오늘 리뷰할 논문은 GPT-1 논문이다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- [논문 리뷰] GPT-1 : Improving Language Understanding by Generative Pre-Training (OpenAI)
- GPT-1 논문 리뷰 - Improving Language Understanding by Generative Pre-Training paper review
NLP에는 다양한 task가 있고 large unlabeled text corpora는 많지만 specific task를 위한 labeled data는 적다. 논문은 language model을 diverse unlabeld text corpus에 generative pre-training를 한 후 각 specific task에 discriminative fine-tuning를 하면 된다고 주장한다. 기존의 연구와 달리 논문은 fine-tuning 도중 effective transfer를 이루고 model architecture을 최소한으로 바꾸기 위해 task-aware input transformations를 한다. 논문의 task-agnostic model은 연구한 12 task 중 9개에서 SOTA를 달성한다.
unlabeled text에서 word-level information 이상을 leverage하려면 두 가지 이유로 어렵다. 첫째로 transfer에 유용한 text representations을 배우려면 어떤 optimization objectives이 가장 유용한지 불확실하다. 둘째로 learned representations를 target task로 transfer하는 가장 효과적인 방법에 대한 의견 일치(consensus)가 없다.
논문은 unsupervised pre-training과 supervised fine-tuning를 결합한 semi-supervised approach를 탐구한다. 논문의 목표는 little adaptation만 가지고도 wide range of tasks에 transfer하는 universal representation을 학습하는 것이다. large corpus of unlabeled text와 several datasets with manually annotated training examples (target tasks)로의 access를 가정하며 이 setup은 target tasks가 unlabeled corpus와 같은 domain에 있기를 요구하지 않는다. two-stage training procedure을 사용하며 첫째로 neural network model의 initial parameter을 배우기 위해 unlabeled data에 language modeling objective를 사용하고 둘째로 corresponding supervised objective를 사용해 앞선 parameters를 target task에 adapt한다.
model architecture은 tranformer을 사용한다. 이는 text 내의 long-term dependencies를 다루는 더 잘 구조화된 기억(memory)을 제공한다. transfer 중에는 traversal-style approaches [52]에서 유래한 task-specific input adaptations 를 사용해서 structured text input를 single contiguous sequence of tokens로 가공한다. 이는 pre-trained model의 architecture을 최소한으로 바꾸고 효과적으로 fine-tune할 수 있게 한다.
우선 첫번째 단계인 Unsupervised pre-training부터 알아보자. unsupervised corpus of tokens U = {u1, . . . , un}가 주어졌을 때, 다음 likelihood를 최대화하기 위해 standard language modeling objective를 사용한다.
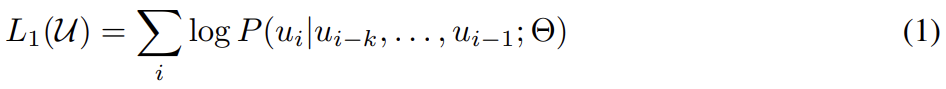
k는 context window의 크기고 conditional probability P는 parameters Θ를 가진 neural network로 model된다. parameters는 stochastic gradient descent를 통해 학습된다.
논문은 language model로 multi-layer Transformer decoder [34]를 사용한다. 이 모델은 multi-headed self-attention operation을 input context tokens에 적용한 후 position-wise feedforward layers를 사용해 output distribution over target tokens를 생성한다.
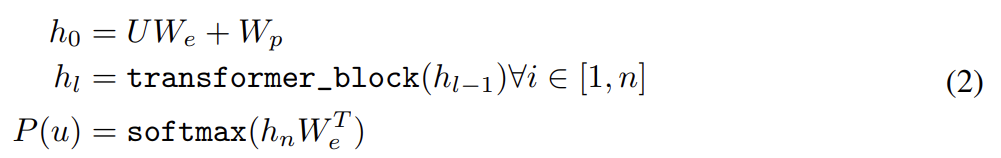
U = (u−k, . . . , u−1)는 tokens의 context vector고 n은 layers 수, We는 token embedding matrix, Wp는 position embedding matrix이다.
