오늘 리뷰할 논문은 VisualBERT 논문이다.
최초의 image-text pre-training model이라고 한다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
VisualBERT는 self-attention을 가지고 input text와 regions의 elements를 associated input image 내에 내재적으로 align하는 Transformer layers의 stack으로 구성된다. image caption data에 VisualBERT를 pretraining하는 2가지 visually-grounded language model objectives를 제안한다. 4가지 visual-and-language tasks, VQA, VCR, NLVR2, Flickr30K에 실험한 결과 VisualBERT가 SOTA 모델보다 더 간단하면서 성능은 더 좋았다. 분석은 VisualBERT가 명시적인 감독(supervision) 없이 elements of language를 image regions으로 ground할 수 있고 심지어 (verbs와 argument에 상응하는 image regions 사이) syntactic relationships/tracking/association에 민감하다는 것을 보인다.
VisualBERT는 자연어 처리를 위한 BERT와 Faster-RCNN 같은 pretrained object proposals systems을 통합한다. object proposals에서 추출된 image features는 unordered input tokens로 취급되어 text와 함께 VisualBERT로 먹여진다. text와 image inputs는 multiple Transformer layers로 공동으로 처리된다. words와 object proposals 간 풍부한 상호작용은 모델이 text와 image 사이 복잡한 연관성을 포착하게 해준다.
pre-training을 위해 2가지 visually-grounded language model objectives을 제안한다. 1. text 일부를 mask하고 remaining text와 visual context에 기반해 masked words를 예측한다. 2. 제공된 text가 image와 match하는지 판별한다.
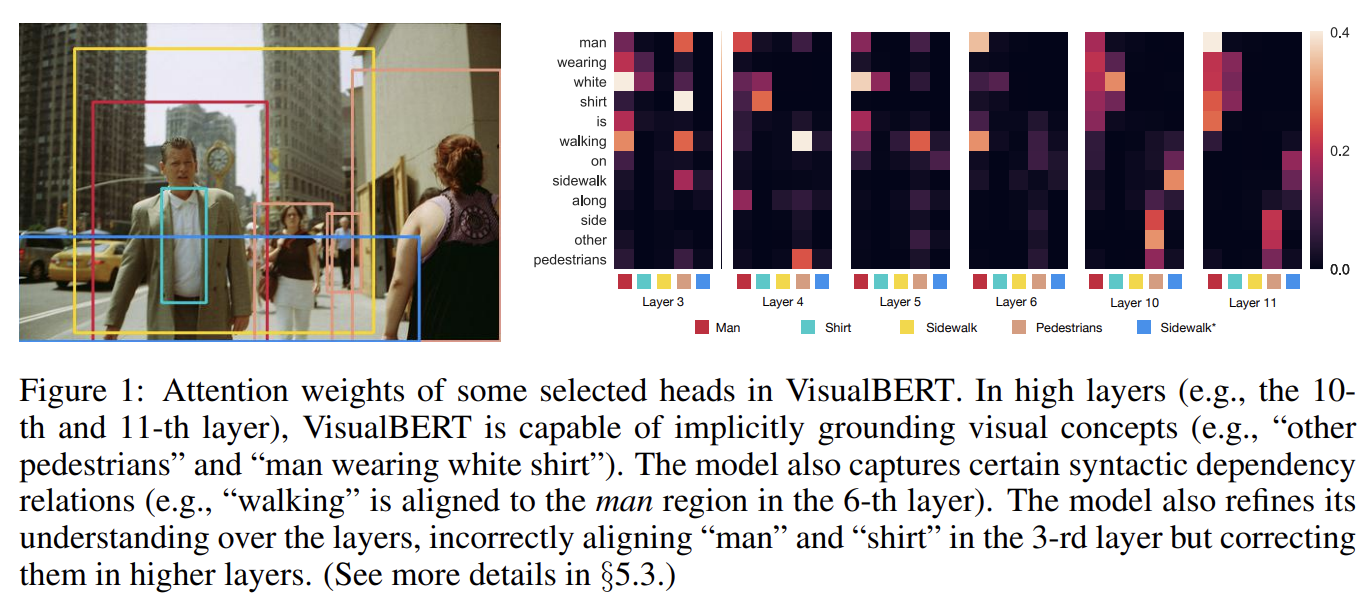
추가적인 양적, 질적 분석은 VisualBERT가 내적으로 words와 image regions을 align하기 위해 어떻게 attention weights를 할당하는지 밝힌다. 논문은 VisualBERT가 pre-training을 통해 entities를 ground하고 words와 image regions 사이 특정 dependency relationships을 encode함을 입증한다. 이는 모델이 사진의 세부적인 semantics를 이해하는 데 기여한다.
