오늘 리뷰할 논문은 RoBERTa 논문이다. BERT 논문의 replication study라 RoBERTa라고 이름까지 붙인 것치고는 별 내용이 없었다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- RoBERTa 논문 정리(논문 리뷰) - A Robustly Optimized BERT Pretraining Approach (RoBERTa)
- [NLP | 논문리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach 논문 리뷰
- [논문 리뷰 스터디] RoBERTa : A Robustly Optimized BERT Pretraining Approach
Summary
Language model pretraining의 여러 approaches 간 비교는 힘든데, training이 expensive하고 주로 다른 크기/종류의 dataset에 학습되며 hyperparameter 선택이 최종 성능에 크게 영향을 주기 때문이다. 논문은 BERT pretraining의 replication study를 제시하며 hyperparameter와 training data size의 영향을 측정한다. 논문은 BERT가 상당히 undertrained되었으며, BERT를 training하는 향상된 방법을 제안하여 RoBERTa라고 부른다. RoBERTa는 이후에 출간된 모든 model과 성능이 비슷하거나 그 이상이다. 바뀐 점은 간단한데, (1) 모델을 더 큰 batch size와 더 많은 데이터로 더 길게 학습하고 (2) next sentence prediction objective를 제거하고 (3) 더 긴 sequence에 학습하고 (4) training data에 적용된 masking pattern을 dynamic하게 바꾼다. 또 training set size의 영향을 조절하기 위해 비교가능한 크기의 large new dataset (CC-NEWS)를 만들었다.
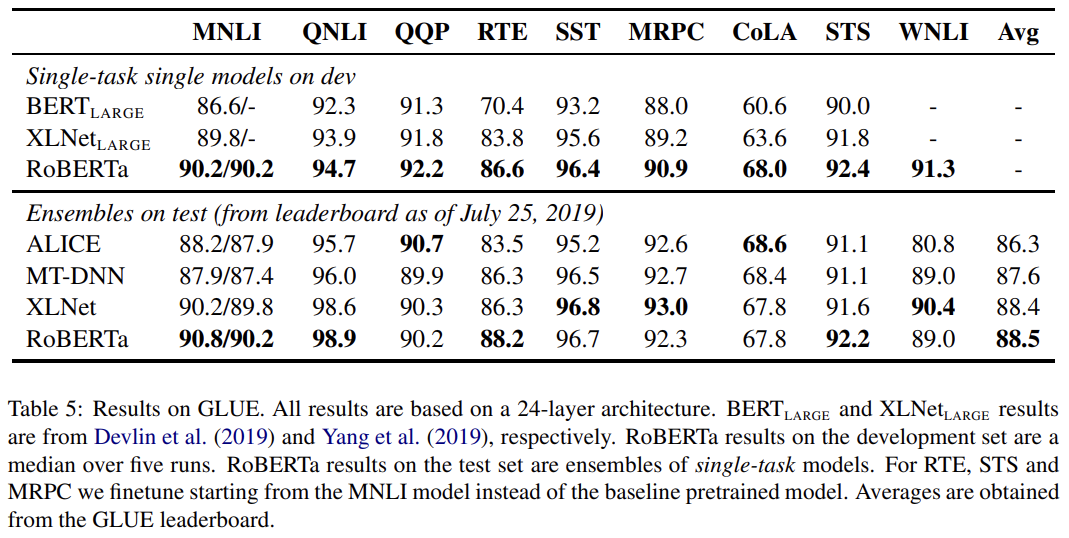
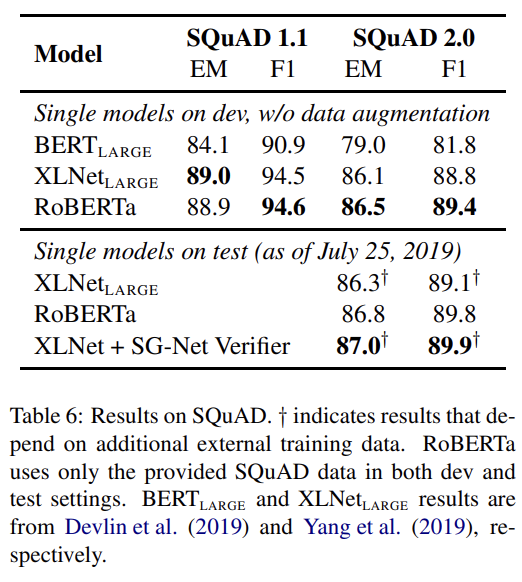
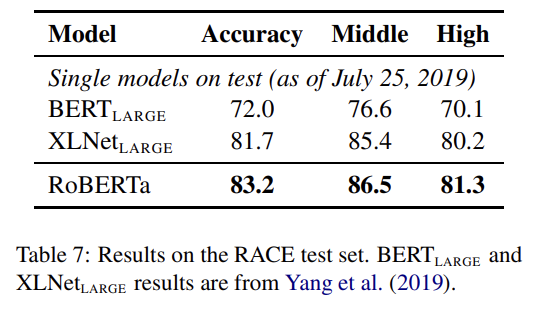
RoBERTa는 GLUE tasks의 4/9, MNLI, QNLI, RTE와 STS-B에서 SOTA를 달성하며 SQuAD와 RACE에서도 SOTA를 달성한다.
