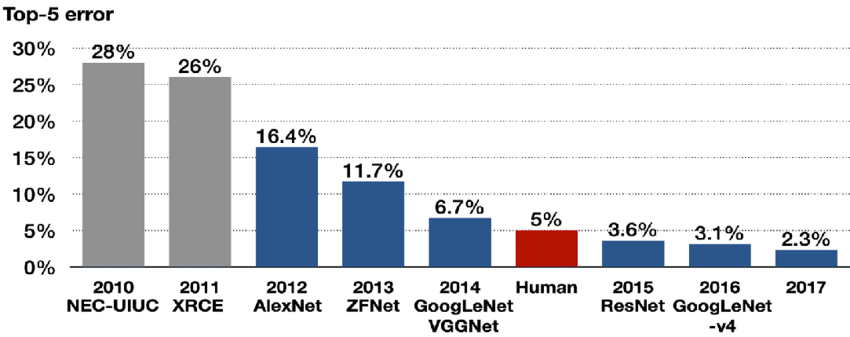
이번에 리뷰할 논문은 ZFNet 논문이다. 의도한 건 아닌데 어쩌다 보니 AlexNet 논문을 리뷰한 다음 순서로 이 논문을 리뷰하게 되었다. 이 논문이 ILSVRC-2013에서 우승하긴 했지만 ZFNet은 AlexNet을 약간 손 본 것에 지나지 않기 때문에 모델 자체에 의미가 있다기보다는 convolutional network의 내부 구조와 작동 방식을 어떻게 이해할지, 시각화하여 해석/분석하는 방법론을 제시하여 성능을 끌어올린 데에 중요한 의미가 있다고 할 수 있다.
아래 포스트들을 먼저 읽으면 이해하기 쉽다.
- https://arclab.tistory.com/164
- https://velog.io/@lolo5329/%EB%85%BC%EB%AC%B8-%EC%9A%94%EC%95%BD-Visualizing-and-Understanding-Convolutional-Networks
- https://velog.io/@lm_minjin/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Visualizing-and-Understanding-Convolutional-Networks
- https://deepapple.tistory.com/14
Summary
이 논문은 convnet의 뛰어난 성능에도 불구하고 내부 작동이나 어째서 이런 좋은 결과를 내는지, 어떻게 network를 improve할 수 있을지에 대한 통찰이 부족한 문제 상황을 해결하고자 visualization technique을 소개한다. 이를 위해 multi-layered Deconvolutional Network(deconvnet)를 사용하며 feature activation을 다시 input pixel space로 project하는 역할을 한다. 즉 convnet의 역과정을 실행하여 결과로부터 원인을 찾는 것이다. 이러면 본래 어떤 input pattern이 feature map 내의 activation을 유발하는지 알 수 있다.
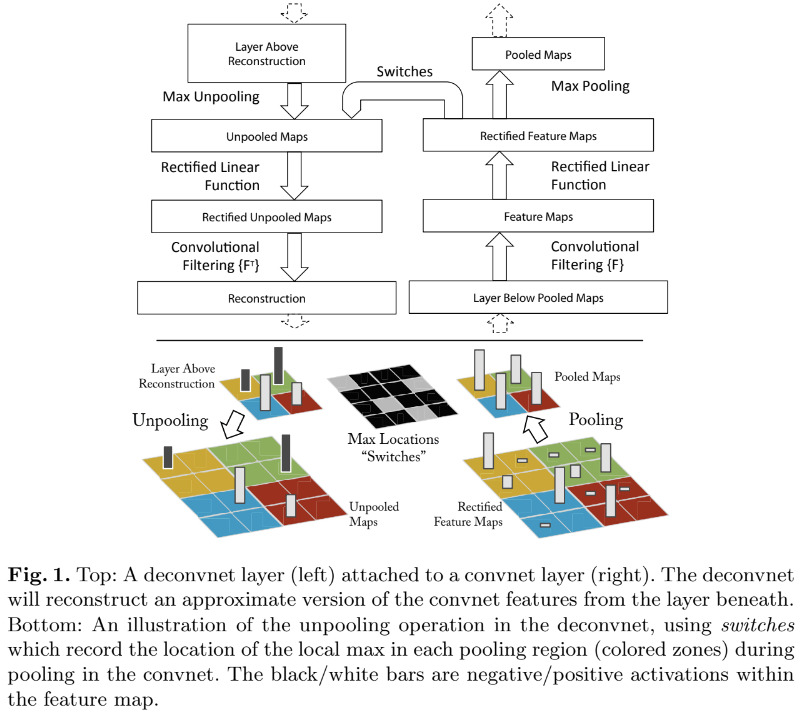
deconvnet은 convnet의 각 layer마다 붙어서 주어진 convnet activation의 feature map을 input으로 삼는다. 그리고 해당 activation을 일으킨 activity를 reconstruct하기 위해 1. unpool 2. rectify 3. filter의 과정을 거친다.
-
unpool
convnet의 max pooling은 non-invertible한데, max pooling은 최대값만 선택하고 나머지는 버리는 거라 필연적으로 정보의 손실이 발생하기 때문이다. 그래서 논문에서는 approximate inverse라도 얻기 위해 pooling에서 maxima 값의 location을 기록하는 'switch' 변수를 도입한다. 그리고 deconvent에서 switch의 위치에 값을 unpooling한다. -
rectification
convnet에서는 ReLU를 사용해 feature map이 항상 poisitive을 보장한다. deconvnet에서도 ReLU를 거쳐 feature reconstruction을 한다. -
filtering
deconvnet은 convnet filter의 transposed 버전 필터를 사용해서 filtering을 한다. (아마도 filter가 orthogonal한, A^TA=I인 특성을 이용하는 것 같다)
contrast normalization은 하지 않는다.
convnet model은 AlexNet과 크게 다르지 않은데, 두 가지 차이라면 AlexNet에서 layer 3,4,5가 (GPU 2개 사용한 것 때문에) sparse connection을 사용한 게 여기서는 dense connection으로 바뀐 것과 layer 1,2에 변화를 준 것이다.
이제 Convnet Visualization을 살펴보자.
- Feature Visualization

