오늘 리뷰할 논문은 마이크로소프트의 UNITER다.
사실 이틀 전에 이미 리뷰를 썼는데 억까 당해서 날아가버려서 다시 쓴다 ㅅㅂ
Summary
각 benchmark의 기존 SOTA 모델은 architecture이 다양하고 learned representations이 몹시 task-specific해서 다른 task에 일반화하기 어렵다. 그래서 논문은 모든 V+L tasks을 위한 universal image-text representation을 학습하고자 한다.
논문은 joint multimodal embedding을 위해 4가지 image-text datasets (COCO, Visual Genome, Conceptual Captions, SBU Captions)에 large-scale pre-training되는 UNITER (UNiversal Image-TExt Representation)을 소개한다. contextualized representations을 학습하기 위해 디자인된 self-attention mechanism을 이용하기(leverage) 위해 Transformer을 모델의 핵심으로 적용한다.
BERT에서 영감을 받아 4가지 pre-training tasks, image에 condition된 Masked Language Modeling (MLM), text에 condition된 Masked Region Modeling (MRM, with three variants), ImageText Matching (ITM), Word-Region Alignment (WRA)을 디자인한다. MRM의 효과를 더 조사하기 위해 3가지 변형, Masked Region Classification (MRC), Masked Region Feature Regression (MRFR), Masked Region Classification with KL-divergence (MRC-kl)을 제안한다.
양쪽 modality에 joint random masking를 적용하는 기존 방법과 달리 pre-training tasks에 conditional masking을 적용한다(즉, masked language/region modeling이 image/text의 full observation에 condition된다). global image-text alignment을 위한 ITM에 추가로 pre-training 중 words와 image regions 사이 fin-grained alignment를 명시적으로 장려하기 위해 Optimal Transport (OT)를 통한 WRA도 제안한다. 복합적인 분석은 conditional masking과 OT-based WRA 모두가 더 좋은 pre-training에 기여함을 보여준다. UNITER은 (9 datasets에) 6 V+L tasks, Visual Question Answering, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, 에 SOTA를 달성한다.
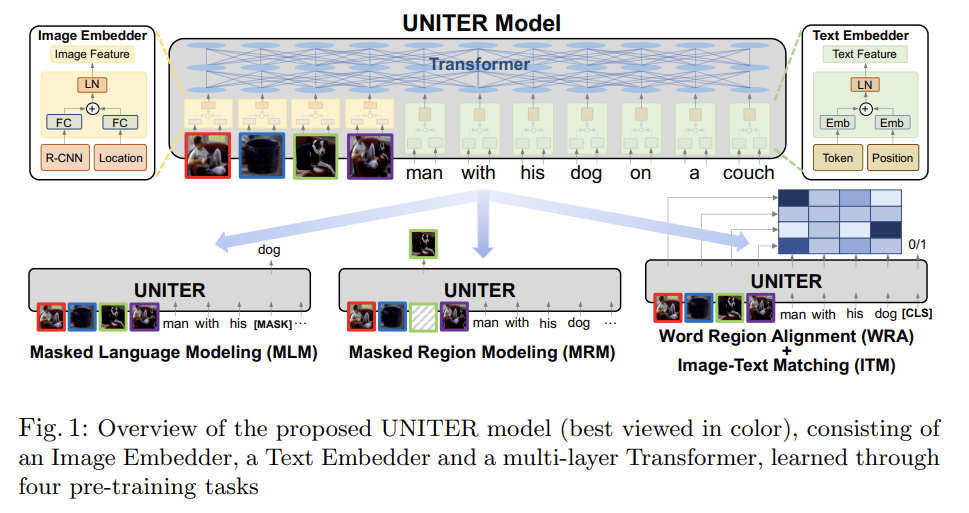
Fig 1에서 볼 수 있듯 UNITER은 먼저 Image Embedder와 Text Embedder을 가지고 image regions (visual features와 bounding box features)와 textual words (tokens와 positions)을 common embedding space으로 encode한다. 그 다음, well-designed pre-training tasks을 통해 각 region과 각 word에 대해 generalizable contextualized embeddings을 배우도록 Transformer module이 적용된다. multimodal pre-training에 대한 기존 연구와 달리 UNITER은 1. masked language/region modeling이 양쪽 modality에 joint random masking을 적용하는 게 아니라 image/text의 full observation에 condition되며 2. words와 image regions 사이 fine-grained alignmnet을 명시적으로 격려하기 위해 Optimal Transport (OT)를 통한 새로운 WRA pre-training task을 도입한다. 직관적으로 OT-based learning은 한 distribution을 다른 distribution으로 transport하는 cost를 최소화함으로써 distribution matching을 최적화한다. 우리의 맥락에선 image regions에서 sentence 내 words로의 embeddings을(그리고 그 역도) transport하는 cost를 최소화함으로써 더 좋은 cross-modal alignment을 향해 최적화한다. conditional masking과 OT-based WRA 둘 다 images와 text 사이 misalignment를 성공적으로 완화할 수 있음을 보인다.
