오늘 리뷰할 논문은 마이크로소프트의 VL-BERT 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- VL-BERT:Visual-Linguistic BERT [Kor]
- VL-BERT, ViL-BERT 논문 설명(VL-BERT - Pre-training of Generic Visual-Linguistic Representations, ViLBERT - Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks)
Summary
논문은 visual-linguistic tasks를 위한 pre-trainable generic representation인 Visual-Linguistic BERT (VL-BERT)을 소개한다. VL-BERT의 backbone은 (multi-modal) Transformer attention
module이며 input sentence로부터 word를, input image로부터 region-of-interest (RoI)를 받는다. VL-BERT는 massive-scale Conceptual Captions dataset와 text-only corpus에 학습한다. VL-BERT는 visual commonsense reasoning, visual question answering and referring expression comprehension 같은 여러 downstream visual-linguistic tasks에 SOTA를 달성한다. 특히 visual commonsense reasoning의 leaderboard에서 single model에 1등을 차지한다.
(BERT 설명 생략)
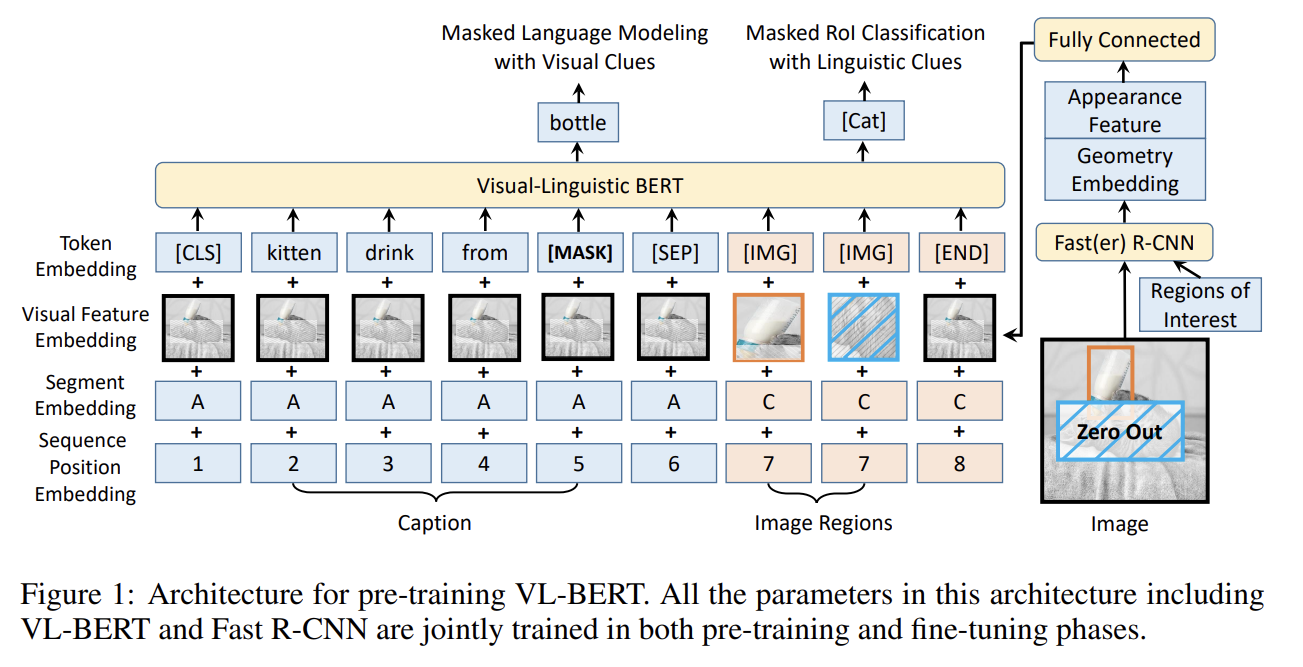
Fig 1은 VL-BERT architecture을 보여준다. 기본적으로 visual contents를 수용하기 위해 새 elements를 추가하고 input feature embeddings에 새로운 종류의 visual feature embedding을 추가함으로써 BERT를 수정한다. BERT와 비슷하게 backbone은 multi-layer bidirectional Transformer encoder이라 모든 input elements 간 dependency modeling을 가능하게 한다. BERT와 달리 VL-BERT는 visual과 linguistic elements 모두를 input으로 받으며 각각 images 내 regions-of-interest (RoIs)와 input sentences로부터의 sub-words로 정의된다. RoI는 object detectors로 생성된 bounding boxes일 수도 있고 특정 tasks에서 annotated ones일 수도 있다.