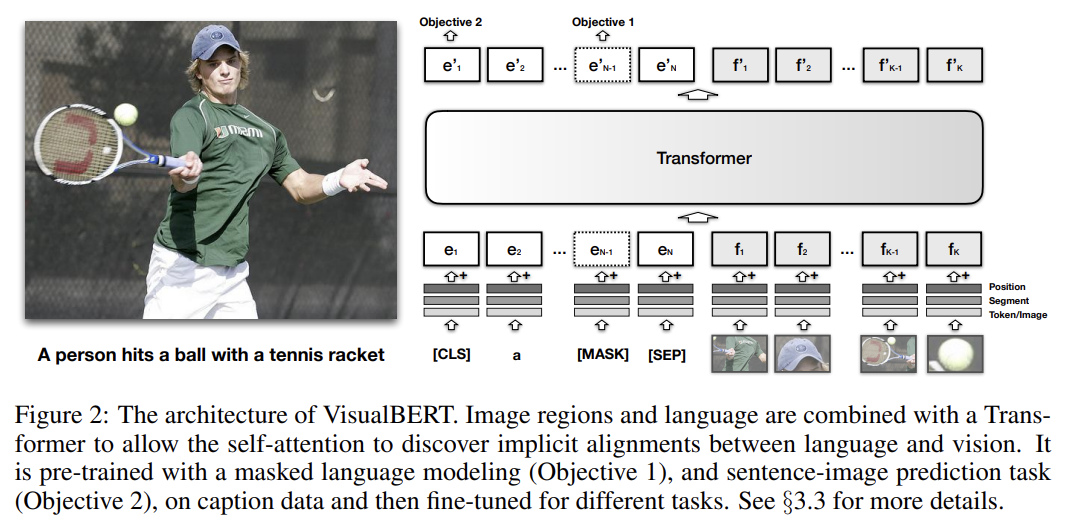
(BERT 설명 생략)
핵심 아이디어는 input text의 elements와 input image 내 regions을 내재적으로 align하기 위해 Transformer 내에서 self-attention mechanism을 재사용하는 것이다. BERT의 모든 구성요소에 추가로 image를 model하기 위해 set of visual embeddings F를 도입한다. 각 f ∈ F는 image 내의 (object detector에서 얻은) bounding region에 상응한다.
F 내의 각 embedding은 3가지 embedding을 합함으로써 계산된다.
1. : CNN으로 계산되는, f의 bounding region의 visual feature representation
2. : 이것이 text embedding이 아니라 image embedding임을 나타내는 segment embedding
3. : words와 bounding regions 사이 alignments가 input의 일부로 주어졌을 때 사용되는 position embedding. 이는 aligned words에 상응하는 position embeddings의 합으로 설정된다.
그 다음 visual embeddings는 original set of text embeddings과 함께 multi-layer Transformer에 전해져서 모델이 두 input 집합 사이 유용한 alignment를 발견하고 joint representation을 개발하도록 한다.
BERT와 비슷한 학습 절차를 적용하지만 VisualBERT는 language와 visual input 둘 다를 수용해야 한다. 따라서 각 image마다 5개의 독립적인 caption을 가지는 COCO 데이터셋을 사용한다. 학습 절차는 3단계로 구성된다.