논문의 기여는 다음과 같다.
- 중요한 BERT design choices와 training strategies를 제시하고 더 좋은 downstream performance로 이어지는 대안책을 소개한다.
- 새로운 dataset CC-NEWS를 사용해 pre-training에 더 많은 data를 사용하는 것이 downstream tasks의 성능을 향상시킴을 확인한다.
- masked language model pretraining이 올바른 design choice 하에 최근 모델들과 비교해도 경쟁적임을 보인다.
BERT 배경 설명 생략. pre-traing으로 두 개의 objective, Masked Language Model (MLM)와 Next Sentence Prediction (NSP)를 사용한다.
Experimental Setup은 간단히 설명하겠다. hyperparameter은 주로 원본 BERT를 따르는데 training이 Adam epsilon term에 아주 민감해서 이건 tuning했고 sequence는 최대 T=512 tokens로 pretrain했다.
데이터는 다섯 개의 English-language corpora를 사용했다. BOOKCORPUS, English WIKIPEDIA, CC-NEWS, OPENWEBTEXT, STORIES이다. evaluation은 세 개의 benchmark를 사용했고 GLUE, SQuAD, RACE이다.
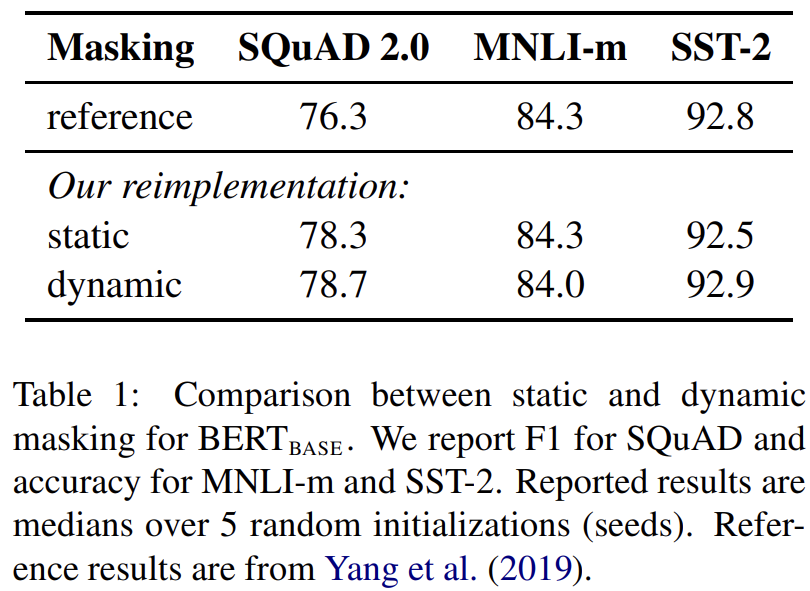
이제 어떤 choice가 BERT의 pre-training에 유리한지 알아보자. 원본 BERT는 data preprocessing 중에 한 번 masking을 하는데, 이는 single static mask다. 모든 epoch에서 각 training instance에 동일한 mask를 쓰는 걸 피하기 위해 training data는 10배로 복제되서 40 epoch 중에 10가지 서로 다른 방법으로 각 sequence가 mask되게 했다. 따라서 각 sequence는 training 중에 4번 동일한 mask를 만난다.
대신 논문은 sequence를 model에 먹일 때마다 masking pattern을 생성하는 dynamic masking 전략을 사용한다. Tab 1에서 볼 수 있듯이 static masking은 원본 BERT와 성능이 비슷했고 dynamic masking은 그보다 약간 좋았다. 이후 실험에서는 모두 dynamic masking을 사용했다.