input formats는 서로 다른 visual-linguistic tasks 간에 다양하다. 그러나 Transformer attention의 unordered representation nature 덕분에(sentence 내 word의 position은 input sequence에서의 order가 아니라 positional embedding으로만 encode된다) input elements와 embedding features가 적절히 디자인되었다면 generic representation을 얻을 수 있다. 3종류 input elements, 즉 visual, linguistic, 그리고 서로 다른 input formats를 구분하기 위한 special elements가 포함된다. input sequence는 항상 special classification element ([CLS])로 시작하고 linguistic elements, visual elements, special ending element ([END]) 순으로 끝난다. linguistic elements 내에 서로 다른 sentences 사이와 linguistic과 visual elements 사이에 special separation element ([SEP])가 삽입된다. 각 input element에 대해 embedding feature는 4종류 embedding, 즉 token embedding, visual feature embedding, segment embedding, sequence position embedding의 합이다. 그 중 visual feature embedding가 visual 단서를 포착하기 위해 새로 도입됐으며 다른 셋은 BERT의 디자인을 따랐다.
- Token Embedding
BERT를 따라 linguistic words가 30,000 vocabulary를 가진 WordPiece embeddings (Wu et al., 2016)로 embed된다. special token은 각 special element에 할당된다. visual elements에 대해 그들 각각 special [IMG] token이 할당된다.
- Visual Feature Embedding
먼저 visual appearance feature와 visual geometry embedding를 따로 묘사하고 visual feature embedding을 형성하기 위해 둘을 어떻게 조합하는지 묘사한다.
RoI에 상응하는 visual element에 대해 visual appearance feature은 Fast R-CNN detector (즉 Faster R-CNN 내 detection branch)을 적용함으로써 추출되고 각 RoI의 output layer 이전 feature vector가 visual feature embedding으로 활용된다(논문에선 2048-d). non-visual elements의 경우 상응하는 visual appearance features는 전체 input image에 추출된 features다. 이는 전체 input image를 cover하는 RoI에 Faster R-CNN을 적용함으로써 얻어진다.
visual geometry embedding은 image 내 각 input visual element의 geometry location을 VL-BERT에게 알리기 위해 디자인됐다. 각 RoI는 4-d vector 로 표현되며 와 는 top-left와 bottom-right corner의 좌표를 나타내고 W, H는 input image의 width, height다. Relation Networks (Hu et al., 2018)를 따라 4-d vector는 다양한 wavelengths의 sine과 cosine 함수를 계산함으로써 high-dimensional representation (논문에선 2048-d)에 embed된다.
visual feature embedding은 각 input elements에 부착되며 visual appearance feature와 visual geometry embedding의 concatenation을 input으로 받는 fully connected layer의 output이다.
- Segment Embedding
input elements를 서로 다른 sources로부터 구분하기 위해 3종류 segments, 즉 A, B, C가 정의된다. A와 B는 각각 첫째, 둘째 input sentence에서 온 words에 대해 C는 input image에서 온 RoI에 대해서다. input element가 어느 segment에 속하는지 표시하기 위해 모든 input element에 learned segment embedding가 더해진다.
- Sequence Position Embedding
BERT처럼 input sequence 내 순서를 표시하기 위해 모든 input element에 learnable sequence position embedding가 더해진다. input visual elements 사이 natural order가 없기 때문에 input sequence 내 어떤 순열(permutation)이라도 동일한 결과를 내야할 것이다. 따라서 모든 visual elements에 대한 sequence position embedding은 동일하다.
pre-train을 위한 visual-linguistic corpus로는 Conceptual Captions dataset을 사용하는데 문제는 captions이 주로 simple clauses라서 downstream task에 쓰기엔 너무 짧고 간단하다는 것이다. 이런 짧고 간단한 text에 overfit하는 것을 막기 위해 길고 복잡한 문장을 가진 text-only corpus에도 pre-train한다. BERT pre-train에도 활용된 BooksCorpus와 English Wikipedia dataset를 사용했다.
SGD training 시 각 mini-batch에 samples는 Conceptual Captions와 BooksCorpus & English Wikipedia에서 랜덤하게 1:1로 뽑는다. Conceptual Captions에서 뽑은 sample의 경우 input format은 <Caption, Image>이고 여기서 image 내 RoIs는 pre-trained Faster R-CNN object detector를 통해 localize되고 categorize된다. 다음과 같은 2 pre-training tasks가 이용된다.
