오늘 리뷰할 논문은 Transformer의 발전형인 Transformer-XL 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- Transformer-XL : Attentive Language Models Beyond a Fixed-Length Context(ACL 2019)
- 논문 설명 - Transformer-XL : Attentive Language Models Beyond a Fixed-Length Context
- [논문 리뷰] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Summary
Transformer는 longer-term dependency를 학습할 수 있지만, fixed-length context로 제한된다. 그래서 논문은 temporal coherence를 훼손하지 않고 fixed length를 넘어 dependency를 학습할 수 있는 Transformer-XL을 제안한다. 이는 segment-level recurrence mechanism으로 이루어졌으며 새로운 positional encoding scheme을 사용한다. 이 방법은 longer-term dependency를 포착할 뿐 아니라 context fragmentation problem도 해결한다. 결과적으로 Transformer-XL은 RNN보다 80% 길고 vanilla Transformer보다 450% 긴 dependency를 학습할 수 있으며 short, long sequence 둘 다에서 더 좋은 성능을 보이며 evaluation 시에 vanilla Transformer보다 1800배 이상 빠르다.
기존의 transformer은 fixed context length로 인해 그 길이 이상의 longer-term dependency는 포착하지 못했다. 또 sentence나 다른 semantic boundary를 고려하지(respect) 않고 consecutive chunk of symbols를 선택하는 것으로 인해 fixed-length segments가 생성된다. 따라서 모델은 first few symbols를 잘 예측하기 위해 필요한 필수적인 contextual information가 부족하고, 이는 inefficient optimization과 inferior performance를 초래한다. 이 문제를 context fragmentation이라고 부른다.
이 문제들을 해결하기 위해 논문은 Transformer-XL (meaning extra long)을 제안한다. 각 새로운 segment에 대해 밑바닥에서부터 hidden states를 계산하는 대신, previous segments에서 얻은 hidden states를 재사용한다. reused hidden states는 현재 segment에 대한 memory로 작동하며, segments 간 recurrent connection을 형성한다. 결과적으로 recurrent connection을 타고 정보가 전파될 수 있기 때문에 very long-term dependency를 modeling하는 것이 가능하다. 한편 previous segment에서 정보를 전달하는 것은 context fragmentation 문제도 해결할 수 있다. 또한 absolute positional encoding 대신 relative positional encodings를 사용해 temporal confusion을 초래하지 않고 state reuse를 가능하게 한다.
논문의 주된 기여는 1. purely selfattentive model에 recurrence 개념을 도입하는 것과 2. 새로운 positional encoding scheme을 고안한 것이다. 이 둘은 함께 작동해야 fixed-length contexts의 문제를 해결한다. Transformer-XL은 character-level와 word-level language modeling 둘 다에서 RNNs보다 상당히 좋은 성능을 내는 최초의 self-attention model이다.

- Vanilla Transformer Language Models
Transformer나 self-attention을 language modeling에 적용하려면 핵심적인 문제는 어떻게 arbitrarily long context를 fixed size representation으로 효과적으로 encode할 것인지다. 실현가능한 (대충 고안한) 방식은 전체 corpus를 감당할 수 있는 크기의 shorter segments로 split해서 전체 contextual information은 무시하고 각 segment에 대해서 모델을 학습하는 것이다. 이러한 모델을 vanilla model이라고 부른다. 이런 방식으로는 각 segment 사이에서 정보가 흐를 수 없다. fixed-length context를 사용하는 데에는 두 가지 치명적인 한계가 있다. 첫째로 largest possible dependency length가 segment length로 상한이 정해진다는 것이다. 따라서 RNN에 비해 self-attention mechanism이 vanishing gradient problem에 덜 영향을 받는다고 하더라도 vanilla model은 이 optimization advantage를 온전히 누릴 수 없다. 둘째로, sentence나 다른 semantic boundaries를 respect하기 위해 padding을 사용하는 게 가능하긴 하지만, 실제로는 효율성을 위해 long text를 fixed-length segments로 chunk하는 것이 standard practice이며, 이는 context fragmentation problem를 초래한다.
또 evaluation phase에서는 각 step마다 training 시와 동일한 길이의 segment를 소비하지만 last position에서 하나의 prediction만을 생성한다. 그리고 (Fig 1b에서 볼 수 있듯) 다음 step에서 segment는 오른쪽으로 only one position만 shift되어 새로운 segment가 밑바닥부터 처리된다. 그러나 이런 방식은 연산이 매우 비싸다(중복된 연산이 많아서. computer vision의 sliding window를 생각해보라).
