오늘 리뷰할 논문은 GPT-2 논문이다.
GPT-1은 transformer를 사용해 약간의 fine-tuning만으로 여러 NLP task에서 SOTA를 달성했고 zero-shot의 가능성을 시사했다. GPT-2의 목적은 fine-tuning 없이 unsupervised pre-training만을 통해 zero-shot으로 down-stream task를 진행할 수 있는 general language model을 개발하는 것이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰, GPT-2]Language Models are Unsupervised Multitask Learners
- [논문 리뷰] Language Models are Unsupervised Multitask Learners
- GPT-2 논문 정리(논문 리뷰) - Language Models are Unsupervised Multitask Learners paper review
Summary
GPT-1 논문처럼 이 논문도 multitask learning에 관심을 가진다. 논문은 zero-shot setting (without any parameter or architecture modification)에서 language model이 down-stream tasks를 수행할 수 있음을 입증한다.
language modeling이란 variable length sequences of symbols
(s1, s2, ..., sn)로 이루어진 set of examples (x1, x2, ..., xn)로부터의 unsupervised distribution estimation를 의미한다.
single task를 수행하도록 학습한다는 것은 conditional distribution p(output|input)를 추정하는 probabilistic framework로 생각할 수 있다. general system은 여러 task를 수행해야 하므로 input뿐 아니라 task에도 condition되어 p(output|input, task)의 형태를 띤다.
대부분의 선행 연구들은 dataset을 뉴스 기사, 위키피디아, 소설책 등 하나의 domain을 사용한다. 그러나 논문은 가능한 다양한 domains와 contexts에서 크고 다양한 dataset을 만들고자 한다.
이런 점에서 유망한 source는 Common Crawsl 같은 web scrapes가 있다. 그렇지만 web scraping은 중대한 data quality issue가 있다. 그래서 논문은 document quality를 강조하는 새로운 web scrape를 만들었다. 사람에 의해 curated/filtered된 web page만 scrape한 것이다. 결과적으로 만들어진 데이터셋은 WebText라고 이름 붙였다.
general language model (LM)은 어떤 string이라도 probability를 계산하고 또 string을 생성할 수 있어야 한다. 최근의 large scale LMs는 lower-casing, tokenization, out-of-vocabulary tokens 같은 pre-processing을 포함하는데 이는 space of model-able strings을 제한한다. Unicode strings를 sequence of UTF-8 bytes로 processing하는 것은 이 요구사항을 훌륭하게 만족하지만 large scale dataset에서 byte-level LMs는 word-level LMs에 비해 경쟁적이지 못하다.
Byte Pair Encoding (BPE) (Sennrich et al., 2015)는 character와 word level language modeling 사이 실용적인 절충안이며 word level inputs for frequent symbol sequences와 character level inputs for infrequent symbol sequences 사이를 효과적으로 interpolate한다. (이름에도 불구하고) 기존의 BPE는 byte sequence가 아니라 Unicode code points에 작동한다. 이는 모든 Unicode string을 model하기 위해 full space of Unicode symbols를 포함해야하는데, 이러면 base vocabulary가 (multi-symbol tokens가 추가 되기 전에) 130,000개나 되버린다. 반면 BPE의 byte-levl version은 base vocabulary 크기가 256만 필요하다. 그러나 BPE를 byte sequence에 바로 적용하는 것은 BPE가 token vocabulary를 build할 때 greedy frequency에 기반한 heuristic을 사용하기 때문에 sub-optimal merges를 초래한다. 이는 한정된 vocabulary slots와 model capacity의 sub-optimal allocation을 야기한다. 이를 해결하고자 BPE가 어떤 byte sequence로부터 character categories를 넘어(across) merge하지 못하게 했다. compression efficiency를 상당히 향상시키는 공간에 대한 예외를 추가한 한편 multiple vocab tokens를 걸쳐(across) minimal fragmentation of words을 추가했다.
이런 input representation는 word-level LMs의 경험적인 이익과 byte-level LMs의 generality를 결합할 수 있다. 우리의 방식이 어떤 Unicode string도 probability를 할당할 수 있기 때문에 pre-processing, tokenization, vocab size에 상관없이 모든 dataset에 LM을 평가할 수 있게 한다.
