오늘 리뷰할 논문은 ALBERT 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- nlp ALBERT 논문 정리(논문 리뷰) - A Lite BERT for Self-supervised Learning of Language Representations
- [논문리뷰] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- [논문리뷰] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Summary
natural language representations를 pretraining할 때 model 크기를 키우면 downstream task 성능이 향상되지만 메모리 한계와 긴 학습시간이라는 한계가 존재한다. 이 문제를 해결하고자 논문은 메모리 소모를 줄이고 BERT의 학습 속도를 향상시키는 두 parameter-reduction techniques를 제안한다. 또 inter-sentence coherence를 모델링하는 데 self-supervised loss를 사용했고 이는 multi-sentence inputs를 가진 downstream tasks에 도움이 됐다. 결과적으로 BERT-large보다 적은 parameter로 GLUE, RACE, SQuAD benchmarks에서 SOTA를 달성했다.
큰 모델을 pre-train하고 더 작은 모델로 distillation하는 것이 관행이 되었다. 논문은 더 좋은 NLP 모델을 얻는 게 더 큰 모델을 다루는 것만큼 쉬운가?라는 질문을 던진다. 논문은 memory limitation과 training speed라는 문제들을 해결하기 위해 BERT보다 적은 parameter를 사용하는 A Lite BERT (ALBERT)를 디자인한다.
ALBERT는 두 parameter reduction techniques를 사용해 pre-trained models를 scaling하는 두 문제점을 다룬다. 첫째는 factorized embedding parameterization로, large vocabulary embedding matrix를 두 개의 작은 matrix로 분해해 hidden layers의 크기를 vocabulary embedding의 크기에서 분리한다. 이 분리는 vocabulary embedding의 parameter size의 큰 증가 없이 hidden size를 키우기 쉽게 해준다. 둘째는 cross-layer parameter sharing로, network 깊이에 따라 parameter가 많아지는 것을 방지한다. 두 방법 모두 성능의 심각한 손상 없이 BERT의 parameter 수를 상당히 줄여준다. ALBERT는 BERT-large 보다 18배 적은 parameter를 가지면서 1.7배 빠르게 학습한다. 이 prameter reduction techniques는 regularization처럼 작동해 학습을 안정화하고 일반화를 돕는다.
ALBERT의 성능을 더 높이기 위해 sentence-order prediction (SOP)에 대한 self-supervised loss도 도입한다. SOP는 inter-sentence coherence에 집중하며 원본 BERT의 NSP loss의 비효율성 때문에 Yang et al.에서 디자인했다.
SOP loss는 Jernite et al. (2017)의 sentence ordering objective와 가장 비슷한데 이는 두 연속적인 문장의 순서를 맞추도록 sentence embeddings를 학습하는 것이다. 반면 SOP loss는 문장 대신 textual segments에 정의된다.
ALBERT architecture의 backbone은 GELU nonlinearities를 가진 Transformer encoder를 사용한다는 점에서 BERT와 비슷하다. BERT의 표기법을 따라 vocabulary embedding size를 E, encoder layers의 수를 L, hidden size를 H라 하고 Devlin et al. (2019)을 따라 feed-forward/filter size를 4H로 attention heads의 수를 H/64로 설정했다.
BERT와 다른 ALRBERT의 세 가지 주요 design choice는 다음과 같다.
- Factorized embedding parameterization
BERT, XLNet, RoBERTa 등은 WordPiece embedding size E와 hidden layer size H가 동일하다. 즉 E ≡ H이다. 이는 modeling과 실용적인 이유, 둘 다에서 suboptimal하다.
modeling 관점에서, WordPiece embeddings는 context-independent representations를 배워야 하는 반면 hidden-layer embeddings는 context-dependent representations를 배워야 한다. context length와 관련된 (Liu et al., 2019)의 실험이 BERT-like representations의 능력이 context-dependent representations를 학습하기 위한 신호를 제공하는 context의 사용에서 온다고 한다. 이와 같이 WordPiece embedding size E를 hidden layer size H에서 untie하는 것은 전체 parameter를 더 효율적으로 사용할 수 있다. 즉 H≫E이다.
실용적인 이유로 NLP는 보통 vocabulary size V가 클 것을 요구한다. E ≡ H면 H의 증가가 V × E 크기인 embedding matrix의 크기도 증가시켜 너무 많은 parameter를 가지게 한다.
