오늘 리뷰할 논문은 Facebook의 MDETR 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
Multi-modal reasoning systems은 image에서 RoI를 추출하기 위해 pre-trained object detector에 의존한다. 그러나 이 중요한 모듈은 downstream task에 독립적으로 훈련되고 fixed vocabulary of objects에 훈련되어 black box로 사용된다. 이는 free form text에 표현된 long tail of visual concepts를 포착하기 어렵게 한다. 이 방식은 다른 modalities와의 co-training을 제한하고 downstream model이 전체 이미지가 아니라 detected objects만 접근 가능하게 제한한다. 또 detection system은 보통 얼려있어(frozen) 추가 refinement도 방지한다.
그래서 논문은 caption이나 question 같은 raw text query에 condition되어 image 내 objects를 감지하는 end-to-end modulated detector인 MDETR을 제안한다. MDETR은 image 내 concepts을 위한 supervision의 형태로 전적으로 text와 aligned boxes에 의존한다. 따라서 기존 detection methods와 달리 free-form text에서 nuanced concepts를 감지하고 Fig 1처럼 categories와 attributes의 unseen combination에도 일반화할 수 있다. text와 image를 공동으로 생각하기(reason) 위해 transformer-based architecture을 사용하고 두 modalities를 early stage에 융합한다.

디자인상 predictions은 text에 기반하며 이는 visual reasoning에 필수 조건이다. box annotations를 가진 200,000 images와 aligned text의 데이터셋에 학습했을 때 phrase grounding에 대해서는 Flickr30k dataset에, referring expression comprehension에 대해서는 RefCOCO/+/g datasets에, referring expression segmentation에 대해서는 PhraseCut에 SOTA를 달성했고 visual question answering에 대해서는 GQA와 CLEVER benchmarks에 경쟁적인 성능을 발휘했다.
논문의 기여는 다음과 같다.
- DETR detector에서 유래한 end-to-end text-modulated detection system을 소개한다.
- phrase grounding과 referring expression comprehension 같은 tasks를 해결하기 위해 modulated detection approach가 균일하게(seamlessly) 적용될 수 있음을 입증하고 syntehtic & real images를 가진 datasets을 이용해 양쪽 tasks에 SOTA를 달성한다.
- good modulated detection performance가 자연스럽게 visual question answering, referring expression segmentation, few-shot long-tailed object detection 같은 downstream task에 경쟁적인 performance로 전환됨을(translate) 보인다.
MDETR은 DETR에 기반한다. DETR은 backbone과(일반적으로 convolutional residual network) 뒤따르는 Transformer Encoder-Decoder로 구성된 end-to-end detection model이다. DETR encoder는 backbone으로부터의 2D flattened image features에 동작하고 일련의(series of) transformer layers을 적용한다. decoder는 object queries라고 불리는 set of N learned embeddings를 input으로 받고 이는 모델이 detected objects로 채워야 하는 slots으로 볼 수 있다. 모든 object queries는 decoder에 parallel하게 먹여지고 decoder는 encoded images를 보기 위해 cross-attention layers를 사용하고 각 query에 대해 output embeddings를 예측한다. 각 object query의 final representation은 shared feed-forward layer을 사용해 독립적으로 box coordinates와 class labels로 decode된다. object queries의 수는 사실상 모델이 동시에 감지할 수 있는 objects 수의 상한선이 된다. 그러니 주어진 image에서 발견할 수 있을 것으로 기대되는 충분한 큰 사물 수로 설정해야 한다. 실제 objects 수가 quries 수 N보다 작을 수 있기 때문에 "no object"에 상응하는 extra class label ∅가 사용된다. 모델은 object에 상응하지 않는 모든 query에 이 class를 output하도록 훈련된다.
DETR은 Hungarian matching loss을 사용해 학습되며 여기서 N proposed objects와 ground-truth objects 사이 bipartite matching가 계산된다. 각 matched object는 상응하는 target을 ground-truth으로 사용해 supervise되고 un-matched objects는 “no object” label ∅를 예측하도록 supervise된다. classification head는 standard cross-entropy를 사용해 supervise되고 bounding box head는 absolute error (L1 loss)와 Generalized IoU 의 조합을 사용해 supervise된다.
