오늘 리뷰할 논문은 XLNet 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] XLNet: Generalized Autoregressive Pretraining for Language Understanding
- [NLP 논문 리뷰] Xlnet: Generalized Autoregressive Pretraining for Language Understanding
- 트랜스포머 기반 자연어처리 모델 간략하게 훑어보기
Summary
BERT처럼 bidirectional context를 modeling하는 denoising autoencoding based pretraining은 autoregressive language modeling 방식보다 더 잘 작동하지만 input을 mask로 오염시키는 데 기반하기 때문에 BERT는 masked positions 간의 dependency를 무시하게 되고 pretrain-finetune discrepancy 문제를 겪는다. 이러한 장단점을 고려해 논문은 generalized autoregressive pretraining method인 XLNet을 제안한다. XLNet은 (1) 모든 factorization order의 순열의 expected likelihood를 최대화하여 bidirectional context를 학습하고 (2) autoregressive formulation 덕분에 BERT의 한계를 극복한다. 또한 XLNet은 SOTA autoregressive model인 Transformer-XL의 아이디어를 pretraining으로 통합한다.
autoregressive (AR) language modeling와 autoencoding (AE)는 가장 성공적인 두 개의 pretraining objectives이다. AR language modeling은 autoregressive model을 통해 text corpus의 probability distribution을 추정하며, text sequence 가 주어질 때 likelihood를 forward product 나 backward product 를 factorize한다. AR language model은 uni-directional context (either forward or backward)에만 학습되기 때문에 deep bidirectional contexts를 modeling하는 데는 효과적이지 않다. 반면 downstream language understanding tasks는 자주 bidirectional context information를 필요로 하기 때문에 AR language modeling과 효과적인 pretraining 사이 불일치가 발생하게 된다.
반면 AE based pretraining는 명시적인 density estimation을 하지 않고 대신 corrupted data로부터 original data를 재구성한다. 대표적으로 BERT는 input의 일부를 [MASK] token으로 바꿔 original token을 복구하고, density estimation이 objective의 일부가 아니기 때문에 BERT는 bidirectional context를 사용할 수 있다. 그러나 pretraining 중에 사용된 [MASK] 같은 인위적인 symbol은 finetuning time의 실제 데이터에 존재하지 않기 때문에 pretrain-finetune 불일치를 발생시킨다. 또 predicted tokens가 input에서 mask되어있기 때문에 BERT는 AR처럼 product rule을 사용해 joint probability를 model할 수 없다. 다시 말해 BERT는 주어진 unmasked tokens와 predicted tokens가 독립적이라고 가정하는데, 이는 high-order, long-range dependency가 만연한 실제 자연어와 다르다.
그래서 논문은 AR language modeling과 AE의 장점은 취하면서 한계는 피하는 XLNet을 제안한다.
- 기존 AR models의 fixed forward/backward factorization order를 사용하는 대신 XLNet은 "all possible permutations of the factorization order"에 대한 sequence의 expected log likelihood를 최대화한다. permutation operation 덕분에 각 position의 context는 좌우 양쪽에서 tokens을 포함할 수 있다. 각 position이 모든 position에서의 contextual information을, 즉 bidirectional context를 포착할 것이 기대된다.
- generalized AR language model로써 XLNet은 data corruption에 의존하지 않고 따라서 pretrain-finetune discrepancy를 겪지 않는다. 한편 autoregressive objective는 predicted tokens의 joint probability를 factorize하기 위한 product rule을 사용할 자연스러운 방법을 제공하고 (BERT와 같은) independence assumption를 제거한다.
새로운 pretaining objective에 더불어 XLNet은 pretraining을 위한 architectural design도 향상한다.
- AR language modeling의 최근 발전에서 영감을 받아 XLNet은 Transformer-XL [9]의 segment recurrence mechanism과 relative encoding scheme을 pretraining에 포함시켜 (특히 longer text sequence를 가진 tasks에 대한) 성능을 향상시킨다.