UNITER의 generalizable power을 입증하기 위해 VQA, Visual Commonsense Reasoning (VCR), NLVR2, Visual Entailment, Image-Text Retrieval (including zero-shot setting), Referring Expression Comprehension을 포함하는 (9 datasets에 걸친) 6 V+L tasks에 평가한다. UNITER은 4 subset, COCO, Visual Genome (VG), Conceptual Captions (CC), SBU Captions으로 구성된 large-scale V+L dataset에 학습된다. UNITER은 모든 9 datasets에 상당한 성능 향상을 보이며 SOTA를 달성한다. (downstream tasks에 없는) 추가적인 CC와 SBU data에 학습하는 것도 COCO와 VG에만 학습하는 것보다 성능을 향상시킨다.
UNITER와 기존 방식의 차이점은 2가지다. (i) UNITER는 MLM과 MRM에 conditional masking을 사용한다. 즉, 하나의 modality만 mask하고 다른 modality는 그대로(untainted) 둔다. (ii) Optimal Transport의 활용을 통한 새로운 Word-Region Alignment pre-training task. 기존 연구에서 그런 alignment은 task-specific losses를 통해 내재적으로만 요구됐다(enforce).
model architecture에 대해 알아보자. image와 sentence 쌍이 주어질 때, UNITER은 image의 visual regions와 sentence의 textual tokens을 input으로 받는다. 각각의 embedding을 추출하기 위해 Image Embedder와 Text Embedder을 디자인한다. 이 embeddings는 visual regions와 textual tokens에 걸쳐 cross-modality contextualized embedding을 학습하기 위해 multi-layer Transformer에 먹여진다. Transformer 내 self-attention mechanism은 순서 무관(order-less)함을, 따라서 positions of token와 locations of regions을 추가적인 input으로 명시적으로 encode해야 함에 주의하라.
구체적으로 Image Embedder는 먼저 각 region에 대해 visual features (pooled ROI features)을 추출하기 위해 Faster R-CNN을 사용한다. 또 각 region에 대한 location features를 7-dimensional vector으로 encode한다. 그 다음 동일한 embedding space로 project하기 위해 visual features와 location features 모두 fully-connected (FC) layer로 먹여진다. 각 region에 대한 final visual embedding은 두 FC outputs을 합하고 layer normalization (LN) layer을 통과시켜 얻어진다. Text Embedder는 BERT를 따르며 input sentence를 WordPieces로 tokenize한다. 각 sub-word token에 대한 final representation은 word embedding과 position embedding을 합하고 또다른 LN layer을 통과시켜 얻어진다.
이제 pre-training task에 대해 알아보자. MRM과 MLM은 BERT와 유사하며 input에서 몇 words나 regions을 랜덤하게 mask하고 Transformer output으로 그걸 복구하고자 하는 것이다. 구체적으로 word masking은 token을 special token [MASK]로 대체하고 region masking은 visual feature vector를 all zeros로 대체함으로써 구현된다. 한 번에 한 modality만 mask하고 다른 modality는 그대로(intact) 둠을 유의하라. 이는 masked region이 masked word에 의해 묘사되는 경우의 잠재적인 misalignment를 예방한다.