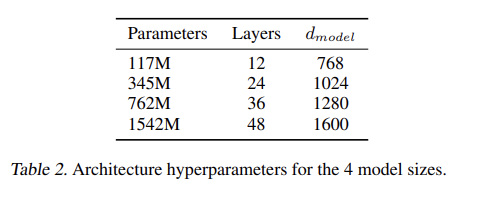
LM 모델은 Transformer based architecture을 사용하며 OpenAI GPT model (Radford et al., 2018)를 약간 수정한다. Layer normalization (Ba et al., 2016)가 각 sub-block의 input으로 이동했고 추가적인 layer normalization가 final selfattention block 이후에 덧붙었다. model depth에 따른 residual path의 accumulation을 계산하는 initialization이 변경되었다. initialization 시 residual layers의 weight에 을 곱한다(N은 residual layers의 수). vocabulary는 50,257로 확장됐다. context size도 512에서 1024 tokens로 증가했고 batch size도 512로 키웠다.
Tab 2처럼 log-uniformly spaced sizes를 가진 4개의 LM을 benchmark했다. 가장 작은 모델은 GPT-1과 동일하고 두 번째로 작은 모델은 BERT (Devlin et al., 2018)의 가장 큰 모델과 동일하다. 가장 큰 모델을 GPT-2라고 부른다. 모든 모델이 WebText에 여전히 underfit되어있다.
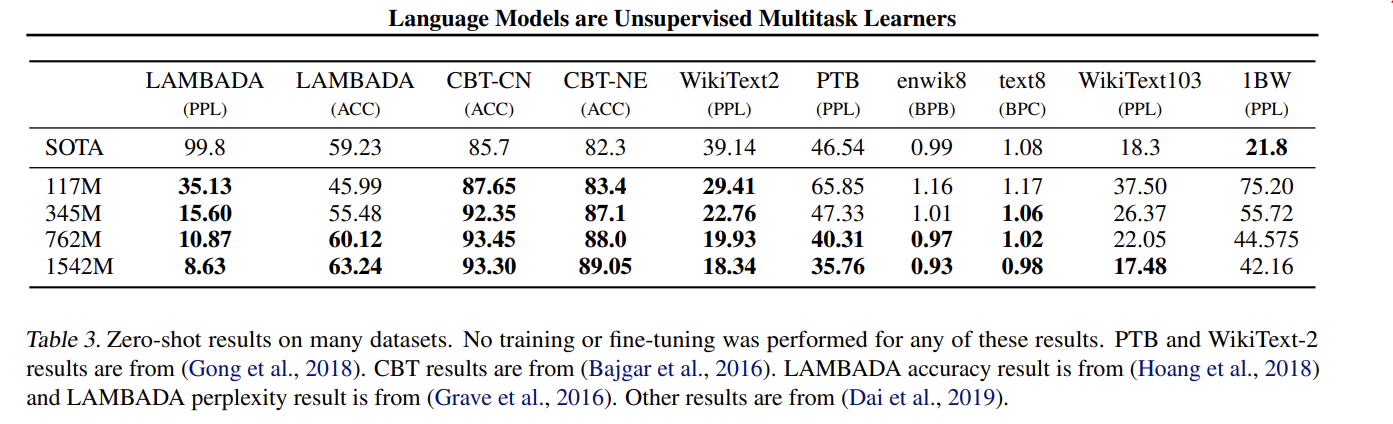
GPT-2는 zero-shot setting(fine-tuning 안함)에서 8개 중 7개의 dataset에서 SOTA를 달성한다.
