오늘 리뷰할 논문은 R-CNN에서 region proposal을 하는 원천 기술인 selective search 알고리즘에 대한 논문이다. R-CNN 논문을 읽고 궁금해져서 리뷰하게 되었다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.

이 논문의 목표는 object recognition에 이용할 수 있는 object locations 후보를 추출하는 것이다. 좀더 엄밀히 말하면 high-quality object locations의 작은 집합을 생성하는 class-independent, data-driven, selective search strategy를 만드는 것이다.
Selective Search는 exhaustive search와 segmentation의 장점을 합쳤다. Selective search는 bottom-up segmentation에서 영감을 받아 object location을 생성하기 위해 image structure를 이용하며 exhaustive search에서 영감을 받아 모든 가능한 objective location을 capture하려 한다.
따라서 single sampling technique를 사용하는 대신 sampling techniques를 다양화해 가능한 많은 image conditions를 처리하려 한다. 특히 data-driven grouping based strategy를 사용하는데, different invariance properties를 가진 다양한 complementary grouping criteria와 다양한 complementary colour spaces를 사용해 diversity를 증가시킨다. set of locations는 이런 complementary partitionings를 연결해 얻어진다.
기존의 exhaustive search 방법들과 달리 selective search는 1. class-independent한 location sets을 만들며, 2. (exhaustive search 중 sliding window 같은) fixed aspect ratio를 사용하지 않기 때문에 사물에 제한이 되지 않고 풀/모래 같은 것도 찾을 수 있으며, 3. 더 적은 location을 생성해 (object recognition) 문제를 쉽게 하고 4. 따라서 computational power를 더 적게 소모한다는 장점이 있다.
또 기존의 segmentation 기법들과 달리 selective search는 1. 다른 grouping criteria와 다른 representations를 적용해 다양한 image conditions를 명시적으로 다루며, 2. 따라서 single best segmentation strategy를 invest할 필요가 없어 computational 이득이 있으며, 3. 다른 image conditions를 따로 다루기 때문에 location들이 일관적인 quality를 갖도록 기대할 수 있으며, 4. regions들이 서로 complement되는 것에 관심을 둔다.
selective search가 염두에 둔 특징은 다음과 같다.
- Capture All Scales : hierarchical algorithm를 사용해 모든 scale의 object를 계산한다.
- Diversification : region들을 grouping하는 단일한 optimal strategy가 있는 게 아니다. colour 때문에 하나의 object로 묶일 수도 있고 texture 때문에, 일부가 둘러싸여 있기 때문에, 조명 때문에 묶일 수도 있다.
- Fast to Compute : practical object recognition framework에 사용될 수 있도록 충분히 빨라야 한다.
1번부터 자세히 살펴보자. Hierarchical Grouping은 원래부터 segmentation에서 인기있는 Bottom-up grouping 방법을 사용한다. grouping 과정 자체가 hierarchical하기 때문에 전체 이미지가 single region이 될 때까지 grouping process를 하면 자연스럽게 모든 scale에서 location을 생성할 수 있다.

우선 여러 object에 걸치지 않는 set of small starting regions를 얻기 위해 Felzenszwalb and Huttenlocher [13]를 사용해 initial regions를 만든다. 그리고 region들을 iterative하게 grouping하는 greedy algorithm을 사용한다.
알고리즘은 첫째로 모든 neighbouring regions 간에 similarity를 계산한다. 가장 큰 similarity를 가진 두 region이 묶이고, 전체 이미지가 하나의 region이 될 때까지 이걸 반복한다.
이때 similarity를 계산하는 s(r_i, r_j)는 충분히 빨라야 하는데, 이는 similarity가 hierarchy를 통해 전해질 수 있는 feature에 기반해야한다는 것을 의미한다. 다시 말해 영역 r_i와 r_j를 r_t로 합칠 때 r_t의 feature가 image pixel에 접근할 필요 없이 오직 r_i와 r_j의 feature들로만 계산 가능해야한다는 의미다.
2번으로 Diversification Strategies에 대해 살펴보자. 논문에서는 다음과 같은 3가지 방법으로 selective search를 다양화한다.
2-1. 서로 다른 invariance를 가진 다양한 colour space를 사용
2-2. 다양한 similarity measure s_ij를 사용
2-3. starting region을 다양화
2-1번 Complementary Colour Spaces의 경우, 다양한 scene과 lighting condition을 고려하기 위해 다양한 invariance properties를 가진 여러 colour space에서 hierarchical grouping algorithm를 수행한다. colour space의 종류는 다음과 같다.