두번째 단계는 Supervised fine-tuning이다. 식 (1)로 pre-training이 끝난 후 parameters를 supervised target task로 adapt해야 한다. 각 instance가 sequence of input tokens, 와 label y로 이루어진 labeled dataset C를 가정한다. inputs는 pre-trained model를 통과해 final transformer block’s activation 를 얻어 parameters Wy를 가진 added linear output layer에 먹여져 y를 예측한다.
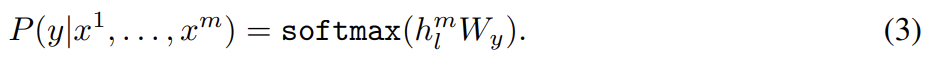
이는 다음 식을 최대화하게 한다.
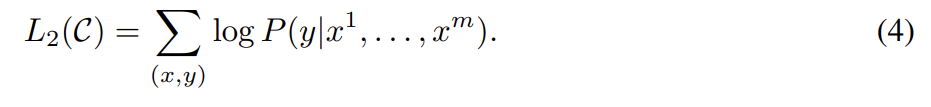
또 논문은 fine-tuning에 auxiliary objective로써 language modeling을 포함하는 것이 1. supervised model의 generalization을 향상시키고 2. convergence를 가속함으로써 학습을 도움을 발견했다. 구체적으로는 weight λ를 가진 다음 objective를 최적화한다. (즉 fine-tuning 시에 target task의 objective만을 사용하는 게 아니라 pre-training의 objective도 포함시키는 것이다)

fine-tuning 중 필요한 extra parameters는 Wy와 delimiter tokens를 위한 embeddings 뿐이다.
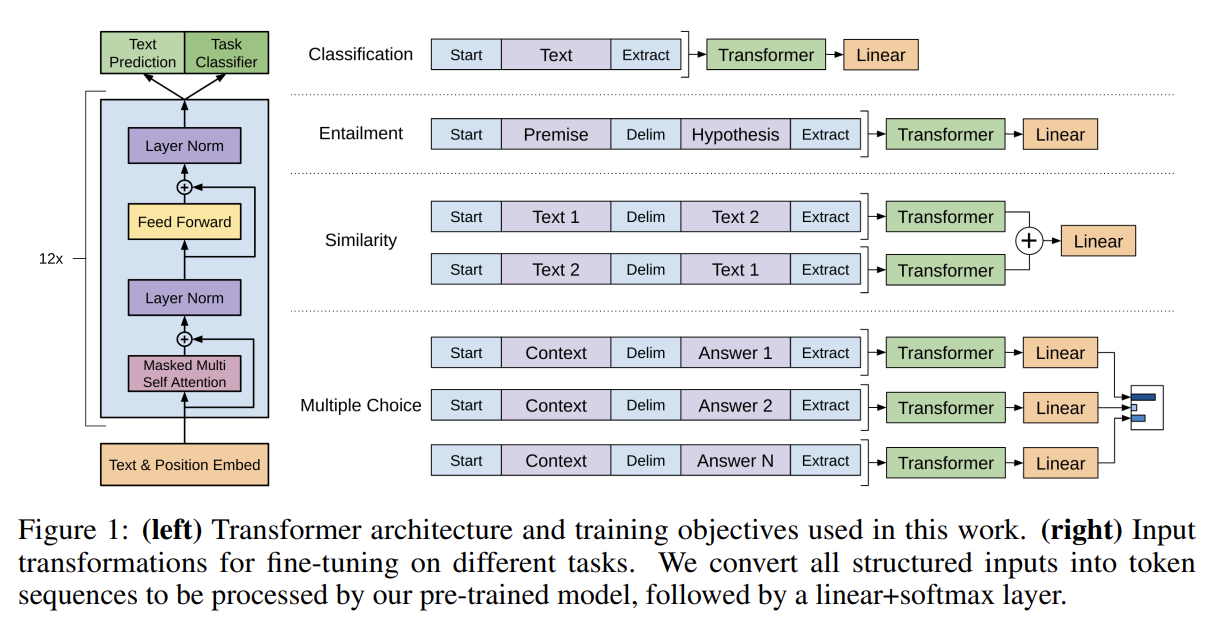
이제 Task-specific input transformations에 대해 알아보자. text classification 같은 task들은 model을 위와 같이 directly fine-tune할 수 있다. 그러나 question answering나 textual entailment 같은 task들은 ordered sentence pairs나 document, question, answers의 triplet 등 특수한 structured inputs를 요구한다. 우리의 pre-trained model이 contiguous sequences of text에 학습되었기 때문에 저런 task에 적용하려면 modification이 필요하다.
