DiNAT 논문리뷰에 나오는 Local-Attention에 대해 보충 설명한 글입니다.
Motivation
- Vision은 고해상도 이미지 처리, NLP는 대규모 Document 처리할 때 Self-Attention을 사용하면 계산량⬆️
- 이러한 계산량을 줄이려는 후속 연구로 Self-Attention의 범위를 줄이는 다양한 시도가 있었음
- 그 중 하나가 Localization
특징
- Local-Attention은 Self-Attention의 Complexity를 줄이는데 효과적
- 하지만 Self-Attention 장점을 살리지 못함
- Long Range Inter-Dependency Modeling
- Global Receptive Field
Local-Attention
SASA (Stand-Alone Self-Attention)
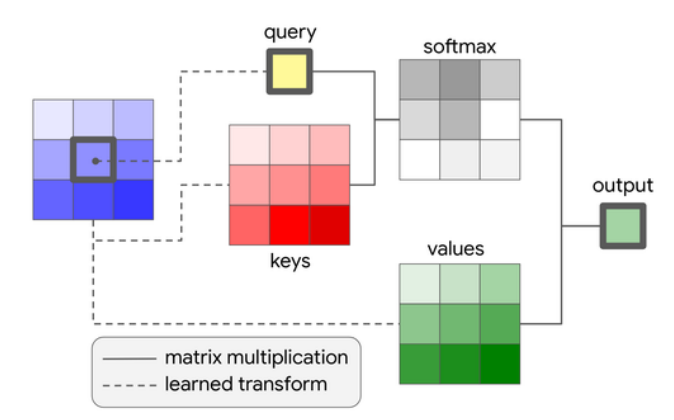
- SASA는 ViT가 나오기 전에 등장한 초기 Local-Attention 중 하나
- Sliding Window 방식
- Convolution 연산을 쉽게 대체할 수 있고 이론적으로 계산량도 줄일 수 있음
- But, 실제로는 비효율적인 구현 때문에 모델 속도가 느림
SWSA (Shifted Window Self Attention)
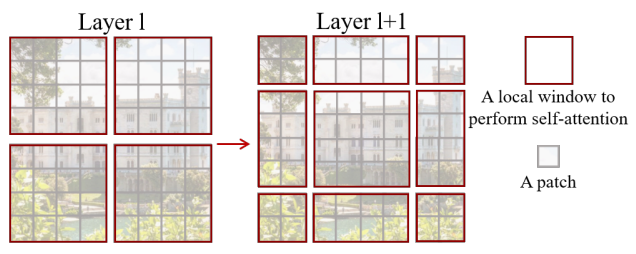
⬆️ SWSA를 나타내는 그림

⬆️ Window Self-Attention 과정

⬆️ Shifted Window Self-Attention 과정
- Swin Transformer에서 WSA, SWSA를 제안함
- WSA는 Window 내에서 Self-Attention 진행
- SWSA는 이전의 Layer와 다르게 Window를 나누고 Window 간 관계 학습
(자세한 설명은 다른 블로그 참고 부탁..)
NA (Neighborhood Attention)
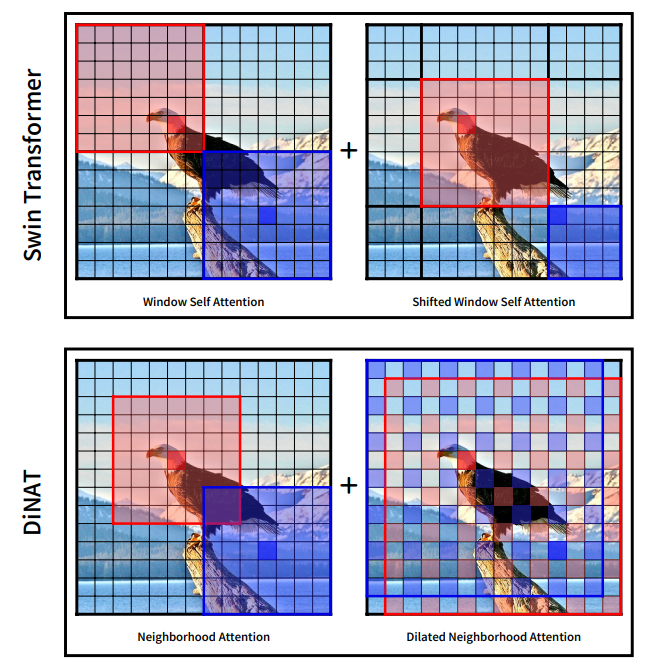
⬆️ Swin과 DiNAT에서 사용된 WSA, SWSA, NA, DiNA
-
NA는 간단한 Sliding-Window Attention
-
각 Pixel에서 가장 가까운 Neighbor들과 Self-Attention 진행
-
WSA, SWSA와 시간, 공간 복잡도 그리고 Parameter 수도 같음
-
Sliding Window가 겹쳐서 연산되기 때문에 Translation Equivariance를 보존함
-
Sliding Window 방식은 SASA와 비슷하지만, Neighbor특징 때문에 window가 커질수록 SASA와 달라짐
-
Sliding-Window Attention 문제가 비효율적으로 구현된 것인데 NATTEN이라는 extension을 도입하면서 해결됨
-
NAT는 Swin과 Hierarchical 한 디자인은 비슷하지만, Swin과 달리 Downsampling Layer에서 Convolution을 중첩해서 사용하는 점이 다름 (Swin은 Patch로 처리)
-
Swin과 Parameter 수와 FLOPS를 비슷하게 만들기 위해서 NAT는 더 작은 Inverted-Bottleneck으로 Layer를 더 쌓음
한계점
- Local-Attention은 Self-Attention와 달리 Convolution처럼 Receptive Field가 작고 천천히 증가함
- Local-Attention 기반 모델은 Locality와 효율성을 잘 살려서 성능은 좋지만
Self-Attention보다는 Global Context를 잘 잡지 못함

OJH