오늘 리뷰할 논문은 BLIP 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- 📹빠르게 보는 BLIP 논문 리뷰📹
- Bootstrapping Language-Image Pre-training(BLIP, BLIP2) 논문 리뷰
- [Paper Review] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML'22)
Summary
현존하는 VLP model은 understanding-based tasks나 generation-based tasks 하나만 잘한다. 또 성능 향상이 인터넷에서 수집한 noisy image-text pairs를 가진 데이터셋을 키우는 것으로 이루어져 suboptimal하다. 논문은 vision-language understanding와 generation tasks 모두 유연하게 transfer하는 BLIP을 제안한다. BLIP은 caption을 bootstrapping함으로써 noisy web data를 효과적으로 활용한다. 즉, captioner가 synthetic captions을 생성하고 filter가 noisy한 것들을 제거한다. image-text retrieval, image captioning, VQA 등 넓은 범위의 vision-language tasks에서 SOTA를 달성한다. 또 zero-shot manner로 video-language tasks에 직접 transfer되었을 때 강한 일반화 능력을 입증한다.
BLIP은 모델과 데이터라는 2가지 측면에서 기여를 한다.
- Multimodal mixture of Encoder-Decoder (MED)
효과적인 multi-task pre-training과 flexible transfer learning을 위한 새로운 model architecture. MED는 unimodal encoder나 image-grounded text encoder나 image-grounded text decoder로도 작동할 수 있다. 모델은 3가지 vision-language objectives, 즉 image-text contrastive learning, image-text matching, image-conditioned language modeling에 공동으로 pre-train된다.
- Captioning and Filtering (CapFilt)
noisy image-text pairs로부터 학습하기 위한 새로운 dataset boostrapping method. pre-trained MED를 2 모듈로, 즉 web images가 주어졌을 때 synthetic captions를 생성하기 위한 captioner와 original/syntehtic web texts에서 noisy captions을 제거하기 위한 filter로 finetune된다.
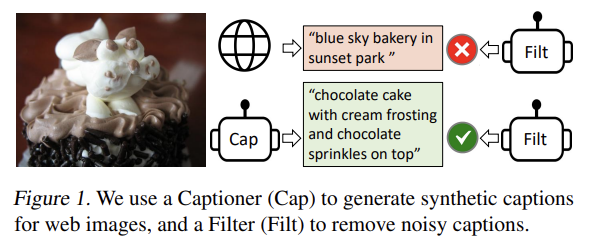
실험과 분석을 통해 다음 2가지를 관찰한다.
- captioner와 filter가 함께 작동해 captions을 bootstrapping함으로써 다양한 downstream tasks에 상당한 성능 향상을 달성한다. 또 더 다양한 captions이 larger gains을 만든다는 것을 발견했다.
- BLIP은 image-text retrieval, image captioning, visual question answering, visual reasoning, visual dialog을 포함하는 광범위한 vision-language tasks에서 SOTA를 달성한다. 또 2가지 video-language tasks, 즉 text-to-video retrieval과 videoQA에 모델을 직접 transfer했을 때 SOTA zero-shot performance를 달성한다.