- Task-Agnostic Pre-Training
2 visually-grounded language model objectives을 사용해 VisualBERT를 COCO에 학습시킨다.
(1) image를 가진 Masked language modeling. text input의 몇 elements가 mask되지만 image region에 상응하는 vectors는 mask되지 않는다.
(2) Sentence-image prediction. 사진 하나에 여러 caption이 달린 COCO에 대해 2개 caption으로 구성된 text segment를 제공한다. caption 하나는 image를 묘사하고 있으며 나머지 하나는 50% 확률로 image를 묘사하고 50% 확률로 랜덤하게 뽑은 caption이다. 모델은 이 두 경우를 구분하도록 학습된다.
- Task-Specific Pre-Training
fine-tuning 전에 downstream task의 data를 사용해 image objective를 가진 masked language modeling로 모델을 학습시키면 이롭다는 것을 발견했다. 이 단계는 모델이 새로운 traget domain에 적응하게 해준다.
- Fine-Tuning
이 단계는 BERT fine-tuning을 따라하며 task-specific input, output, objective가 도입된다.
실험은 4가지 vision-and-language applications에 평가한다.
(1) Visual Question Answering (VQA 2.0) (Goyal et al., 2017)
(2) Visual Commonsense Reasoning (VCR) (Zellers et al., 2019)
(3) Natural Language for Visual Reasoning (NLVR2
) (Suhr et al., 2019)
(4) Region-to-Phrase Grounding (Flickr30K) (Plummer et al., 2015)
모든 task에서 task-agnostic pre-training을 위해 COCO의 Karpathy train split (Karpathy & Fei-Fei, 2015)을 사용한다. 모든 모델의 Transformer encoder는 와 동일한 설정이다(12 layers, 768 hidden size, 12 self-attention heads). parameter는 pre-trained parameters로 초기화된다.
image representations의 경우 우리가 연구하는 각 데이터셋은 (region proposals와 region features을 생성하기 위해) 서로 다른 standard object detector을 가진다. 그들과 비교하기 위해 그들의 세팅을 따르며 그 결과 각 tasks에 서로 다른 image features가 사용된다. 일관성을 위해 COCO에 task-agnostic pre-training을 할 때 end tasks와 동일한 image features를 사용한다. 각 데이터셋에 모델의 3가지 버전을 평가한다.
(1) VisualBERT : BERT로 parameter initialization을 하고 COCO에 pre-training을 겪고 fine-tuning하는 full model.
(2) VisualBERT w/o Early Fusion : image representations가 text와 initial Transformer layer에서 결합되지 않고 대신 끝에서 new Transformer layer에서 결합된다. 이는 language와 vision 사이 상호작용이 전체 Transformer stack에서 성능에 중요한지 실험하게 해준다.
(3) VisualBERT w/o COCO Pre-training : COCO captions에 task-agnostic pre-training을 생략한다. 이는 그 단계의 중요성을 입증하게 해준다.