(1) RGB
(2) the intensity (grey-scale image) I
(3) Lab
(4) rg channels of normalized RGB plus intensity denoted as rgI
(5) HSV
(6) normalized RGB denoted as rgb
(7) C [14] which is an opponent colour space where intensity is divided out
(8) Hue channel H from HSV
그런데 논문에서는 (실험에) 하나의 colour space(RGB인듯)만 사용했다.
(아마 이렇게 다양한 colour space에서 여러번 알고리즘을 돌리면 더 많은 후보를 뽑아낼 수 있다는 의미 아닐까)
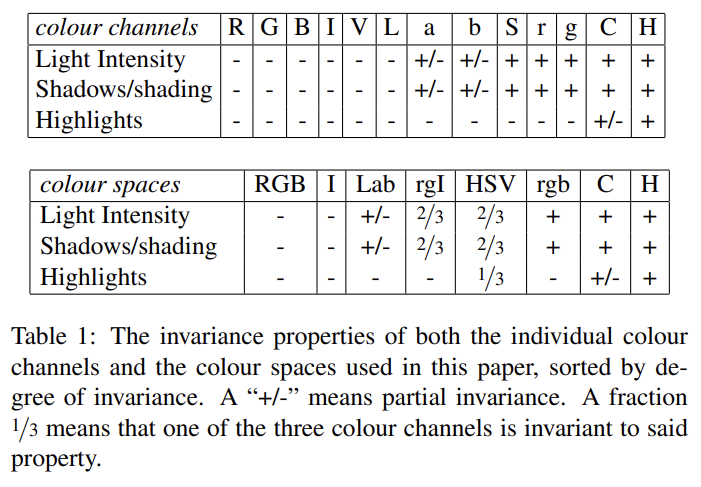
2-2번 Complementary Similarity Measures의 경우 complementary하고 연산이 빠른 4개의 similarity measure를 정의했다. 이 measure들을 서로 조합하기 위해 measure들은 모두 [0,1]의 범위다. 리뷰가 너무 길어지지 않게 similarity에 대한 설명은 생략하고 사진만 첨부하겠다.
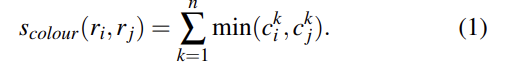
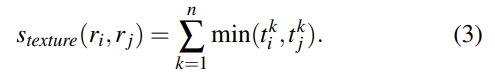
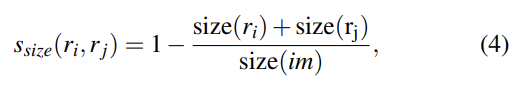
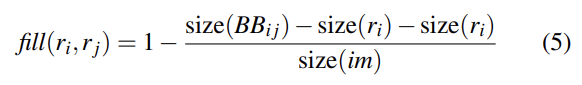
(참고로 식 (5)는 s_fill인데 s 기호가 누락되었다)
이 4가지를 조합해 식 (6)처럼 최종 similarity를 만들며, 여기서 a는 0 또는 1으로 해당 similarity measure을 사용할지 안 사용할지를 나타내는 값이다.
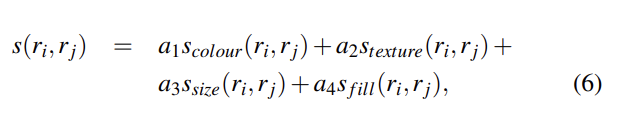
2-3번 Complementary Starting Regions의 경우 위에서 언급한 Felzenszwalb and Huttenlocher의 방법을 사용하며, 계산이 빠르고 효율적이다.
(3.3 Combining Locations 이해 잘 못함)
여러 variations의 hierarchical grouping algorithm으로 나온 object hypotheses(=여러 후보 bounding box)를 조합한다(그러니까 위에서 말한 대로 다양화를 통해 얻은 bounding box를 묶고 중복을 없앤다는 의미인듯).
이때 object hypotheses를 object일 것이 확실한 순서대로 정렬하고 싶다. combined object hypotheses set를 각 hypotheses가 생성된 grouping strategy의 순서대로 정렬한다. 하지만 80개 정도의 grouping strategy에서의 결과를 조합한 거라 이렇게 정렬하면 large regions를 너무 강조하게 된다(즉 원래 이미지 크기에 가까운 큰 region일수록 80개의 grouping strategy에서 중복되어 나타나니까 단순히 크기가 커서 강조되는 문제가 생긴다는 의미인듯). 그래서 무작위성을 부여해준다(자세한 내용은 논문 참고).
location을 bounding box의 형태로 사용할 때, 위와 같은 방식으로 모든 location의 rank를 매긴다. 그다음 lower rank의 duplicates를 삭제한다. 이는 duplicate boxes가 high rank에 있을 가능성을 높아며, 이는 여러 grouping strategies가 동일한 box location을 제안할 때 사진의 시각적으로 일관적인 부분에서 왔을 공산이 크다는 점에서 바람직하다.
