오늘 리뷰할 논문은 ILSVRC 2014에서 GoogLeNet에 밀려 우승하지는 못했지만 비교적 간단한 구조로 상당히 뛰어난 성과를 내 이후 수많은 모델의 backbone이 된 VGGNet의 논문이다. 이 논문의 주 목표는 작은 convolution 필터(3x3)를 사용해서 network의 깊이를 증가시키는 것이다.
아래의 포스트들을 먼저 보면 이해가 편하다.
- VGG16 논문 리뷰 — Very Deep Convolutional Networks for Large-Scale Image Recognition
- VGGNet (Very Deep Convolutional Networks for Large-Scale Image Recognition) 논문 리뷰
- 1. VGGNet 논문 리뷰
Summary
VGGNet의 input image는 224x224 크기이며, 전처리로 mean RGB value subtraction을 한다. 저자는 네트워크를 11~19 layer의 여러 configuration으로 만들어봤으며, 그 구조는 아래의 표와 같다.
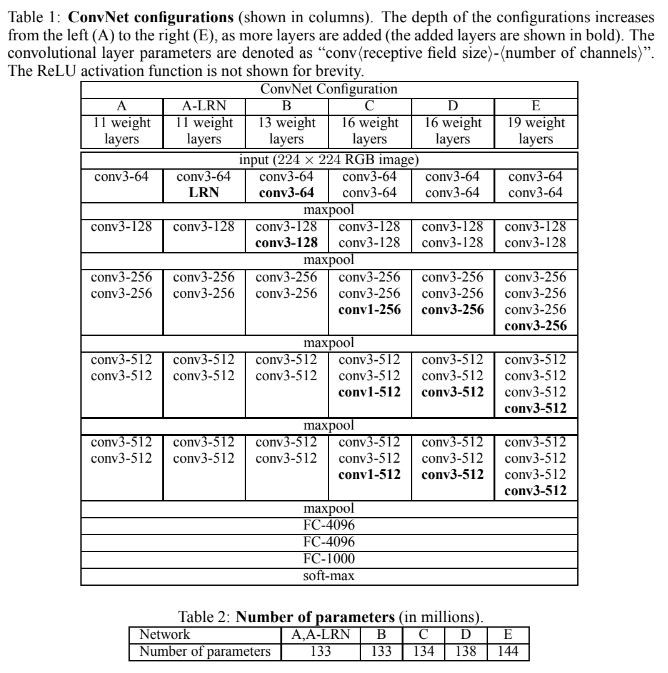
사실 구조 자체는 위의 표를 보면 알 수 있듯이 흔한 CNN이라 크게 설명할 건 없다. VGGNet의 특이한 점을 꼽아보자면 아래와 같다.
- 13 Convolution Layers + 3 Fully-connected Layers
- 3x3 convolution filters, stride 1, padding 1
- 2x2 max pooling, stride 2
- ReLU
(참고로 C 설정에서는 1x1 convolution layer을 쓰기도 한다)
AlexNet(Krizhevsky et al., 2012)과 달리 Local Response Normalisation(LRN)을 사용하지 않는데(A-LRN 설정만 제외하면), 이는 LRN 사용이 성능 향상은 없는데 메모리 사용량과 연산량은 증가시키기 때문이다.
Table2에서는 parameter 수를 보여주는데, network의 깊이가 깊음에도 더 큰 layer width와 receptive field를 가진 shallower network보다 parameter가 더 많지 않다.
앞선 ILSVRC 우승 network들과 VGGNet의 가장 큰 차이는 filter의 크기다. 첫 convolution layer에서 AlexNet은 11x11 filter을 사용하고 ZFNet은 7x7을 사용하지만 VGGNet은 대신 (모든 layer에서) 3x3 filter을 사용하고 그 대신 네트워크 깊이를 늘렸다. 이는 3x3 filter 2층이 있으면 5x5 filter와 같은 receptive field를 보이고 3층이 있으면 7x7과 같은 receptive field를 보이는, 즉 작은 filter를 여러개 중첩하여 큰 filter와 같은 receptive field를 가지게 하는 효과를 이용하는 것이다.
이렇게 여러 작은 filter convolution layer을 중첩하면 하나의 큰 filter conv layer을 사용하는 것보다 1. non-linear rectification layer을 더 많이 통과하여 decision function을 더 discriminative하게 만들 수 있고 2. parameter 수를 줄일 수 있다. 7x7 filter은 parameter가 49개지만 3x3 filter 3개는 parameter가 27개밖에 되지 않기 때문이다.