기존의 연구는 transferred representation 위에 task specific architecture을 추가하는 방식인데 논문은 traversal-style approach [52]를 사용해서 structured inputs를 pre-trained model가 처리할 수 있는 ordered sequence로 바꾼다. 모든 transformation은 randomly initialized start, end tokens (<si, ei>)을 추가하는 작업을 포함한다.
논문은 4종류의 task에 실험하는데 각 task에 대한 input transformation은 다음과 같다.

실험의 경우 Unsupervised pre-training을 위해 BooksCorpus dataset [71]을 사용한다. 이는 긴 범위의 연속된 text(long stretches of contiguous text)를 포함하기에 generative model이 long-range information을 배울 수 있다. alternative dataset으로는 비슷한 크기의 1B Word Benchmark와 ELMo [44]가 있지만 문장 단위로 shuffle되어 있어 long-range structure가 파괴되어있다.
model은 original transformer work(Attention is all you need)를 따르며 masked self-attention heads (768 dimensional states와 12 attention heads)를 가진 12-layer decoder-only transformer를 학습시켰다. position-wise feed-forward networks로는 3072 dimensional inner states를 사용했다. Adam optimization scheme을 사용했다. layernorm [2]이 model에 널리 사용됐기 때문에 N(0, 0.02)로 간단하게 weight initialization하면 충분했다. 40,000 merges를 가진 bytepair encoding (BPE) vocabulary [53]를 사용했고 regularization을 위해 0.1 rate로 residual, embedding, attention dropouts을 했다. L2 regularization의 modified version [37]을 사용했다(w = 0.01 on all non bias or gain weights). activation function으로는 Gaussian Error Linear Unit (GELU) [18]를 사용했다. original work(Attention is all you need)에서 사용한 sinusoidal version 대신 learned position embeddings를 사용했다. BooksCorpus 내의 raw text를 clean하고 punctuation과 whitespace를 standardize하기 위해 ftfy library를 사용했고 spaCy tokenizer를 사용했다.
fine-tuning의 경우 따로 명시되지 않은 이상 unsupervised pre-training과 같은 hyperparameter setting을 사용했고 classifier에 rate 0.1의 dropout을 추가했다. λ는 0.5로 설정했다.
논문은 natural language inference, question answering, semantic similarity, and text classification를 포함한 여러 supervised tasks에 실험을 한다. 몇 task는 GLUE multi-task benchmark [64]의 일부다.
- Natural Language Inference (NLI)
NLI는 textual entailment를 인식하는 것이며 문장 쌍을 읽고나서 그들의 관계를 entailment, contradiction이나 neutral로 판단하는 것을 포함한다. 논문은 image captions (SNLI), transcribed speech, popular fiction, and government reports (MNLI), Wikipedia articles (QNLI), science exams (SciTail), news articles (RTE)를 포함하는 다양한 source를 가진 다섯 dataset에 평가한다. 결과는 모델이 여러 문장에 걸쳐 reason하는 것을 잘하고 linguistic ambiguity를 잘 다룸을 입증한다.
