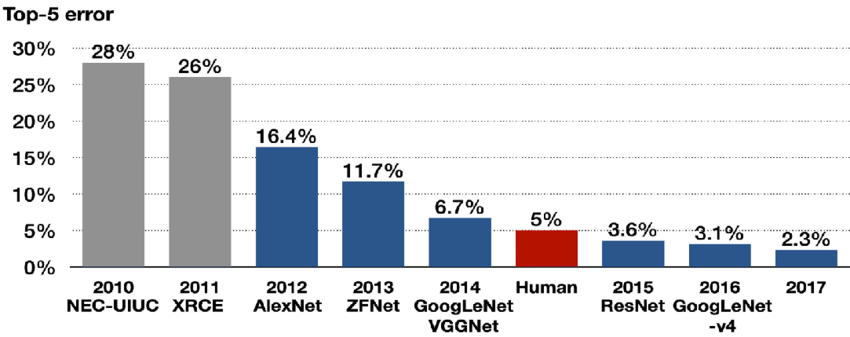
오늘 리뷰할 논문은 그 유명한 AlexNet 논문이다. ImageNet 데이터셋을 분류하는 대회에서 2012년 전년도에 비해 10%p나 오류율을 줄였고 이후로 image classification에 머신러닝이 우후죽순 사용하게 되었다. 유명한 모델이다보니 논문을 읽을 때도 흥미롭게 읽었던 것 같다.
Summary
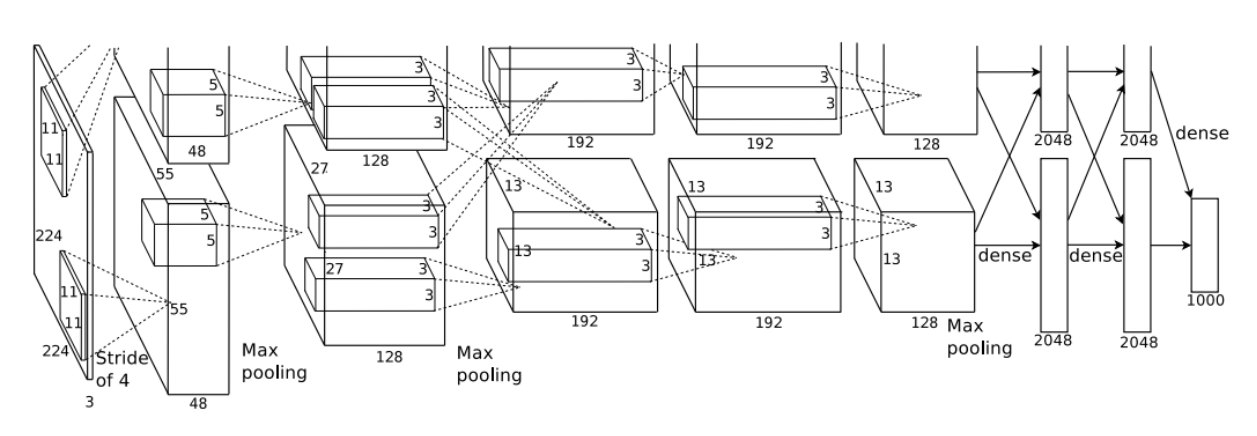
AlexNet의 뼈대가 되는 CNN이나 Max Pooling은 이 논문 이전에도 존재했던 기술이니 넘어가고, 이 논문의 특별한 점을 짚어보겠다.
-
input image 크기가 224x224로 고정되어 있다. ImageNet에는 다양한 크기의 이미지가 있는데, 이를 256x256 크기로 downsample한 후 data augmentation을 해서 224x224 크기의 이미지를 10개 만든다. 이는 이후 data augmentation을 설명할 때 다시 자세하게 다루겠다.
-
ReLUs(Rectified Linear Units)를 activation 함수로 사용했다. 기존에는 tanh나 Sigmoid를 사용했는데, 이런 saturating nonlinearity들은 ReLUs 같은 non-saturating nonlinearity보다 느리다. 더 적은 수의 epoch으로도 비슷한 error rate에 도달할 수 있다는 의미다. 이런 점에서 dataset과 model의 크기가 클 때 ReLU가 유리하다.
-
training에 GPU를 하나를 사용하지 않고 2개를 병렬적으로 사용했다. 이때 kernel(filter)을 GPU에 각각 절반씩 할당하고 특정 layer에서만 두 GPU가 교류하게 했다. 예를 들면 위의 사진에 나온 것처럼 layer3은 layer2의 모든 kernel의 값을 받아오지만 layer4에서는 자기와 같은 GPU에 속하는 layer3의 kernel만 사용한다. 이는 계산 부담을 덜 뿐더러 성능 향상 효과도 존재한다.
-
Local Response Normalization를 사용한다. 식은 아래와 같다.