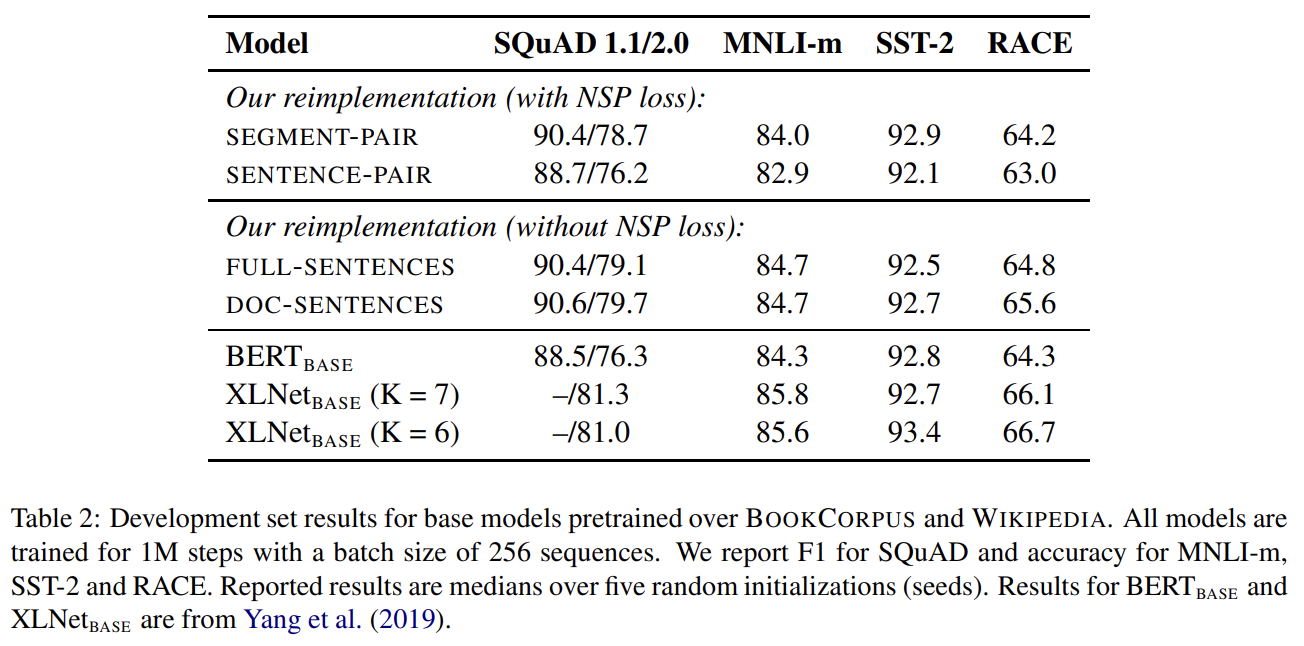
NSP loss는 원본 BERT 모델을 학습시킬 때 중요한 요소로 가설이 설정됐으나 이후 연구들은 NSP loss가 필수적인지 의문을 제기했다. 이 불일치를 이해하기 위해 논문은 다음과 같이 몇 가지 대안적인 training formats를 비교한다.


Tab 2가 네 가지 세팅의 비교 결과를 보여준다. original SEGMENT-PAIR input format와 SENTENCE-PAIR format를 비교(둘 다 NSP loss 사용, 후자는 single sentences 사용)한 결과 individual sentence를 사용하는 게 downstream task의 성능을 저하한다는 사실을 알아냈다. 다음으로 NSP loss 없이 실험해서 NSP loss를 없애는 게 downstream task 성능을 약간 향상시킴을 알아냈다. 마지막으로 DOC-SENTENCES와 FULL-SENTENCES를 비교했다. 그러나 DOC-SENTENCES format은 batch 크기가 가변적(variable)이기 때문에 이후 실험에선 다른 연구와의 쉬운 비교를 위해 FULL-SENTENCES를 사용했다.
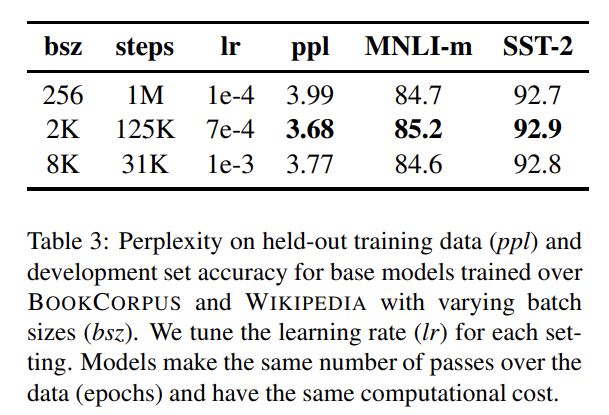
Neural Machine Translation에 과거 연구들은 큰 mini-batch에 학습하는 것이 learning rate를 적절히 상승시켰을 때 optimization speed와 end-task performance를 향상시킴을 보였다. Tab 3에서 batch size에 따른 의 perplexity와 end-task performance를 비교했다.