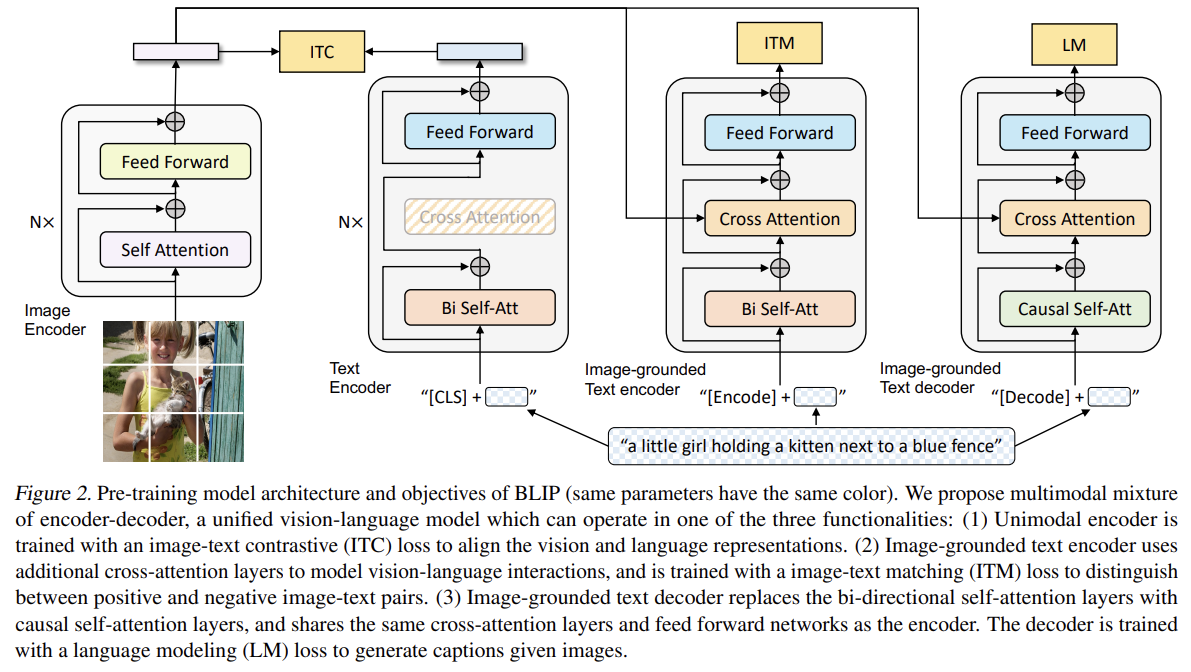
- Model Architecture
image encoder로 visual transformer를 이용한다. 이는 input images를 patches로 나누고 (global image feature를 대표하기(represent) 위한 추가적인 [CLS] token을 가진) sequence of embeddings으로 encode한다. visual feature extraction을 위해 pre-trained object detectors을 사용하는 것과 달리 ViT를 사용하는 것이 더 computation-friendly하고 더 최신 방법들에서 (ViT가) 사용되었다.
understanding과 generation 능력을 둘 다 가진 unified model을 pre-train하기 위해 다음 3가지 기능 중 하나로 작동할 수 있는 multi-task model인 multimodal mixture of encoder-decoder (MED)을 제안한다.
(1) Unimodal encoder
Unimodal encoder는 image와 text를 따로 encode한다. text encoder는 BERT와 같고 sentence를 요약하기 위해 text의 시작에 [CLS] token이 첨부된다.
(2) Image-grounded text encoder
Image-grounded text encoder는 text encoder의 각 transformer block에 대해 self-attention (SA) layer와 feed forward network (FFN) 사이에 하나의 추가적인 cross-attention (CA) layer을 삽입함으로써 visual information을 주입한다. text에 task-specific [Encode] token이 첨부되며 [Encode]의 output embedding이 image-text pair의 multimodal representation으로 사용된다.
(3) Image-grounded text decoder
Image-grounded text decoder은 image-grounded text encoder 내에서 bidirectional self-attention layers을 causal self-attention layers로 대체한다. [Decode] token이 sequence의 시작을 signal하기 위해 사용되며 end-of-sequence token이 끝을 signal하기 위해 사용된다.
- Pre-training Objectives
pre-trainig 중 2 understanding-based objectives와 1 generationbased objective, 총 3가지 objectives로 공동으로 최적화한다. 각 image-text pair는 1번만 computational-heavier visual transformer을 통과하면 되고, 3가지 losses를 계산하기 위해 서로 다른 functionalities가 활성화되는 text transformer를 3번 통과하면 된다.
(1) Image-Text Contrastive Loss (ITC)
ITC는 unimodal encoder을 활성화한다. ITC는 positive
image-text pairs가 negative pairs에 비해 비슷한 representations을 가지게 장려함으로써 visual transformer와 text transformer의 feature space를 align하는 데 집중한다. 이는 vision과 language understanding을 향상시키는 데 효과적인 objective임이 입증된 바 있다. Li et al. (2021a)의 ITC loss를 따르며 features을 생성하기 위해 momentum encoder가 도입됐고 negative pairs 내의 potential positives을 처리하기 위해 momentum encoder로부터 soft labels가 training targets로써 만들어진다.
