오늘 리뷰할 논문은 Autoencoder 논문이다. RBM과 DBN의 선행 연구라고 해서 읽어보게 되었다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- 초보자용 RBM(Restricted Boltzmann Machines) 튜토리얼
- Restricted Boltzmann Machine
- Review — Autoencoder: Reducing the Dimensionality of Data with Neural Networks (Data Visualization)
작은 central layer를 가진 multilayer neural network를 학습하여 High-dimensional data를 low-dimensional codes로 전환하고 다시 high-dimensional input vectors를 복원할 수 있다. 그러나 이는 initial weight가 좋은 해에 근접할 때만 잘 작동한다. 논문은 데이터의 차원을 축소하는 데 PCA보다 효과적으로 deep autoencoder networks가 low-dimensional codes를 학습하는 weight initializing 방법을 소개한다.
랜덤 weights를 가진 두 network에서 시작해 original data와 reconstruction의 차이를 최소화하도록 두 네트워크가 학습된다.
2~4 층의 multiple hidden layers를 가진 nonlinear autoencoders를 최적화하는 것은 어렵다. initial weights가 크면 autoencoders는 poor local minima를 찾고 initial weights가 작으면 early layers의 gradients가 작아서 학습이 효과적이지 않다. initial weight가 good solution에 근접하면 gradient descent가 잘 작동하지만, 이를 찾는 게 쉽지 않다. 논문은 binary data에 대한 'pretraining' procedure을 소개하고 이를 real-valued data로 일반화한다.
ensemble of binary vectors (e.g., images)는 restricted Boltzmann machine (RBM) (5, 6)라고 불리는 two-layer network를 통해 model될 수 있다. 거기서 stochastic, binary pixels는 symmetrically weighted connections를 사용해 stochastic, binary feature detectors에 연결된다. pixels는 (그들의 states가 관측되기 때문에) RBM의 "visible" units에 상응하고 feature detectors는 "hidden" units에 상응한다. visible units와 hidden units의 joint configuration (v, h)는 다음과 같은 energy를 가진다.
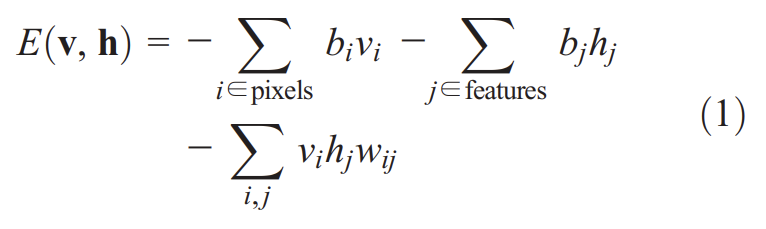
는 pixel i와 feautre j의 binary states고 는 그들의 biases, 는 둘 사이의 weight이다. 네트워크는 모든 가능한 image에 이 energy function을 통해 probability를 할당한다. training image의 probability는 그 이미지의 energy를 낮추고 비슷한 조작된(confabulated) 이미지의 에너지를 높이도록 weights와 bias를 조정하는 것으로 높일 수 있다. training image가 주어졌을 때 각 feature detector j의 binary state 는 확률로 1로 설정된다. 는 logistic function(sigmoid), 는 j의 bias, 는 pixel i의 state, 는 i와 j 사이 weight이다. hidden states에 대한 binary units가 정해지면 각 를 확률로 1로 설정하는 것으로 "confabulation"이 생성된다. 그리고 hidden units의 states가 한 번 더 업데이트 되어 그들이 confabulation의 features를 나타내게 한다. weight 변화는 다음과 같다.
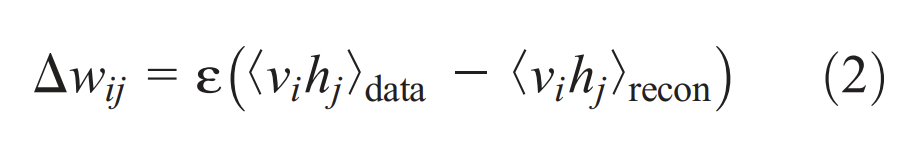
은 learning rate고, 는 feature detectors가 data에 의해 이끌어졌을 때(being driven by data) pixel i와 feature detector j가 함께 있는(on together) fraction of times이고 은 confabulations의 상응하는 fraction이다. 동일한 학습 규칙의 simplified version이 bias에도 사용된다.