Byte-Pair Encoding (BPE)는 character-level과 word-level representations 사이의 hybrid로 natural language corpora에 흔한 large vocabulary를 다루게 해 준다. 원본 BERT는 character-level BPE vocabulary를 사용하는데 논문은 (GPT-2의) byte-level BPE vocabulary를 사용한다.
앞선 설정들, dynamic masking, FULL-SENTENCES without NSP loss, large mini-batches, larger byte-level BPE를 모두 가지고 훈련한 BERT를 Robustly optimized BERT approach, RoBERTa라고 부른다.
추가적으로 기존 연구에서 under-emphasized된 두 가지 중요한 요소, pre-training에 사용된 data와 training passes의 횟수를 조사했다. 이 요소들을 pretraining objective 같은 다른 modeling choice에서 disentangle하기 위해 RoBERTa를 architecture을 따라 학습하는 것에서 시작한다.
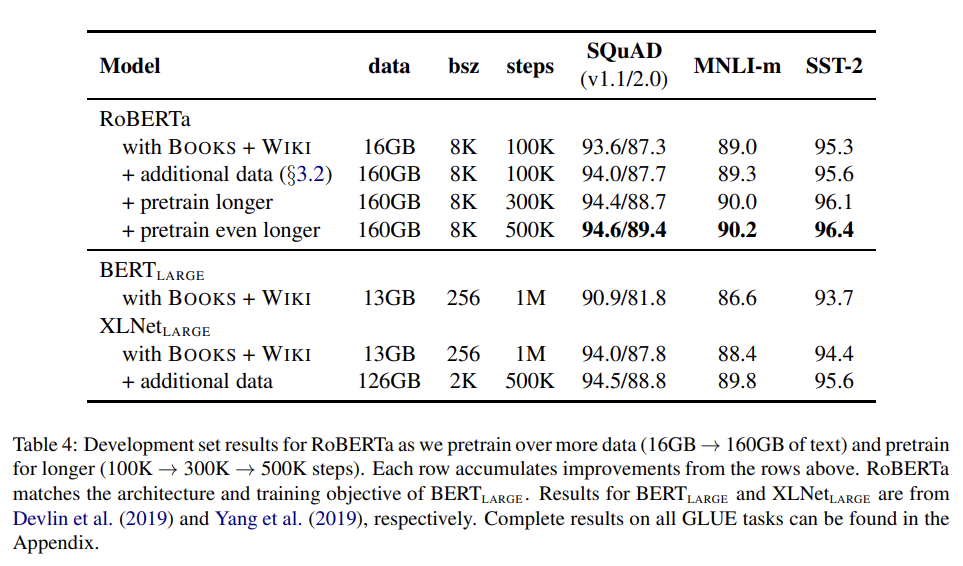
Tab 4에서 RoBERTa가 보다 성능이 크게 향상된 것을 보고 논문의 design choice의 중요성을 알 수 있다. 또 앞서 설명한 세 개의 추가적인 데이터셋을 더 학습시킬 경우 모든 downstream task에서 성능 향상이 있어 pretraining에서 data size와 diversity의 중요성을 알 수 있다. 마지막으로 pretraining step을 늘렸을 때도 성능이 향상됐고 심지어 longest-trained model조차 overfit되지 않았다.
이제 다섯 데이터셋에 500K steps 동안 학습한 RoBERTa를 GLUE, SQuaD, RACE 벤치마크에 평가한다. 설명은 생략한다.
Strengths
- BERT가 underfit되었음을 보여 더 큰 dataset, batch size, 더 긴 pre-training step, longer sequence으로 성능 향상을 이루었다.
- BERT의 NSP loss를 없애도 성능이 뛰어남을 보이고 MLM에서 dynamic masking을 하는 것으로 기존 BERT의 pre-training objective을 개선했다.
- BERT 자체의 잠재력이 더 뛰어남을 보임으로써 BERT 이후에 나온 모델들의 성능 향상에 의문을 제기했다.
