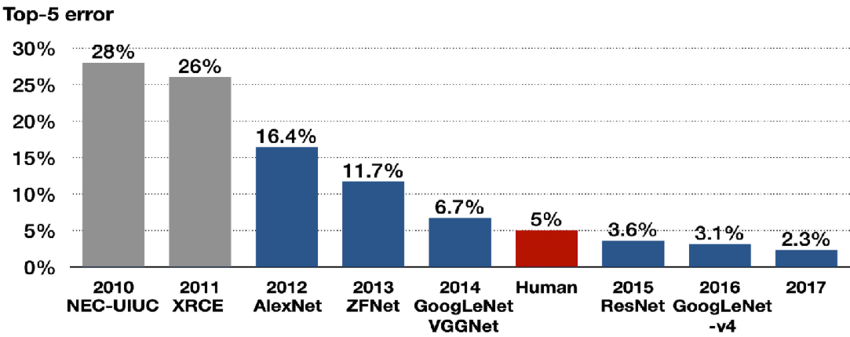
이번에 리뷰할 논문은 ILSVRC15에서 우승한 ResNet 논문이다. ResNet은 무려 152 layer으로 VGGNet보다 약 8배 더 깊은데, 이게 가능한 것은 ResNet이 residual block이라는 구조를 사용했기 때문이다. 이런 residual network는 optimize도 쉽고 증가한 깊이에서 accuracy를 향상시킬 수 있다고 한다.
아래의 포스트들을 먼저 읽으면 도움이 될 것이다.
Summary
깊은 neural network일수록 train이 어렵다. vanishing/exploding gradients 문제가 학습을 방해하기 때문이다. normalized initialization과 intermediate normalization layers를 사용해서 SGD 역전파를 하면 10층짜리 network까지는 문제가 없었다.
그런데 더 깊은 network가 converge하기 시작하면 degradation 문제가 발생한다. degradation은 네트워크의 깊이가 증가할수록 accuracy가 포화하고, 급속하게 감소하는 문제다. degradation의 원인은 오버피팅이 아니며, layer를 더 추가하면 더 큰 trainning error를 얻을 뿐이다.
이 논문에서는 deep residual learning framework를 소개하여 degradation을 해결하고자 한다. 쌓인 layer들이 곧바로 desired underlying mapping을 맞추는 게 아니라, 이들이 residual mapping에 맞추도록 하는 것이다.
desired underlying mapping이 H(x)라면, H(x)=F(x)+x로 생각해서 stacked nonlinear layers이 F(x)=H(x)-x를 맞추도록 하는 것이다. 논문은 residual mapping F(x)를 optimize하는 것이 기존의 unreferenced mapping H(x)보다 쉽다고 가정했다. 또 극단적으로 만약 identity mapping이 optimal이라면, 즉 H(x)=x라면 residual F(x)를 0으로 만드는 것이 stack of nonlinear layers를 identity mapping으로 맞추는 것보다 쉬울 것이다.
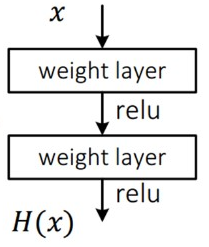
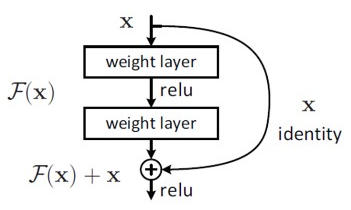
또 F(x)+x라는 구조는 “shortcut connections”를 가진 feedforward neural networks로 생각할 수 있다. Shortcut connections란 하나 이상의 layer를 건너뛰는 구조를 의미하여, 여기서는 shortcut이 단순히 identity mapping의 역할을 수행하여 stacked layers의 output F(x)와 합쳐진다.