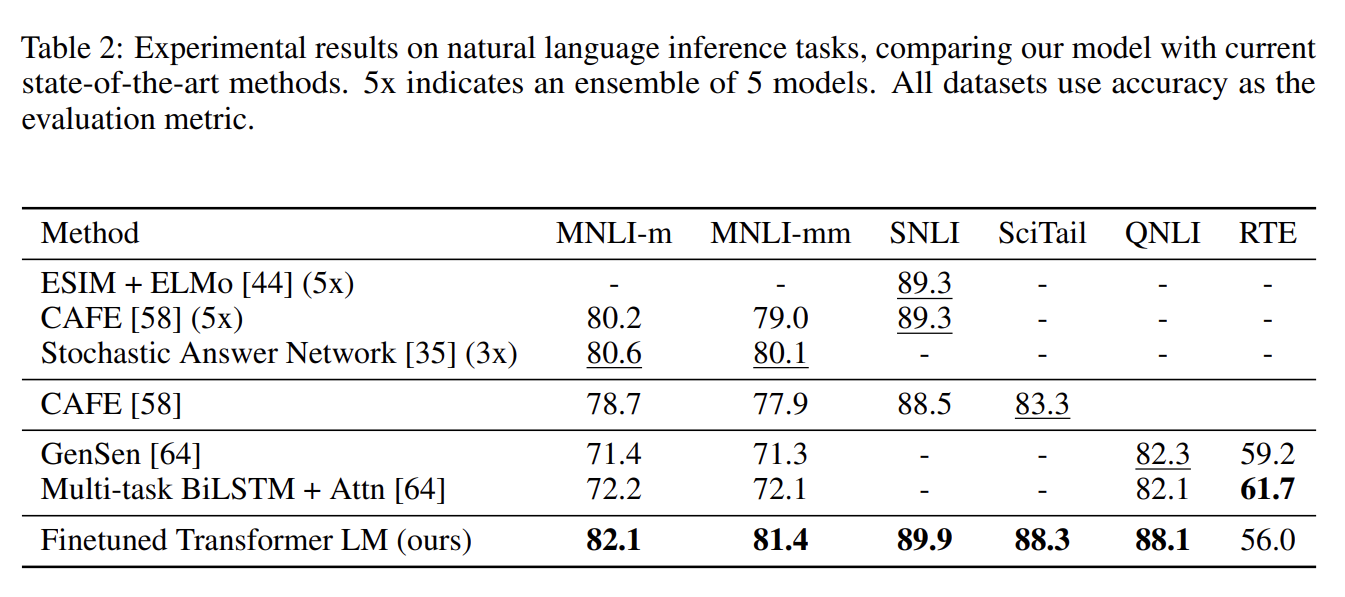
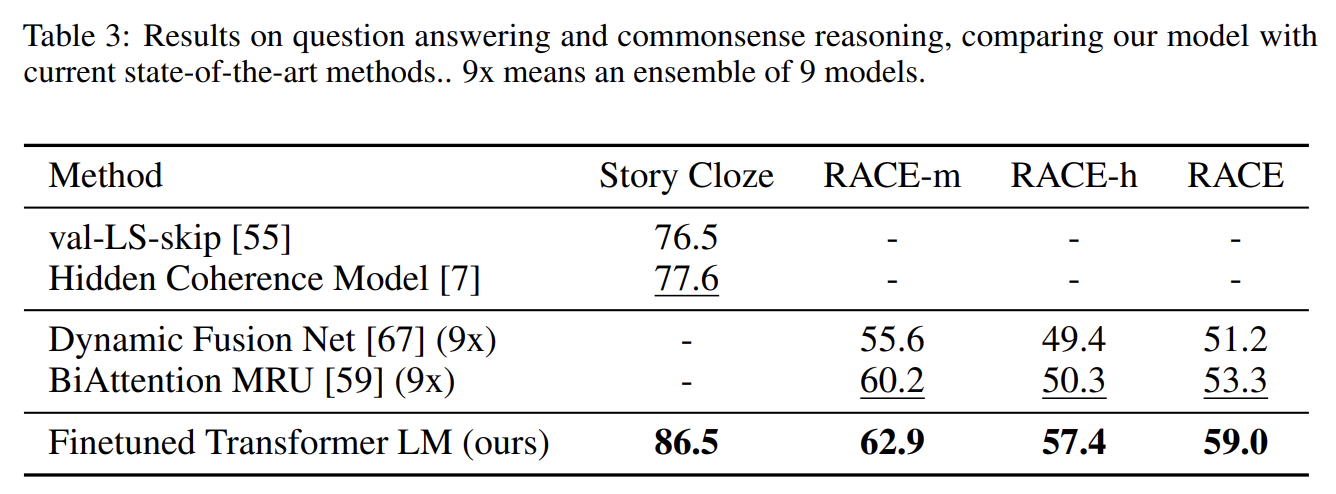
- Question answering and commonsense reasoning
RACE dataset [30]와 Story Cloze Test [40]를 사용했다. 결과는 모델이 long-range contexts를 효과적으로 다룸을 입증한다.