또 ITM을 통해 전체 image와 sentence 사이 instance-level alignment도 학습한다. training 중에 positive와 negative image-sentence pairs를 모두 sample하고 그들의 matching scores을 학습한다. 또 word tokens와 image regions 사이 more fine-grained alignment을 제공하기 위해 Optimal Transport 활용을 통한 WRA를 제안한다. 이는 contextualized image embeddings을 word embeddings로(그리고 그 역도) transport하는 최소 비용을 효과적으로 계산한다. 따라서 inferred transport plan은 더 좋은 cross-modal alignment을 위한 추진력 역할을 한다. 이런 tasks로 UNITER을 pre-train하기 위해 각 mini-batch 당 하나의 task를 랜덤하게 sample하고 SGD update 당 하나의 objective으로만 학습한다.
- Masked Language Modeling (MLM)
image regions을 로, input words을 w = w_1, ..., w_T}로, mask indices을 으로 표기한다. MLM에서 input words를 15% 확률로 랜덤하게 mask out하고 mask된 을 special token [MASK]로 대체한다. 목표는 surrounding words 와 모든 image regions v를 관측한 것에 기반해 negative log-likelihood을 최소화함으로써 이 masked words를 예측하는 것이다.
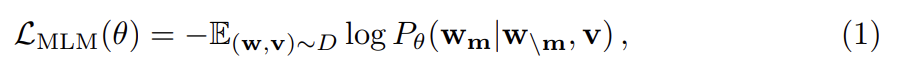
θ는 trainable parameters다. 각 (w, v) 쌍은 전체 training set D에서 sample된다.
- Image-Text Matching (ITM)
ITM에선 additional special token [CLS]이 모델로 먹여지며 이는 양쪽 modalities의 fused representation을 나타낸다. ITM으로의 input은 sentence와 set of image regions이며 output은 sampled pair이 match하는지 나타내는 binary label y ∈ {0, 1}이다. [CLS] token의 representation을 input image-text pair의 joint representation으로서 추출하며 0~1 사이 score를 예측하기 위해 FC layer와 sigmoid function에 먹인다. output score을 로 표기한다. ITM supervision은 [CLS] token 위에(over) 있다. trainig 중에 각 step마다 dataset D에서 positive 또는 negative pair (w, v)를 sample한다. negative pair은 paired sample 내 image나 text를 다른 sample의 randomly-selected image/text로 대체함으로써 만들어진다. 최적화를 위해 binary cross-entropy loss를 적용한다.
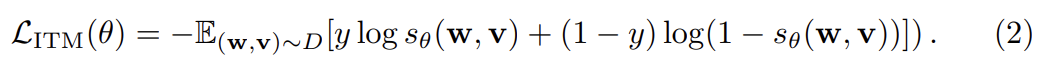
- Word-Region Alignment (WRA)
WRA를 위해 Optimal Transport (OT)를 사용하며, 여기서 w와 v 사이 alignment를 최적화하기 위해 transport plan 가 학습된다. OT는 WRA에 적합한 여러 특이한 특징이 있다.
(i) Self-normalization: T의 모든 elements 합이 1
(ii) Sparsity: 정확히 풀었을(solve) 때, OT는 최대 (2r - 1) non-zero elements를(r = max(K, T)) 보유하는 sparse solution T를 만든다. 이는 더 interpretable하고 robust한 alignment를 이끌어낸다.
(iii) Efficiency: 전통적인 linear programming solvers와 비교했을 때, 논문의 solution은 matrix-vector products만 요구하는 iterative procedures을 사용해 쉽게 구할 수 있어 large-scale model pre-training에 쉽게 적용 가능하다.
구체적으로 (w, v)는 두 discrete distributions µ, ν로 고려될 수 있으며 로 공식화된다. 는 에 center된 Dirac function이다. µ와 ν가 probability distributions이기 때문에 weight vectors 와 는 각각 T-dimensional, K-dimensional simplex에 속한다. 즉, 이다. µ와 ν 사이 OT distance는 (따라서 (w, v) 쌍에 대한 alignment loss도) 다음과 같이 정의된다.