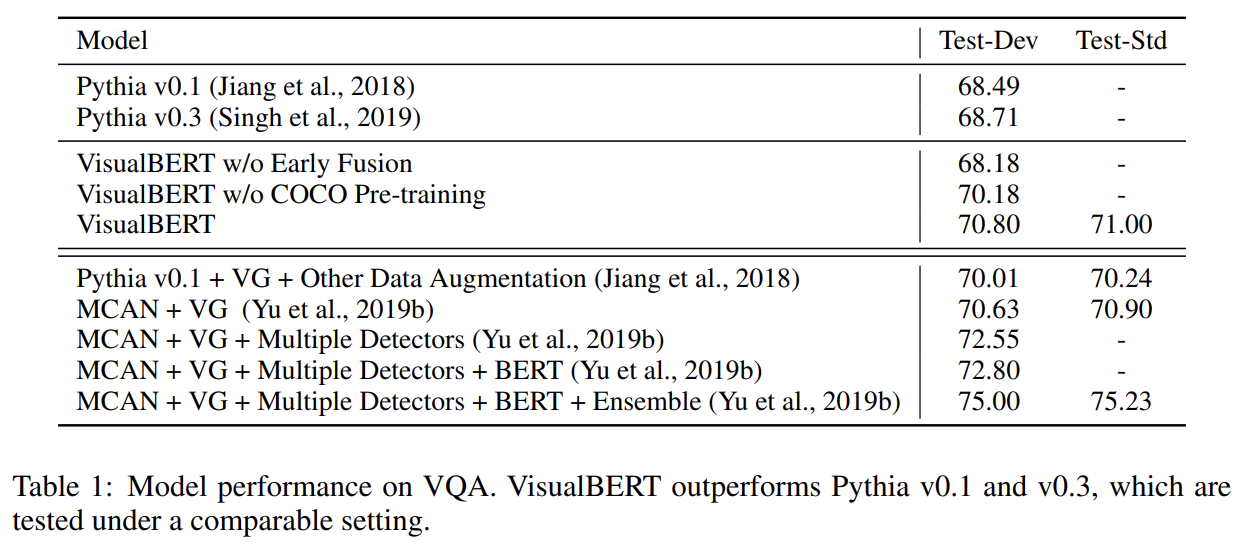
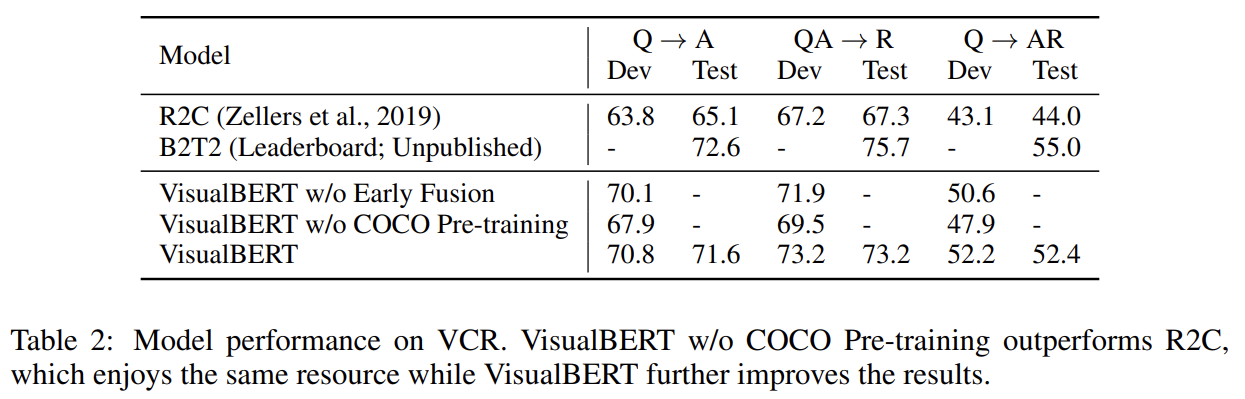
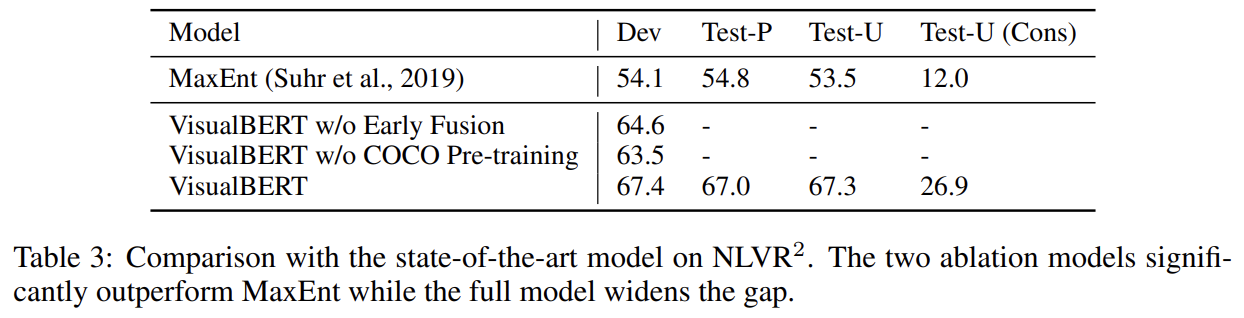
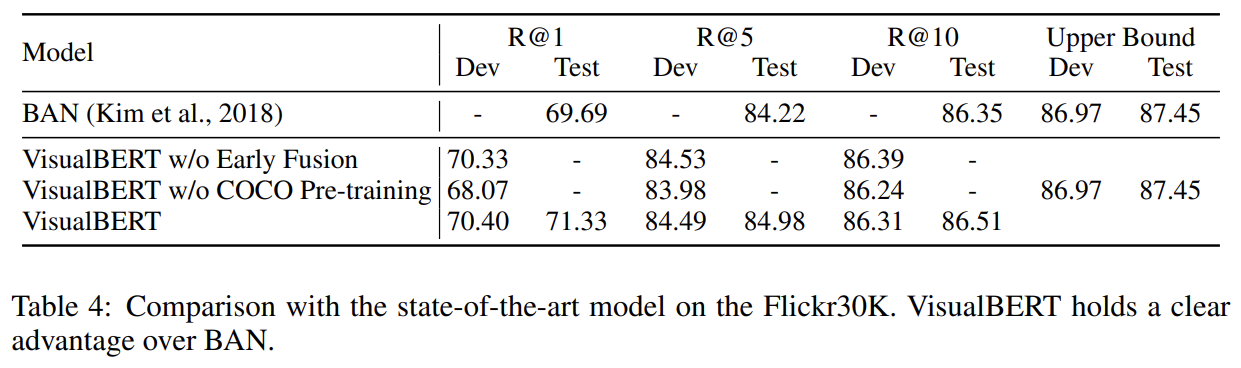
실험 결과는 생략한다.
VisualBERT의 어느 부분이 성능에 중요한지 