- Semantic Similarity (or paraphrase detection)
semantic similarity는 두 문장이 의미적으로 동일한지 아닌지 예측하는 것이다. dataset은 Microsoft Paraphrase corpus (MRPC) [14], Quora Question Pairs (QQP) dataset [9] Semantic Textual Similarity benchmark (STS-B) [6]을 사용했다.
- Classification
text classification task 2개를 했다. Corpus of Linguistic Acceptability (CoLA) [65]는 문장이 문법적인지 아닌지 판단하며 trained model의 innate linguistic bias를 시험한다. Stanford Sentiment Treebank (SST-2) [54]는 standard binary classification task다.
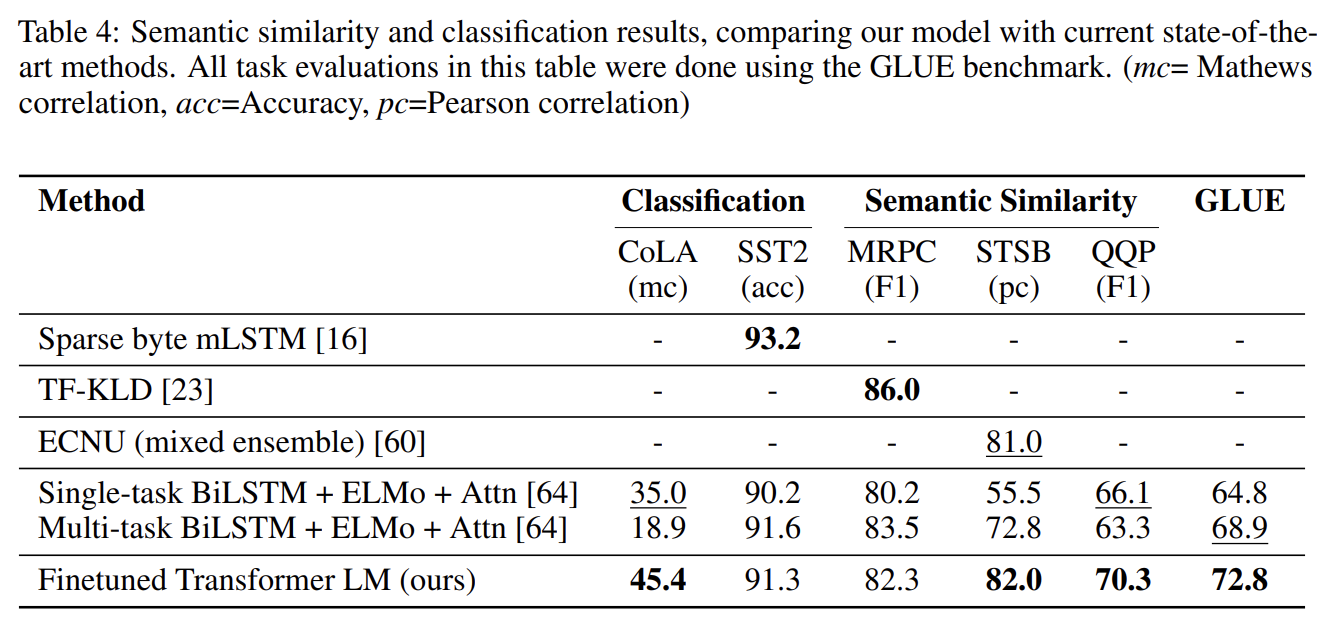
- Impact of number of layers transferred
또 논문은 unsupervised pre-training에서 supervised target task로 transfer하는 layer 개수의 영향을 분석했다. MultiNLI와 RACE에서 성능을 관찰했고 transferring embeddings이 성능을 향상시킨다는 것과 각 transformer layer이 최대 9%까지 성능을 향상시킨다는 일반적인 결과를 얻었다. 이는 pre-trained model의 각 layer가 target task를 푸는 데 유용한 기능을 포함함을 의미한다.