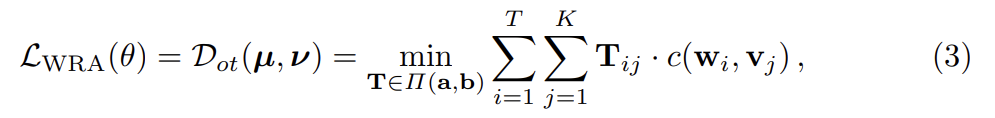
이고, 은 n-dimensional all-one vector을 나타내고, 은 와 사이 거리를 평가하는 cost function이다. 실험에선 cosine distance 이 사용된다. matrix T는 transport plan이며 두 modalities 사이 alignment를 설명한다(interpret). 불행히도 T에 대한 정확한 minimization은 computational intractable하므로 OT distance를 근사하기 위해 IPOT algorithm [53]을 고려한다. T를 푼 후, OT distance는 parameters θ update에 사용될 수 있는 WRA loss 역할을 한다.
- Masked Region Modeling (MRM)
MLM과 비슷하게 image regions도 sample하고 15% 확률로 region의 visual features을 mask한다. 모델은 remaining regions 과 모든 words w가 주어졌을 때 masked regions 을 재구성하도록 훈련된다. masked region의 visual features는 zeros로 대체된다. discrete labels로 표현되는 textual tokens와 달리 visual features는 high-dimensional하고 continuous해서 class likelihood를 통해 supervise될 수 없다. 대신 MRM에 3가지 변형을 소개하며, 이들은 같은 objective base를 공유한다.
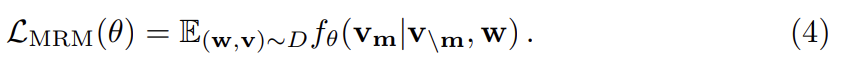
1) Masked Region Feature Regression (MRFR)
MRFR은 각 masked region 의 Transformer output을 그것의 visual features로 regress하도록 학습한다. 구체적으로는 Transformer output을 input ROI pooled feature 와 동일한 차원의 vector 로 전환하기 위해 FC layer을 적용한다. 그 다음 둘 사이 L2 regression을 적용한다.
2) Masked Region Classification (MRC)
MRC는 각 masked region에 대한 object semantic class를 예측하도록 학습한다. 먼저 K object classes에 대한 scores를 예측하기 위해 masked region 의 Transformer output을 FC layer에 먹인다. 이는 softmax function을 통과해 normalized distribution 로 변환된다. object categories가 제공되지 않기 때문에 ground-truth label이 없음에 주의하라. 따라서 Faster R-CNN로부터의 object detection output을 사용하고 (가장 높은 confidence score을 가진) detected object category를 masked region의 label로 택해 one-hot vector 로 전환한다. 최종 objective는 cross-entropy (CE) loss을 최소화한다.
3) Masked Region Classification with KL-Divergence (MRC-kl)
MRC는 detected object class가 region에 대한 ground-truth label이라고 가정하고 object detection model에서 가장 그럴듯한 object class를 hard label (w.p. 0 or 1)로 택한다. 그러는 이는 사실이 아닐 수 있는데, ground-truth label이 존재하지 않기 때문이다. 따라서 MRC-kl에선 detector로부터의 raw output인(즉, distribution of object classes ) soft label을 supervision signal으로 사용하여 이 가정을 거부한다. MRC-kl은 두 distributions 사이 KL divergence을 최소화함으로써 [16]처럼 UNITER에 그런 지식을 distill하도록 목표한다.
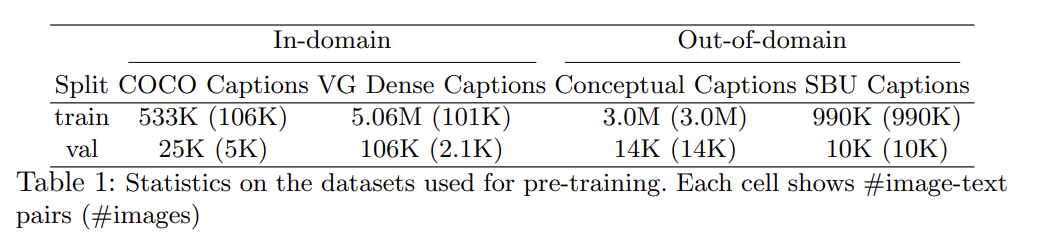
pre-training dataset은 기존의 4가지 V+L datasets, COCO [26], Visual Genome (VG) [21], Conceptual Captions (CC) [41], and SBU Captions [32]을 기반으로 구성했다. pre-training에 image와 sentence pair만 사용해서 (추가적인 image-sentence pairs을 추가하기 쉽기 때문에) model framework가 더 scalable하다.