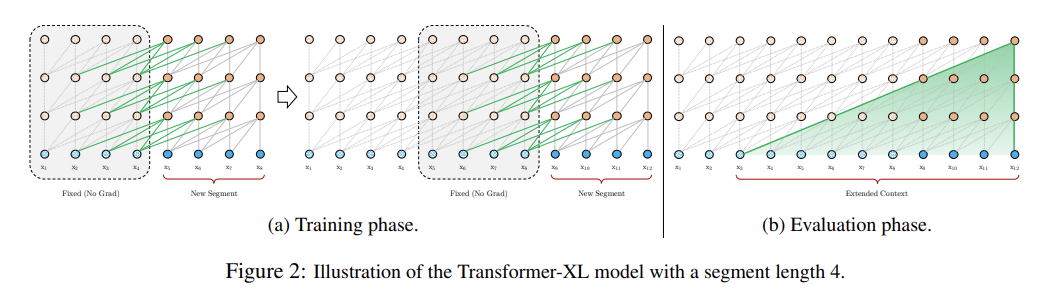
- Segment-Level Recurrence with State Reuse
fixed-length context의 한계들을 극복하고자 transformer에 recurrence mechanism을 도입한다. Fig 2a에서 볼 수 있듯 training 중에는 previous segment에서 계산된 hidden state sequence이 fix되고 cache되서 next new segment를 처리할 때 extended context로써 사용된다. gradient는 여전히 segment 내에 머물지만 이 additional input은 network가 history 내의 정보를 사용할 수 있게 해서 longer-term dependency를 가능하게 하고 context fragmentation을 피한다.
수식을 쓰기 귀찮기 때문에 구체적인 구현은 캡처로 대신한다.

이 recurrence mechanism이 corpus의 모든 두 연속된 segment마다 적용되어 hidden states 내에 segment-level recurrence를 생성한다. 결과적으로 두 segments를 넘어 효과적인 context가 사용될 수 있다.
그러나 사이 recurrent dependency는 one layer downwards per-segment만큼 shift해서 same-layer recurrence를 하는 기존의 RNN-LMs와 다르다. (즉, RNN에서는 step τ의 n번째 layer의 hidden state가 step τ+1의 n번째 layer의 hidden state로 연결됐는데 Transformer-XL은 step τ의 n번째 layer의 hidden state가 step τ+1의 n+1번째 layer의 hidden state로 연결된다.) 따라서 largest possible dependency length는 layers 수와 segment length에 비례하게, 즉 O(N × L)로 커진다. 이는 truncated BPTT (Mikolov et al., 2010)와도 유사한데, truncated BPTT와 달리 Transformer-XL은 마지막 하나 대신 sequence of hidden states를 cache하며, 이후 설명할 relative positional encoding technique와 함께 적용되어야 한다.
longer context와 context fragmentation 말고도 recurrence scheme의 또다른 이점은 evalutaion 속도가 빠르다는 것이다. vanilla model처럼 밑바닥부터 다시 계산하는 대신 previous segments로부터의 representations를 재사용할 수 있다. enwiki8를 사용한 실험에서 Transformer-XL은 vanilla model보다 evaluation이 1800배 이상 빨랐다.
마지막으로 recurrence scheme은 직전 previous segment 하나에만 제한될 필요가 없다. 이론적으로 GPU memory가 허락하는 한 가능한 많은 previous segment를 cache해서 그들 모두를 extra context로 재사용할 수 있다. 여러 segments로부터 predefined length-M old hidden states를 cache해서 그들을 memory 로 삼을 수 있다. 실험에선 training 중 M을 segment length와 동일하게 두고 evaluation 중에 여러 배로 증가시킨다.
- Relative Positional Encodings
그러나 아직 hidden state를 재사용하는 데 중요한 문제를 해결하지 않았다. 그건 바로 state를 재사용할 때 어떻게 positional information을 일관되게 유지할 것인가이다. 기존의 Transformer에서 sequence order 정보가 set of positional encodings 로 제공되던 걸 떠올려보라. (i번째 row Ui는 segment 내의 i번째 absolute position에 상응하고 Lmax는 model되는 maximum possible length를 의미한다.) Transformer로의 실제 input은 word embeddings와 positional embeddings의 element-wise addition이다. 이 positional encoding을 단순히 우리의 recurrence mechanism에 적용하면 hidden state sequence는 다음과 같이 계산된다.