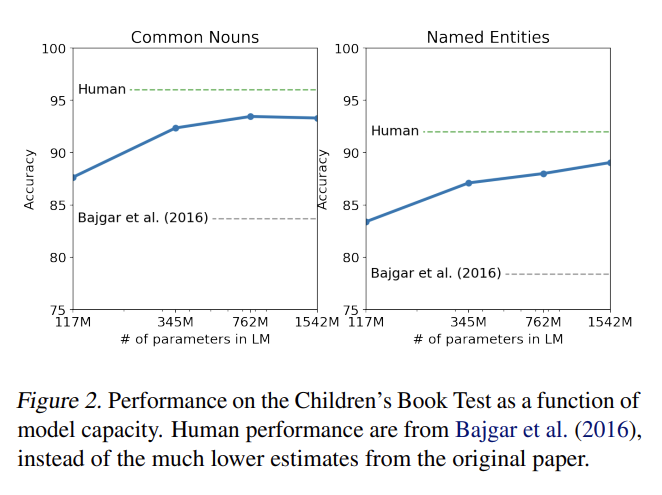
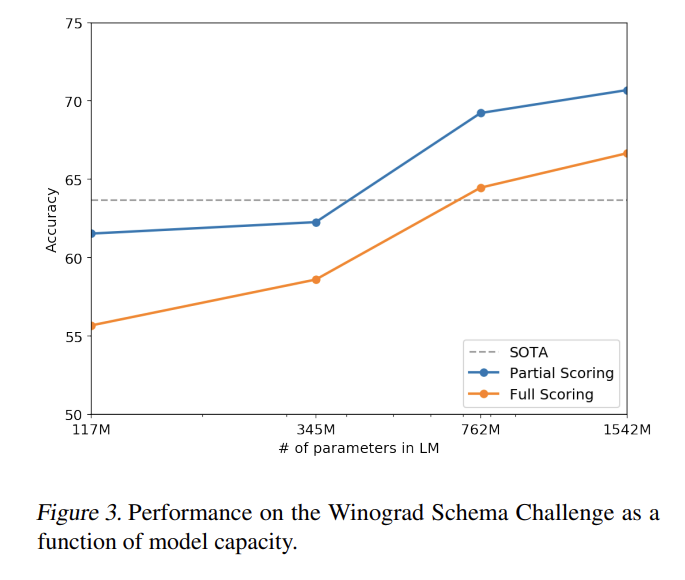
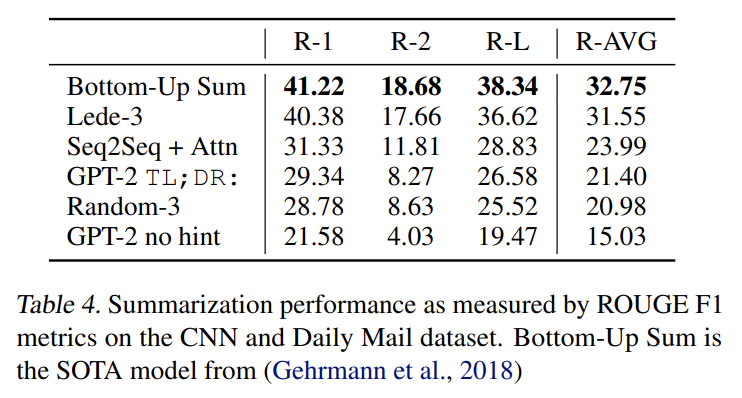
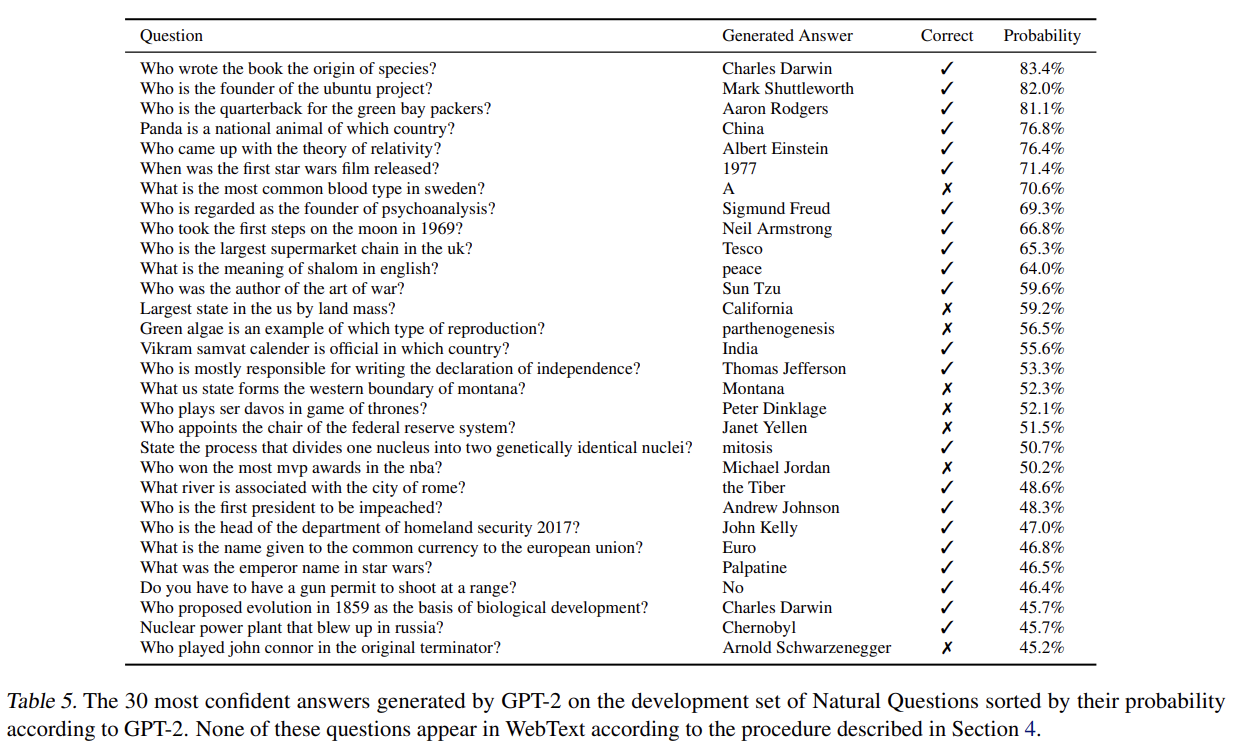
Children’s Book Test, LAMBADA, Winograd Schema Challenge도 실험하며 Conversation Question Answering dataset (CoQA)에 Reading Comprehension을, CNN and Daily Mail dataset (Nallapati et al., 2016)에 Summarization을, WMT-14 English-French test set에 Tanslation을, Natural Questions dataset (Kwiatkowski et al., 2019)에 Question Answering을 실험한다. 결과는 생략한다.
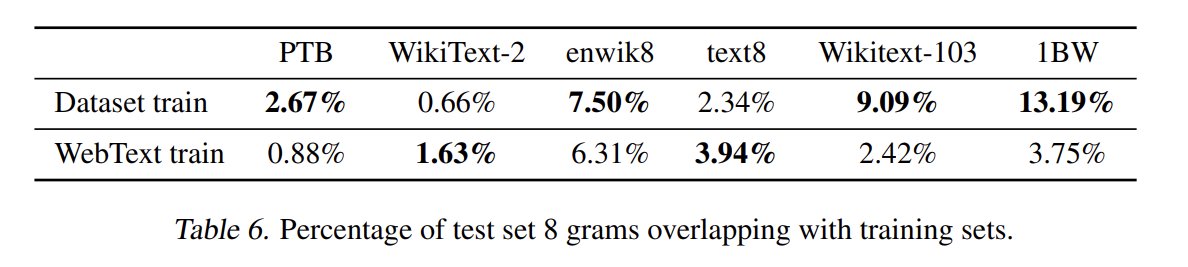
또 논문은 모델이 generalization이 아니라 memorization하는 것을 걱정해서 test data가 얼마나 많이 train data에 나타나는지 분석한다. 전반적으로 WebText training data와 특정 evaluation datasets 사이 data overlap이 작지만 consistent한 이익을 결과에 준다고 볼 수 있다. 그러나 기존의 standard training, test sets 사이 overlap보다 의미있게 크지는 않다.
Strengths
- GPT-1이 input transformation을 통해 여러 task에 범용적으로 generalization을 했다면, GPT-2는 아예 fine-tuning 없이 zero-shot으로 사용 가능해서 훨씬 더 범용적이다.
- 성능도 GPT-1보다 좋아 많은 task에서 SOTA를 달성했다. 대신 이는 단순히 파라미터 수가 order of magnitude 더 커서 그럴 수도 있다.
- Web scaping으로 만든 dataset으로 text data domain의 다양성과 양을 늘렸다.
- 범용성을 위해 Byte Pair Encoding(BPE)을 변환한 input representation을 사용했다.
Weaknesses
- 사실 GPT-1도 Transformer을 조금 변형시킨거지만 GPT-2는 GPT-1을 약간 수정하고 parameter 수가 많아진 거라 모델이 참신하다고 생각하기는 힘들었다.
- 단지 train data와 test data 사이의 overlap을 측정하는 것으로 memorization 정도를 분석하는 건 비약 아닐까?