binary features의 single layer은 사진 집합 내의 구조를 모델링하는 최고의 방법이 아니다. one layer of feature detectors를 학습한 이후 그들의 activities를 second layer of features를 학습하는 데 필요한 데이터로 다룰 수 있다. 그러면 first layer of feature detectors는 다음 RBM을 학습하기 위한 visible units가 된다. 이 layer-by-layer learning는 원하는 만큼 반복될 수 있다. extra layer를 추가하는 것은 (layer 당 feature detectors 수가 감소하지 않고 weights가 올바르게 초기화되었다는 가정 하에) model이 training data에 할당하는 log probability의 lower bound를 항상 향상시킨다. 각 layers of features는 직전 layer 내 units의 activities 사이 high-order correlations를 포착한다.
multiple layers of feature detectors를 pretraining한 후, 모델은 (처음에는 동일한 weights를 사용하는) encoder와 decoder를 생성하도록 "unfold"된다. 다음으로 global finetuning stage가 stochastic activities를 deterministic, real-valued probabilities로 대체하고 optimal reconstruction을 위한 weight을 fine-tune하도록 전체 autoencoder를 걸쳐 backpropagation을 사용한다.
continuous data의 경우, first-level RBM의 hidden units는 binary인 채로 유지하고, visible units은 Gaussian noise를 가진 linear units로 대체한다. 이 noise가 unit variance를 가진다면 hidden units을 위한 stochastic update rule는 동일하게 유지되고 visible unit i를 위한 update rule은 unit variance와 mean 를 가진 Gaussian에서 sample하는 것이다.
모든 실험에서 모든 RBM의 visible units는 (logistic units에 대해) [0, 1] 범위의 real-valued activities를 가졌다. higher level RBMs를 학습할 때는 visible units가 직전 RBM의 hidden units의 activation probabilities로 설정됐고 꼭대기 놈을 제외하고 모든 RBM의 hidden units는 stochastic binary values를 가졌다. top RBM의 hidden units는 (평균이 그 RBM의 logistic visible units에서 온input으로 결정된) unit variance Gaussian에서 얻은 stochastic real-valued states를 가졌다.
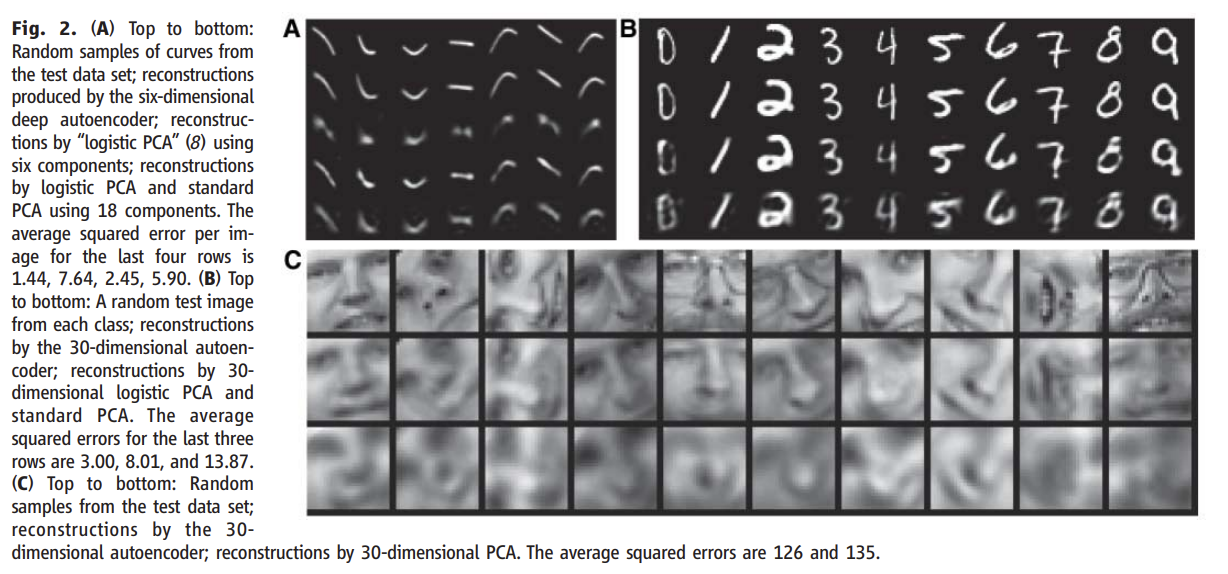
실험 설명은 생략한다.