(2) Image-Text Matching Loss (ITM)
ITM은 image-grounded text encoder을 활성화한다. vision과 language 사이 fine-grained alignment을 포착하는 image-text multimodal representation을 학습하는 데 집중한다. ITM은 binary classification task이며 모델은 image-text pair의 multimodal feature가 주어졌을 때 image-text pair가 positive (matched)인지 negative (unmatched)인지 예측하기 위해 ITM head (a linear layer)을 사용한다. more informative negatives를 찾기 위해 Li et al. (2021a)의 hard negative mining strategy를 적용하며, 여기서 batch 내에서 higher contrastive similarity를 가진 negative pairs는 loss를 계산하기 위해 더 자주 선택된다.
(3) Language Modeling Loss (LM)
LM은 image-grounded text decoder를 활성화하며 image가 주어졌을 때 textual descriptions을 생성하는 데 집중한다. LM은 모델이 autoregressive manner로 text의 likelihood를 최대화하도록 학습하는 cross entropy loss를 최적화한다. loss를 계산할 때는 0.1의 label smoothing을 적용한다. VLP에 널리 사용되는 MLM loss와 달리 LM은 모델이 visual information을 일관된 captions으로 전환하도록 generalization capability을 가능하게 한다.
multi-task learning을 leverage하면서 효율적인 pre-training을 수행하기 위해 text encoder와 text decoder는 SA layers를 제외하고 모든 parameters를 공유한다. 그 이유는 encoding과 decoding tasks 사이 차이점이 SA layers에 의해 가장 잘 포착되기 때문이다. 특히 encoder는 current input tokens에 대한 representations을 build하기 위해 bi-directional self-attention을 사용하는 한편 decoder는 다음 tokens을 예측하기 위해 causal self-attention을 사용한다. 반면 embedding layers, CA layers와 FFN은 encoding과 decoding tasks 간에 비슷하게 작동하며 따라서 이 layers를 공유하는 것은 training efficiency를 향상시키고 multi-task learning로부터 득을 볼 수 있다.
- CapFilt
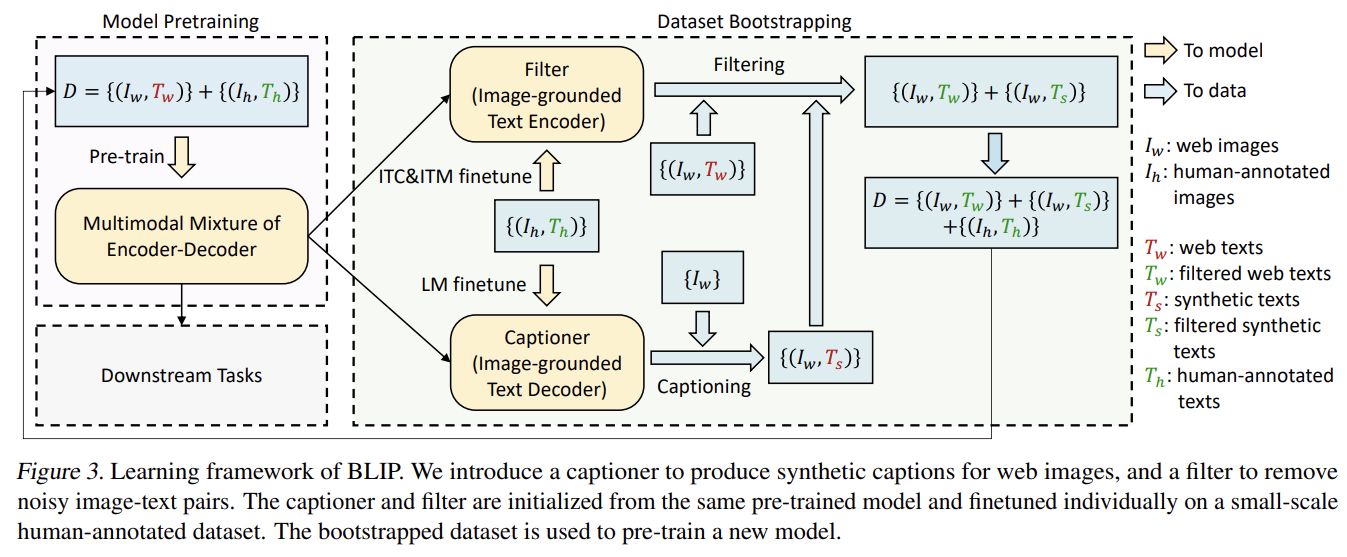
엄두를 못 낼 정도의 annotation cost 때문에 high-quality human-annotated image-text pairs {(I_h, T_h)}의 수는 한정되어있다. 최근 연구들은 web에서 자동으로 수집한 대량의 image와 alt-text pairs {(Iw, Tw)}을 사용한다. 그러나 alt-texts는 자주 image의 visual contents를 정확히 묘사하지 않으며 vision-language alignment 학습에 suboptimal한 noisy signal이 된다.
