오늘 리뷰할 논문은 ELMo 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] Deep contextualized word representations
- [논문리뷰] ELMo(Deep contextualized word representations)의 이해
Summary
논문은 (1) 단어 사용의 복잡한 특징과(예를 들어 syntax와 semantics) (2) 어떻게 이 사용이 linguistic contexts에 걸쳐 다른지(즉, 다의성을 model) model하는 새로운 deep contextualized word representation을 소개한다. 논문의 word vectors은 (large text corpus에 pre-train된) deep bidirectional language model (biLM)의 internal states의 learned functions이다. 이 representations이 기존 models에 쉽게 적용될 수 있고 question answering, textual entailment, sentiment analysis를 포함하는 6가지 NLP tasks에 SOTA를 향상시킴을 보인다.
논문의 representations은 각 token이 (전체 input sentence의 함수인) 하나의 representation을 할당받는다는 점에서 기존 word type embedding과 다르다. large text corpus에 coupled language model (LM) objective로 학습된 bidirectional LSTM에서 얻은 vectors를 사용한다. 그런 이유에서 ELMo (Embeddings from Language Models) representations라고 이름 붙였다. contextualized word vectors를 배우려는 기존 연구와 달리 ELMo representations은 그들이 biLM의 모든 internal layers의 함수라는 점에서 deep하다. 더 구체적으로는 (단순히 LSTM layer 꼭대기를 사용하는 것보다 성능을 향상시키는) 각 end task에 대해 각 input word 위에 stack된 vectors의 linear combination을 학습한다.
이런 식으로 internal states를 결합하는 것은 아주 풍부한 word representations을 가능하게 한다. intrinsic evaluations을 통해 higher-level LSTM states가 단어 의미의 context-dependent aspects을 포착하고(예컨대 supervised word sense disambiguation tasks에 수정없이 잘 작동할 수 있고) lower-level states가 syntax 측면을 포착함을(예컨대 part-of-speech tagging에 사용될 수 있음) 보인다. 이 신호들을 동시에 부과하는 것은 매우 유익한데, learned model이 각 end task에 가장 유용한 semi-supervision의 종류를 선택할 수 있게 한다.
가장 널리 사용되는 GloVe word embeddings와 달리 ELMo word representations은 전체 input sentence의 함수다. 그들은 character convolutions을 가진 two-layer biLMs의 꼭대기에서 internal network states의 linear function으로 계산된다. 이 구조는 semi-supervised learning을 허용하고 biLM은 large scale로 pre-train되어 광범위한 기존 neural NLP architectures에 쉽게 통합된다.
sequence of N tokens, 가 주어졌을 때 forward language model은 history 가 주어졌을 때 token 의 probability를 modeling함으로써 sequence의 probability를 계산한다.
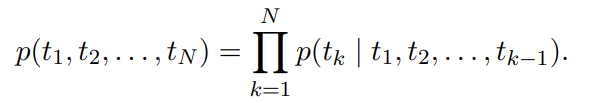
SOTA neural language models은 (token embeddings나 characters에 대한(over) CNN을 통해) context-independent token representation 를 계산하고 이를 forward LSTMs의 L layers에 통과시킨다. 각 position k에서 각 LSTM layer은 context-dependent representation 을 output한다(j=1,...,L). top layer LSTM output 이 Softmax layer를 통해 next token 을 예측하기 위해 사용된다.
backward LM은 forward LM과 비슷하며 sequence에 대해(over) 역방향으로 동작한다는 것만 다르다(즉, future context가 주어졌을 때 previous token을 예측한다).
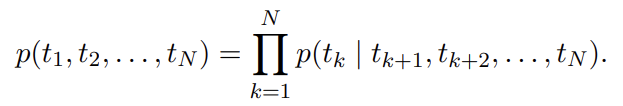
forward LM와 유사한 방법으로 구현될 수 있으며 L layer deep model 내의 각 backward LSTM layer j는 가 주어졌을 때 의 representations 을 생성한다.
biLM은 forward와 backward LM을 결합한다. 다음 공식은 forward와 backward 방향의 log likelihood를 공동으로 최대화한다.