- permutation-based language modeling에 Transformer(-XL) architecture를 naively 적용하는 것은 통하지 않는데 factorization order가 임의적이고 target이 모호하기 때문이다. 논문은 해결책으로 Transformer(-XL) network를 reparameterize해서 모호성을 제거한다.
- Objective: Permutation Language Modeling
orderless NADE [32]의 아이디어를 빌려 논문은 AR 모델의 장점은 취하고 bidirectional context를 포착하는 permutation language modeling objective를 제안한다. length T의 sequence x에 대해 유효한 autoregressive factorization을 수행하는 데 T!의 서로 다른 순서가 존재한다. 직관적으로 생각할 때 model parameters가 모든 factorization orders에 걸쳐 공유되면 모델이 모든 position에서 좌우 양쪽의 정보를 학습한다고 기대할 수 있다. 를 length-T index sequence [1, 2, . . . , T]의 모든 가능한 permutation의 집합으로 두자. 는 permutation 의 t-th element와 first t−1 element를 의미한다. permutation language modeling objective는 다음과 같다.
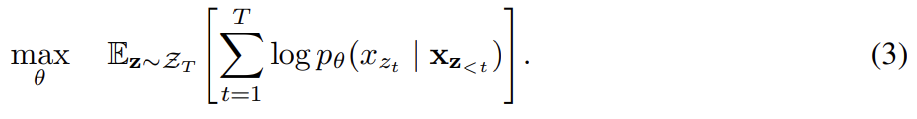
text sequence x에 대해 factorization order z를 sample하고
likelihood pθ(x)를 factorization order에 따라 decompose한다. model parameter θ가 모든 factorization order에 걸쳐 공유되기 때문에 x_t는 sequence 내의 모든 가능한 element 를 만나봤으므로 bidirectional context를 포착할 수 있다. 또 이 objective가 AR famework에 들어맞기 때문에 자연스럽게 independence assumption과 pretrain-finetune discrepancy를 피한다.
permutation이 sequence order이 아니라 factorization order만 순회한다. 다시 말해 sequence order은 유지하고, original sequence에 상응하는 positional encoding을 사용하고, factorization order의 permutation을 얻기 위해 Transformer 내의 적절한 attention mask에 의존한다.
- Architecture: Two-Stream Self-Attention for Target-Aware Representations
permutation language modeling objective은 원하는 특징을 지녔지만, 일반적인 Transformer parameterization을 가지고 한 naive implementation는 통하지 않을 수 있다. (중략) representation 가 예측하는 위치(=value of )에 의존하지 않으므로 target position에 관계없이 같은 distribution을 예측해서 유용한 representation을 배울 수 없다. 이 문제를 해결하기 위해 논문은 target position aware하도록 next-token distribution을 다음과 같이 re-parameterize한다.
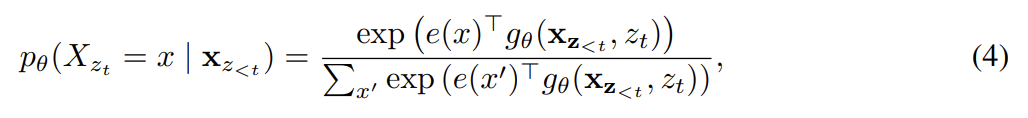
는 target position 를 추가적인 input으로 받는 새로운 종류의 representation이다.