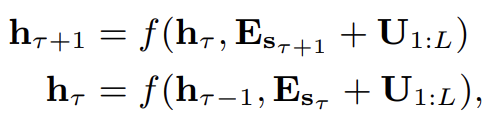
는 의 word embedding sequence고 f는 transformation function이다. 와 는 모두 동일한 positional encoding 과 연관된다. 결과적으로 모델은 와 사이 positional 차이를 구분하기 위한 정보가 없으므로 performance loss를 초래한다.
이 문제를 해결하기 위해 hidden states 내에 relative positional information만을 encode한다. positional encoding이란 어떻게 정보가 gather될지, 즉 어디를 attend할지 temporal clue 내지는 “bias”를 제공하는 것이다. 같은 의도로, bias를 initial encoding에 statically incorporate하는 대신, 동일한 정보를 각 layer의 attention score에 더할(inject) 수 있다. 더욱이 temporal bias를 relative manner로 정의하는 것이 더 직관적이고 generalizable하다. 예를 들어 query vector 가 key vectors 를 attend할 때, segment의 temporal order를 식별하기 위해 각 key vector의 absolute position을 알 필요가 없다. 대신 각 key vector 와 그 자신 사이 relative distance, 즉 i-j만 알면 충분하다.
실제로는(practically) set of relative positional encodings 를 만들 수 있다. (i-th row Ri는 두 positions 사이 i의 relative distance를 의미한다.) relative distance를 attention score에 동적으로 주입하는 것으로 query vector는 거리 차이를 통해 와 의 representations을 쉽게 구분하여 state reuse mechanism 실현할 수 있다. 한편 absolute position이 relative distances로부터 재귀적으로 계산될(recover) 수 있기 때문에 temporal information도 잃지 않는다.
원본 Transformer에서 같은 segment 내의 query qi와 key vector kj 사이 attention score은 다음과 같이 분해될 수 있다.
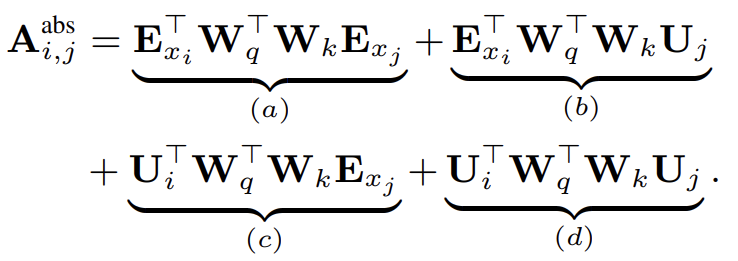
relative positional information에만 의지하는 아이디어에 따라 논문은 네 항을 다음과 같이 reparameterize한다.
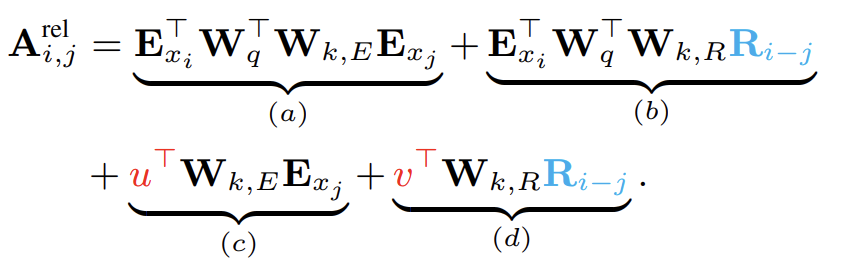


새로운 parameterization 아래 각 항은 다음과 같은 직관적인 의미를 가진다. (a)는 content based addressing를 의미하고, (b)는 content-dependent positional bias를 capture하고, (c)는 global content bias를 govern하고 (d)는 global positional bias를 encode한다.
recurrence mechanism과 relative positional embedding을 합쳐 Transformer-XL architecture을 만든다. single attention head 를 가진 N-layer Transformer-XL의 연산과정을 다음과 같이 요약한다.

는 word embedding sequence로 정의한다.