논문은 text corpus의 질을 향상시키는 Captioning and Filtering (CapFilt)을 소개한다. web images가 주어졌을 때 captions을 생성하는 captioner와 noisy image-text pairs을 제거하기 위한 filter가 있다. captioner와 filter 모두 동일한 pre-trained MED model로부터 초기화되며 COCO dataset에 개별적으로 finetune된다. finetuning은 lightweight procedure이다.
구체적으로 captioner는 image-grounded text decoder이다. captioner는 image가 주어졌을 때 text를 decode하기 위해 LM objective로 finetune된다. web images I_w가 주어졌을 때 captioner는 image 당 caption 하나씩 synthetic captions T_s을 생성한다. filter는 image-grounded text encoder이다. filter는 text가 image에 match하는지 학습하기 위해 ITC와 ITM objectives에 finetune된다. filter는 original web texts T_w와 synthetic texts T_s 둘 다에서 noisy texts를 제거한다. text는 ITM head가 image에 unmatch하다고 예측한다면 noisy한 것으로 간주된다. 마지막으로 new model을 pre-train할 새로운 dataset을 형성하기 위해 filtered image-text pairs와 human-annotated pairs을 결합한다.
image transformer는 ImageNet에 pre-train된 ViT로 초기화되고 text transformer는 로 초기화된다. 2가지 ViT, 즉 ViT-B/16와 ViT-L/16를 탐구한다. 명시하지 않은 한 모든 결과는 ViT-B을 사용한다. Li et al. (2021a)와 동일한 pre-training dataset을 사용하며 2가지 human-annotated datasets (COCO와 Visual Genome)와 3가지 web datasets (Conceptual Captions, Conceptual 12M, SBU captions)을 포함한다. more noisy texts를 가진 추가적인 web dataset인 LAION을 가지고도 실험한다.
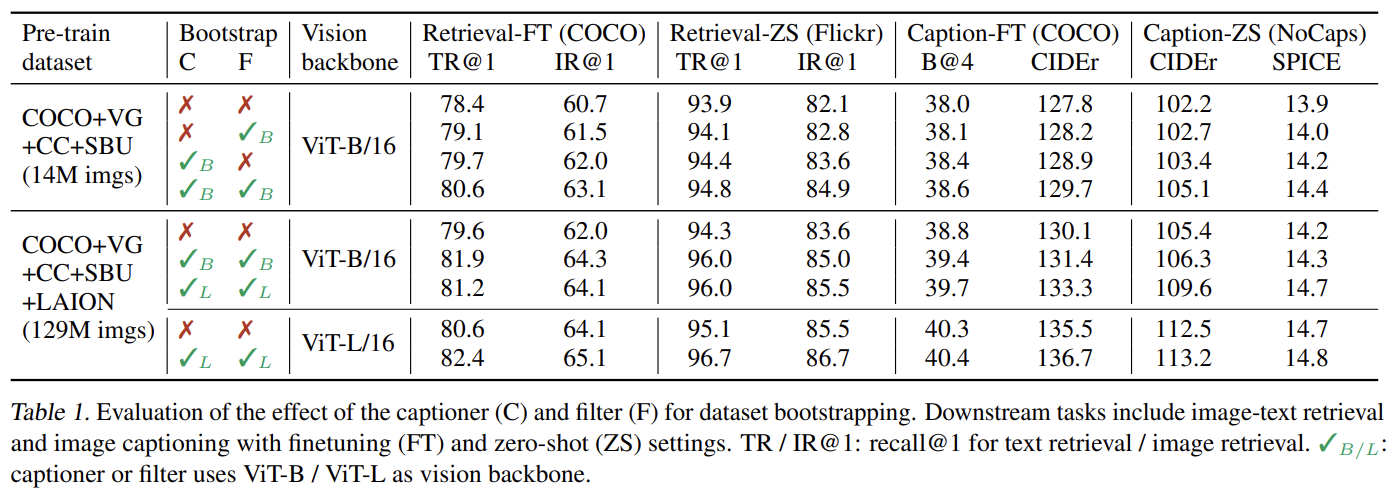

CapFilt의 효과를 입증하기 위해 다양한 데이터셋으로 pre-train한 모델들을 비교한다.