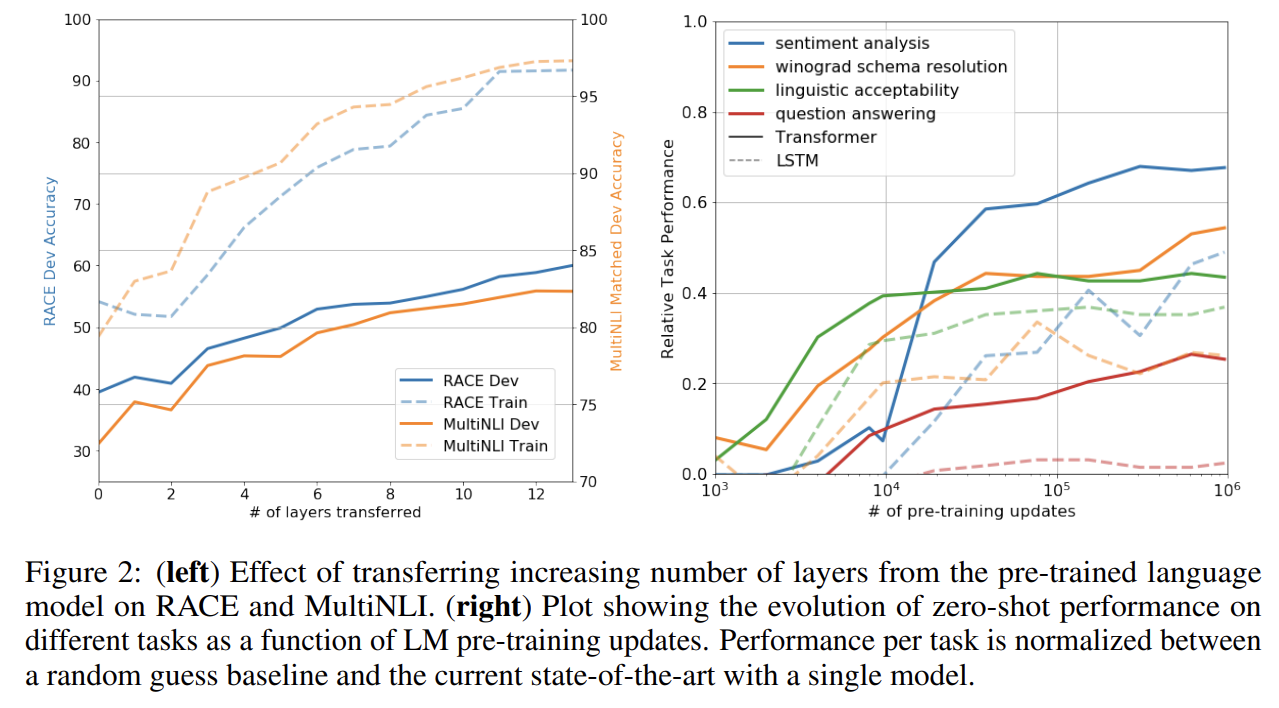
- Zero-shot Behaviors
논문은 왜 trasformer를 사용한 language model이 pre-training에 효과적인지 이해하고자 했다. 이에 대한 가설을 세웠는데, underlying generative model이 language modeling의 capability를 향상시키기 위해 많은 tasks을 배울 수 있고, LSTM에 비해 transformer의 더 구조화된 attentional memory가 transfer에 도움이 된다는 것이다. 이를 위해 몇 가지 heuristic solutions를 디자인했는데, supervised fine-tuning 없이 (그냥 바로) underlying generative model를 사용하는 것이다. Fig 2에서 이 heuristics가 stable하고 training에 따라 꾸준하게 증가함을 보여 generative pretraining이 다양한 task와 관련된 기능을 배우게 도움을 알 수 있다. 또 LSTM이 zero-shot performance에서 더 높은 variance를 보이는 것으로 transformer architecture의 inductive bias가 transfer을 돕는다는 것도 알 수 있다.