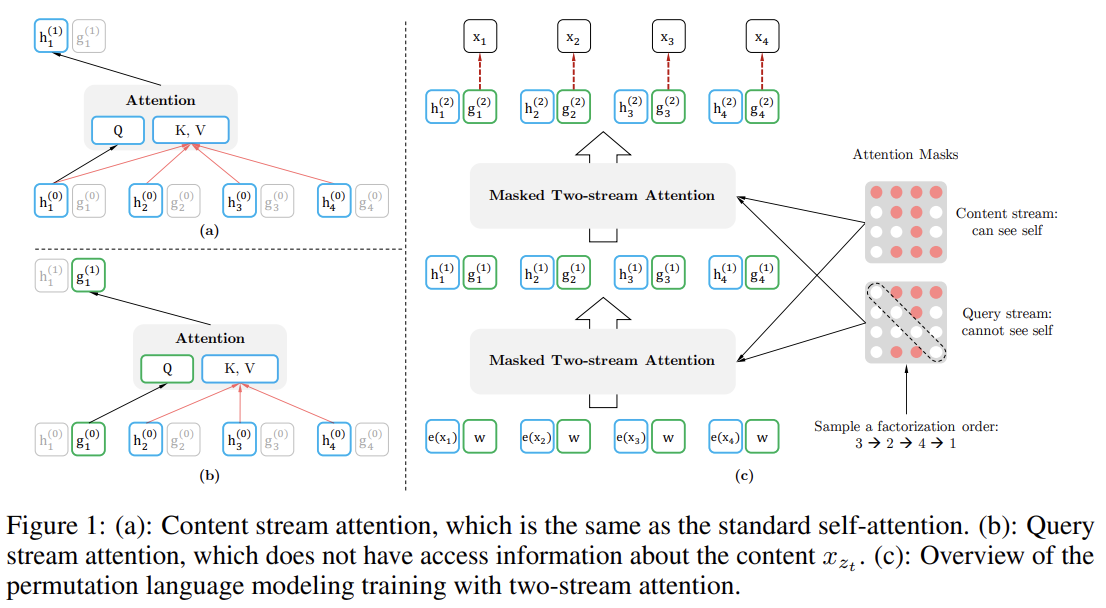
- Two-Stream Self-Attention
target-aware representation 발상이 target prediction의 모호성을 제거하지만 이제 를 어떻게 formulate할 건지가 문제가 된다. 논문은 target position 에 "stand"해서 attention을 통해 context 로부터 정보를 모으는 방법을 제안한다. 이 parameterization이 통하려면 기존 Transformer architecture와 모순되는 두 가지 요구사항이 있는데, (1) token 를 예측하려면 가 position 만 사용하고 content 를 사용하면 안되고 (그렇지 않으면 objective가 trivial해지니까) (2) 다른 token 를 예측하려면 full contextual information을 제공하기 위해 가 content 도 encode해야 한다.
이 모순을 해결하기 위해 논문은 하나 대신 two sets of hidden representations를 사용할 것을 제안한다.
- Transformer의 standard hidden state와 비슷한 역할을 하는 content representation . 이 representation은 context와 그 자신을 둘 다 encode한다.
- contextual information 와 position 는 접근 가능하지만 content 는 불가능한 query representation
first layer query stream은 trainable vector로 초기화되고(즉 이고) content stream은 상응하는 word embedding으로 설정된다(즉 ). Fig 1에서 볼 수 있듯 각 self-attention layer m=1,...,M에 대해 two streams of representation은 공유하는 parameters를 가지고 다음과 같이 schematically update된다.
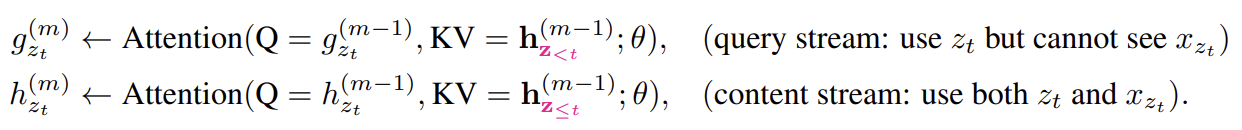
content representation의 update 규칙은 일반적인 self-attention과 동일하다. 따라서 finetuning 중에 단순히 query stream을 drop하고 content stream을 일반적인 Transformer(-XL)로 사용하면 된다. 마지막으로 식 (4)를 계산하기 위해 last-layer query representation 를 사용한다.