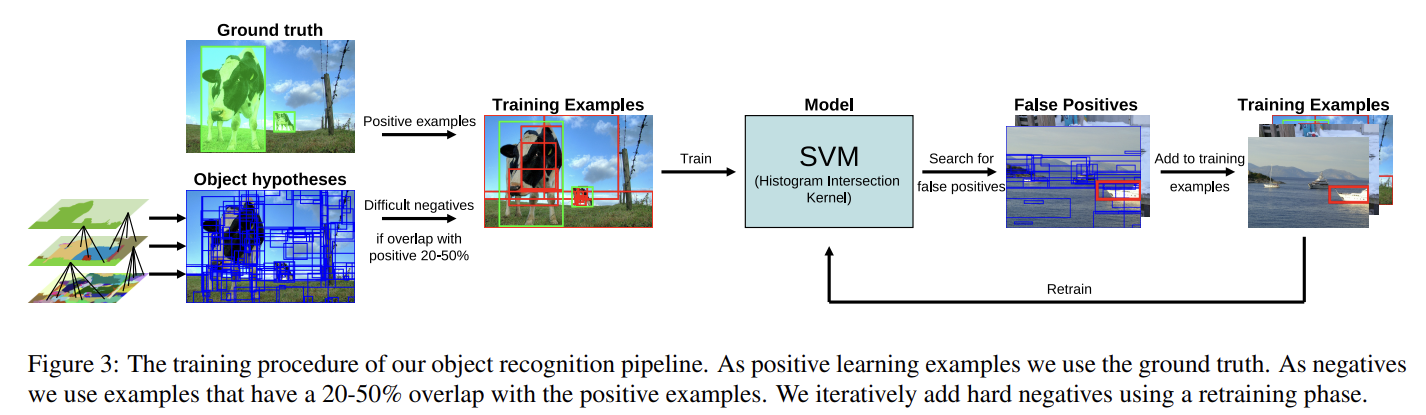
논문에서는 이렇게 selective search로 얻은 location을 가지고 object detection도 실험해본다. object detection에 주로 사용되는 feature은 histograms of oriented gradients(HOG)와 bag-of-words가 있다. selective search가 비교적 연산이 저렴한 덕분에 HOG보다 연산이 더 비싸지만 강력한 BOW를 사용할 수 있는데, 여기선 BOW에 다양한 colour-SIFT descriptors와 finer spatial pyramid division를 추가했다. classifier로는 Shogun Toolbox를 이용하는 histogram intersection kernel를 가진 Support Vector Machine를 이용했다.
대략적인 training 순서는 다음 사진과 같다.
evaluation에서 몇 가지 흥미로운 점만 짚어보겠다.
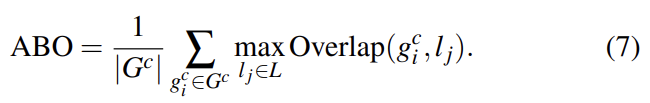
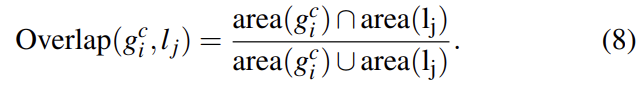
object hypotheses의 quality를 평가하기 위해 Average Best Overlap (ABO)와 Mean Average Best Overlap (MABO) 점수를 정의한다. MABO는 모든 classes의 평균 ABO다.