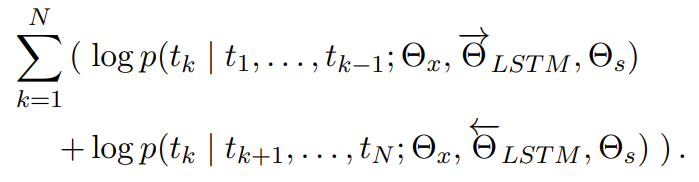
(식에서 알 수 있듯) token representation (Θx)와 Softmax layer (Θs)는 forward와 backward에서 같은 parameters를 사용하고 LSTMs은 두 방향에서 parameters를 따로 사용한다.
ELMo는 biLM 내 intermediate layer representations의 task specific combination이다. 각 token 에 대해 L-layer biLM은 set of 2L + 1 representations을 계산한다.
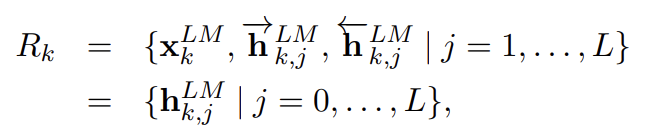
은 token layer이고 각 biLSTM layer에 대해 다.
downstream model에 포함하기 위해 ELMo는 R 내의 모든 layers를 single vector 로 collapse한다. 가장 간단한 경우 ELMo는 TagLM이나 CoVe처럼 그냥 top layer 을 선택한다. 더 일반적으로는 모든 biLM layers의 task specific weighting을 계산한다.
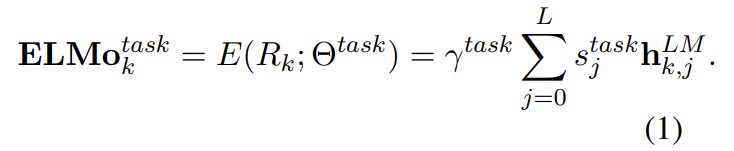
식 (1)에서 는 softmax-normalized weights이고 scalar parameter 는 task model이 전체 ELMo vector를 scale할 수 있게 한다. γ는 optimization process를 돕는 실용적인 중요성이 있다. 각 biLM layer의 activations가 다른 distribution을 가짐을 고려하면 경우에 따라 가중치를 부여하기(weighting) 이전에 각 biLM layers에 layer normalization을 적용하는 게 도움이 되었다.
pre-trained biLM와 target NLP task를 위한 supervised architecture가 주어졌을 때 task model을 향상시키기 위해 biLM을 사용하는 방법은 간단하다. 단순히 biLM을 작동시켜 각 word에 대한 모든 layer representations을 기록한다. 그 다음, end task model이 곧 설명할 것처럼 이 representations의 linear combination을 학습하게 한다.
먼저 biLM 없는 supervised model의 lowest layers를 생각해보자. 대부분 supervised NLP models는 lowest layer에서 일반적인 architecture를 공유하며 이는 우리가 ELMo를 consistent, unified manner로 추가하는 것을 허용한다. sequence of tokens 가 주어졌을 때 pre-trained word embeddings와 선택적으로 character-based representations를 사용해 각 token position에 대한 context-independent token representation 를 형성하는 것이 일반적이다. 그 다음 모델은 일반적으로 bidirectional RNNs나 CNNs나 feed forward networks을 사용해 context-sensitive representation 을 형성한다. supervised model에 ELMo를 추가하기 위해 먼저 biLM의 weights를 얼리고 ELMo vector 를 에 concatenate하고 ELMo enhanced representation 를 task RNN에 전달한다. (SNLI, SQuAD 같은) 몇몇 tasks에선 (another set
of output specific linear weights을 도입하고 를 로 대체함으로써) task RNN의 output에도 ELMo를 포함시킴으로써 추가적인 성능 향상이 관측된다. supervised model의 나머지는 변하지 않기 때문에 ELMo를 추가하는 것은 더 복잡한 neural models의 맥락 내에서 이루어질 수 있다.
마지막으로 ELMo에 적당한 양의 dropout을 추가하는 것도 유익함을 발견했다. 어떤 경우에는 loss에 를 추가함으로써 ELMo weights를 regularize하는 것도 유익했다. 이는 ELMo weights가 모든 biLM layers의 평균에 가깝도록 inductive bias를 부과한다.