- Partial Prediction
permutation language modeling objective (3)이 여러 장점이 있지만 permutation으로 인해 optimization 문제가 더 어렵고 느린 수렴을 초래한다. optimization 난이도를 낮추기 위해 논문은 factorization order 내 마지막 token만 예측하도록 했다. 구체적으로는 c가 cutting point일 때 non-target subsequence 와 target subsequence 로 z를 분할했다. objective는 다음과 같이 non-target subsequence에 condition된 target subsequence의 log-likelihood를 최대화하는 것이다.
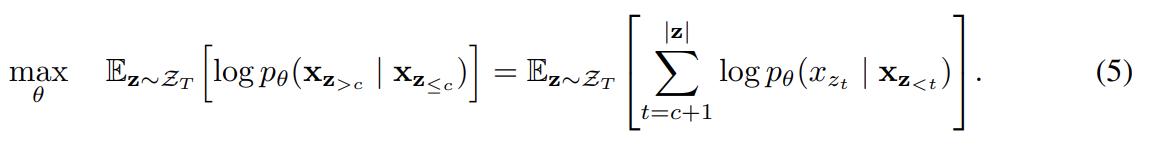
current factorization order z가 주어졌을 때 가 sequence 내에 가장 긴 context를 보유하기 때문에 가 target으로 선택된 것에 유의하라. hyperparameter K는 1/K tokens가 prediction을 위해 선택되도록 사용된다(즉, |z|/(|z| − c) ≈ K). unselected tokens에 대해서는 그들의 query representations가 계산될 필요가 없고 speed와 memory를 절약할 수 있다.
- Incorporating Ideas from Transformer-XL
objective이 AR framework에 맞기 때문에 SOTA AR language model인 Transformer-XL를 우리의 pretraining framework에 넣고 이름을 XLNet이라고 지었다. Transformer-XL의 두 가지 중요한 기술을 포함하는데, relative positional encoding scheme과 segment recurrent mechanism이다. 앞서 설명했듯 original sequence에 기반해 relative positional encoding을 적용한다. 이제 proposed permutation setting에 어떻게 recurrence mechanism을 통합해서 model이 previous segment로부터 hidden state를 재사용할 수 있게 할지 설명하겠다.
일반성을 잃지 않고 long sequence s에서 두 segments 를 얻었다고 하자. 가 각각 [1 · · · T]와 [T + 1 · · · 2T]의 permutation이라고 하자. 그러면 permutation 에 기반해 first segment를 처리하고 각 layer m에 대해 얻어진 content representations 를 cache한다. 그리고 다음 segment x에 대해 attention update with memory는 다음과 같다.
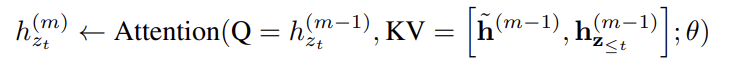
[.,.]는 sequence dimension을 따라(along) concatenation한 것이다. positional encoding이 original sequence 내의 실제 position에만 의존한다는 것에 주의해라. 따라서 위의 attention update는 representations 이 얻어진 이상 와 독립적이다. 이는 previous segment의 factorization order을 모르고도 caching과 reusing memory를 가능하게 한다. 모델이 last segment의 모든 factorization order를 걸쳐(over) memory를 활용하도록 학습할 것을 기대할 수 있다. query stream도 같은 방법으로 계산될 수 있다.
- Modeling Multiple Segments
많은 downstream tasks가 muliple input segments를 필요로 한다. XLNet은 어떻게 multiple segments를 model하는지 알아보자. BERT처럼 XLNet은 pretraining phase 중에 (같은 context에서나 다른 context에서나) 두 segments를 랜덤하게 sample하고 (permutation language modeling을 수행하기 위해) 둘을 concatenate해서 하나의 sequence로 취급한다. 같은 context에 속하는 memory만 재사용한다. input은 BERT와 같이 [CLS, A, SEP, B, SEP] 형식이고 SEP, CLS는 special token이고 A, B는 두 segment다. 논문이 two-segment data format를 따르지만 XLNet-Large는 (이후 나올 ablation study에서) 일관적인 향상을 보이지 않기 때문에 next sentence prediction [10] objective를 사용하지 않는다.
