💥이전 글인 머신러닝을 위한 데이터 전처리 실습의 데이터를 그대로 사용
Classification
새로 관측된 데이터가 어떤 범주 집합에 속하는지를 식별하는 것.
훈련 데이터를 이용해 모델을 학습하면, 모델은 결정경계 라는 데이터를 분류하는 선을 만들어낸다.
Logistic Regression
선형회귀모델에서 변형된 모델.

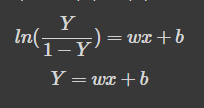
Odds를 Y에 적용시킨다. (0~1의 확률값으로 보기 위해)
정리하면
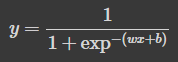 sigmoid 식이 된다.
sigmoid 식이 된다.
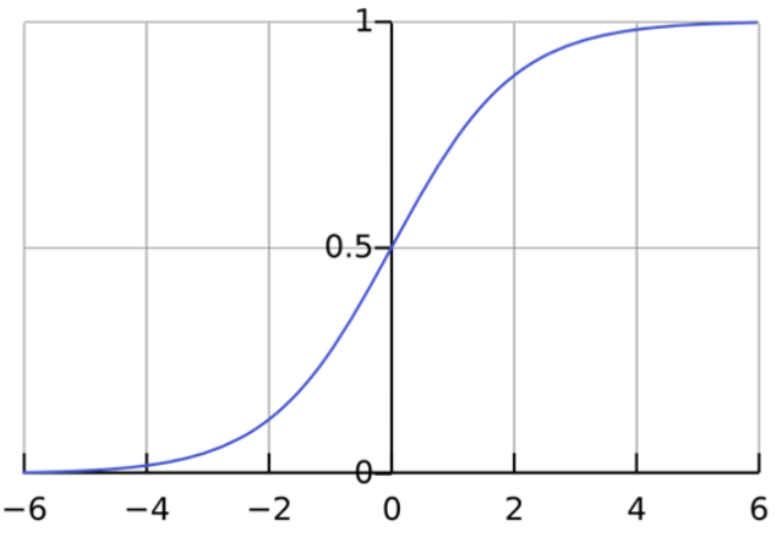
로지스틱회귀는 이진분류 모델 아님?
하나의 수식이 출력하는 결과는 클래스의 확률을 나타내는 것은 맞습니다. 하지만, 멀티 클래스인 경우 내부적으로 클래스 수에 맞게 여러개의 수식을 만들어 각각의 클래스에 속할 확률을 계산한 후 가장 높은 확률은 가진 클래스로 분류합니다. 이를 One-vs-Rest라고 합니다.
참조)
Logistic Regression 대표 파라미터
- C (float): 얼마나 모델에 규제를 넣을지 결정하는 값 작아질수록 모델에 규제가 높아짐 (과적합 방지, from SVM)
- fit_intercept (bool) : 회귀 수식에서 y 절편을 포함할지 유무
- random_state (int) : 내부적으로 사용되는 난수값
- l1_ratio (float): L1 규제 항을 얼마나 많이 적용할지
- class_weight (dict) : 학습 시 클래스의 비율에 맞춰 손실값에 가중치를 부여
실습
1. 모델 불러오기 및 정의하기
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()2. 모델 학습하기(훈련 데이터)
lr.fit(x_train, y_train)3. 결과 예측하기(검증 데이터)
y_pred = lr.predict(x_valid)4. 결과 살펴보기
from sklearn.metrics import accuracy_score
print('로지스틱 회귀, 정확도 : {:.2f}%'.format(accuracy_score(y_valid, y_pred)*100))
정확도만 보고 판단해서는 안된다. 다른 평가지표도 봐야하고, 이 데이터는 open:close = 95:5 였다. open으로 다 예측해버릴 가능성이 높음
5. 로지스틱 회귀 모델의 계수w, 절편b 살펴보기