실험은 word-level와 character-level language modeling 둘 모두에 다양한 dataset을 실험한다. 많은 데이터셋에서 SOTA를 달성한다. 설명은 생략한다.
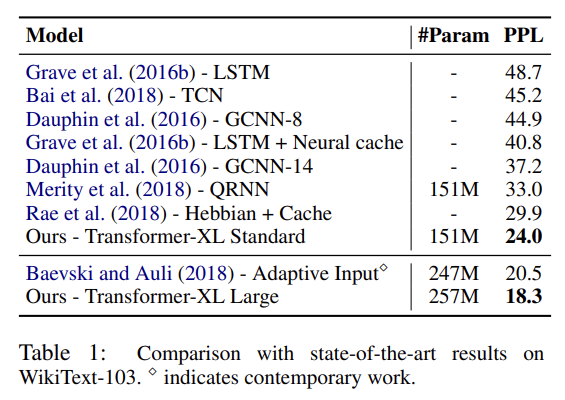
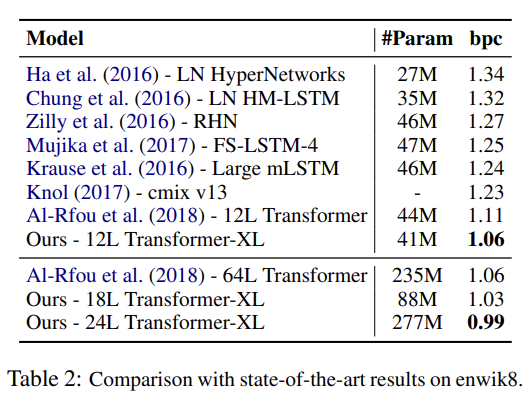
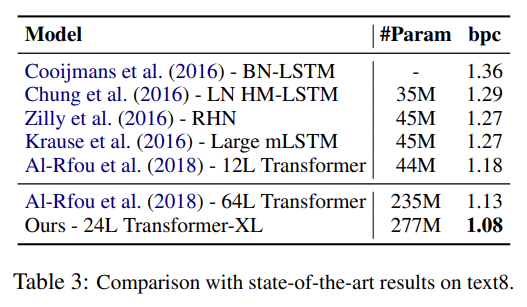
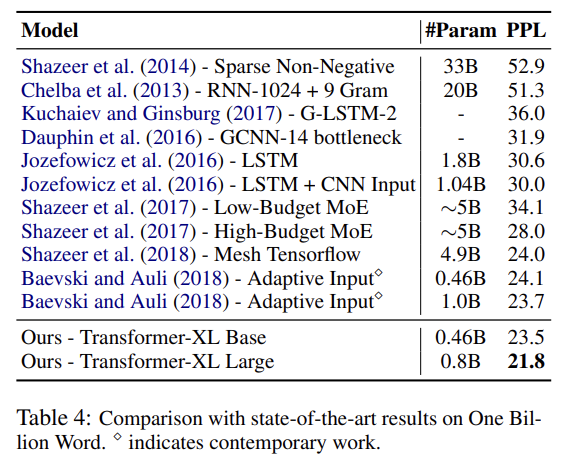
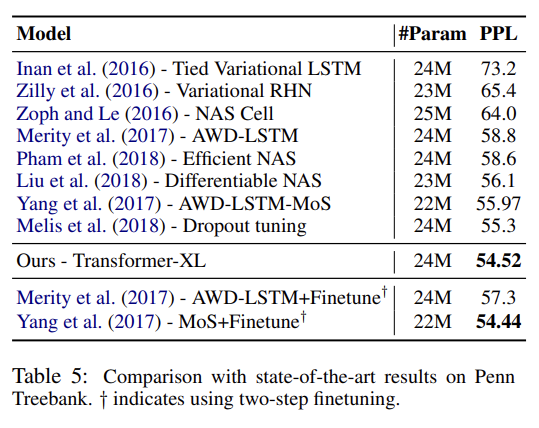
recurrence mechanism와 새로운 positional encoding scheme의 효과를 알아보고자 두 가지 ablation study도 한다.