각 layer에서 deconvnet으로 reconstruct한 사진이다. 이는 네트워크 내에서 feature의 hierarchical nature를 보여준다. Layer 2는 corner와 other edge/color conjunctions, Layer 3는 더 복잡한 invariance나 similar texture를 cature하고 Layer 4는 significant variation을 보여주며 더 class-specific하고, Layer 5는 entire objects with significant pose variation를 보여준다.
- Feature Evolution during Training

lower layer는 적은 epoch로도 수렴하지만 upper layer은 상당한 epoch(약 40-50)가 필요하다. 즉 이런 시각화를 통해 깊은 layer일수록 학습에 더 많은 epoch이 필요함을 알 수 있다.
- Architecture Selection
논문에서는 AlexNet의 layer 1,2를 시각화하여 두 가지 문제점을 찾아내고, 이를 layer 1에서 filter 크기를 11x11에서 7x7로 고치고 layer 1,2의 stride도 4에서 2로 조정하는 것으로 문제를 해결한다. 이렇게 architecture selection에 visualization이 사용될 수도 있다.
- Occlusion Sensitivity

model이 실제로 object를 detect하는지, 아니면 단지 주변 context를 이용하는지도 visualization을 통해 판별할 수 있다. 위의 사진처럼 회색 사각형으로 input image 일부를 가리고 결과를 보면 올바르게 classify할 확률이 상당히 감소하는 것으로 model이 사물을 localizing한다고 알 수 있다.
(c)는 이렇게 나온 feature를 다시 input image space로 reconstruct한 결과이다. 첫 행을 예로 들면 개의 얼굴이 가장 강한 feature임을 보여준다. 사진의 (e)는 회색 사각형으로 가린 위치에 따라 어떻게 detect 결과가 나오는지를 보여준다. 예를 들어 첫 행의 개는 대부분 위치에서 “pomeranian”이라고 정확하게 인식하지만 얼굴을 회색 사각형으로 가리면 “tennis ball”라고 인식한다.
ablation study도 하는데... 내용은 생략하고 결과는 모델의 성능에 개별 섹션보다 네트워크 깊이를 최소화하는 게 더 좋다는 것이다.
Strenghts
- visualization의 여러 용도를 보여준 게 좋았다.
- feature이 random하거나 무작위한 pattern이 아님을 보여주었다. 깊은 layer일수록 compositionality, invariance와 class discrimination에 강한 규칙성을 보여주었다.
- ImageNet 외에도 여러 dataset을 비교하여 성능을 보장한 게 좋았다.
- visualization을 model debugging 용도로 사용할 수 있다는 가능성을 제시했다.
Weaknesses
- model이 AlexNet과 크게 다르지 않은 점은 아쉬웠다. visualization을 통해 어떻게 수정했는지를 의의로 봐야 할 것 같다.