print('로지스틱 회귀, 계수(w) : {}, 절편(b) : {}'.format(lr.coef_, lr.intercept_))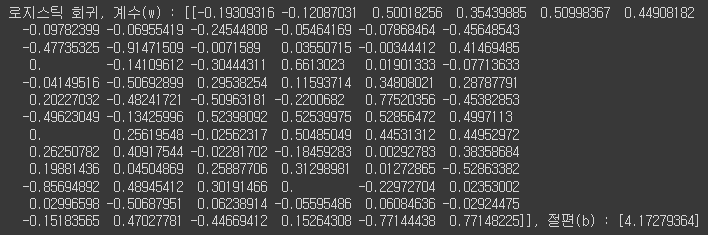
Support Vector Machine(SVM)
서포트 벡터 머신은 주어진 데이터를 바탕으로하여 두 카테고리(이진분류일때) 사이의 간격(Margin)을 최대화하는 데이터 포인트(Support Vector)를 찾아내고, 그 서포트벡터에 수직인 경계를 통해 데이터를 분류하는 알고리즘
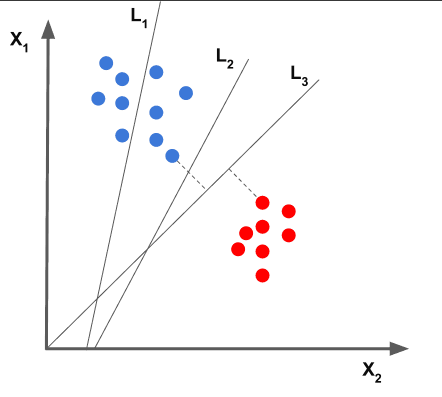
왜 마진을 최대화 해야되는가?
경험적 위험 최소화(ERM), 구조적 위험 최소화(SRM) 라는 말이 있다.
- 경험적 위험 최소화
- 훈련 데이터에 대해 위험을 최소화
- 학습 알고리즘의 목표
- 뉴럴 네트워크, 결정 트리, 선형 회귀, 로지스틱 회귀 등.
- 구조적 위험 최소화
- 관찰하지 않은(Unseen) 데이터에 대해서도 위험을 최소화
- 오차 최소화를 일반화 시키는 것
SVM은 관찰하지 않은 데이터에 대해서도 위험을 최소화(구조적 위험 최소화)시켜서 일반화 성능을 높이기 위해서 soft margin(오차는 어느정도 감안하면서 일반화가 높게 나오도록 선택하는.hard magin의 반대)방식을 선택한다.
그리고 만약에 저차원에서는 선형분리하기 힘들 때 차원을 올려서 고차원으로 보면 선형분리시키기 좋기 때문에 사용한다.(Kernel Trick 방식. -> 고차원mapping + 내적연산 한번에 시켜줌)
그만큼 성능은 좋지만 속도가 느린편이라 최근에는 잘 사용되지 않는 추세이다.(딥러닝 전에는 최고였지만 딥러닝이 나오면서 죽음)
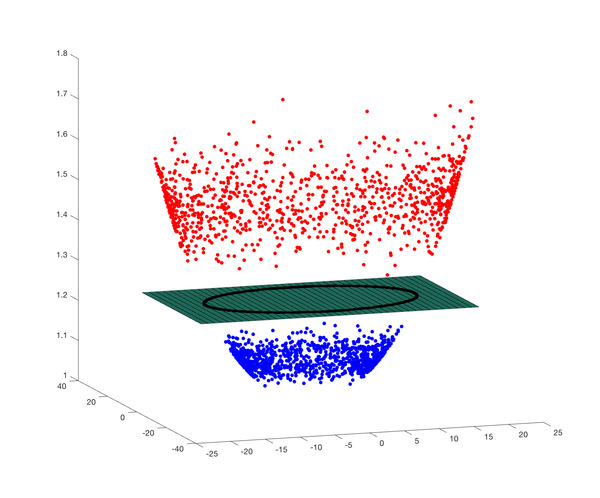
- kernel 함수 종류
- Linear (선형 함수)
- Poly (다항식 함수)
- RBF (방사기저 함수)
- Hyper-Tangent (쌍곡선 탄젠트 함수)
SVM 대표 파라미터
- C (float): 얼마나 모델에 규제를 넣을지 결정하는 값 작아질수록 모델에 규제가 높아짐 (과적합 방지, from SVM, Hard Margin)
- degree (int) : Poly Kernel 사용 시, 차수를 결정하는 값
- kernel (str) : Kernel trick에 사용할 커널 종류
- random_state (int) : 내부적으로 사용되는 난수값
- class_weight (dict) : 학습 시 클래스의 비율에 맞춰 손실값에 가중치를 부여
- gamma (float): 모델이 생성하는 경계가 복잡해지는 정도 (값이 커질수록 데이터 포인터가 영향력을 행사하는 거리가 짧아져 경계가 복잡해진다.)