(데이터셋 분류 설명 생략)
실험은 6 V+L tasks에 평가한다. 2가지 모델 크기로, 12층짜리 UNITER-base와 24층짜리 UNITER-large에 결과를 보고한다.
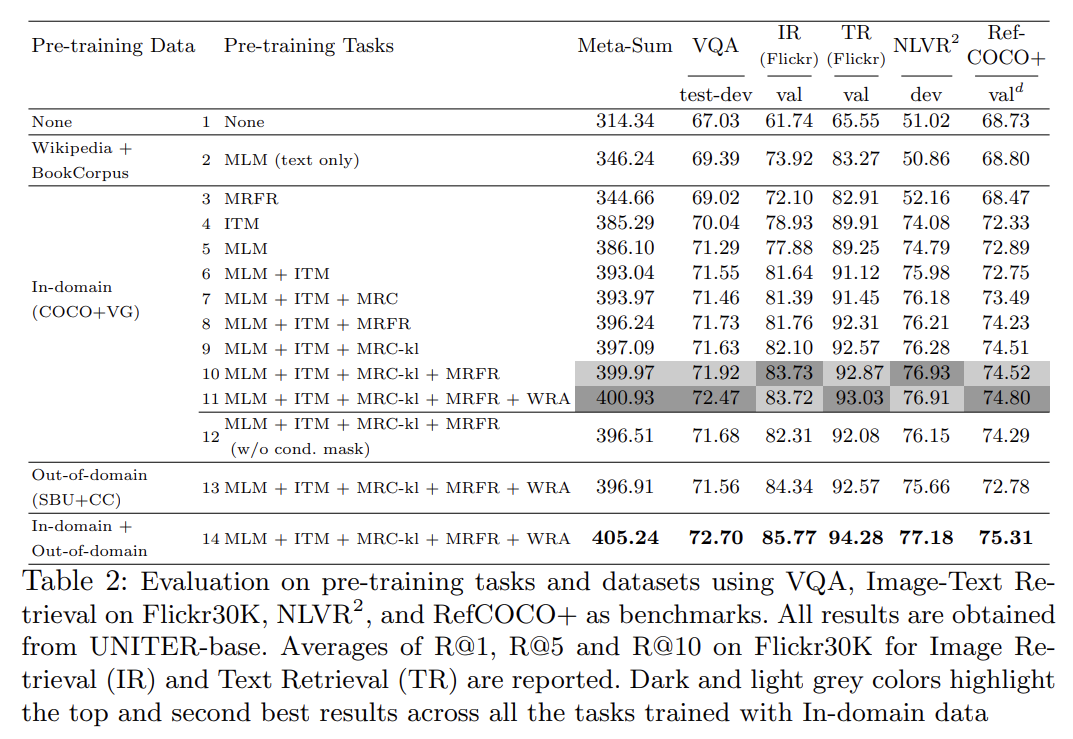
ablation study를 통해 pre-training setting을 비교한다. 설명은 생략한다.
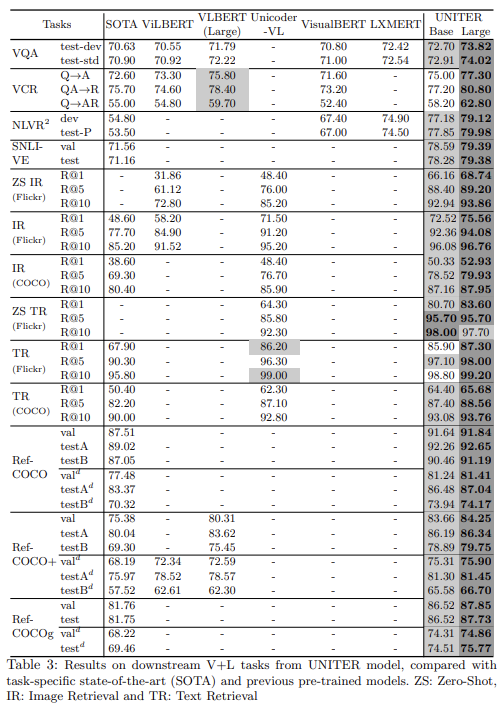
Tab 3는 모든 downstream tasks에 UNITER 결과를 보여준다. base와 large model 둘 다 In-domain+Out-of-domain datasets에 optimal pre-training setting (MLM+ITM+MRC-kl+MRFR+WRA)을 가지고 pre-train됐다.