CapFilt에서 synthetic captions을 생성하기 위해 nucleus sampling (Holtzman et al., 2020)을 사용했다. Nucleus sampling은 (cumulative probability mass가 threshold p(실험에서는 p=0.9)를 초과하는) token들의 집합에서 각 token이 sample되는 stochastic decoding method이다. Tab 2에서 이를 highest probability를 가지는 captions을 생성하는 deterministic decoding method인 beam search와 비교한다. Nucleus sampling가 더 noisy하지만 더 좋은 성능을 보인다. 이는 Nucleus sampling가 더 다양하고 놀라운 captions을 생성해 모델이 득을 볼 수 있는 더 많은 새로운 정보를 보유하기 때문으로 추측된다. 반면 beam search는 dataset에 흔한 safe captions을 생성해 extra knowledge가 적게 제공될 것이다.
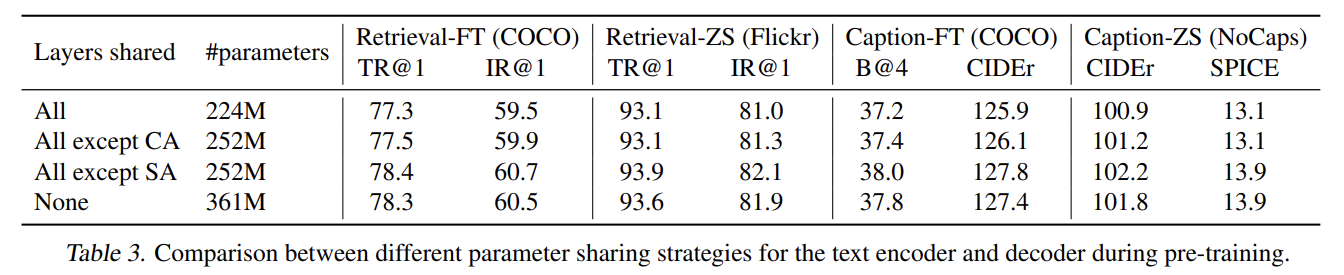
pre-training 중 text encoder와 decoder는 self-attention layers를 제외하고 모든 parameters를 공유한다. Table 3에서 다양한 parameter 공유 전략을 비교한다. SA를 제외한 모든 layers를 공유하는 것이 not sharing보다 성능이 좋았고 model size도 줄여 학습 효율을 향상시켰다. SA layers가 공유된다면 encoding task와 decoding task 사이 갈등 때문에 성능이 하락한다.

CapFilt 중에 captioner와 filter는 COCO에 개별적으로 end-to-end finetune된다. Tab 4에선 pre-training처럼 captioner와 filter가 parameter를 공유할 때 효과를 연구했다. downstream tasks에 성능이 감소하는데, 주로 confirmation bias 때문이다. 더 낮은 noise ratio가 나타내듯 parameter sharing으로 인해 captioner가 생성한 noisy captions이 filter로 인해 잘 걸러지지 않는 것이다.