논문은 실험을 통해 degradation 문제에 대한 Residual network의 효과를 입증하려 한다. 이들은 1. 몹시 깊은 residual net가 optimize하기 쉽지만 일반적인 net은 깊이가 증가할수록 더 높은 training error를 보임과 2. deep residual nets는 몹시 깊은 깊이에서 accuracy가 증가하며 기존의 network보다 좋은 성능을 보임을 보이고자 한다.
논문에서 만든 ResNet은 152 layer으로 현재(당시)까지 ImageNet으로 실험한 network중 가장 깊으며, 그럼에도 VGGNet보다 낮은 복잡도를 가진다.
이 아이디어는 degradation에 대한 반직관적인 현상에서 기인했는데, 기존의 model에 identity layer를 덧붙여 더 깊은 network를 만들면 기존의 model보다 training error이 더 커서는 안 될텐데 실제로는 그렇지 않았다는 것이다. 이는 여러 nonlinear layer들로는 identity mapping을 근사하는 것이 힘들다는 것을 시사한다. 차라리 identity mapping을 기본으로 두고, residual mapping을 0으로 만드는게 쉽다는 것이다. 물론 실제 상황에서 identity mapping이 optimal할 경우는 거의 없겠지만, 이런 reformulation은 문제를 precondition하는 데 도움이 될 것이다. optimal mapping이 zero mapping보다 identity mapping에 더 가깝다면 작은 동요(perturbatoins, 즉 residual)을 찾는 게 처음부터 함수를 새로 찾는 것보다 더 쉬울 것이기 때문이다.
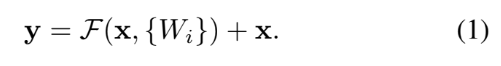