실습
1. 모델 불러오기 및 정의하기
from sklearn.svm import SVC
svc = SVC()#(class_weight='balanced')2. 모델 학습하기(훈련 데이터)
svc.fit(x_train, y_train)3. 결과 예측하기(검증 데이터)
y_pred = svc.predict(x_valid)4. 결과 살펴보기
print('서포트 벡터 머신, 정확도 : {:.2f}%'.format(accuracy_score(y_valid, y_pred)*100)) 아까 말했듯이 이 데이터는 imbalance하기 떄문에 정확도가 높게 나오는게 크게 의미가 없다.
아까 말했듯이 이 데이터는 imbalance하기 떄문에 정확도가 높게 나오는게 크게 의미가 없다.
Decision Tree
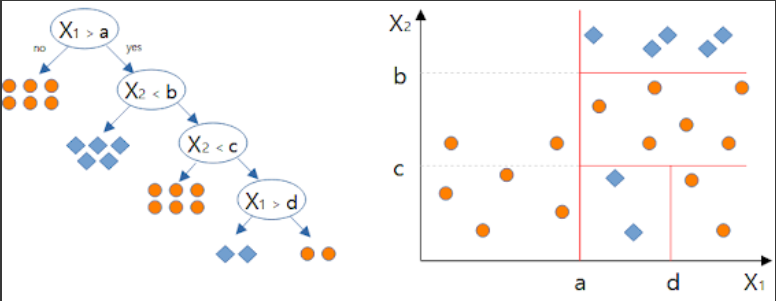
- 사람의 논리적 사고 방식을 모사하는 분류 방법론
- IF-THEN rule의 조합으로 class 분류
- 결과를 나무 모양으로 그릴 수 있음
- Greedy 한 알고리즘 (한번 분기하면 이후에 최적의 트리 형태가 발견되더라도 되돌리지 않음, 최적의 트리 생성을 보장하지 않음)
- 축에 직교하는 분기점
불순도(Impurity, Entropy)
분류 문제에서 결정 트리는 데이터의 불순도를 최소화 할 수 있는 방향으로 트리를 분기합니다.
불순도란 정보 이론(Information Theory)에서 말하는 얻을 수 있는 정보량이 많은 정도를 뜻합니다.
ex) 오늘 해가 동쪽에서 뜰꺼야 -> 낮은 정보량, 오늘 일식이 일어날꺼야 -> 높은 정보량
- 회귀 문제의 경우 분산을 최대로 감소시키는 방향으로 트리를 분기합니다.
시간나면 정보이론의 정보량 관련 공부
-> 정보이론 기초
가지치기(Pruning)
풀트리를 생성하게되면 모델이 과적합되는데, 이를 방지하기 위한 방법으로 가지치기를 진행한다.
트리의 크기를 제한하거나, 리프 노드의 데이터셋 개수를 제한하는 방식으로 가지치기를 진행할 수 있다.
Decision Tree 대표 파라미터
- crierion (str): 정보량 계산 시 사용할 수식 (gini, entropy)
- max_depth (int): 생성할 결정 트리의 높이
- min_samples_split (int): 분기를 수행하는 최소한의 데이터 수
- max_leaf_nodes (int): 리프 노드에서 가지고 있을 수 있는 최대 데이터 수
- random_state (int): 내부적으로 사용되는 난수값
- class_weight (dict) : 학습 시 클래스의 비율에 맞춰 손실값에 가중치를 부여
실습
1. 모델 불러오기 및 정의하기
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()2. 모델 학습하기(훈련 데이터)
dt.fit(x_train, y_train)3. 결과 예측하기(검증 데이터)
y_pred = dt.predict(x_valid)4. 결과 살펴보기
print('결정 트리, 정확도 : {:.2f}%'.format(accuracy_score(y_valid, y_pred)*100))
-> 일반화 성능은 좋을 수도 있겠는데? 라는 생각으로 접근
5. Feature Importance
트리 기반 모델은 트리를 분기하는 과정에서 어떤 변수가 모델을 생성하는데 중요한지에 대한 변수 중요도를 살펴볼 수 있습니다.