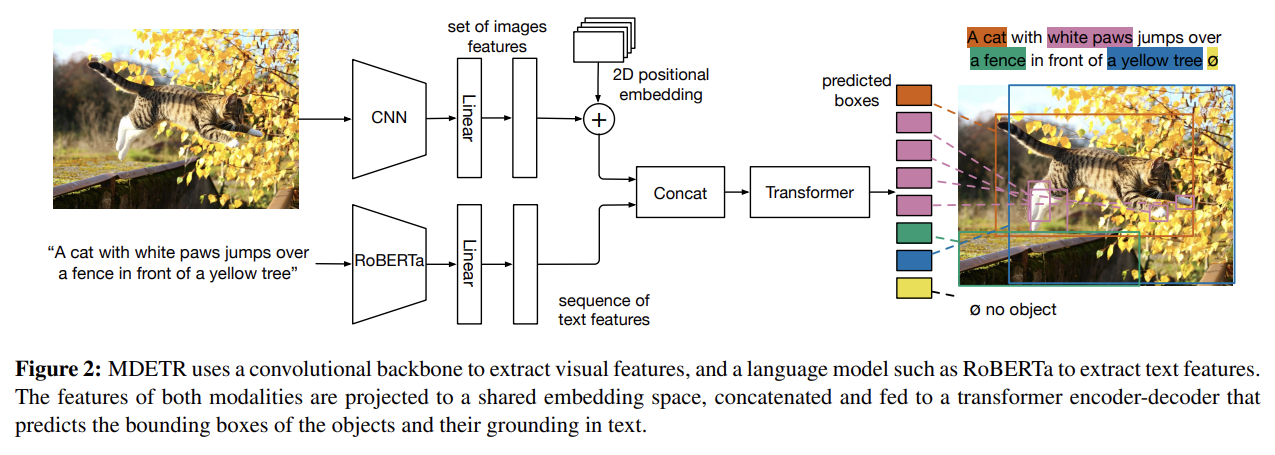
MDETR에서도 DETR처럼 image가 convolutional backbone에 의해 encode되고 flatten된다. spatial information을 보존하기 위해 2-D positional embeddings가 flattened vector에 추가된다. input과 동일한 크기의 hidden vectors의 sequence를 생성하기 위해 pre-trained transformer language model를 사용해 text를 encode한다. 그 다음 image와 text features를 shared embedding space에 project하기 위해 image와 text features 둘 다 modality dependent linear projection을 적용한다. 이 feature vectors는 image와 text features의 single sequence를 형성하기 위해 sequence dimension에 concatenate된다. 이 sequence는 cross encoder라고 이름 붙인 joint transformer encoder에 먹여진다. DETR을 따라 object queries에 transformer decoder를 적용하고 cross encoder의 final hidden state로 cross attend한다. decoder output은 actual boxes를 예측하는 데 사용된다.
image와 text 사이 alignment를 장려하는 2가지 추가적인 loss functions을 소개한다. 둘 다 동일한 annotation의 source를, 즉 free form text with aligned bounding boxes를 사용한다. 첫번째 loss인 soft token prediction loss은 non parametric alignment loss이다. 두번째는 text-query contrastive alignment라고 이름붙였으며 aligned object queries와 tokens 사이 유사도를 강요하는 parametric loss function이다.
- Soft token prediction
modulated detection에 대해, 일반적인 detection setting과 달리, MDETR은 각 detected object에 대해 categorical class를 예측하는 데 관심이 없다. 대신 original text에서 각 matched object을 참조하는(refer) span of tokens을 예측한다. 구체적으로는 먼저 주어진 아무 문장에 대한 tokens의 최대 숫자를 L=256으로 설정한다. bi-partite matching을 사용해 ground truth box에 match된 각 predicted box에 대해 모델은 objects에 상응하는 모든 token positions의 uniform distribution을 예측하도록 학습된다.

Fig 6에서 loss의 simplified visualization을 보여주는데 실제로는 BPE scheme [52]을 사용한 tokenization 이후에 token spans을 사용한다. target에 match되지 않는 query는 “no object” label ∅를 예측하도록 학습된다. text 내 여러 words가 image 내 동일한 object에 상응할 수 있고 역으로 여러 objects가 동일한 text에 상응할 수 있음에 주의하라. 이 loss function 디자인으로 모델은 same referring expression에서 co-referenced objects을 배울 수 있다.