결과는 UNITER-large model이 모든 benchmarks에서 SOTA를 달성함을 보여준다. UNITER-base model도 VQA를 제외하고 모든 task에서 다른 모델보다 성능이 뛰어나다. LXMERT가 downstream VQA (+VG+GQA) data를 가지고 pre-train해서 VQA task에 적응했을 수 있음에 주의하라. 그러나 NLVR2 같은 unseen tasks에 평가되면 UNITER-base가 LXMERT보다 뛰어나다. 또 VilBERT와 LXMERT 결과에서 two-stream model이 single-stream model보다 뛰어남을 관측할 수 있는데 UNITER-base 결과는 논문의 pre-training setting에서 single-stream model이 더 적은 parameter로 SOTA를 달성할 수 있음을 경험적으로 보인다.
(이하 설명 생략)
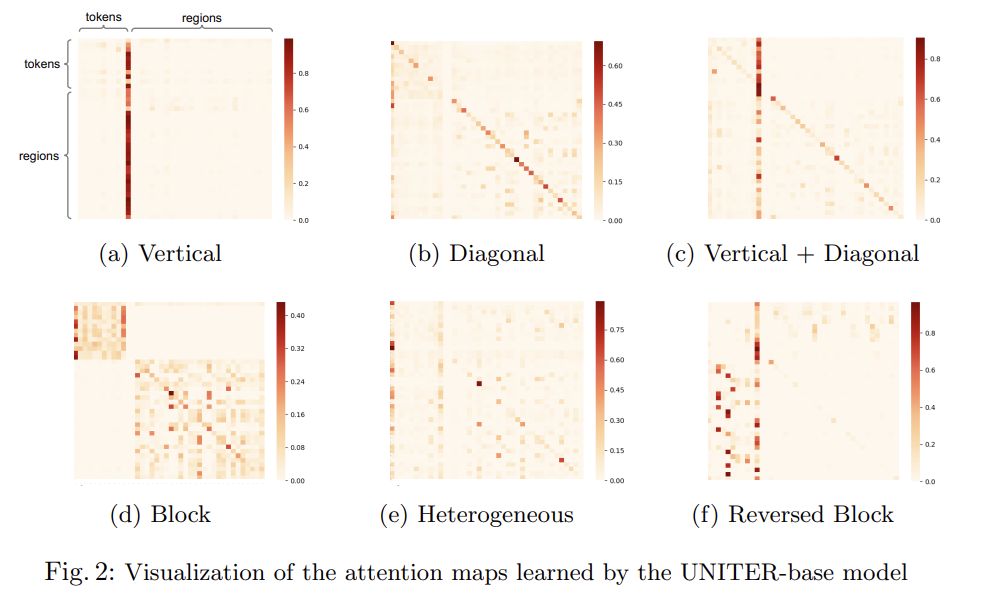
[20]과 비슷하게 UNITER model의 attention maps에서 몇 patterns을 관찰했다. [20]과 달리 논문의 attention mechanism은 inter-modality와 intra-modalitiy manners 둘 다 작동함을 주의하라.

Reversed Block (Fig. 2f)이 tokens와 regions 사이 cross-modality alignment를 보여줌에 주의하라. Fig 3에선 regions와 tokens 사이 local cross-modality alignment를 입증하기 위해 몇 가지 text-to-image attention 예시를 시각화한다.

Strengths
- 양쪽 modality가 모두 mask되는 경우가 없게 해서 잠재적인 misalignment를 피했다.
- single-stream model이 two-stream model보다 뛰어날 수도 있음을 보였다.
objective을 가중합하는 게 아니라 mini-batch마다 랜덤하게 하나를 sample하는 학습 방식이 특이했다.
그런데 OT가 뭔지 몰라서 WRA는 이해가 안됐다. 이게 핵심 아이디어 중 하나 같은데...