feature_importance = pd.DataFrame(dt.feature_importances_.reshape((1, -1)), columns=x_train.columns, index=['feature_importance'])
feature_importance
-> 사후분석 느낌으로 가야함. 너무 맹신하지는 말고 만약 수치가 높으면 우선 한번 그쪽으로 좀 더 접근을 해볼까? 같은 느낌으로 활용
Random Forest
결정 트리가 나무였다면, 랜덤 포레스트는 숲 입니다. 랜덤 포레스트의 특징은 작은 트리들을 여러개 만들어 합치는 모델입니다.
서로 다른 변수 셋으로 여러 트리를 생성합니다. 여러개의 모델을 합치는 앙상블 기법 중 대표적인 예시입니다.
Random Forest 대표 파라미터
- n_estimators (int) : 내부에서 생성할 결정 트리의 개수
- crierion (str) : 정보량 계산 시 사용할 수식 (gini, entropy)
- max_depth (int) : 생성할 트리의 높이
- min_samples_split (int) : 분기를 수행하는 최소한의 데이터 수
- max_leaf_nodes (int) : 리프 노드에서 가지고 있을 수 있는 최대 데이터 수
- random_state (int) : 내부적으로 사용되는 난수값
- n_jobs (int) : 병렬처리에 사용할 CPU 수
- class_weight (dict) : 학습 시 클래스의 비율에 맞춰 손실값에 가중치를 부여
실습
1. 모델 불러오기 및 정의하기
import multiprocessing
multiprocessing.cpu_count()
# n_jobs 쓸때 -1 입력하면 모든 cpu를 사용하겟다는 뜻인데,
# 이러면 버벅거리니까 (내cpu수 -1) 정도로 사용하자from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()2. 모델 학습하기(훈련 데이터)
rf.fit(x_train, y_train)3. 결과 예측하기(검증 데이터)
y_pred = rf.predict(x_valid)4. 결과 살펴보기
print('랜덤 포레스트, 정확도 : {:.2f}%'.format(accuracy_score(y_valid, y_pred)*100))
5. Feature Importance
feature_importance = pd.DataFrame(rf.feature_importances_.reshape((1, -1)), columns=x_train.columns, index=['feature_importance'])
feature_importance
XGBoost
각 이터레이션에서 맞추지 못한 샘플에 대해 가중치를 부여하여 모델을 학습시키는 부스팅(Boosting) 계열의 트리 모델입니다.
부스팅 알고리즘 자체도 강력하지만, XGBoost는 강력한 병렬 처리 성능과 자동 가지치기(Pruning) 알고리즘이 적용되어 기존 부스팅 알고리즘보다 과적합 방지에 이점이 있습니다.