- Contrastive alignment
soft token prediction이 objects를 text에 align하기 위해 positional information을 사용하는 반면 contrastive alignment loss는 decoder output의, object의 embedded representations와 cross encoder output의 text representation 사이 alignment를 강요한다. 추가적인 contrastive alignment loss은 (visual) object의 embeddings와 상응하는 (text) token이 feature space에서 unrelated tokens의 embeddings보다 가깝도록 보장한다. 이 제약은 soft token prediction loss보다 강력한데 representations에 직접 작동하고 positional information에 전적으로 기반하지 않기 때문이다. 구체적으로 tokens의 최대 숫자를 L로, objects의 최대 숫자를 N으로 두자. 가 주어진 object 가 align되어야 할 tokens의 집합이라고 두고 가 주어진 token 가 align되어야 할 objects의 집합이라고 두자. InfoNCE [40]에서 영감을 받아 모든 objects에 대한 contrastive loss는 다음과 같이 각 object에 대한 positive tokens의 숫자로 normalize된다.
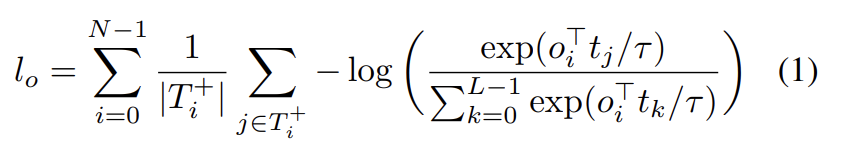
τ는 temperature parameter이며 기존 연구를 따라 0.07로 설정했다. 대칭적으로 각 token에 대한 positive objects의 숫자로 normalize한, 모든 tokens에 대한 contrastive loss는 다음과 같다.
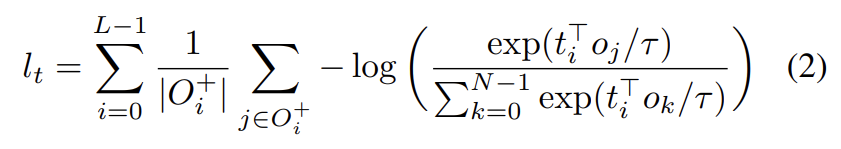
두 loss functions를 평균 내서 contrastive alignment loss로 삼는다.
- Combining all the losses
MDETR에선 DETR처럼 predictions와 ground-truth targets 사이 best match를 찾기 위해 bipartite matching이 사용된다. 주요 차이점은 각 object에 대해 예측된 class label이 없다는 것이고, 대신 text 내에서 이 object에 상응하는 relevant positions의 uniform distribution을 예측하도록 soft cross entropy로 supervise한다는 것이다(soft token predictions). matching cost는 이것과 추가로 DETR처럼 prediction과 target box 사이 L1 & GIoU loss로 구성된다. matching 후에 total loss는 box prediction losses (L1 & GIoU), soft-token prediction loss, contrastive alignment loss로 구성된다.
pre-training의 경우 modulated detection의 task에 집중하며 여기서 목표는 aligned free form text 내에 언급된 모든 objects를 감지하는 것이다. Flickr30k [46], MS COCO [30], Visual Genome (VG) [24] datasets로부터의 images를 사용해 combined dataset을 만든다. referring expressions datasets, VG regions, Flickr entities, GQA train balanced set로부터의 annotations가 학습에 사용된다. image 하나는 여러 연관된 text annotations을 가질 수 있다.

(Data combination 설명 생략)
text encoder로는 pre-trained RoBERTa-base를 사용하며 12 transformer encoder layers가 768 hidden dimension과 multihead attention에 12 heads를 가진다. HuggingFace [61]에서의 implementation과 weights을 사용한다. visual backbone의 경우 2가지 옵션을 탐구한다. 첫째는 (Torchvision에서 가져온) ImageNet에 pretrain됐고 frozen batchnorm layers를 가진 ResNet-101이다. 이는 (VG dataset에 학습한 Resnet-101 backbone을 가지는 BUTD object detector 사용이 유행인) 현재(당시) 문헌들과 비교하기 위함이다. 본 논문에서는 pre-trained detectors의 존재에 국한되지 않고 backbone으로 EfficientNet family도 탐구한다. ImageNet에 추가로 Noisy-Student라는 pseudo-labelling technique을 사용해 대량의 unlabelled data에 학습한 모델을 사용한다. EfficientNetB3와 EfficientB5를 선택하고 Timm library가 제공한 implementation을 사용하고 batchnorm layers을 얼린다.