분석한다. diagnostic dataset으로는 Flickr30K를 사용한다.
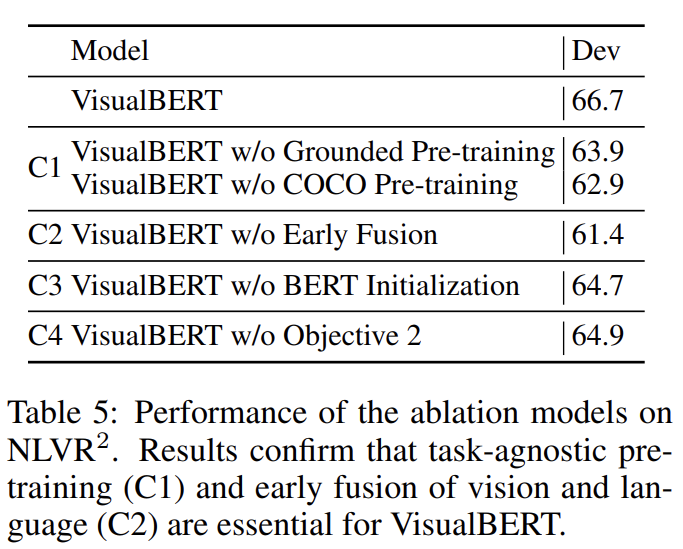
NLVR2에 ablation study를 수행하며 앞서 설명한 2개의 ablation model과 추가적인 4개의 모델을 비교한다. 연산을 완화하기 위해 모든 모델은(full model 포함) image 당 36 features로만 학습된다.