또한 자체 교차검증 알고리즘과 결측치 자체처리 기능을 가지고 있습니다. 다른 부스팅 알고리즘과 동일하게 균형 트리 분할 방식으로 모델을 학습하여 대칭적인 트리를 형성하게됩니다. (이쁘게 트리모양을 내려고 함)
- Gradient Boosting Model 대비 빠른 수행시간
- 과적합 규제 기능(Regularization)
- 가지치기 기능(Tree pruning)
- 자체 내장 교차 검증 기능
- 결측치 자체 처리(결측치 처리를 하지 않아도 모델 사용 가능)
- Early Stopping 기능
보면 좋은 자료)
XGBoost 대표 파라미터
- n_estimators (int) : 내부에서 생성할 결정 트리의 개수
- max_depth (int) : 생성할 결정 트리의 높이
- learning_rate (float): 훈련량, 학습 시 모델을 얼마나 업데이트할지 결정하는 값
- colsample_bytree (float): 열 샘플링에 사용하는 비율
- subsample (float): 행 샘플링에 사용하는 비율
- reg_alpha (float): L1 정규화 계수
- reg_lambda (float): L2 정규화 계수
- booster (str) : 부스팅 방법 (gblinear / gbtree / dart)
- random_state (int) : 내부적으로 사용되는 난수값
- n_jobs (int) : 병렬처리에 사용할 CPU 수
- objective : loss함수 선택
실습
1. 모델 불러오기 및 정의하기
from xgboost import XGBClassifier
xgb = XGBClassfier(tree_method='gpu_hist')!nvidia-smi # gpu 쓰는지 안쓰는지 보고싶을 때 사용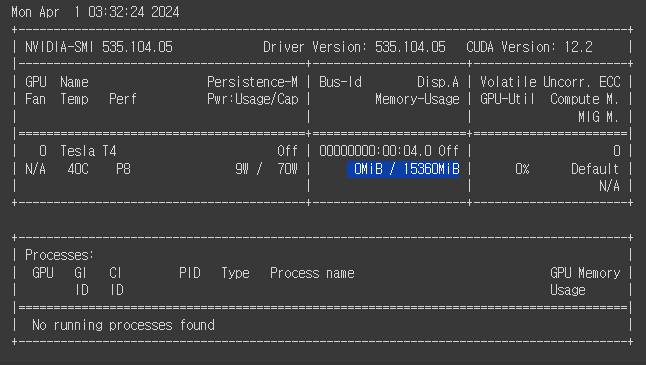 파란색 부분 메모리 확인
파란색 부분 메모리 확인
2. 모델 학습하기(훈련 데이터)
xgb.fit(x_train, y_train)warning ~~ 뜨는데 돌아간다?
-> 곧 버전 바뀌거나 이미 버전이 바뀌어서 다음부터 명령어 바꿔라
!nvidia-smi 다시 쳐보면 메모리 사용량 나온다.
3. 결과 예측하기(검증 데이터)
y_pred = xgb.predict(x_valid)4. 결과 살펴보기
print('XGBoost, 정확도 : {:.2f}%'.format(accuracy_score(y_valid, y_pred)*100))
5. Feature Importance
feature_importance = pd.DataFrame(xgb.feature_importances_.reshape((1, -1)), columns=x_train.columns, index=['feature_importance'])
feature_importance
LightGBM
XGBoost가 기존의 부스팅 트리 모델보다는 학습이 빠르다는 장점이 있지만, 여전히 속도가 느린 알고리즘입니다.
LightGBM은 XGBoost보다 가볍고 더 나은 학습 성능을 제공하며, 더 적은 메모리를 사용합니다.
다른 부스팅 트리와는 다른 특징으로 균형 트리 분할 방식으로 모델을 학습시키는 것이 아닌 리프 중심 트리 분할방식을 사용해 비대칭적인 트리를 형성하게 됩니다.
예측 성능 자체는 XGBoost와 비슷하지만 학습 속도 및 메모리 사용량에서 이점을 갖습니다.
XGBoost의 장점 + XGBoost 보다 가볍고 빠른 모델, 하지만 더 나은 학습 성능
Leaf-wise tree growth (대체적으로 더 나은 성능을 보장하지만, 적은 데이터에서 과적합 우려)
LightGBM 대표 파라미터
- n_estimators (int) : 내부에서 생성할 결정 트리의 개수
- max_depth (int) : 생성할 결정 트리의 높이
- learning_rate (float): 훈련량, 학습 시 모델을 얼마나 업데이트할지 결정하는 값
- colsample_bytree (float): 열 샘플링에 사용하는 비율
- subsample (float): 행 샘플링에 사용하는 비율
- reg_alpha (float): L1 정규화 계수
- reg_lambda (float): L2 정규화 계수
- boosting_type (str) : 부스팅 방법 (gbdt / rf / dart / goss)
- random_state (int) : 내부적으로 사용되는 난수값
- n_jobs (int) : 병렬처리에 사용할 CPU 수
-> 얘는 사용하려면 명령어를 몇개 따로 입력해야한다.
