오늘 리뷰할 논문은 최초의 seq2seq이자 LSTM의 변형인 Gated Recurrent Units (GRU)를 제안한 논문이다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- [논문 리뷰] Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation
Summary
논문에선 2개의 RNN을 연결해 RNN Encoder–Decoder라고 이름붙인 모델을 만든다. encoder은 (길이가 자유로운) symbol의 sequence를 정해진 길이의 vector representation으로 encode하고 decoder은 그걸 (마찬가지로 자유로운 길이의, 그리고 물론 input과 길이가 다를 수도 있는) symbol의 sequence로 decode한다. 즉 source sequence가 주어졌을 때 target sequence를 내보내도록 conditional probability를 학습하는 것이다. 또 memory capacity와 training의 편의를 위해 정교한 hidden unit을 제안한다.
여기선 영어를 프랑스어로 번역하도록 RNN Encoder–Decoder을 훈련시킨다. 그리고나서 모델은 phrase table 내의 각 phrase pair에 점수를 매기는 식으로 standard phrase-based SMT(statistical machine translation) system의 일부로 사용된다. 이 방식은 translation 성능을 향상시킴을 경험적인 평가로 알 수 있다.
또 논문은 다른 번역 모델과의 phrase scores 비교를 통해 RNN Encoder–Decoder가 phrase table 내의 linguistic regularities를 포착하는 데 더 뛰어나다는 것을 보인다. 또 다른 분석은 이 모델이 phrase의 semantic, syntactic 구조를 보존하는 continuous space representation를 배운다는 것을 보인다.
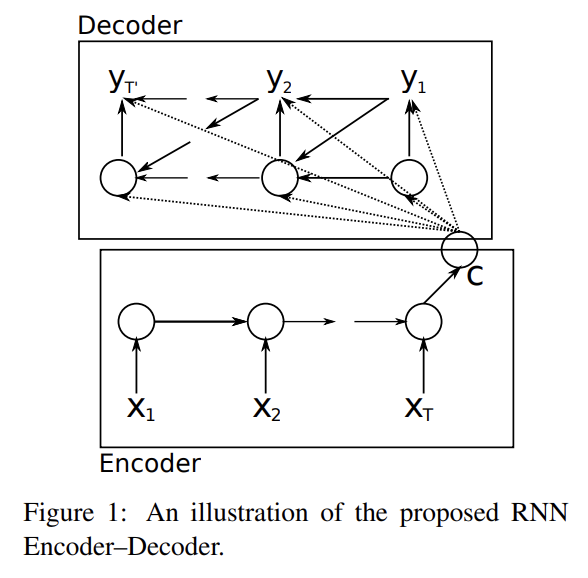
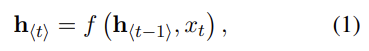
식 (1)은 일반적인 RNN이 작동하는 식이다. encoder가 input x를 차례대로 읽으며 hidden state를 변화시키고, sequence를 다 읽으면 hidden state는 전체 input sequence의 요약인 c가 된다.
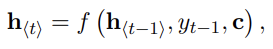
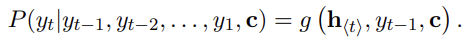
decoder은 hidden state h_t가 주어졌을 때 다음 symbol y_t를 예측하여 sequence를 생성한다. 이때 위 식과 같이 h_t와 y_t는 모두 y_t-1과 summary c를 전제로 계산된다. f, g는 activation function이며 g는 (softmax 등으로) 유효한(valid) probability를 계산한다.
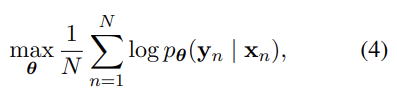
encoder와 decoder는 함께 conditional log-likelihood를 최대화하도록 학습된다. 학습된 모델은 두 가지로 사용될 수 있는데 1. input sequence를 넣어 그에 따른 target sequence를 생성할 수 있고 2. input과 output을 모두 제공한 후 점수를 매길 수도 있다. 이때 점수는 식 (3), (4)의 probability pθ(y | x)가 된다.