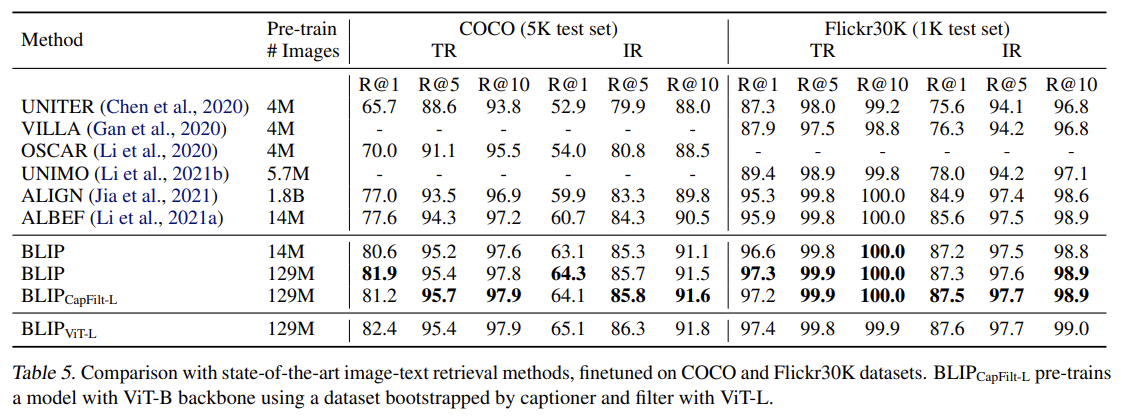
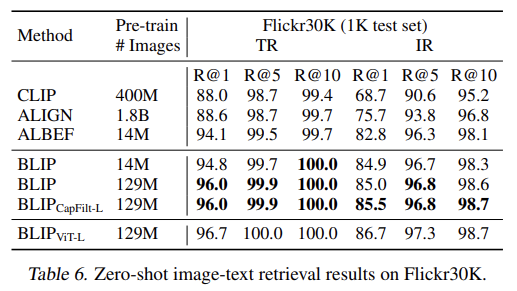
COCO와 Flickr30K 데이터셋에 image-to-text retrieval (TR)와 text-to-image retrieval (IR)을 평가한다. ITC와 ITM losses을 사용해 pre-trained model을 finetune한다. COCO에 finetune된 모델을 Flickr30K에 곧장 transfer해서 zero-shot retrieval도 수행한다.
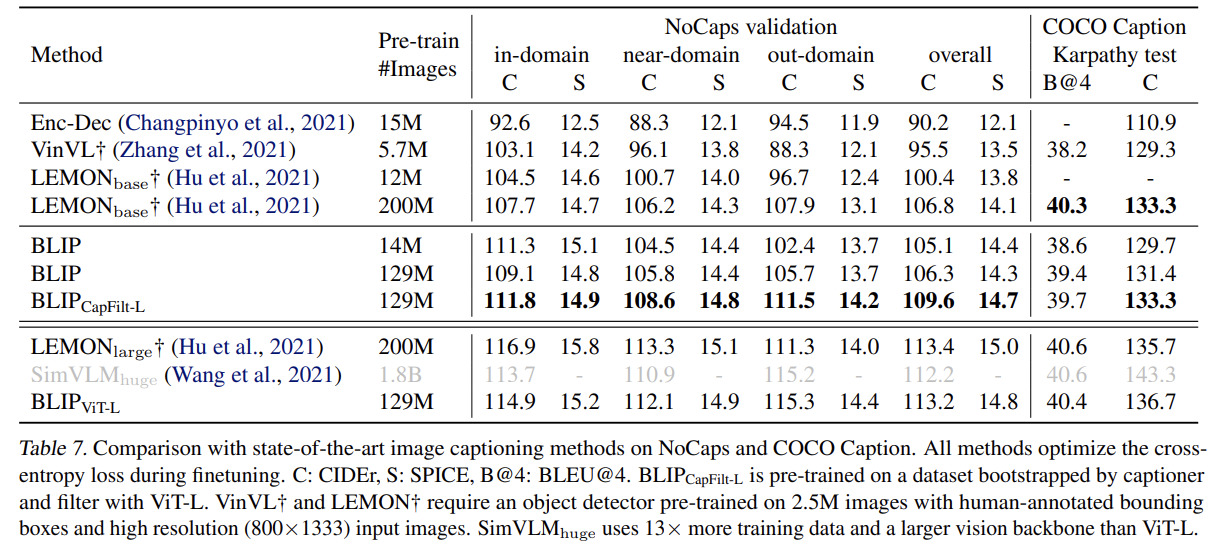
LM loss를 가지고 COCO에 finetune된 모델을 사용해 NoCaps와 COCO에 image captioning을 평가한다.