논문의 pre-trained biLMs는 Jozefowicz et al. (2016)와 Kim et al. (2015)의 architecture와 비슷하지만 양방향의 joint training을 지원하도록 수정되었고 LSTM layers 사이 residual connection을 추가했다. Peters et al. (2017)이 forward-only LMs보다 biLMs 사용과 large scale training의 중요성을 강조한 것처럼 논문은 large scale biLMs에 집중한다.
purely character-based input representation을 유지하면서 language model perplexity를 model size와 downstream task에 대한 연산 요구량과 balance하기 위해 Jozefowicz et al. (2016)의 single best model에서 모든 embedding과 hidden dimensions을 절반으로 줄였다. final model은 4096 units와 512 dimension projections와 1층에서 2층으로의 residual connection을 가진 L = 2 biLSTM layer을 사용한다. context insensitive type representation은 2048 character n-gram convolutional filters를 사용하고 2 highway layers (Srivastava et al., 2015)와 512 representation으로의 linear projection가 뒤따른다. 그 결과 biLM은 (purely character input으로 인해 training set 바깥의 것들도 포함해) 각 input token에 대해 3 layers of representations을 제공한다. 반면 전통적인 word embedding 방법들은 fixed vocabulary 내의 tokens에 대해 1 layer of representation만 제공한다.
1B Word Benchmark (Chelba et al., 2014)에 10 epochs 학습한 후 평균 forward & backward perplexities는 39.7이다. 비교 대상인 forward CNN-BIG-LSTM는 30.0이다. 일반적으로 forward와 backward perplexities는 거의 동일했고 backward 값이 약간 더 낮았다.
한번 pretrain되면 biLM은 아무 task를 위해서든 representations을 계산할 수 있다. 어떤 경우에는 biLM을 domain specific data에 fine tuning하는 것이 perplexity에 상당한 손실과 downstream task performacne의 향상을 야기했다. 이는 biLM에 대한 domain transfer로 볼 수 있다. 결과적으로 대부분 경우 논문은 downstream task에서 fine-tuned biLM을 사용했다.
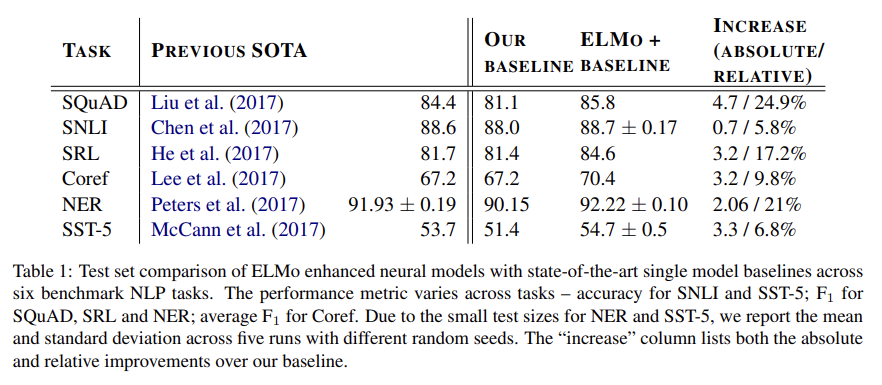
Tab 1은 6 benchmark에서 ELMo의 성능을 보여준다. 모든 task에서 단순히 ELMo를 추가하는 것이 SOTA를 달성한다. 각 task에 대한 설명은 생략한다.
ablation analysis도 한다.
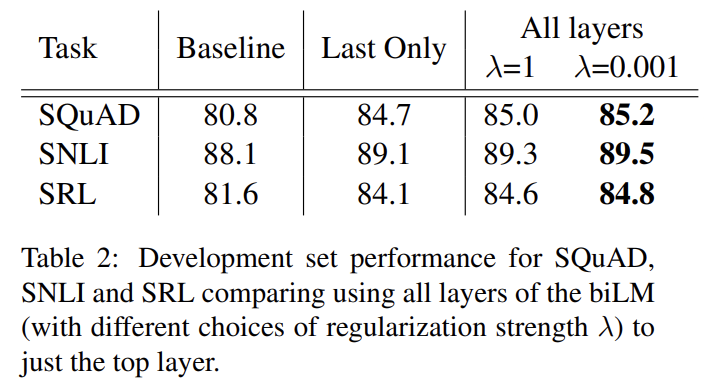
식 (1) 외에도 biLM layers를 조합하는 많은 대안들이 있다. contextual representations에 대한 기존 연구들은 biLM이나 MT encoder에서 last layer만 사용했다. regularization parameter λ의 선택도 중요한데, λ = 1 같은 큰 값은 weighting function을 layers에 대한(over) 단순한 average로 효과적으로 축소시키고 반면 λ = 0.001 같은 작은 값은 layer weights가 다양하도록(vary) 허용한다.