C 설정에서 1x1 filter을 사용한 것은 receptive field는 건드리지 않고 decision function의 non-linearity를 증가시키고 싶었기 때문이다.
training의 경우 multinomial logistic regression objective를 optimize한다. 세부사항은 다음과 같다.
- mini-batch (size 256) gradient descent with momentum 0.9
- regularised by weight decay (the L2 penalty multiplier set to 5 · 10^−4)
- 첫 2개 fully-connected layer에 dropout regularisation(0.5)
- learning rate initially 10^−2, decreased by a factor of 10 when the validation set accuracy stopped improving
370K iterations (74 epochs) 후에 학습이 끝났다. AlexNet보다 parameter와 layer가 더 많음에도 수렴에 더 적은 epoch이 걸린 것은 1. implicit regularisation imposed by greater depth and smaller conv filter sizes와 2. 몇몇 layer의 pre-initialisation 때문으로 추정된다.
또 깊은 네트워크에서 잘못된 가중치 초기화는 학습을 도중에 멈출 수도 있기 때문에 가중치를 잘 초기화하는 것이 중요하다. 여기서는 그 문제를 피하기 위해 비교적 낮은 층의 설정 A부터 먼저 random initialisation으로 학습을 시키고 더 깊은 설정들은 첫 4개의 convolution layer와 마지막 3개 fully-connected layer을 net A의 parameter로 초기화했다. bias는 0으로 초기화했고 random initialization은 zero mean, 10^−2 variance의 normal distribution을 따르게 했으며 pre-initialise된 layer은 learning rate를 감소시키지 않아 layer들이 학습 도중 바뀔 수 있게 했다.
training input image 크기(S, width와 height중 작은 쪽의 크기가 S, S>=224)의 경우 두 가지 방법을 사용한다. 첫째는 single-scale training으로, 고정된 S를 사용하는 것이다. 논문에서는 S=256와 S=384 두 가지로 시험해본다. (여기서 224x224를 crop하여 network에 집어넣는 듯하다.) 두 번째는 multi-scale training으로, 이미지를 [Smin=256, Smax=512] 범위의 크기로 랜덤하게 rescale한 후 224x224를 crop하는 것이다. 이는 data augmentation 효과도 있고 network가 다양한 scale에서 object를 인식하는데 도움을 준다. 참고로 multi-scale을 학습할 때 (속도를 위해) S=384로 pre-train된 single-scale을 모델로 fine-tuning을 한다.
이해를 도울 만한 사진을 해당 포스트에서 무단으로(...) 가져왔다.




test 시에도 train할 때처럼 사진을 pre-defined smallest image side(Q)로 isotropically rescale해준다. 이때 Q가 S와 같을 필요는 없지만 각 S마다 여러 개의 Q를 사용하면 성능이 더 좋게 나타난다.
또 test(=validation)에서는 fully-connected layer를 전부 convolutional layer로 바꿔준다. 첫 conv layer은 7x7 필터를 쓰며 나머지 두 개는 1x1 필터를 쓴다. fully-connected layer가 있으면 input size가 고정되어 있어서 정해진 크기의 input image밖에 쓸 수 없는데 fully-convolutional network가 되면서 input 크기 제한이 사라져 crop 안 된 아무 사진이나 넣을 수 있다. fully-convolutional network를 통과하면 input 크기에 따라 가변적인 spatial resolution과 class 수와 동일한 channel 수를 가지는 class score map을 얻게 된다. 마지막으로 고정된 크기의 class scores vector를 얻기 위해 class score map를 spatially average(sum-pooled)해준다.
추가적으로 test set을 horizontal flipping으로 augmentation했는데, soft-max class posteriors를 마지막에 추가해 원본 이미지와 flip된 이미지의 결과를 average해서 final score를 계산한다.
Strenghts
- representation depth가 classification accuracy에 성능이 좋음을 입증했다. network 깊이의 중요성을 재고하게 했다.
- 작은 크기의 filter들을 중첩하여 큰 filter를 대체할 수 있고, 동시에 network 깊이를 늘릴 수 있음을 보였다.
- GoogLeNet보다 간단한 구조로도 비슷한 성능을 낼 수 있다.
Weaknesses
- filter 크기를 줄였음에도 parameter 수가 여전히 너무 많다. 해당 포스트에 따르면...