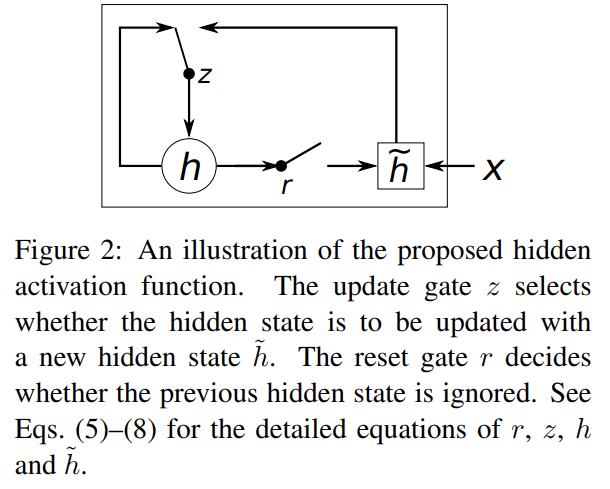
앞서 말했듯 논문은 LSTM에서 영감을 얻어 새로운 hidden unit을 소개한다. 형태는 Fig 2와 같으며 식 (1)에서의 f를 의미한다. 유닛 안에는 reset gate(r)와 update gate(z)가 존재하며 hidden state 계산은 다음과 같다. σ는 sigmoid, Φ는 hyperbolic tangent function를 사용했다.
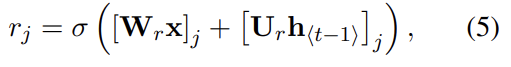
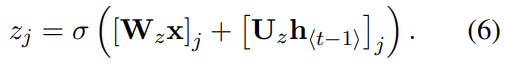
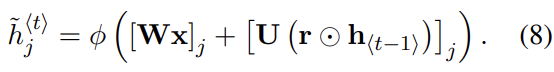
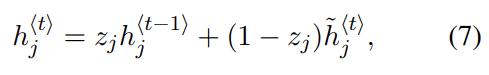
위의 식에서 reset gate가 0이 되면 hidden state가 이전 hidden state를 무시하고 현재 input으로 reset된다. 이는 어떤 정보가 미래에서 무용하다고 판단될 때 그걸 hidden state가 drop할 수 있게 하여 compact한 representation을 가능케 한다.
반대로 update gate는 이전 hidden state가 현재 hidden state에 얼마나 반영될지를 결정한다. 이는 LSTM의 memory cell처럼 작동하며 RNN이 long term information을 기억하게 한다.
각 hidden unit이 reset, update gate를 따로 가지고 있으므로 각 hidden unit은 서로 다른 time scales에 대한 dependency를 포착하도록 학습된다. 즉, short-term dependency를 포착하도록 배우는 unit들은 자주 활성화되는 reset gate를 가지며 longer-term dependency를 포착하는 unit들은 update gate가 자주 활성화된다.
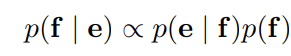
SMT system의 목표는 source sentence(e)가 주어졌을 때 translation(f)를 찾아 위의 식을 최대화하는 것이다. 이때 p(e|f)는
translation model, p(f)는 language model이라고 불린다.
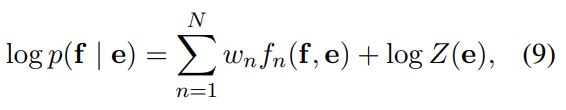
하지만 실제로는 대부분 SMT system들이 위와 같이 추가적인 feature(f)와 대응하는 weight(w)를 가진 log-linear model을 사용한다. Z(e)는 weight에 의존하지 않는 normalization constant다. weight들은 development set에서 BLEU score를 최대화하도록 학습된다.
SMT 모델들 중 phrase-based SMT에선 translation model이 source와 target 문장들의 phrases를 matching하는 translation probability(식 (9))로 환원된다.
논문에선 RNN Encoder-Decoder를 phrase pairs의 table로 학습시킨 후 SMT decoder를 tuning할 때 그 점수를 식 (9)의 additional features로 사용한다.
RNN Encoder-Decoder가 학습된 후 phrase table에 존재하는 각 phrase pair에 새로운 score를 추가해준다. 이러면 최소한의 추가적인 연산 overhead로 이미 존재하는 tuning algorithm에 새로운 score이 들어갈 수 있게 해준다.