- Relative Segment Encodings
각 position에서 absolute segment embedding을 word embedding에 더하는 BERT와 달리 Transformer-XL의 relative encoding 아이디어를 확장해 segments도 encode하게 했다. sequence 내의 position i, j에 대해 i와 j가 같은 segment에서 왔다면 segment encoding 를 사용하고 그렇지 않다면 를 사용했다. 는 각 attention head에 대한 learnable model parameters이다. 즉 두 position이 어떤 특정 segment에서 왔는지가 아니라 둘이 같은 segment에 있는지만 고려한다는 것이다. 이는 relative encoding의 핵심 아이디어인 "only modeling the relationships between positions"와 일관적이다. i가 j를 attend할 때 attention weight 를 연산하기 위해 segment encoding 가 사용된다(qi는 일반적인 attention operation처럼 query vector고 b는 learnable head-specific bias vector). 마지막으로 value 가 normal attention weight에 더해진다. relative segment encoding의 장점은 두 가지다. 첫째로 relative encoding의 inductive bias은 generalization [9]를 향상시킨다. 둘째로 (absolute segment encoding으로는 불가능한) input segment가 두 개보다 많은 task에 대한 finetuning의 가능성을 열어준다.
(2.6 Discussion 생략)
pretraining을 위한 데이터셋으로는 BERT를 따라 BooksCorpus [40]와 English Wikipedia를 사용하고 추가로 Giga5 (16GB text) [26], ClueWeb 2012-B (extended from [5]), Common Crawl [6]도 사용한다.
가장 큰 모델인 XLNet-Large는 BERT-Large와 동일한 architecture hyperparmeter을 가져 비슷한 모델 크기를 가진다. pretraining 중에 항상 full sequence length 512를 사용했다. BERT와 공평한 비교를 위해 처음에는 모든 pretrainig hyperparameter를 원본 BERT처럼 설정하고 BooksCorpus와 Wikipedia 데이터셋으로만 학습한 XLNet-Large-wikibooks을 만들고 그 다음에 모든 데이터셋을 사용해서 XLNet-Large로 학습했다.
recurrence mechanism이 도입됐기 때문에 각 forward/backward directions이 batch size의 절반씩을 차지하는 bidirectional data input pipeline를 사용했다. XLNet-Large를 학습할 때 partial prediction constant K를 6으로 두었다. span-based prediction 아이디어를 적용해 먼저 length L ∈ [1, · · · , 5]를 sample하고 그 다음 (KL) tokens의 context 내에서 prediction targets로 consecutive span of L tokens를 랜덤하게 선택했다.
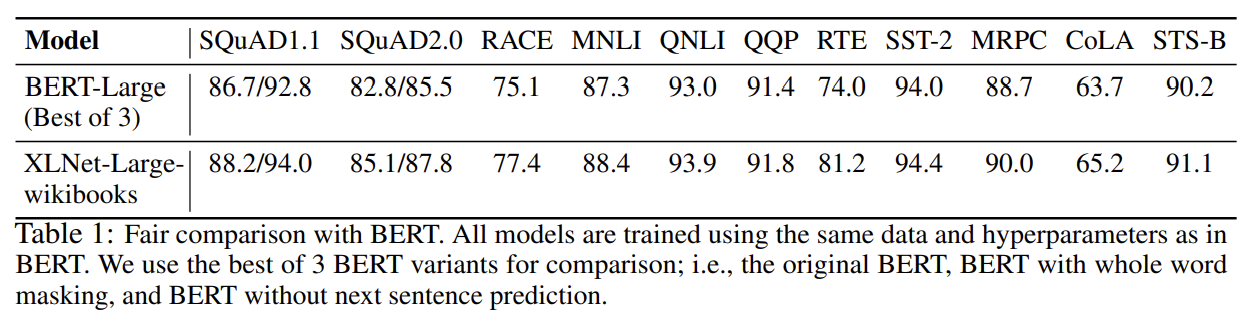
먼저 BERT와 XLNet을 공평한 세팅과 동일한 학습 데이터셋으로 비교한 결과 XLNet이 BERT보다 모든 데이터셋에서 outperform했다.