(1) C1: Task-agnostic Pre-training
task-agnostic pre-training의 기여를 알기 위해 이를 생략하고(VisualBERT w/o COCO Pre-training) 또한 COCO에서의 image 없이 text로만 pre-training한다(VisualBERT w/o Grounded Pre-training). 두 변형 모두 underperform하며 paired vision and language data에 pre-trainig하는 것이 중요함을 보여준다.
(2) C2: Early Fusion
image와 text features 사이 early interaction을 허용하는 것의 중요성을 입증하기 위해 VisualBERT w/o Early Fusion를 포함한다. vision과 language 사이 multiple
interaction layers이 중요함을 다시 입증한다.
(3) C3: BERT Initialization
여태까지 모든 모델은 pre-trained BERT model로 parameter가 초기화됐다. BERT initialization의 기여를 이해하기 위해 randomly initialized parameters를 가진 변형을 도입한다. 그 다음 모델은 full model으로 훈련된다. language-only pre-trained BERT로부터의 가중치가 중요한 것처럼 보이지만 예상만큼 크게 성능이 하락하지는 않았다. 이는 모델이 COCO pre-training 중에 grounded language에 대한 동일한 유용한 측면을 학습함을 주장한다.
(4) C4: The sentence-image prediction objective
task-agnostic pre-training 중 sentence-image prediction objective 가 없는 모델을 도입한다(VisualBERT w/o Objective 2). 결과는 이 objective가 positive하지만 다른 요소에 비해선 덜 중요한 효과를 가짐을 보여준다.
전체적으로 결과는 task-agnostic pre-training (C1)과 early fusion of vision and language (C2)가 가장 중요한 design choice임을 보여준다. pre-training에서 additional COCO data 포함과 image와 caption 둘 다 사용하는 것이 가장 중요하다.
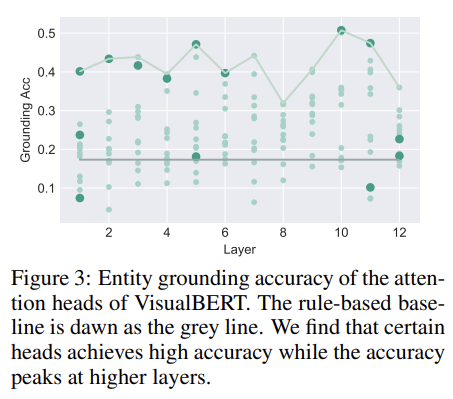
이제 VisualBERT가 fine-tuned되기 전에 어떤 bounding regions가 words에 의해 attend되는지 조사한다.
- Entity Grounding
먼저 VisualBERT 내에서 entity grounding을 수행할 수 있는 attention heads를 찾고자 시도한다. 즉, 문장 내 entities에서 상응하는 bounding regions에 attend하는 부분을 찾는 것이다. 구체적으로는 Flickr30K의 evaluation set에서 ground truth alignments을 사용했다. sentence 내 각 entity와 VisualBERT 내 각 attention head에 대해 최대의 attention weight를 받는 bounding region을 살펴본다. word가 image region뿐 아니라 text 내 words도 attend하기 때문에 이 평가에선 words로의 head의 attention을 mask out하고 image regions로의 attention만 유지했다. 그 다음 특정 head가 얼마나 자주 Flickr30K 내의 주석에 동의하는지 계산했다.
Fig 3에서 layer 순으로 모든 144 attention heads의 accuracy를 기록했다. highest detection confidence를 가진 region을 선택하는 baseline도 고려했다. entity grounding를 위한 직접적인 감독(supervision)이 없음에도 VisualBERT는 두드러지게 높은 정확도를 보인다. 또 grounding accuracy는 higher layers에서 높아지는데, 모델이 lower layer에서 두 inputs을 합성할 때는 덜 확신하는데(certain) 갈수록 어떻게 align할지 알게 되는 것이다.