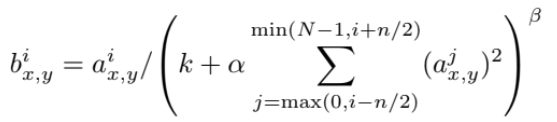
a는 (x,y) 위치에서 kernel i를 적용한 뉴런의 activity가 ReLU를 통과한 것이다. b는 a 주변의 n개(양옆으로 n/2개씩)를 normalize한 response-normalized activity다. N은 layer의 전체 kernel 개수고 k, n, alpha, beta는 hyper-parameter다. 이 normalization은 lateral inhibition을 구현하는데, big activity에서 다른 kernel로부터 계산된 출력과 경쟁을 일으키게 하는 효과가 있다. -
Overlapping Pooling을 한다. 전통적으로는 pooling시 adjacent pooling unit은 서로 overlap하지 않는데, 여기서는 3x3 pooling unit을 stride 2로 움직이면서 서로 겹치게 했다. 이는 약간의 error rate 감소 효과와 overfit 예방 효과가 작게 있었다.
-
Overfitting을 막기 위해 data augmentation을 했다. train 시에는 256x256 크기의 input 이미지에서 224x224 크기의 이미지 patch를 뽑아 이미지가 2048배 늘어나는 효과를 보았다. test 시에는 224x224 patch 5개를 랜덤하게 뽑고 그것을 수평으로 대칭시켜 총 10개의 이미지를 만든다. 그리고 그 10개 patch에 대한 prediction을 softmax로 average해서 최종 예측을 산출한다.
-
RGB channel intensity를 조작해 data augmentation을 하기도 했다. ImageNet trainning set에서 RGB pixel에 PCA를 실행해 (Gaussian 분포를 따르는 랜덤 값) alpha에 eigenvalue를 배수한 것을 principal components에 곱해서 본래의 RGB 값에 더해준다. 즉, 아래의 두 식을 더해 준다.
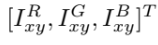
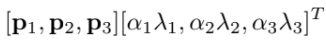
pi, labmda_i는 각각 RGB pixel값의 3x3 covariance matrix의 eigenvector, eigenvalue다. 이는 natural image에서 중요한 property를 capture해 조명의 intensity/color를 바꿔도 object identity를 변하지 않게 한다. 즉, label을 유지한 채 data augmentation의 효과가 있는 것이다. -
또 Overfitting을 방지하기 위해 처음 두 개의 fully connected layer에서 Dropout을 한다. train 시에 각 hidden 뉴런의 output을 50% 확률로 0으로 만든다. 이렇게 dropped out된 뉴런은 forward pass와 back propagation에 기여하지 못한다. 이는 뉴런이 다른 특정 뉴런의 presense에 의존할 수 없으므로 뉴런 간 co-adaptation을 줄인다. 따라서 뉴런들이 다른 랜덤한 뉴런들과 연계하여 사용할 때 효과적인 더 robust한 feature을 배우도록 강요한다. test 시에는 모든 뉴런을 사용하지만 대신 그들의 output에 0.5를 곱해 사용한다.
-
training error를 줄이고자 아래와 같은 weight decay를 사용했다.
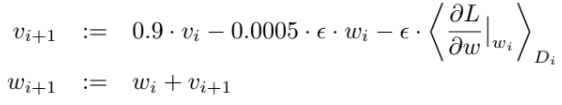
v는 momentum variable, e는 learning rate, 대괄호 항은 wi에서 계산한 w에 대한 Loss의 미분값을 i번째 batch Di에서 평균을 낸 것이다.
Strengths
- 당시 기준으로 매우 큰 neural network를 성공적으로 학습해 ILSVRC-2012에서 우승함으로써 이후 딥러닝의 가능성을 제시한 것이 역사적인 의의가 될 것이다.
- layer 하나만 빼도 성능이 줄어드는 것을 보여 layer 수도 중요하다는 것을 보였다.
- 당시에 생소했을 dropout을 도입하여 고질적인 overfitting 문제를 효과적으로 다룬 것도 좋았다.
- computation적으로 영리한 기법들을 사용했다. GPU 2개를 병렬적으로 사용할 수 있는 architecture을 고안해 계산 부담을 던 것, data augmentation을 CPU가 담당하게 하여 사실상 GPU의 부담 없이 data를 늘린 것 등이 좋았다.
Weaknesses
- 이미지 preprocess 과정에서 이미지 크기를 강제로 256x256으로 맞추는데 이 과정이 세련되지 못한 것 같다. 강제로 크기를 끼워맞추는 부분에서 성능 저하가 발생했을 수도 있다고 생각한다. 기왕이면 일반적인 input size에도 모델이 적용 가능하면 더 좋았을 것이다.
- 사실 논문에서 Local Response Normalization를 한 것이나 Overlapping Pooling을 한 건 큰 효과가 없는 것 같다. 의미가 있는지 잘 모르겠다.
RGB를 SVD분해해서 data augmentation하는 기법이 흥미로웠다. 저런 식으로도 data augmentation이 가능하구나 하는 감상이 들었다.

또 GPU 2개를 따로 학습시켰더니 첫 layer에서 각 GPU의 kernel이 보인 양상이 흥미로웠다. GPU 1의 kernel은 하나같이 색깔에 무지한데(color-agnostic), GPU 2의 kernel은 전부 color-specific하다. 어떻게 랜덤하게 initialization을 해도 이런 특화가 항상 관찰된다는 점이 인간의 좌뇌 우뇌가 다른 역할을 맡는 것처럼 neural network의 layer/neuron이 특화되는 것 같아서 신기했다.
역사적으로도 의미가 깊고 내용도 재미있어서 읽는 내내 흥미로웠던 논문인 것 같다.