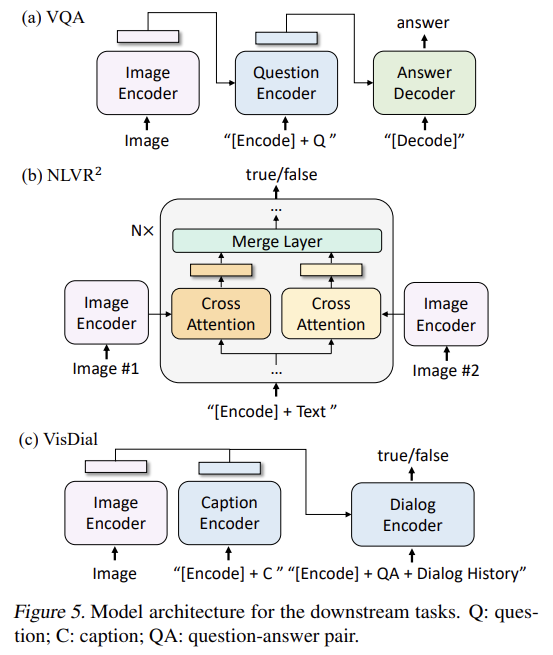
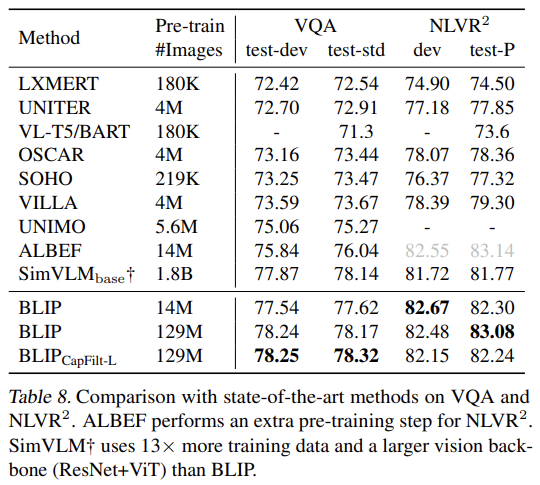
VQA를 multi-answer classification task로 형성하는 대신 Li et al. (2021a)을 따라 (open-ended VQA을 가능하게 하는) answer generation task로 간주한다. Fig 5a에서 볼 수 있듯 finetuning 중 pre-trained model을 재배열한다. image-question가 먼저 multimodal embeddings로 encode되고 answer decoder로 전해진다. VQA model은 ground-truth answers을 target으로 삼아 LM loss를 가지고 finetune된다.
NLVR2는 sentence가 images 쌍을 묘사하는지 묻는다. 두 images에 사고하는 것을 가능하게 하기 위해 pre-trained model에 간단한 변형을 가해 기존 방식들보다 더 연산 효율적인 architecture을 이끌어낸다. Fig 5b처럼 image-grounded text encoder 내 각 transformer block에 대해 2 input iamges를 처리하기 위해 2 cross-attention layers가 존재하고 그들의 output이 합쳐져 FFN에 먹여진다. 2 CA layers는 동일한 pre-trained weights로 초기화되었다. merge layer은 encoder의 처음 6 layers에서 단순한 average pooling을 수행하고 concatenation을 수행한 후 layer 6-12에서 linear projection을 한다. [Encode] token의 output embedding에 MLP classifier가 적용된다. (extra step of customized pre-training을 하는) ALBEF를 제외하고 BLIP가 모든 현존하는 방법을 능가한다.