- Syntactic Grounding
BERT의 attention heads가 syntactic relationships을 발견할 수 있던 것처럼 어떻게 grounding information이 VisualBERT가 발견했을 수도 있는 syntactic relationships를 통해 전해지는지 분석한다. 구체적으로는 dependency relation 으로 연결된 두 단어가 주어질 때 에 있는 attention heads가 얼마나 자주 에 상응하는 regions에 attend하는지(그리고 그 역도) 알고 싶은 것이다.
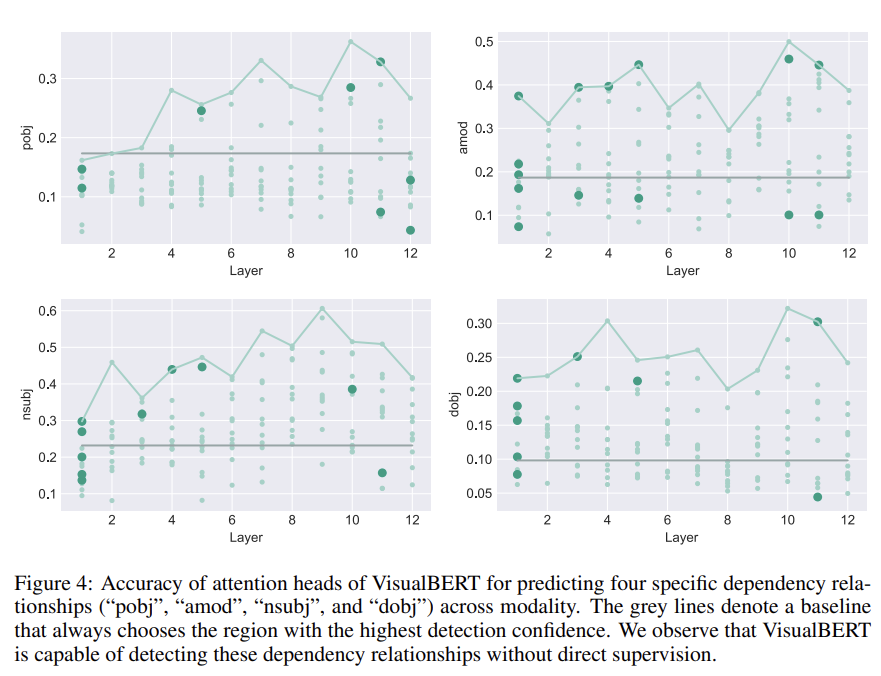
VisualBERT의 그런 syntactic sensitivity을 평가하기 위해 먼저 Flickr30K 내 모든 문장을 AllenNLP’s dependency parser을 통해 parse했다. 그 다음 VisualBERT 내 각 attention head에 대해, 주어진 두 단어가 특정 dependency relationships을 가졌을 때, 그리고 그 중 하나가 Flickr30K 내에 ground-truth grounding를 가질 때, head attention weights가 얼마나 정확하게 ground-truth grounding을 예측하는지 계산한다. 모든 dependency relationships에 실험한 결과 각 relationship 당 적어도 하나의 head가 most confident bounding region를 추측하는 데 상당히 outperform함을 보여준다. 많은 heads가 arguments를 verb와 정확히 연관시켜 VisualBERT가 감독(supervision) 없이 이 arguments를 visual elements에 연관시킴(resolve)을 보여준다.
Weaknesses
- 모델이 좀 task-specific하다는 생각이 들었다. task-specific pre-training이라던가, object detector와 그로 인한 image feature가 task마다 다르다던가, VQA test set이 pre-trainig에 사용된 COCO라던가. 이건 반칙 아닌가...
초기 논문이라 그런지 이전에 읽은 논문들보다 아이디어가 간단하고 익숙했다(그래서 리뷰에서 Strengths를 생략했다). pre-training에서 언어에는 MLM을 사용하고 image와 text가 match하는지 예측하는 방식이 이후 논문에 영향을 준 것 같다. BERT와 vision을 결합한 초기 논문이라는 데 의의가 있는 것 같다.
