상수값을 가짐
- Window Partitioning이 Window 간 Interaction을 막기 때문에 RF 확장 X
SWSA가 이 문제를 해결했고, Layer 당 Window 하나로 RF를 넓힘 ->
DiNA의 RF는 Flexible
- Dilation Value와 같이 변함 ( 부터 까지 )
정리
최적의 dilation value를 가진 NA - DiNA 조합은 RF를 폭발적으로 까지 증가시킴
DiNA의 효과는 Dilated Convolution에서 알 수 있듯이 예상 가능함
4. Experiments
- DiNAT 모델과 다른 모델들과 성능을 비교해서 효과를 잘 입증
- NAT, Swin, ConvNeXt와 비교 실험(Image Classification, Detection, Segmentation)
- Mask2former에 적용해서 Segmentation Task에 실험
Segmentation을 때문에 이 모델을 사용해서 Segmentation만 알아보겠습니다.
Segmentation
UPerNet에 Backbone으로 DiNAT을 써서 ADE20k에 적용
실험 세팅은 ADE20k 학습했던 Swin의 세팅과 동일
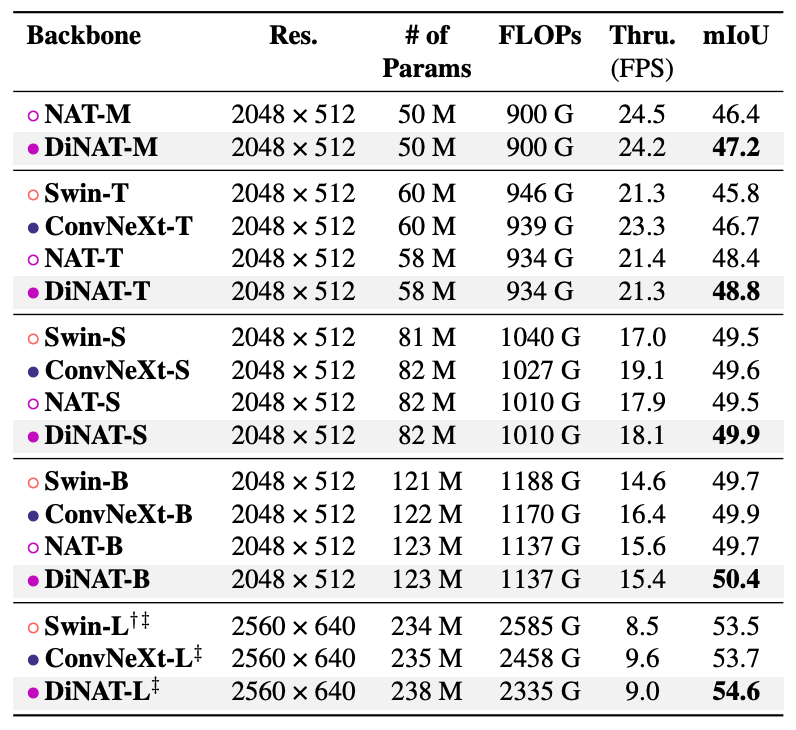
- 기존 NAT모델보다 성능이 좋음
- mIoU 기준 좋은 성능을 냄
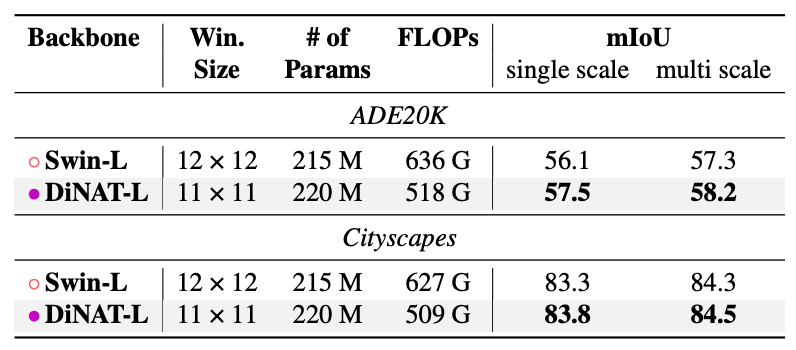
Image segmentation with Mask2Former
- DiNAT의 segmentation 성능을 분석하기 위해서 Mask2former를 이용해 실험 수행
- Mask2former는 backbone으로 Swin-L을 사용했기 때문에 비교실험하기 좋았음
- backbone만 DiNAT-L로 바꿔서 실험 진행