- Task #1: Masked Language Modeling with Visual Clues
이건 BERT의 Masked Language Modeling (MLM) task와 유사하다. 핵심 차이점은 visual와 linguistic contents 사이 dependencies를 포착하기 위해 visual clues가 통합되었다는 것이다. pre-training 중 input sentence(s) 내 각 word는 15% 확률로 랜덤하게 mask된다. masked words의 token은 special token [MASK]로 대체된다. 모델은 unmasked words와 visual features에 기반해 masked words를 예측하도록 학습된다. 이 task는 네트워크가 sentence words 내 dependencies만 model할 뿐 아니라 visual & linguistic contents도 align하게 한다. masked word에 상응하는 final output feature는 전체 vocabulary에 대한 classifier에 먹여지고 Softmax cross-entropy loss를 통해 구해진다.
- Task #2: Masked RoI Classification with Linguistic Clues
이건 Task #1의 dual task다. image 내 각 RoI는 15% 확률로 랜덤하게 mask되고 모델은 다른 단서들로부터 masked RoI의 category label을 예측해야 한다. 다른 elements의 visual feature embeddings로부터 visual clue leakage를 피하기 위해 masked RoI 내 pixels은 Fast R-CNN을 적용하기 전에 0으로 세팅된다. pre-training 중 masked RoI에 상응하는 final output feature는 object category classification을 위해 Softmax cross-entropy loss를 가진 classifier에 먹여진다. pre-trained Faster R-CNN로 예측된 category label이 ground-truth로 설정된다.
BooksCorpus & English Wikipedia datasets에서 뽑은 sample의 경우 input format은 visual information 없이 <Text, ∅ >로 퇴보한다(degenerate). Fig 1의 “visual feature embedding” term은 모든 words에 공유되는 learnable embedding이다. training loss는 BERT와 같은 일반적인 Masked Language Modeling (MLM)이다.
VL-BERT를 다양한 downstream tasks에 finetune하는 것은 상대적으로 쉽다. 단순히 properly formatted input과 output을 VL-BERT에 먹이고 모든 parameters를 end-to-end로 finetune하면 된다. input의 경우 전형적인 <Caption, Image>와 <Question, Answer, Image> format이 대부분 visual-linguistic tasks를 포괄한다. 또한 VL-BERT는 서로 다른 input sources를 식별하기 위한 적절한 segment embeddings가 도입되는 한 더 많은 sentences와 더 많은 images도 지원한다. output에선 전형적으로 [CLS] element의 final output feature이 sentence-image-relation level prediction에 사용된다. words나 RoIs의 final output features는 word-level이나 RoI-level prediction을 위해 사용된다. input과 output format뿐 아니라 task-specific loss functions와 training strategies도 조정돼야 한다.
VL-BERT가 BERT에 visual input을 추가하는 식으로 개발되었기 때문에 original BERT의 parameter로 초기화를 한다. 와 는 각각 와 에서 개발됐다. VL-BERT에 새롭게 추가된 parameters는 mean 0와 std 0.02의 Gaussian distribution로 랜덤하게 초기화됐다. Visual content embedding은 Faster R-CNN + ResNet-101로 생성되며 Visual Genome (Krishna et al., 2017)에 pre-train된 parameters로 초기화된다.
Conceptual Captions에 pre-train하기 전에 pre-trained Faster R-CNN이 RoIs를 추출하도록 적용된다. 구체적으로는 0.5 초과 detection scores를 가지는 최대 100개 RoIs가 각 image에서 선택된다. detection score threshold와 상관없이 한 image에서 최소 10개 RoIs가 선택된다.