따라서 ALBERT는 embedding paramters의 factorization을 사용해서 embedding parameters를 두 개의 작은 matrix로 분해한다. one-hot vectors를 크기 H의 hidden space에 곧장 project하는 대신 먼저 크기 E의 lower dimensional embedding space에 project하고 나서 hidden space로 project한다. 이 분해를 통해 embedding parameters를 O(V × H)에서 O(V × E + E × H)로 줄인다. 이 parameter reduction은 특히 H≫E일 때 효과적이다.
- Cross-layer parameter sharing
parameter를 공유하는 방법은 여러 가지가 있다. ALBERT의 디폴트 설정은 layers에 걸쳐 모든 parameter를 공유하는 것이다. 따로 명시하지 않는 이상 모든 실험에서 디폴트 설정을 사용한다.
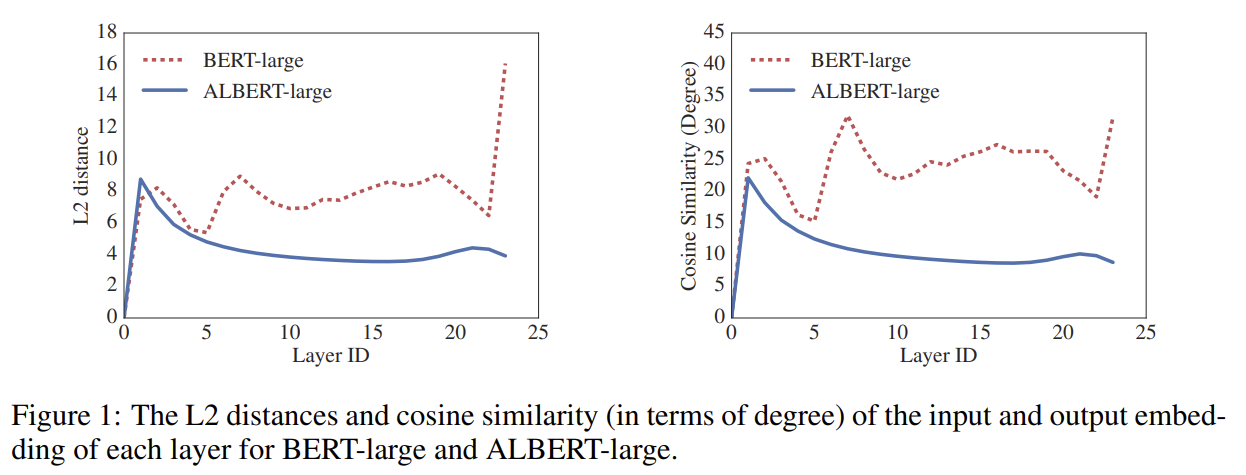
Fig 1은 각 layer에서 input과 output embedding의 L2 distance와 cosine similarity를 보여준다. BERT보다 ALBERT에서 더 매끄러운 변화가 관찰되며 이는 weight-sharing이 network parameters를 안정화하는 작용이 있음을 보여준다.
- Inter-sentence coherence loss
BERT는 masked language modeling (MLM) loss뿐 아니라 추가적인 next-sentence prediction (NSP) loss도 사용한다. NSP는 이후 연구들에서 비효율적이라고 밝혀지는데, 논문은 그 원인이 MLM에 비해 task로써 난이도가 낮기 때문으로 본다. NSP는 topic prediction와 coherence prediction를 융합했지만 topic prediction은 coherence prediction보다 배우기 쉽고 MLM loss로 배운 것과 많이 겹친다.
논문은 inter-sentence modeling가 언어 이해의 중요한 측면이라는 점은 유지하지만 대신 coherence에 기반한 loss를 제안한다. ALBERT는 topic prediction을 피하고 대신 inter-sentence coherence를 modeling하는 sentence-order prediction (SOP) loss를 사용한다. SOP loss는 positive example로 BERT와 같은 기술(같은 document에서 온 두 연속적인 segments)을 사용하고 negative example로 순서만 바뀐 동일한 두 연속적인 segments를 사용한다. 이는 모델이 discourse-level coherence properties에 대한 세세한 구분(finer-grained distinctions)을 배우게 한다. 이후 실험에서 나오지만 NSP는 SOP task를 아예 풀지 못하고 SOP는 (추측건대 misaligned coherence cues의 분석을 기반으로) NSP를 어느 정도 풀 수 있다. 결과적으로 ALBERT는 multi-sentence encoding tasks에서 downstream task 성능이 향상됐다.