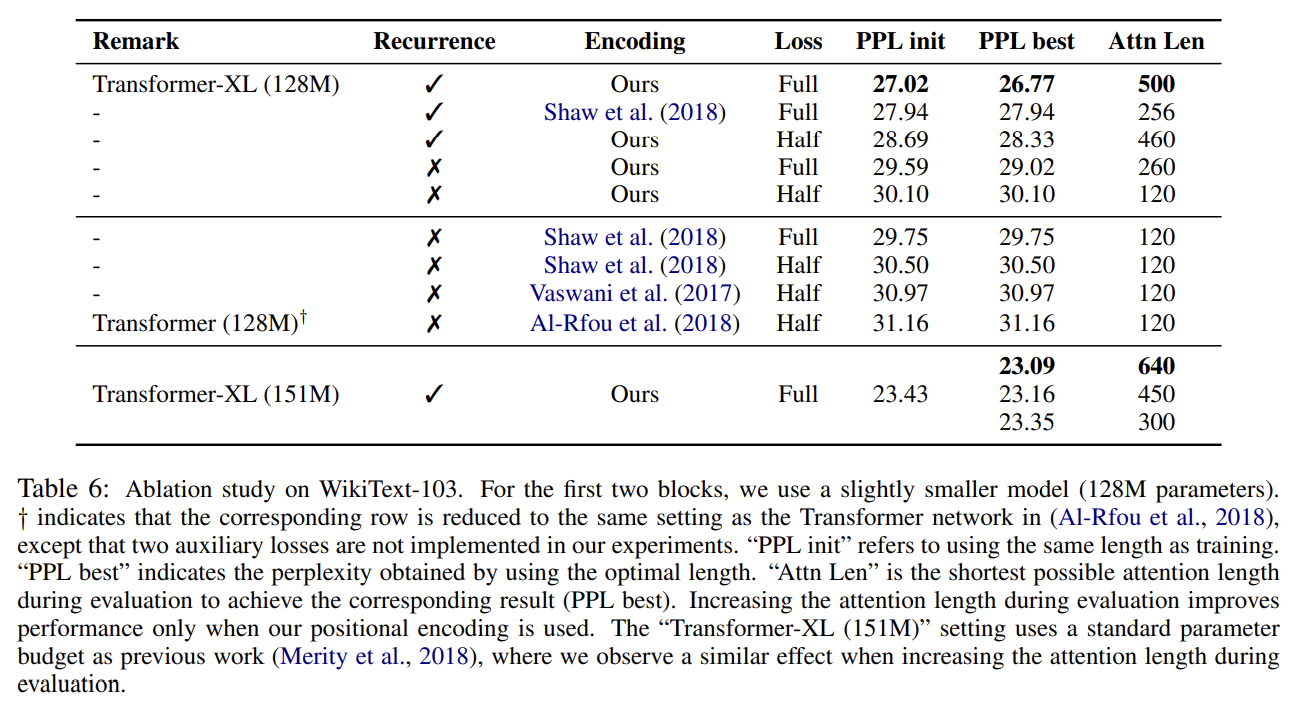
첫번째 실험은 long-term dependency를 modeling하도록 요구하는 WikiText-103에 수행해서 relative encoding scheme인 Shaw et al. (2018)와 absolute 방식인 Vaswani et al. (2017), Al-Rfou
et al. (2018)를 논문의 방식과 비교한다. “Full”, “half” losses는 cross entropy loss를 segment 내의 모든 position에 적용하냐, recent half position에 적용하냐를 의미한다. 실험 결과 absolute encoding은 half losses에만 잘 작동했다. Table 6에서 recurrence mechanism과 논문의 encoding scheme이 최고의 성능을 위해 필수적임을 알 수 있었다.