링크 : lightgbm gpu tutorial
실습
1. 모델 불러오기 및 정의하기
from lightgbm import LGBMClassifier
lgb =LGBMClassifier()2. 모델 학습하기(훈련 데이터)
lgb.fit(x_train, y_train)3. 결과 예측하기(검증 데이터)
y_pred = lgb.predict(x_valid) # predict : label로 나옴
y_pred_proba = lgb.predict_proba(x_valid) # proba : 확률로 나오게함4. 결과 살펴보기
print('LightGBM, 정확도 : {:.2f}%'.format(accuracy_score(y_valid, y_pred)*100))
5. Feature Importance
feature_importance = pd.DataFrame(lgb.feature_importances_.reshape((1, -1)), columns=x_train.columns, index=['feature_importance'])
feature_importance
Evaluation
Accuracy, 정확도
모든 데이터에 대해 클래스 라벨을 얼마나 잘 맞췄는지를 계산
Confusion Matrix
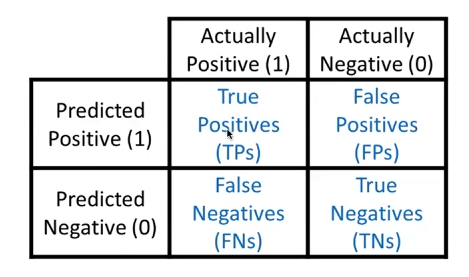
정확도로는 분류 모델의 평가가 충분하지 않을 수 있습니다. 예를 들어, 병이 있는 사람을 병이 없다고 판단하는 경우 Risk가 높기 때문에 모델의 목적에 맞게 분류 모델을 평가하여야 합니다. 이때 사용되는 것이 Confusion Matrix 입니다.
-
Precision, 정밀도 : TP/(FP+TP), 1이라고 예측한 것 중 실제로 1인 것
모델이 1이라고 예측한 것 중에 실제로 1인 것 -
Recall, 재현율 : True Positive rate = Recall = Hit ratio = Sensitivity = TP/(TP+FN), 실제로 1인 것 중에 1이라고 예측한 것
실제로 1인 것 중에 모델이 1이라고 예측한 것, 질병 예측에서 가장 중요한 척도 중 하나, 예측을 잘못하면 사람이 죽을 수도 있기 때문에 -
False Alarm, 오탐 : False Positive rate = 1-Specificity = FP/(FP+TN), 실제로 0인 것 중에 1이라고 예측한 것
이게 코로나 검사에서 안걸렸는데 걸렸다고 하는 경우 입니다. -
F1 Score, 정밀도와 재현율의 조화 평균 : 클래스 불균형한 문제에서 주로 사용되는 평가지표 (클래스가 imbalance 할때 사용하기 좋은 지표. 하지만 맹목적으로 믿으면 안됨)
-> 수식을 외우려고 하지 말고 개념적으로 이해만 하고 있으면 됨 수식은 어차피 함수로 나와있어서 괜찮다.
ROC Curve, AUC
ROC Curve(Receiver-Operating Characteristic curve)는 민감도와 특이도가 서로 어떤 관계를 가지며 변하는지를 2차원 평면상에 표현한 것 입니다.
ROC Curve가 그려지는 곡선을 의미하고, AUC(Area Under Curve)는 ROC Curve의 면적을 뜻합니다.
AUC 값이 1에 가까울 수록 좋은 모델을 의미합니다.