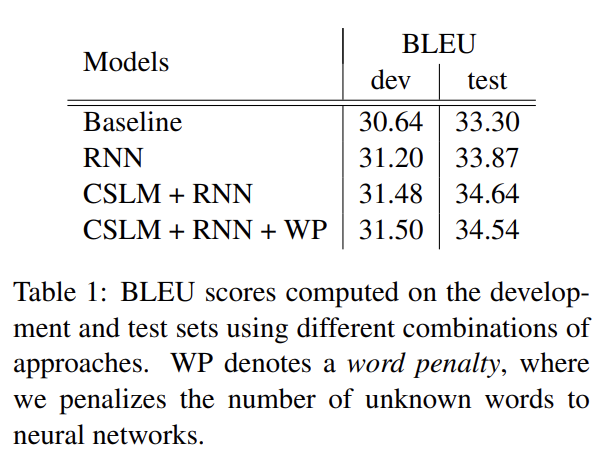

논문은 WMT’14 translation task로 English/French 번역 성능을 실험한다. baseline phrase-based SMT system는 default setting으로 Moses를 사용했고, development set과 test set에서 BLEU score를 각각 30.64, 33.3점을 받았다.
실험에 사용된 parameter나 implementation에 관한 세부사항은 리뷰에선 생략하겠다. 논문에선 baseline 모델에 RNN Encoder-Decoder을 적용하기도 하고 CSLM이라는 target language model도 함께 적용해보면서 RNN Encoder-Decoder의 효과를 확인한다. 논문은 RNN Encoder–Decoder에서 얻은 phrase scores와 CSLM을 동시에 사용했을 때 최고의 성능을 보이는 것을 보고 두 방법의 기여가 서로 독립적이라고 주장한다.
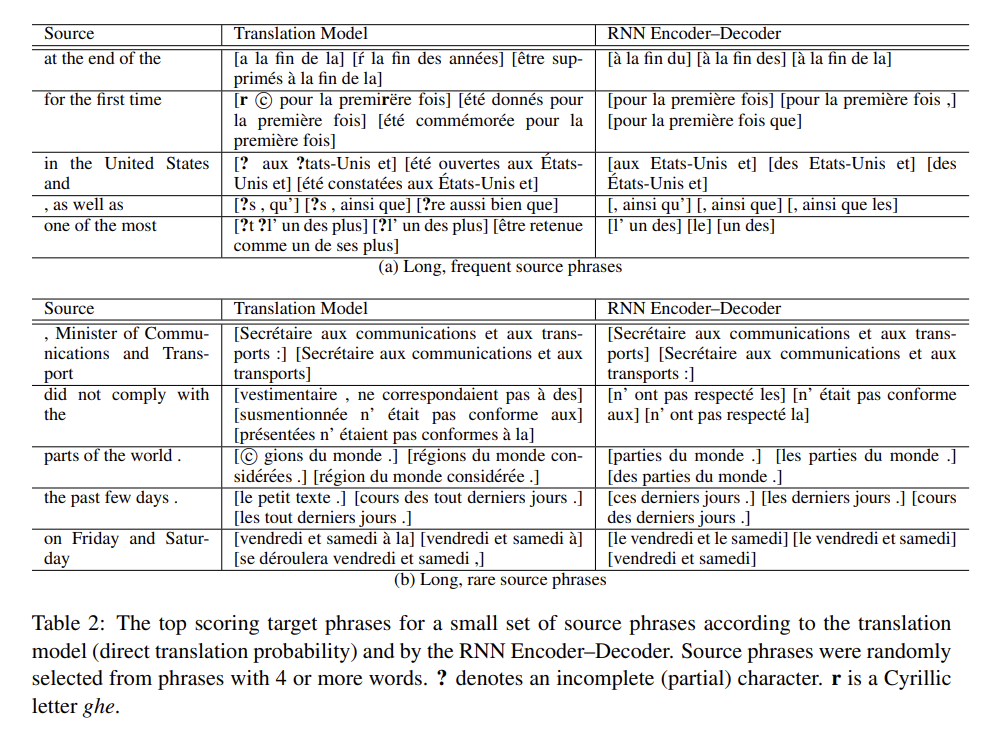
논문에선 정성적 평가도 실시한다. RNN Encoder–Decoder로 계산된 phrase scores를 translation model에서 온 상응하는 p(f | e)에 대해 분석한다. translation model이 corpus 내의 phrase pairs의 statistics에 전적으로 의존하기 때문에 freqeuent phrase는 잘 추정하지만 rare phrase는 잘 못할 거라고 저자들은 예상한다. 또 RNN Encoder-Decoder은 frequency information 없이 학습되었기 때문에 corpus에서의 occurrences statistics보다는 linguistic regularities에 기반할 것으로 기대된다.
table 2는 각 모델로 생성된, source phrase 당 top-3 target phrases 예시다. 대부분 경우에서 RNN Encoder–Decoder의 결과가 좀 더 actual/literal translations에 가깝다. 또 일반적으로 RNN Encoder–Decoder가 짧은 phrase를 좋아하는 것도 관찰할 수 있다.