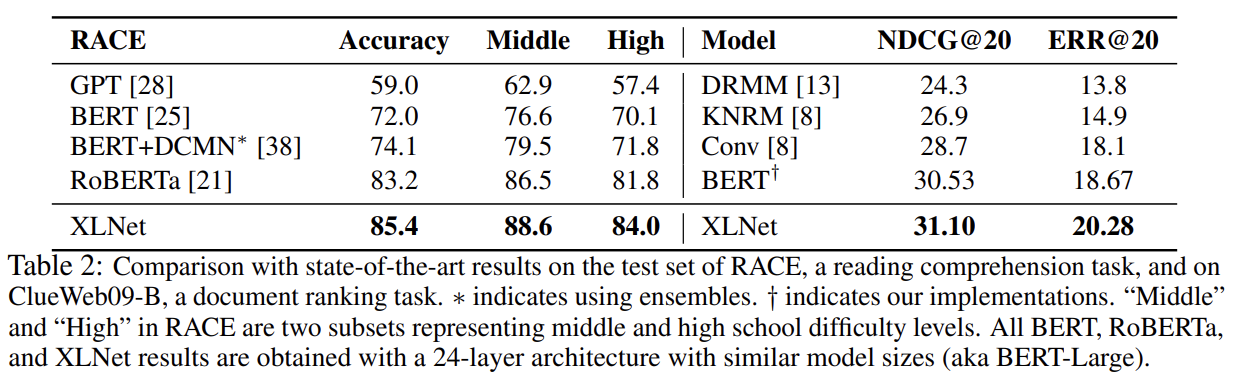
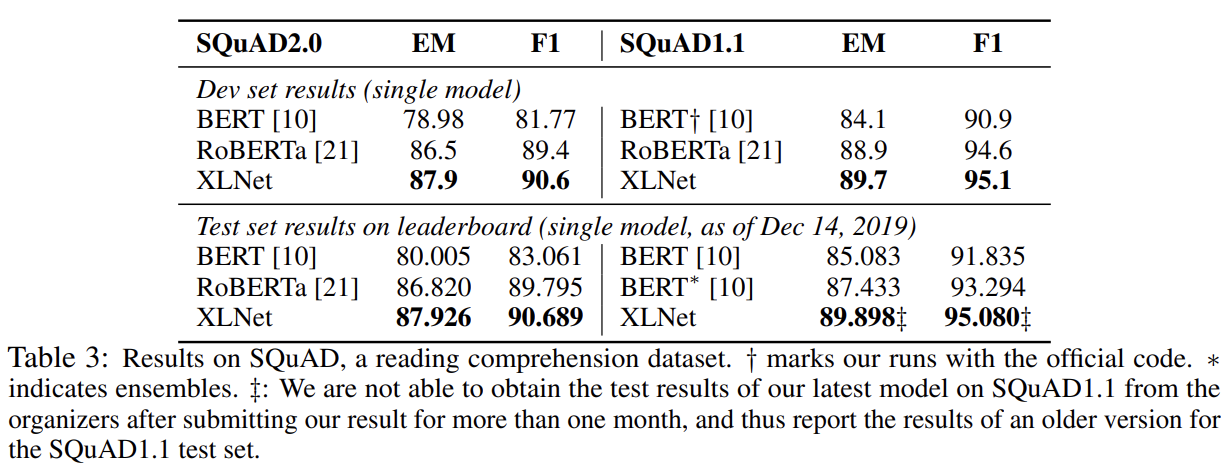
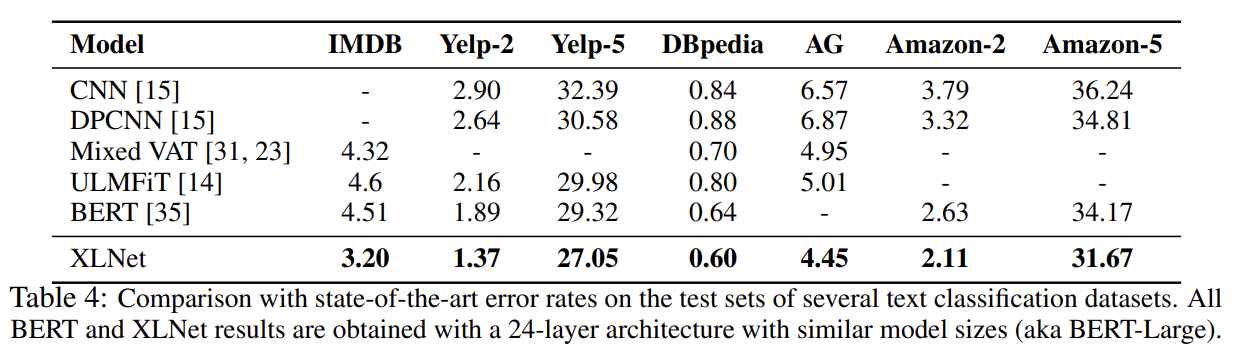
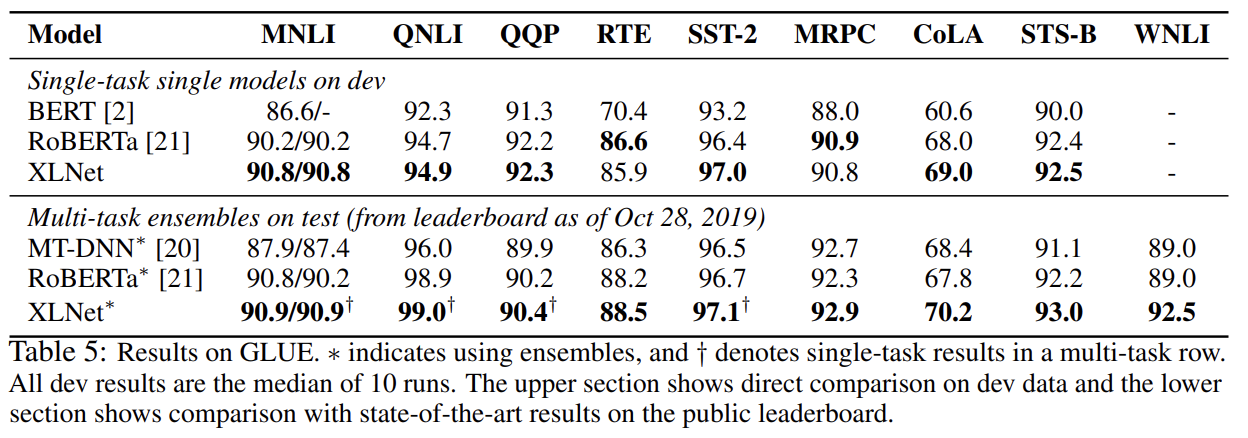
다음으로 RoBERTa와 비교하는데 공평한 비교를 위해 모든 데이터셋을 사용하고 RoBERTa의 hyper-parameter을 따라한다. XLNet이 일반적으로 BERT와 RoBERTa보다 성능이 좋았다. longer context를 지닌 SQuAD나 RACE 같은 explicit reasoning tasks에서 XLNet의 performance gain이 더 컸다. longer context를 다루는 우수성은 Transformer-XL backbone에서 왔을 것이다. MNLI, Yelp, Amazon처럼 supervised exmamples가 풍부한 classification tasks에 대해서도 XLNet이 여전히 상당한 gain을 얻었다.