residual network의 building block은 식 (1)과 같이 표현할 수 있다. 이는 추가적인 parameter나 computational complexity를 요구하지 않기 때문에 실용적이다. 대신 F와 x의 dimension이 동일해야 한다. 만약 그렇지 않을 경우, 아래의 식 (2)처럼 Ws로 linear projection을 수행해 차원을 맞춰줄 수도 있다.
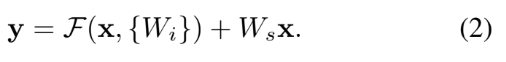
하지만 식 (1)로도 degradation을 해결하기 충분하고 이게 더 경제적이기 때문에 Ws는 dimension을 맞출 때만 사용되었다.
residual function F의 형태는 flexible할 수 있는데 이 논문에서 F를 2~3 layer로 설정했다. F를 더 많은 layer로 설정하는 것도 가능하고 1층으로만 사용할 수도 있지만, 1층으로 사용하면 결국 식이 y=Wx + x 꼴이라 장점이 사라진다. 또 F는 fully-connected layer뿐 아니라 convolutional layer들이 될 수도 있다.
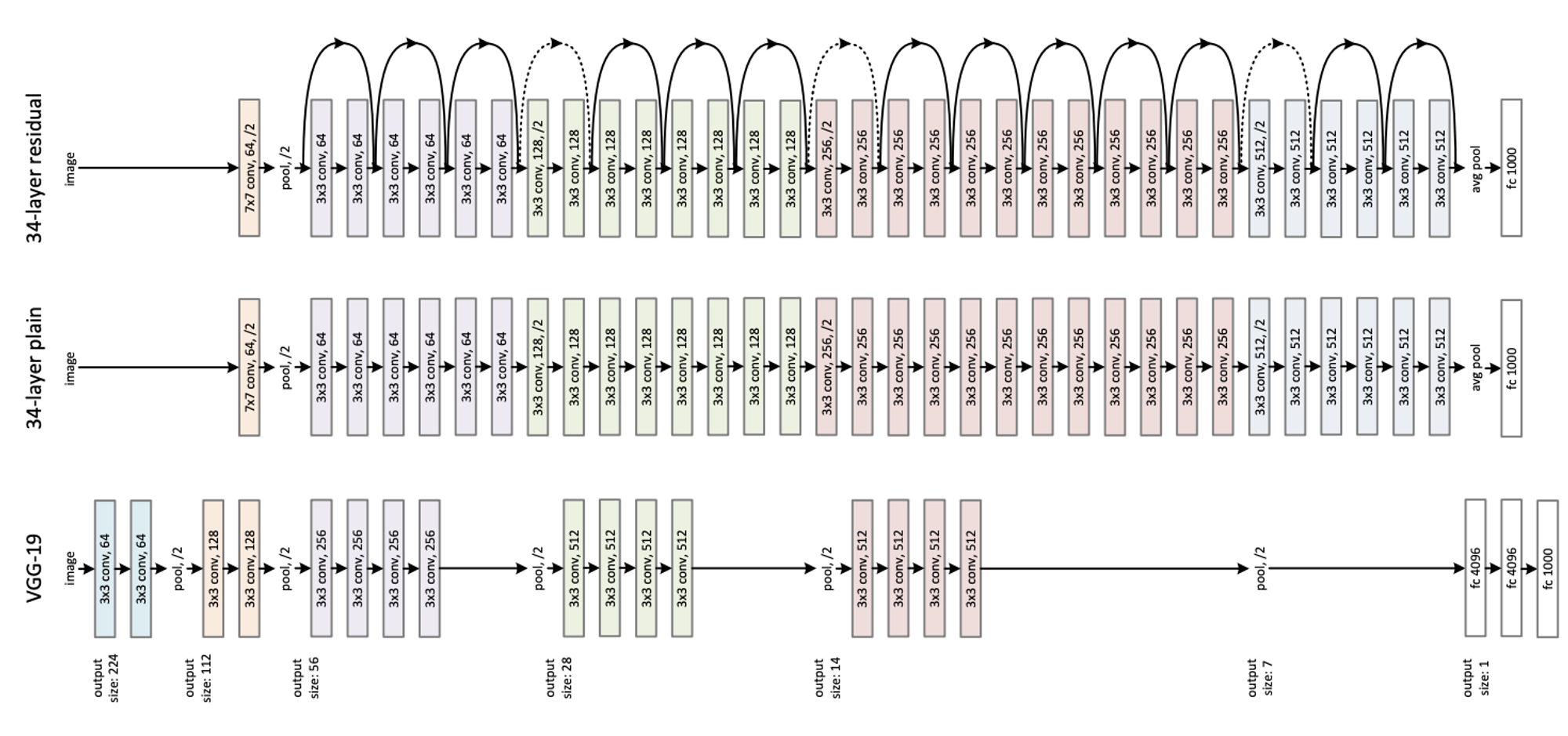
논문에서는 residual network의 효과를 입증하기 위해 일반적인 network와 residual network를 비교한다. 일반적인 network는 VGGNet을 참고해 만들었으며, 18-layer과 34-layer짜리가 있다. residual network는 위의 사진에서 보이는 바와 같이 일반적인 network에 3x3 filter pair마다 shortcut connection을 삽입한 구조다. 자세한 architecture나 implementation은 논문에서 읽어볼 수 있으며 여기서는 생략하겠다.