Tab 1은 BERT와 ALBERT의 hyperparameter를 비교한 것이다. 위의 design choice 덕분에 ALBERT는 BERT보다 parameter가 훨씬 적다.
(EXPERIMENTAL SETUP 생략)
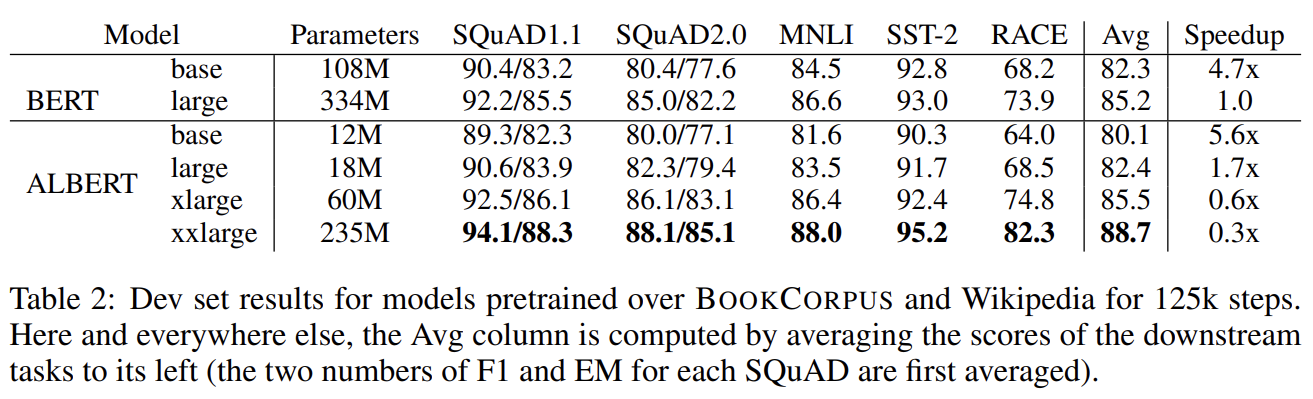
ALBERT-xxlarge는 BERT-large의 paramter 수의 70% 정도만으로도 상당한 성능 향상을 보인다.
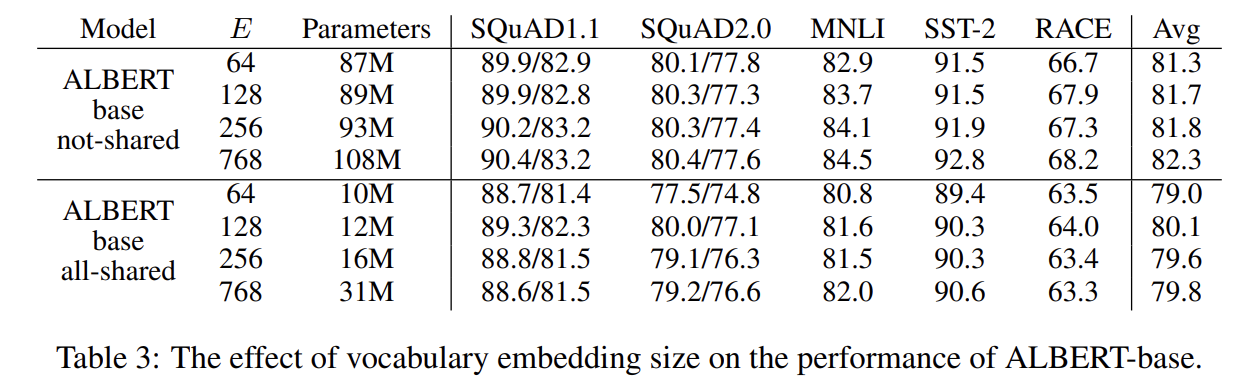
Tab 3는 vocabulary embedding size E의 효과를 보여준다. non-shared condition (BERT-style)는 E가 클수록 성능이 좋아지지만 향상이 그리 크진 않았다. all-shared condition (ALBERT-style)는 128에서 성능이 가장 좋았다.