Tab 2가 SQuAD, SNLI와 SRL에 대해 이 대안들을 비교한다. 전체 layers로부터 representations을 포함하는 것이 마지막 layer 것만 쓰는 것보다 뛰어나고 마지막 layer에서 contextual representations을 포함하는 것이 baseline보다 뛰어나다. ELMo를 가지고는 대부분 경우 작은 λ가 선호되지만 training set이 작은 NER의 경우 결과는 λ에 무감각하다.
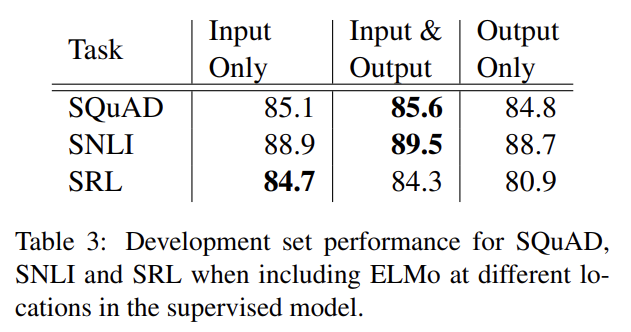
논문의 모든 task architectures은 word embeddings을 lowest layer biRNN으로의 input으로만 포함한다. 그러나 task-specific architectures에서 ELMo를 biRNN의 output에 포함시키는 것이 몇 tasks에서 결과를 향상시켰다. Tab 3에서 볼 수 있듯 SNLI와 SQuAD에서 input과 output layers 둘 다에 ELMo를 포함하는 것은 성능을 향상시키지만 SRL에서는 input layer에만 포함하는 것이 성능이 가장 높다. 가능한 설명은 SNLI와 SQuAD architectures가 biRNN 이후에 attention layers를 사용해서 ELMo를 이 layer에 도입하는 것이 모델이 직접 biLM의 internal representations에 attend할 수 있게 한다는 것이다. SRL의 경우 task-specific context representations이 biLM의 것보다 중요하다.
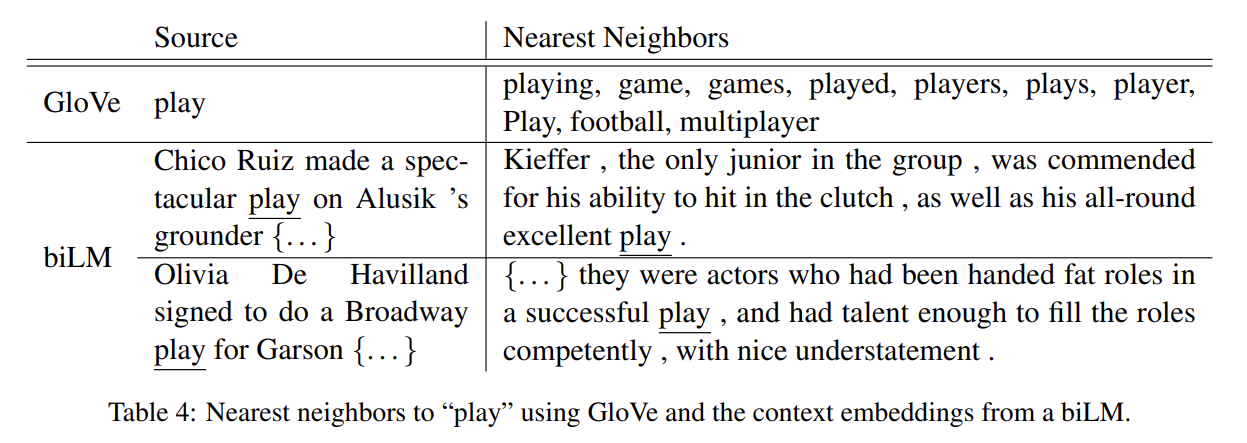
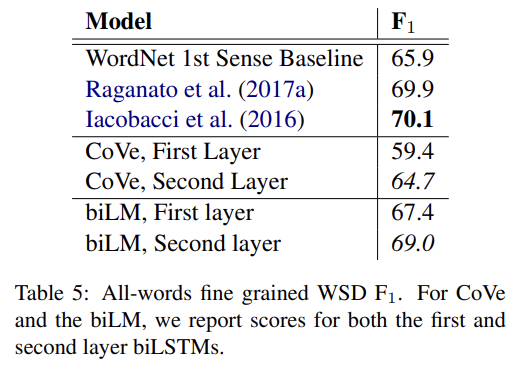
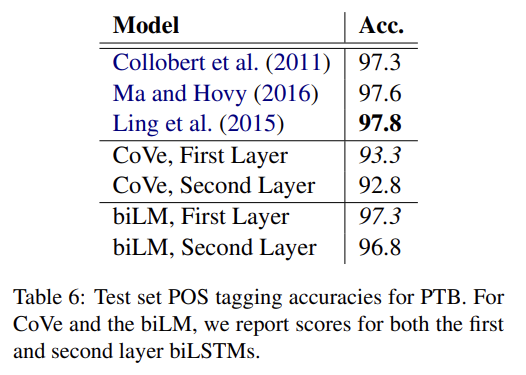