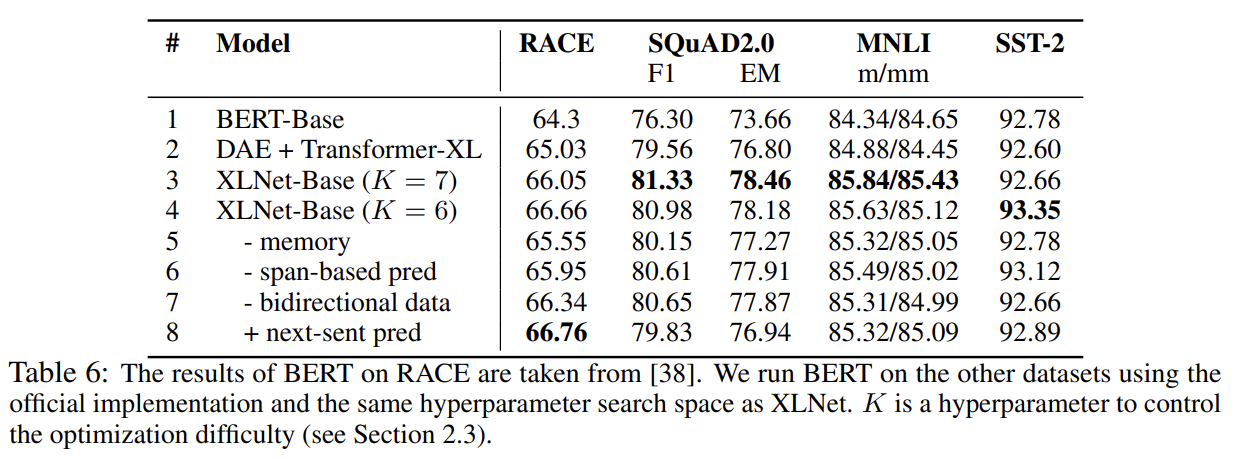
각 design choice의 중요성을 이해하고자 ablation study를 한다. 알고자 하는 세 가지 주요 측면은 다음과 같다.
- (특히 BERT의 denoising auto-encoding objective와 비교했을 때) permutation language modeling objective 자체의 효과
- Transformer-XL를 backbone neural architecture로 사용한 중요성
- span-based prediction, bidirectional input pipeline, next-sentence prediction와 같은 implementation detail의 필수성
Tab 6의 1-4행을 보면 Transformer-XL와 permutation LM이 모두 성능에 기여함을 알 수 있다. 또 5행에서 memory caching mechanism을 제거하면 성능이 하락했다. 6-7행은 span-based prediction와 bidirectional input pipeline이 둘 다 XLNet에 중요한 역할을 함을 보여준다. 마지막으로 원본 BERT에서 제안된 next-sentence prediction objective이 우리의 세팅에서 성능 향상을 일으키지 않는다는 사실을 의도치 않게 발견했다. 따라서 XLNet에서 NSP objective를 제외했다.
Strengths
- AR language modeling이 uni-directional context만 사용하는 단점과 AE의 independence assumption과 pretrain-finetune discrepancy라는 단점을 모두 피한다.
- permutation language modeling objective로 모든 가능한 token 순서 조합을 학습시켜 bidirectional context를 학습 가능하게 했다. Permutation을 사용한 AR pretraining 방식을 개척했다는 점에서 의의가 있다.
별개로 다른 논문에서도 BERT의 NSP가 필요없다는 내용을 봤는데 여기서도 또 나온 걸 보니 NSP objective는 별로 효과가 없는 것 같다.
Two-Stream Self-Attention 부분 설명이 헷갈렸는데 여기에 설명을 잘 해놨다. Content Representation (h)는 기존 Transformer의 hidden state와 동일하며 context에 현재 시점(t)의 정보까지() 포함해 입력으로 받아 Key, Value에 사용한다. Query Representation (g)는 context에 현재 시점(t)의 정보()는 제외하고 대신 현재 시점(t)의 위치 정보()는 입력으로 받아 Query에 사용한다.