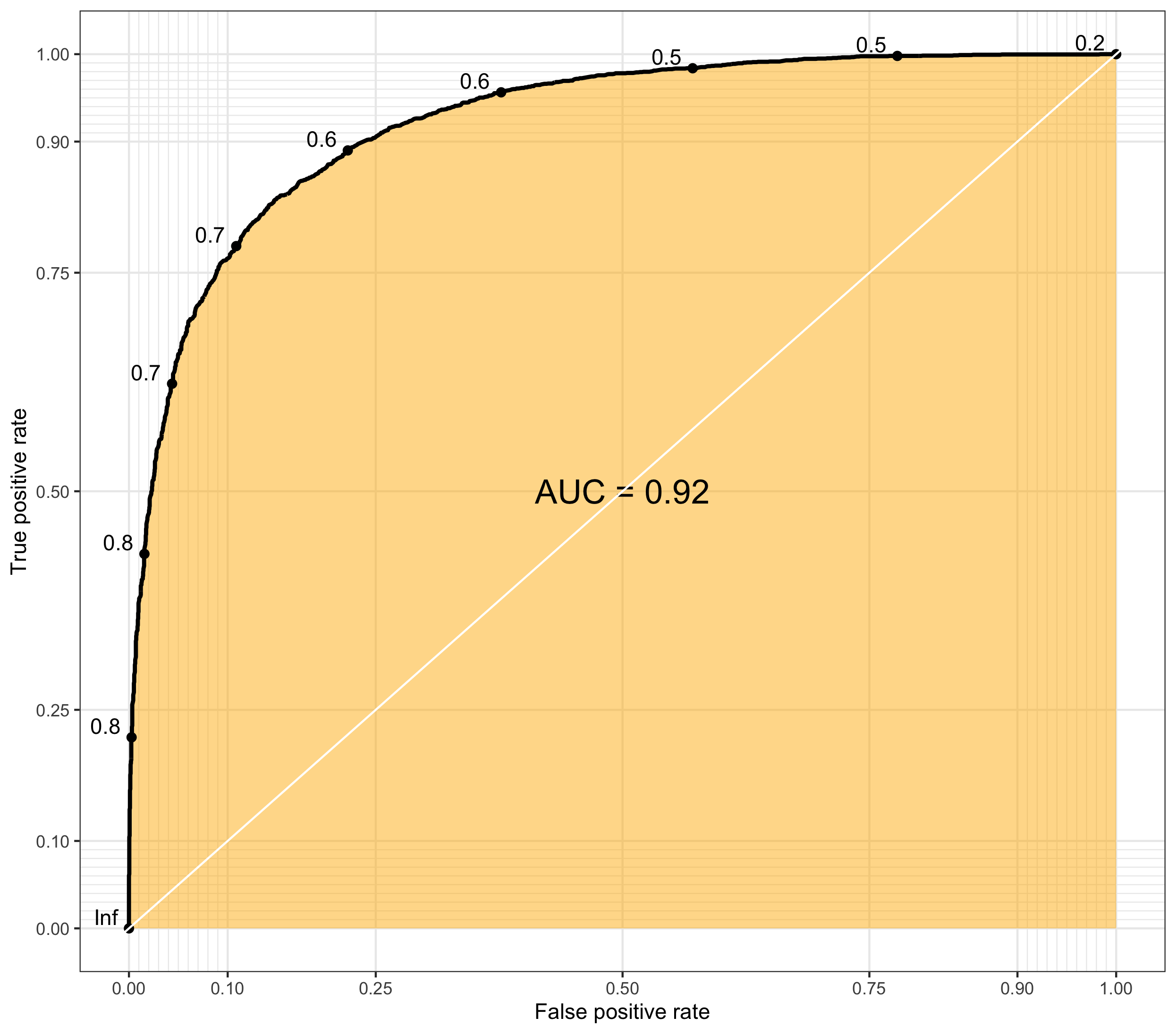
- 클래스가 불균형한 데이터인 경우 정확도로 모델의 성능을 판단하는건 적절하지 않습니다.
- 이러한 경우에는 정밀도나 재현율 또는 정밀도와 재현율의 조화 평균인 F1 Score를 사용하기도 합니다.
- 이러한 경우에는 정밀도나 재현율 또는 정밀도와 재현율의 조화 평균인 F1 Score를 사용하기도 합니다.
- 이진 분류인 경우 확률을 사용해서 평가하는 메트릭은 확률 값이 아닌 라벨을 제출하지 않도록 주의해야한다.
- 다중 분류에서는 라벨을 제출할 때 에러를 발생시키지만, 이진 분류에서는 라벨을 제출하면 에러를 발생시키지 않는다.
실습
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, f1_score, log_lossprint('Accuracy : {:.3f}'.format(accuracy_score(y_valid, y_pred)))
print('Precision : {:.3f}'.format(precision_score(y_valid, y_pred)))
print('Recall : {:.3f}'.format(recall_score(y_valid, y_pred)))
print('F1 Score: {:.3f}'.format(f1_score(y_valid, y_pred)))
print('AUC : {:.3f}'.format(roc_auc_score(y_valid, y_pred_proba[:, 1])))
print('Log Loss : {:.3f}'.format(log_loss(y_valid,y_pred_proba[:, 1])))
# 이렇게 하지 않도록 주의
# roc_auc_score(y_valid, y_pred)