ELMo를 추가하는 것이 word vectors만 사용하는 것보다 성능을 향상시키기 때문에 biLM의 contextual representations은 word vectors가 포착하지 못한, NLP tasks에 보편적으로 유용한 정보를 encode해야 한다. 직관적으로 biLM은 context를 사용해 단어의 의미를 disambiguate해야 한다. Tab 4에서 GloVe는 단어 "play"와의 nearest neighbor을 스포츠와 관련된 의미만 보여주지만 biLM의 context representation을 사용해 SemCor dataset에서 nearest neighbor sentence를 찾으면 의미를 구분할 수 있다.
(중략)
종합적으로, 이 실험들은 biLM 내 서로 다른 layers가 서로 다른 종류의 정보를 나타낸다는 것을 입증하고 왜 모든 biLM layers를 포함하는 것이 downstream tasks에서 가장 높은 성능에 중요한지 설명한다.
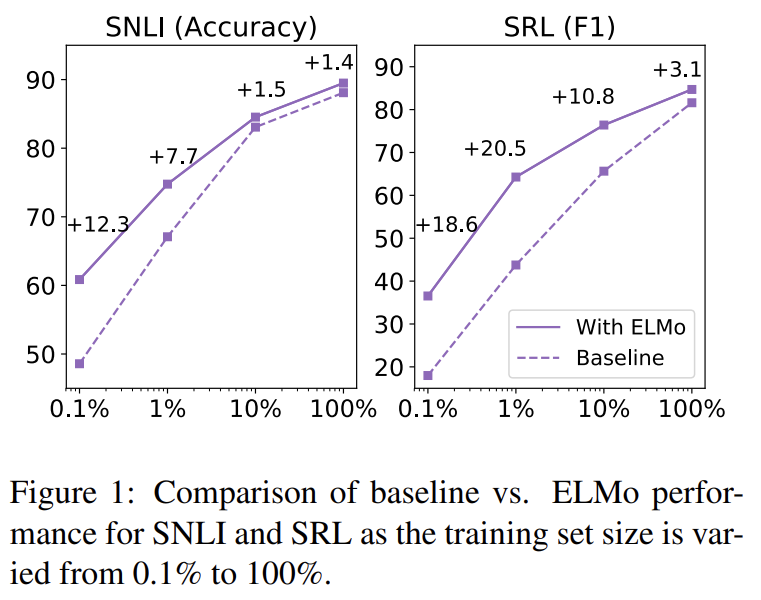
ELMo를 추가하는 것은 SOTA 성능 달성을 위한 parameter updates 횟수와 전체적인 training set size라는 두 측면에서 sample efficiency를 상당히 향상시킨다. 또 ELMo-enhanced models은 ELMo가 없는 모델보다 smaller training sets를 더 효율적으로 사용한다.

Fig 2는 softmax-normalized learned layer weights를 시각화한다. input layer에선 task model이 (특히 coreference와 SQuAD에서) 첫번째 biLSTM layer를 선호한다. output layer weigths는 상대적으로 균형이 유지되며 lower layers에 약한 선호가 있다.
Strengths
- 기존 모델에 ELMo를 손쉽게 추가할 수 있으며 높은 성능 향상을 보인다.
- biLM에서 top layer만 사용하는 것이 아니라 여러 층을 선형 결합해서 context를 담고자 했다.