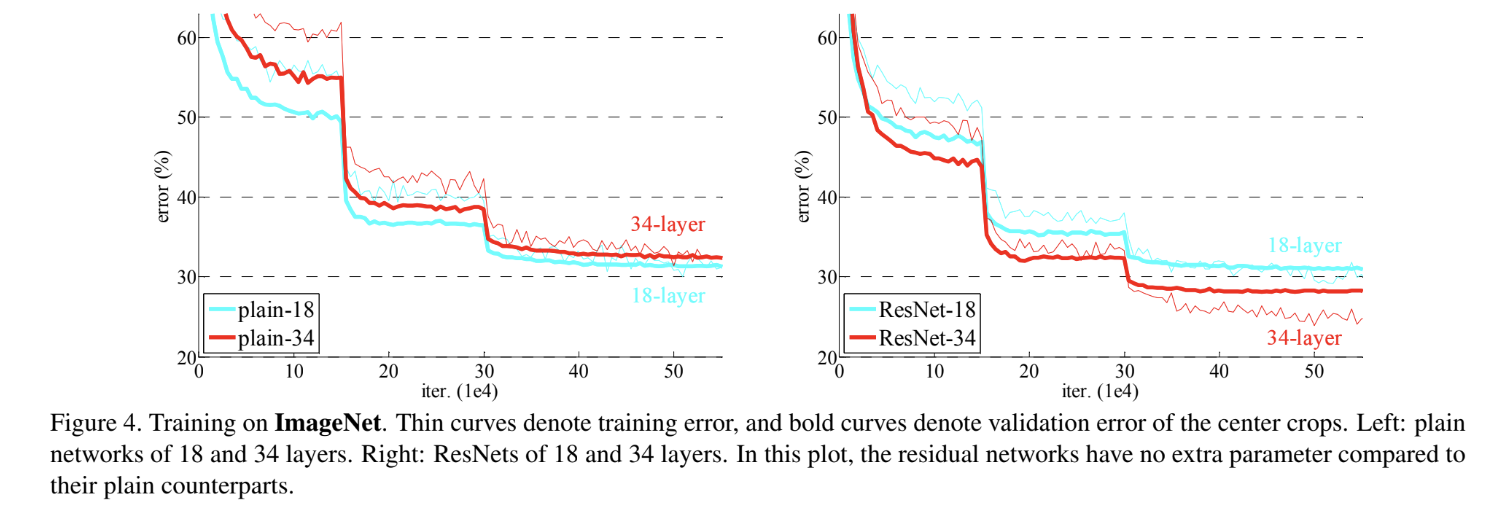
18-layer plain net와 34-layer plain net를 비교한 결과 34층 짜리가 더 높은 validation error와 training error를 보였다. 이는 plain network가 degradation 문제를 겪음을 보인 것이다.
논문에서는 optimization difficulty가 vanishing gradients 문제로 인한 게 아니라고 주장한다. BN(batch normalization)으로 train했기 때문에 forward/backward signal이 vanish하지 않기 때문이다.
또 ResNet의 경우 18-layer와 34-layer을 가지고 2가지 옵션으로 실험했다. 옵션 A는 모든 shortcut에 identity mapping를 사용하고 만약 dimension이 증가할 경우 zero-padding을 사용한 것이다. 따라서 parameter 개수 증가가 없다. 이 경우 Figure 4에서 볼 수 있듯이 plain net와 달리 34-layer이 18-layer보다 더 error가 작다. degradation 문제가 잘 해결되었으며 증가한 깊이로부터 정확도를 얻었음을 의미한다. 또 34-layer resnet이 34-layer plain net보다 error가 작음을 보면 deep network에서 residual learning이 효과적임을 알 수 있다. 18-layer에서는 resnet과 plain net이 비슷하게 정확하지만, resnet이 더 빠르게 converge한다. 즉 network가 충분히 깊지 않고 plain net도 SGD로 좋은 해를 찾을 수 있더라도 ResNet은 optimization을 쉽게 해서 더 빠르게 해를 찾을 수 있다는 것이다.
다음으로 논문은 식 (2), 즉 projection shortcut의 효과를 실험하기 위해 옵션 (B)와 (C)를 도입한다. 옵션 (B)는 increasing dimension 시에만 projection shortcut을 사용하고 나머지는 identity shortcut을 사용하는 것이며, 옵션 (C)는 전부 projection shortcut을 사용하는 것이다.
실험 결과 (A), (B), (C) 모두 plain network보다는 성능이 상당히 좋았다. (B)는 (A)보다 약간(slightly) 더 좋았는데, 이는 (A)에서 zero-padded dimension이 residual learning이 없기 때문이다. (C)는 (B)보다 아주 조금(marginally) 더 좋았고, 많은(13개) projection shortcut으로 인해 추가적인 parameter들이 도입되었기 때문이다. 하지만 (A), (B), (C)의 차이가 거의 없는 것으로 보아 projection shortcut이 degradation을 다루는 데 필수는 아님을 알 수 있다. 그래서 논문에선 memory/time complexity와 model size를 줄이기 위해 이후로 옵션 (C)는 사용하지 않는다. 특히 identity shortcut은 곧 다룰 bottleneck architecture의 complexity를 높이지 않는 데 중요하기 때문이다.