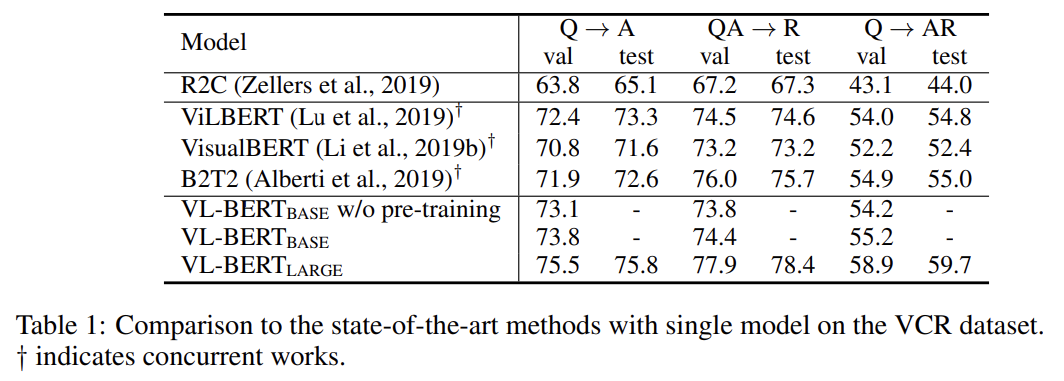
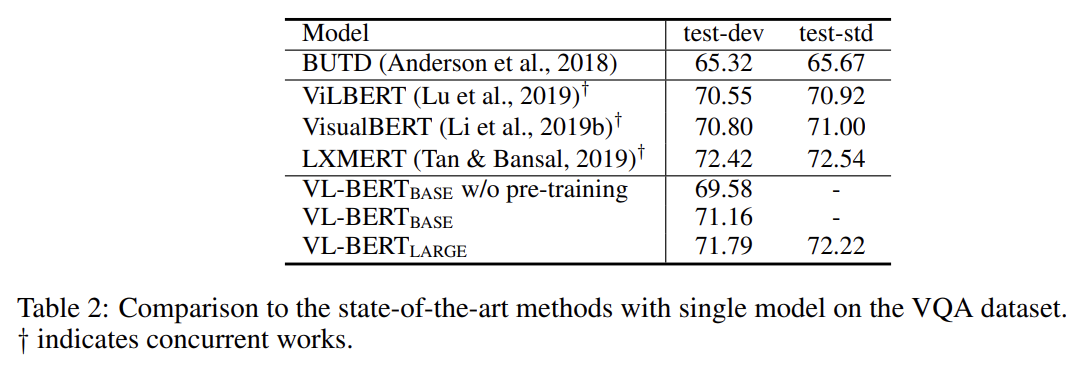
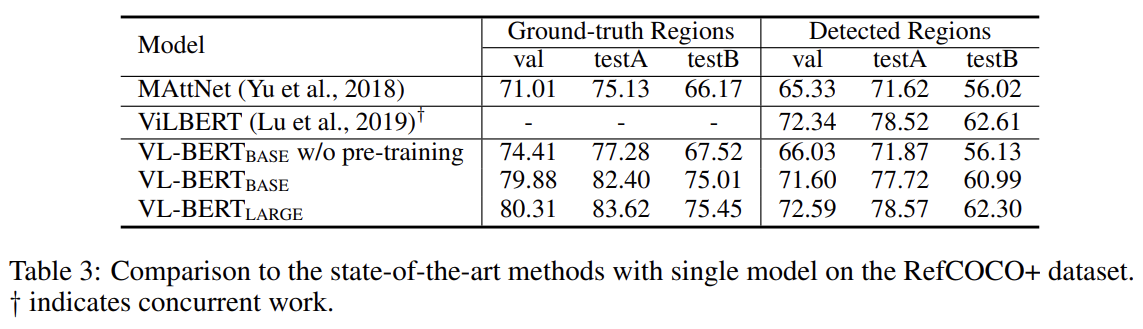
VCR, VQA, REFERRING EXPRESSION COMPREHENSION에 실험한 결과다. 설명은 생략한다.
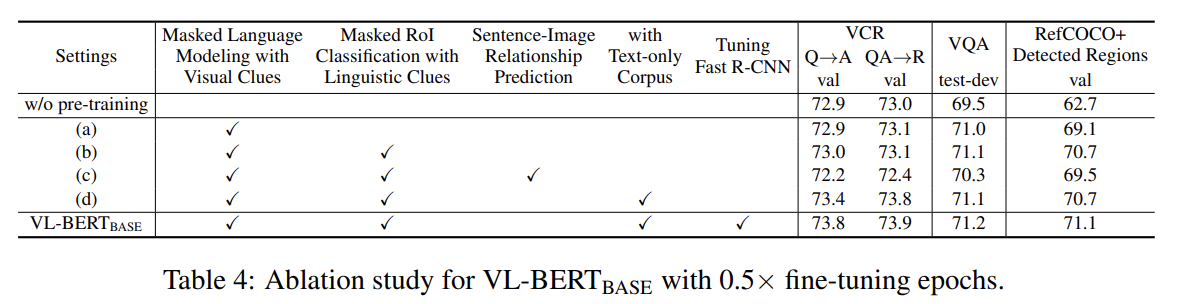
ablation study도 한다. 설명은 생략한다.
Strengths
- single-stream model인데 SOTA를 달성했다.
Weaknesses
- 모든 words에 visual embedding으로 동일하게 전체 image를 넣어줬는데 그게 좀 찝찝하다. masked RoI classification할 때 Faster R-CNN에선 visual clue leakage 방지를 위해 image에 mask해줬는데 visual embedding에 남아있으면 소용 없는 것 아닌가? 내가 잘못 이해하고 있는 건가?
VL-BERT도 다른 것들이랑 비슷비슷해서 사실 특별한 strengths는 못 찾겠다.
여기서도 LXMERT가 VQA 데이터셋에 pre-train되었다고 지적한다.