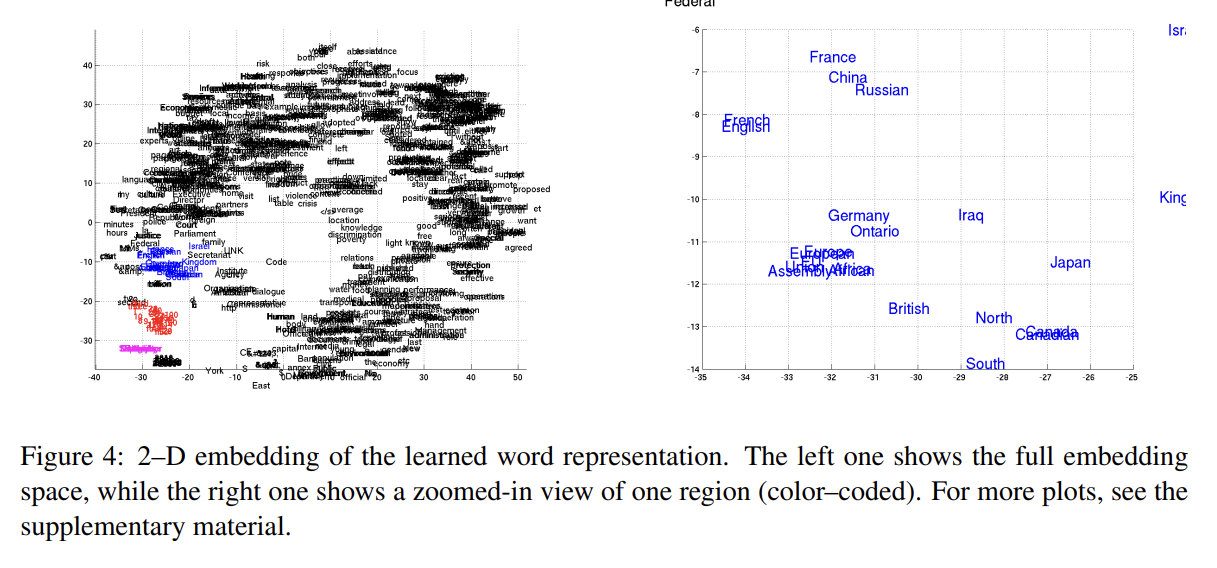

RNN Encoder–Decoder는 (continuous space vector, 즉 c를 사용하기 때문에) 의미있는 word embedding으로 사용될 수도 있다. 위의 사진들은 Hut-SNE로 시각화한 결과다. Figure 4를 보면 semantically 비슷한 단어들이 군집을 이루고 있음을 볼 수 있다. 또 RNN Encoder-Decoder는 phrase의 continuous-space representation도 생성한다. Figure 5를 통해 이 모델이 semantic, syntactic structures를 포착함을 알 수 있다. 왼쪽 아래 사진은 의미적으론 시간에 관한 내용이며 syntactically 비슷한 phrase들이 군집을 이룬다. 오른쪽 아래는 semantically 비슷한 phrase들이 군집을 이루며 반대로 오른쪽 위는 syntactically 비슷한 군집을 이룬다.
Strengths
- 데이터를 선택한, 전처리한 방법에 대한 이유를 설명해줘서 좋았다. 덕분에 왜 이런 방법을 택했는지 납득이 가능했다.
- 정량적, 정성적 평가를 모두 실시했다.
- 시각화를 통해 synatically/semantically 비슷한 word/phrase들이 서로 뭉쳐있는 것을 보여주어 모델의 능력을 직관적으로 보기 좋았다.
- input이 written language에 국한되지 않으므로 앞으로 speech transcription 등의 다른 application이 나올 가능성이 많다. 즉, 용도와 발전 가능성이 넓다.
Weaknesses
- SMT system 내에서 RNN Encoder-Decoder의 기여가 orthogonal(=independent)하다고 주장하는 근거가 부족한 것 같다.