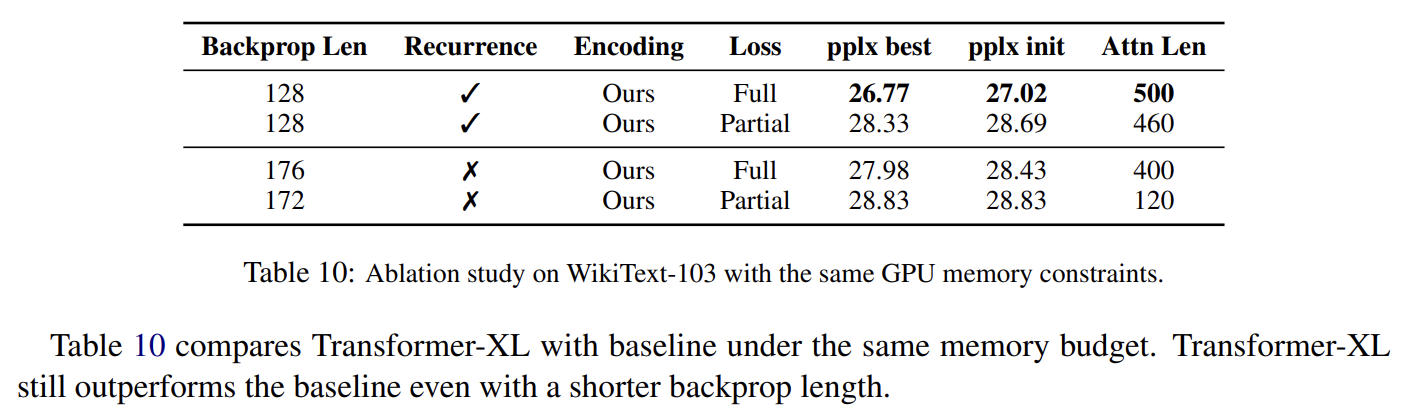
recurrence mechanism이 추가적인 메모리를 필요로 하기 때문에 동일한 GPU memory constraints 아래 Transformer-XL과 다른 baseline을 비교했다. backpropagation length가 짧음에도 Transformer-XL이 baseline보다 뛰어났다.

두번째 context fragmentation problem를 해결하는 효과와 longer context length를 포착하는 이점을 분리하는(isolate)하는 실험이다. 이를 위해 long term dependency를 요구하지 않는 One Billion Word dataset을 골랐으며 recurrence를 통해 얻을 수 있는 성능 향상이 context fragmentation 때문으로 국한되게 했다. Tab 7에서 long-term dependency가 불필요함에도 불구하고 segment-level recurrence를 사용하는 것이 상당한 성능 향상을 보여 recurrence mechanism이 context fragmentation problem을 해결함을 알 수 있었다.
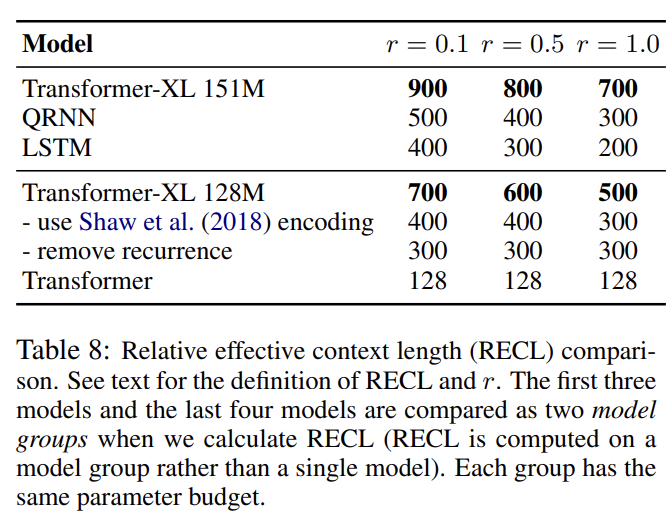
- Relative Effective Context Length
Khandelwal et al. (2018)는 sequence model의 Effective Context Length (ECL)를 평가할 방법을 제안했다. 논문은 대신 Relative Effective Context Length (RECL)라고 이름붙인 새로운 metric을 제안한다. RECL은 single model 대신 model group에 정의되며 long context의 gain이 best short context model에 대한(over) relative improvement로 측정된다. model group은 공평한 비교를 위해 동일한 baseline을 공유한다. RECL은 parameter r도 있어서 top-r hard examples를 비교하도록 제약을 둔다(constrain). 이 기준에 따르면 Transformer-XL의 RECL은 RNN보다 80% 길고 Transformer보다 450% 길다. recurrence mechanism와 relative positional encodings 모두 RECL에 기여했다.

- Evaluation Speed
마지막으로 Transformer-XL와 vanilla Transformer의 evalutaion speed를 비교했다. 전자가 후자보다 1,874배 빨랐다.
Strengths
- recurrence mechanism을 통해 context를 fixed length에서 동적으로 확장하고 context fragmentation problem도 해결했다.
- relative positional encoding을 제안해 recurrence mechanism에 absolute positional encoding을 사용했을 때 positional information이 무시되는 문제를 지적하고 해결했다.
- 기존의 Transformer보다 더 정확하고 속도도 훨씬 빠르다.