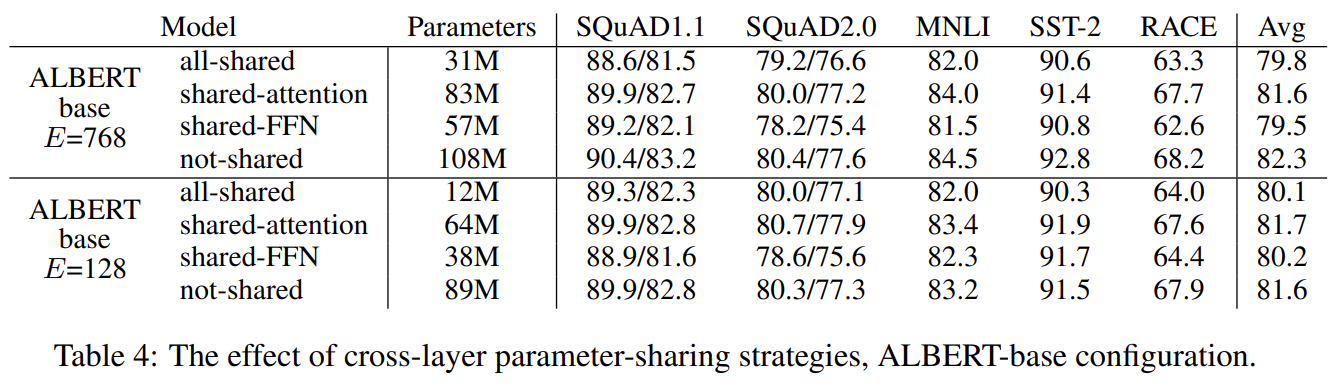
Tab 4는 두 embedding size에서 다양한 cross-layer parameter-sharing strategies를 비교한다. all-shared strategy (ALBERT-style)와 not-shared strategy (BERT-style)와 (FNN 말고) attention parameters만 공유하거나 (attention 말고) FFN parameters만 공유한 intermediate strategies를 비교했다. all-shared strategy는 두 경우 모두 성능을 감소시키지만 E=128일 때가 768일 때보다 덜했다. 추가로 대부분의 성능 저하는 FFN-layer parameters 공유에서 왔고 attention parameters의 공유는 E=128에서 성능이 약간 향상됐고 768에서 성능이 약간 저하됐다. all-shared strategy를 default choice로 선택했다.

ALBERT-base 설정에서 none (XLNet- and RoBERTa-style), NSP (BERT-style), SOP (ALBERT-style)를 비교한다. NSP는 SOP task에 대해 random-guess performance나 다름없는 52%의 정확도를 보여 SOP에 대한 discriminative power가 없었다. 이는 NSP가 topic shift만을 modeling함을 보여준다. 반면 SOP는 NSP task를 78.9% 정확도로 상대적으로 잘 처리했다. 또한 multi-sentence encoding tasks에서 downstream task performance가 향상됐다.

data throughput (number of training steps)를 조절하는 대신 실제 training time을 조절했다. ALBERT-xxlarge가 BERT-large보다 잘 작동했다.

지금까지 실험들은 원본 BERT 논문처럼 Wikipedia와 BOOKCORPUS datasets만 사용했다. 이번엔 XLNet (Yang et al., 2019)와 RoBERTa (Liu et al., 2019)에서 사용한 추가적인 dataset의 영향을 실험했다. Wikipedia에 기반한 SQuAD benchmark를 제외하고 성능 향상이 있었다.

1M steps이 지나고도 largest models는 여전히 overfit되지 않았기 때문에 dropout을 제거해 실험하니 성능이 향상됐다. 저자들이 아는 한 large Transformer-based models에서 dropout이 성능을 저하시키는 걸 최초로 보였다. 그러나 ALBERT의 구조는 Transformer의 특수한 경우고 이 현상이 다른 transformer-based architectures에서도 동일한지는 향후 실험이 필요하다.
Strengths
- Factorized embedding parameterization과 Cross-layer parameter sharing으로 BERT보다 parameter 수를 확연히 줄였다.
- NSP loss 대신 Inter-sentence coherence loss인 SOP를 사용해 downstream task 성능을 향상시켰다.
Weaknesses
- ALBERT-xxlarge가 BERT-large보다 parameter가 적고 성능도 좋지만 larger structure 때문에 computationally expensive하다.