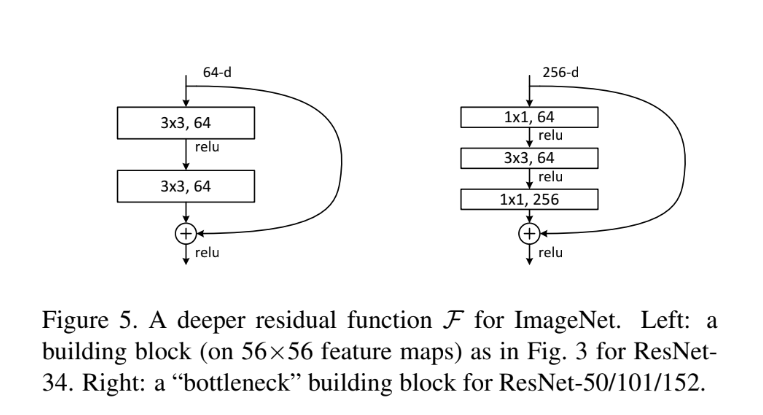
Figure 5의 오른쪽 그림이 bottleneck building block이다. 이는 training time을 감당할 수 있는 수준으로 줄이기 위해 기존의 3x3 layer 2개 대신 1x1 layer로 dimension을 reduce한 후 3x3 layer을 거치고 다시 1x1 layer로 dimension을 increase(restore)한 것이다. 이때 여기서 projection shortcut을 사용하면 time complexity와 model size가 2배가 되기 때문에 parameter-free한 identity shortcut을 사용하는 것이 중요하다.
논문에선 ImageNet 말고 CIFAR-10으로도 연구를 수행하는데, 몇 가지 흥미로운 점만 정리해보겠다. ResNet-20, 56, 110을 비교한 결과 ResNet이 깊을수록 response magnitude가 작다고 한다. layer가 더 많을수록 layer 각각이 signal을 덜 modify하려 한다는 것이다. 또 아주 깊은, 1202 layer으로도 실험을 해봤는데 optimization difficulty는 전혀 보이지 않았고 training error도 0.1% 미만을 기록했다. test error도 7.93%로 여전히 좋지만, 비슷한 training error를 가진 110-layer network보다는 나쁘다. 이는 overfitting 때문으로 추정되며 작은 dataset에 비해 1202 layer가 너무 깊기 때문일 것이다.
Strenghts
- 아주 단순하고 기발한 아이디어로 degradation을 해결하면서 network 깊이를 증가시킨 게 인상적이다. VGGNet보다 무려 8배나 깊은 것이 충격적이었다.
Weaknesses
- residual block을 input과 output dimension이 같을 때밖에 못 쓴다는 게 아쉽다. 물론 다를 때 projection shortcut을 쓸 수도 있지만, parameter 수 증가 등 단점이 많아 보인다. zero padding을 선택한 이유도 딱히 없어서 아쉽다. (아마 가장 간단하고 기본적인 방법이라서 사용한 것일 테지만)
- ResNet에서 dropout이나 maxout, regularization의 효과도 비교해 봤으면 더 좋았을 것 같다. 단순히 다른 논문을 따라 dropout을 안했다고 하는데, 왜 안했는지 모르겠다.
개인적으로 아이디어가 무척 흥미로운 논문이라 정말 재미있게 읽었다. 여기서는 resial block 간의 shortcut이 서로 겹치지 않게 해 놨는데 겹칠 수도 있게 설정하면 어떤 변화가 있을까 궁금하다.
참고로 이것으로 ImageNet challenge 논문 리뷰는 끝이다. 다음으로는 아마 R-CNN을 리뷰할 듯하다.