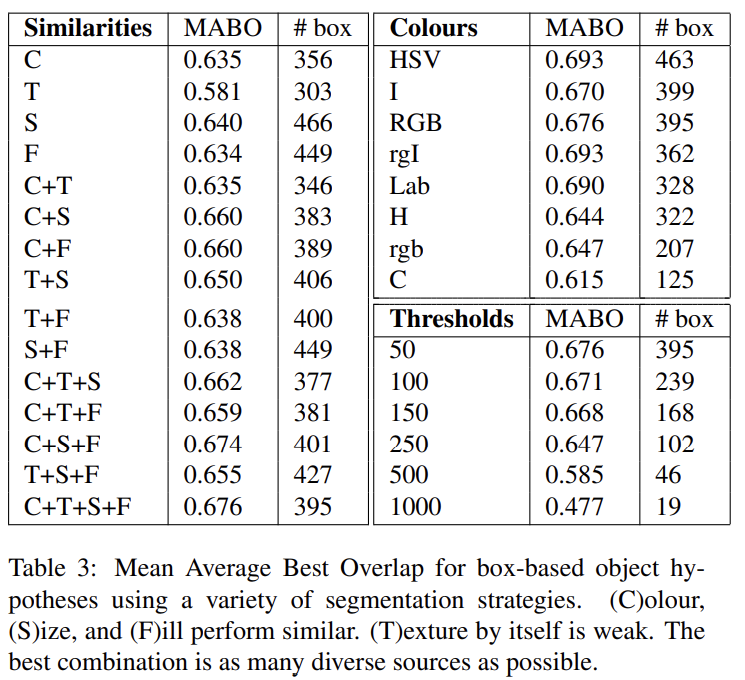
아까 위의 식 (6)에서 왜 a가 존재하는지 의아했는데, 이렇게 평가할 때 여러 similarity 조합의 효과를 비교하는 데 쓰이는 걸 알 수 있었다. 신기하게도 (직관과 달리) texture(T)를 기준으로 하는 분류 성능이 가장 떨어졌는데, 논문에서는 인접한 물체 사이의 경계에서 두 물체가 비슷한 edge-responses를 만들기 때문에 부주의하게 similarity가 증가한 것이라고 추측했다. 또 하나의 similarity measure만 사용하는 것보다는 여러개를 조합하는 게 성능이 더 좋았다.
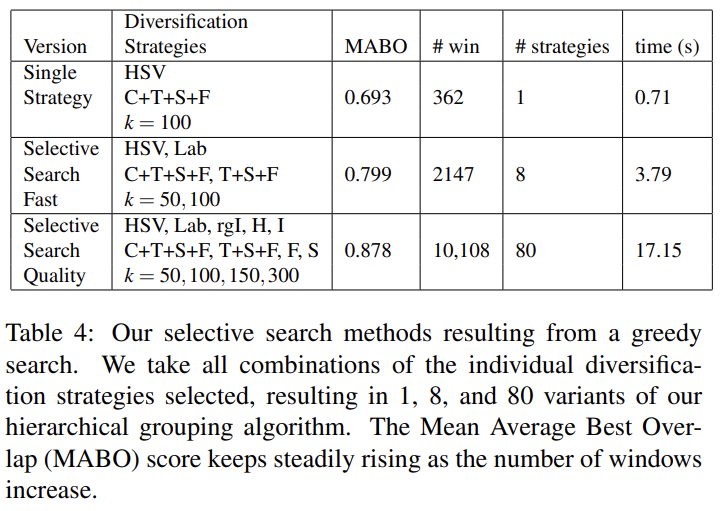
Table 4는 MBO를 기준으로 greedy search를 해서 가장 좋은 조합을 찾아낸 결과다. single best strategy, fast selective search, quality selective search로 3가지를 찾았다. 앞에서 80개의 grouping strategy를 조합했다~는 표현이 있었는데 그게 여기의 selective search quality에서 나온 듯하다. 5가지(colour space) x 4가지(similarity measure) x 4가지(threshold) = 80가지 strategy가 된다.
또 재미있는 점은 HOG와 BOW를 비교한 것인데, bike, bottle, bus,
car, person, train 같은 rigid한 사물에 대해서는 HOG-based 방식이 더 성능이 좋았고 plane, cat, cow, dog, plant, sheep 같은 non-rigid한 사물에 대해선 BOW가 더 성능이 좋았다. 예외적으로 table, sofa, tv는 rigid하지만 BOW에서 더 잘 인식됐다.
결론적으로 selective search는 다양한 complementary, hierarchical grouping strategies 집합을 사용해 stable하고 robust한 성능을 보였다. 또 rigid, non-rigid, (게다가 이론적으로는) amorphous(e.g. water) 등의 사물도 감지하며 object-class에 무관하게 잘 작동했다.
Strengths
- 한 가지 기준이 아닌 여러 기준을 모두 고려하는 것으로 성능을 끌어올린 것 같다. 특히 similarity 식을 잘 정의해서 좋은 결과가 나온 것 같다.
- 정확도나 quantity/quality뿐 아니라 실용적으로 사용할 수 있는 속도인지도 고려한 덕분에 이후 R-CNN으로 발전할 수 있었던 것 같다.
대략적인 원리 이해는 했는데 논문이 어려워서 detail을 적지 않게 놓친 것 같다.... BoW에 대한 논문도 찾아보고 싶다.