- Ablation studies
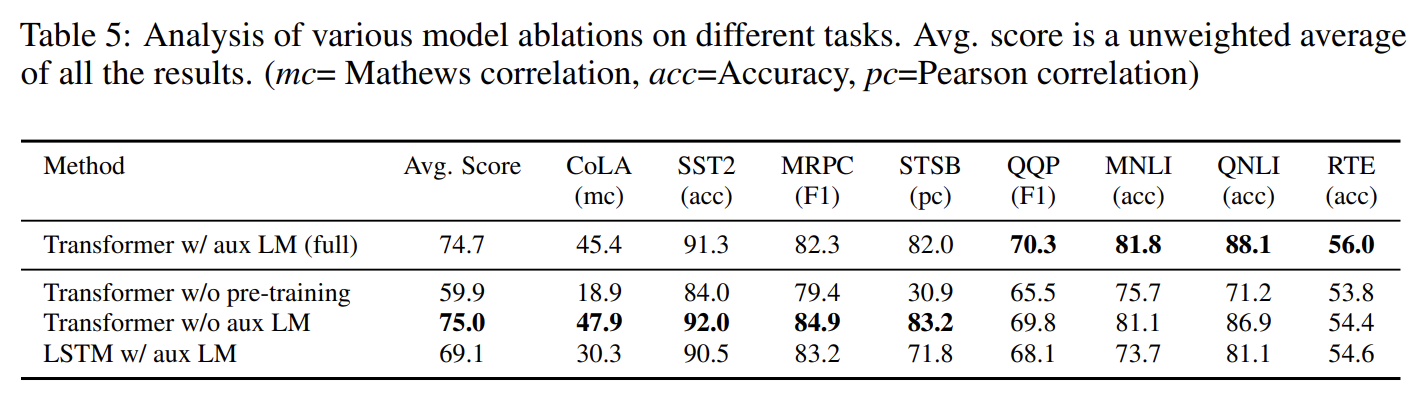
세 가지 ablation study를 했다. 첫째로 fine-tuning 중에 auxiliary LM objective 없이 성능을 평가한다. auxiliary objective가 NLI tasks와 QQP를 도움을 알 수 있었다. 전반적으로 큰 dataset일수록 auxiliary objective로부터 이익을 받고 작은 dataset은 아님을 알 수 있었다. 둘째로 single layer 2048 unit LSTM와의 비교를 통해 transformer의 효과를 확인했다. LSTM은 5.6 average score drop이 있었고 MRPC 하나에서만 더 성능이 좋았다. 마지막으로 모델을 pre-training 없이 직접 supervised target tasks에 학습시켜 성능을 비교했다. 그 결과 모든 task에서 성능이 하락했다.
Strengths
- generative pre-training와 discriminative fine-tuning의 두 단계를 통해 single task-agnostic model을 만들었다.
- 각 task에 fine-tuning할 때 architecture을 추가하는 대신 input을 변환시키는 것으로 architecture 변화를 최소화했다.
- auxiliary objective을 통해 성능을 향상시켰다.