- 모든 task에서 Swin-L보다 성능 좋음
5. Ablation study
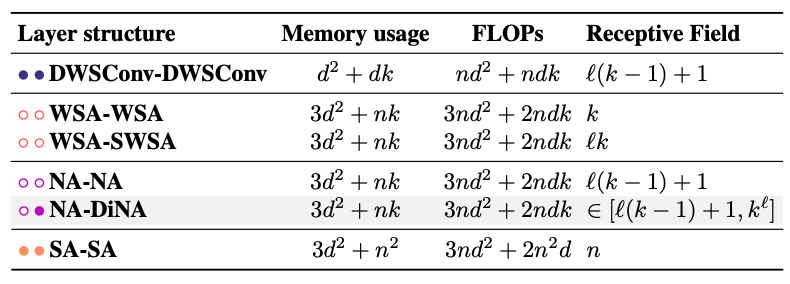
NA-DiNA vs DiNA-NA
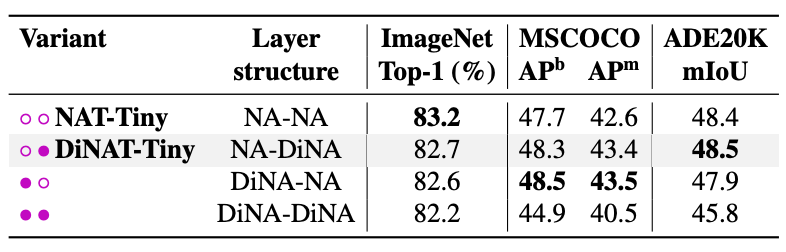
- Layer를 구성할 때 어떤 순서가 더 좋은가
- DiNA-DiNA 조합이 가장 성능이 좋지 않았음
- Local Attention(NA)과 Sparse Global Attention(DiNA) 조합의 효과 입증
DiNAT에서는 NA-DiNA 조합을 사용함 이 조합이 전체적으로 더 효과적
Kernel size
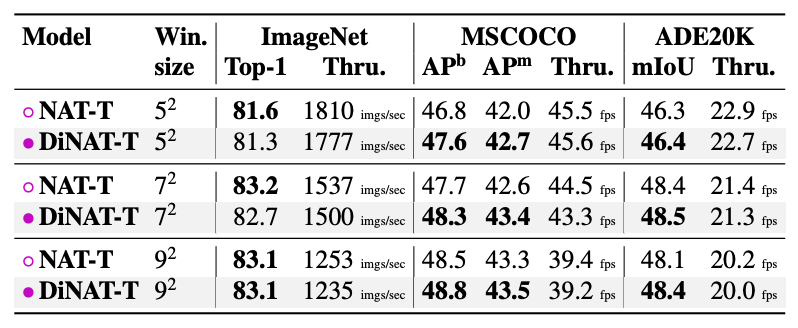
모델 성능에 kernel size는 어떤 영향을 미치는가
- Kernel Size가 클 수록 성능이 좋음
- 하지만 Kernel Size가 7이상을 넘어가면 유의미한 차이 X
6. Conclusion
-
Local attention은 계산량을 줄이는 데 효과적이여서 Input을 점차 Downsample하는 Hierarchical Model에서 중요한 역할을 함
-
하지만 RF를 키우지 않으면 Global Self-Attention만큼 Longer Range Inter-Dependencies를 잘 잡지 못함
- 하지만 RF를 키우는 것은 Local attention의 본 목적인 효율성을 해침
따라서 저자들은 추가 비용없이 Local Attention을 Sparse Global Attention으로 확장하는 NA의 업그레이드 버전인 DiNA를 제안
DiNA를 적용한 DiNAT 모델은 NA - DiNA Layer로 구성되고 추가 비용없이 우수한 성능을 보임
DiNA가 Global Self-Attention과 비슷한 역할을 하기 때문에 성능이 좋았음