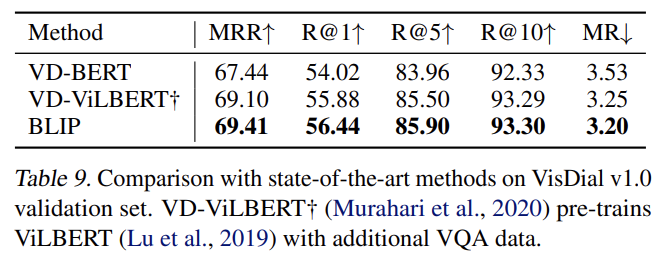
VisDial은 VQA를 natural conversational setting로 확장한다. 모델은 image-question pair뿐 아니라 dialog history와 image의 caption도 고려해서 answer를 예측해야 한다. 모델이 pool of answer candidates를 rank하는 discriminative setting을 따른다. Fig 5c에서 볼 수 있듯 image와 caption embeddings를 concatenate해서 cross-attention을 통해 dialog encoder에 전달한다. dialog encoder는 전체 dialog history와 image-caption embeddings가 주어졌을 때 question에 대한 질문이 참인지 거짓인지 구분하도록 ITM loss를 가지고 학습된다.
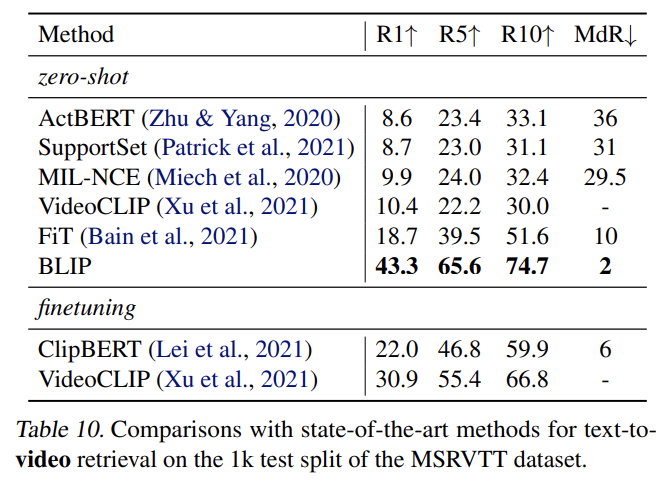
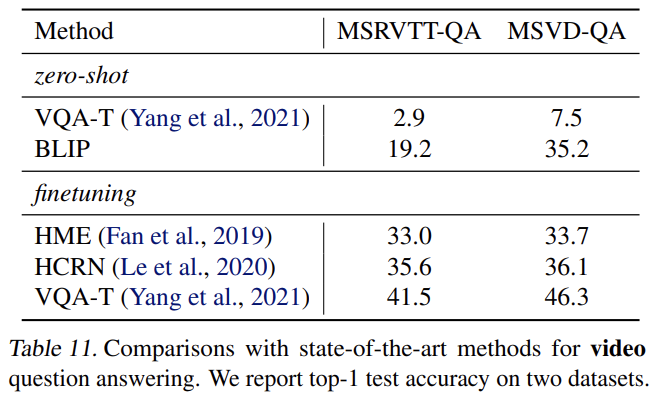
Tab 10, Tab 11에선 text-to-video retrieval과 video question answering으로 zero-shot transfer을 수행한다. 각각 COCO-retrieval과 VQA에 학습된 모델을 평가한다.


추가적인 ablation study도 한다. 설명은 생략한다.
Strengths
- CapFilt를 통한 data augmentation이 흥미로웠다. captioner로 (noisy한 것도 포함해서) caption을 만들고 filter로 noisy한 데이터를 제거해서 데이터의 양은 늘리면서 질도 높일 수 있었다.
- captioner와 filter의 parameter를 공유하지 않아서 filter가 captioner에 overfit?되지 않게 했다.
- understanding과 generation 분야 둘 다 SOTA를 달성했다.
- text encoder와 text decoder가 parameter를 공유하되 self-attention layer은 따로 둔 점이 흥미로웠다.
그동안 instructional video나 web caption 같은 데이터셋은 항상 noisy data 문제가 지적되었는데 그걸 일부나마 해소한 것 같아서 인상적이었다. captioner와 filter를 보고 GAN 생각도 났다.
cross-modal을 위해 image encoder와 text encoder 결과를 cross-attention하는 게 아니라 image-grounded text encoder를 따로 두는 구조가 신기했다.