RBM을 모르는 채로 읽었더니 내용이 잘 이해가 안 되서 다른 포스트들을 읽고 이해한 바를 정리한다.
RBM은 visible layer (=input layer)와 hidden layer로 이루어진 2층짜리 네트워크다. RBM을 하나의 autoencoder처럼 사용할 수 있는데, visible layer에 input을 넣어 순전파해서 hidden unit들의 activation을 구하고, 그 다음 반대로 hidden unit에서 visible layer로 역전파해서 original input에 근사한 reconstruction을 복원하는 것이다. 논문에서 back propagation이라는 용어가 중복으로 사용되서 헷갈릴 수 있는데, weight를 업데이트하기 위해 gradient를 전파하는 의미로 사용되기도 하고 hidden layer에서 visible layer 방향으로 순전파한다는 의미로 사용되기도 한다. 아무튼 visible > hidden 방향의 전파가 encoder 역할을, hidden > visible 방향의 전파가 decoder 역할을 해서 RBM 하나가 autoencoder 하나처럼 작동할 수 있는 것이다.
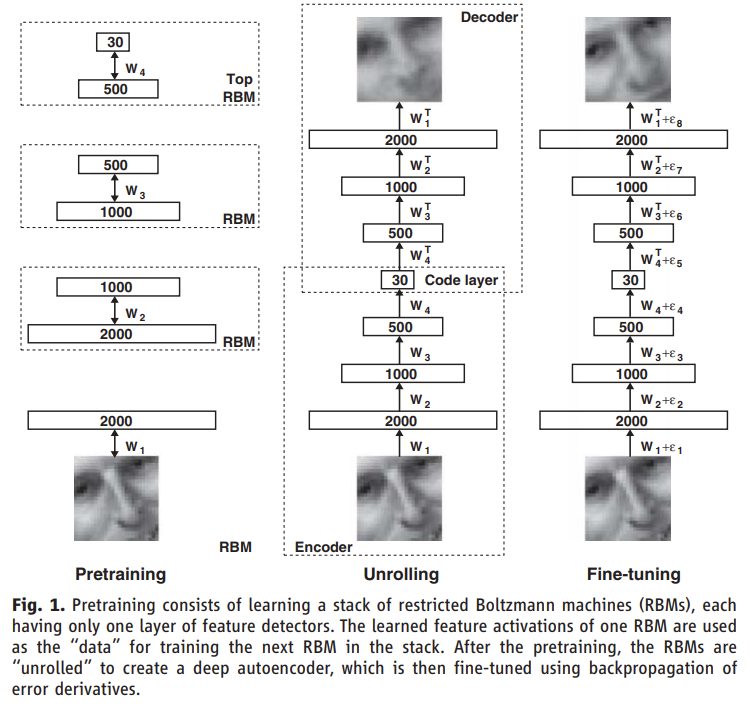
그런데 논문은 도입부에서 deep autoencoder의 weight을 어떻게 올바르게 초기화할 수 있는지를 묻는다. 논문은 RBM을 여러 층으로 쌓아 하나씩 차례대로 초기화하는 것으로 층을 늘려가는 방식(layer-by-layer learning)으로 올바르게 initialize된 deep autoencoder를 pretrain할 수 있다고 말하는 것이다.
Fig 1에서 볼 수 있듯이 4개의 RBM을 준비한 후(1번, 2번, 3번, 4번=top으로 칭하겠다) 1번 RBM을 먼저 학습시킨 후, 1번을 사용해 2번을 학습하고, 3번을 학습하고, 마지막으로 4번까지 학습하는 방식으로 하나씩 층(=RBM)을 늘리는 것이다. 1번의 hidden layer가 2번의 visible layer가 되서 2번 RBM은 1번 hidden layer의 activation을 근사하도록 학습되는 것이다. 즉 이전 RBM이 다음 RBM을 학습하기 위한 데이터가 되는 것이다. 각각의 RBM을 pretrain한 후 이들을 하나로 펼쳐서(unroll) deep autoencoder를 만들고 마지막으로 이걸 finetuning하는 것이다.
논문에서 feature detectors라는 용어가 나오는데 이건 hidden layer의 unit들을 일컫는 말 같다.