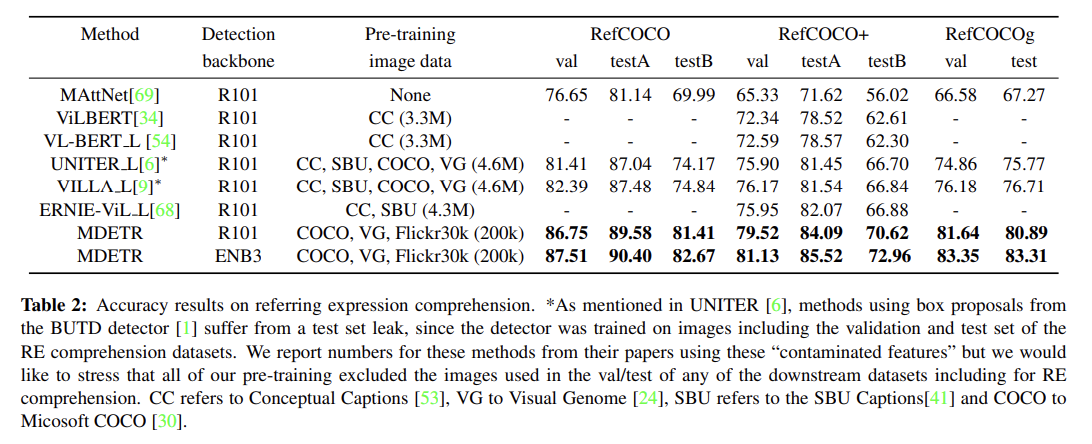
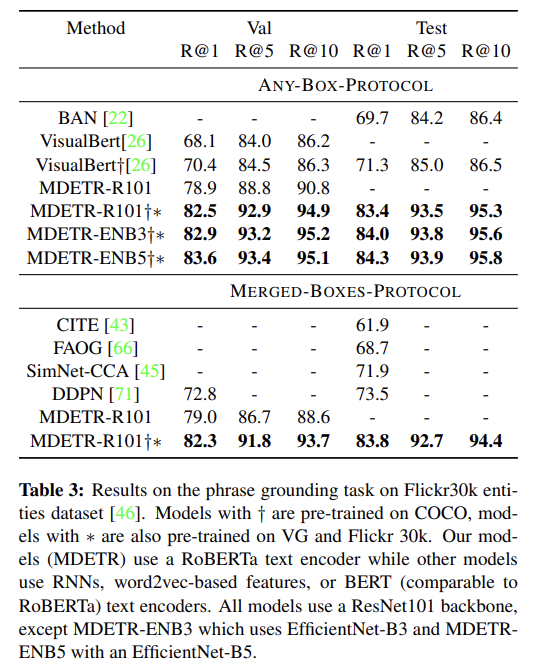
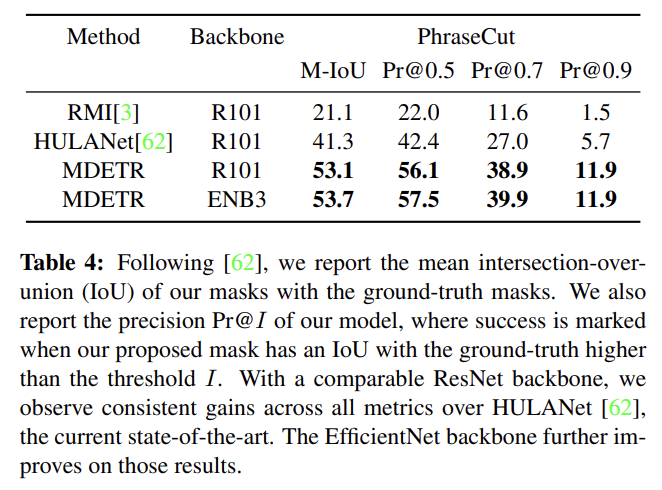
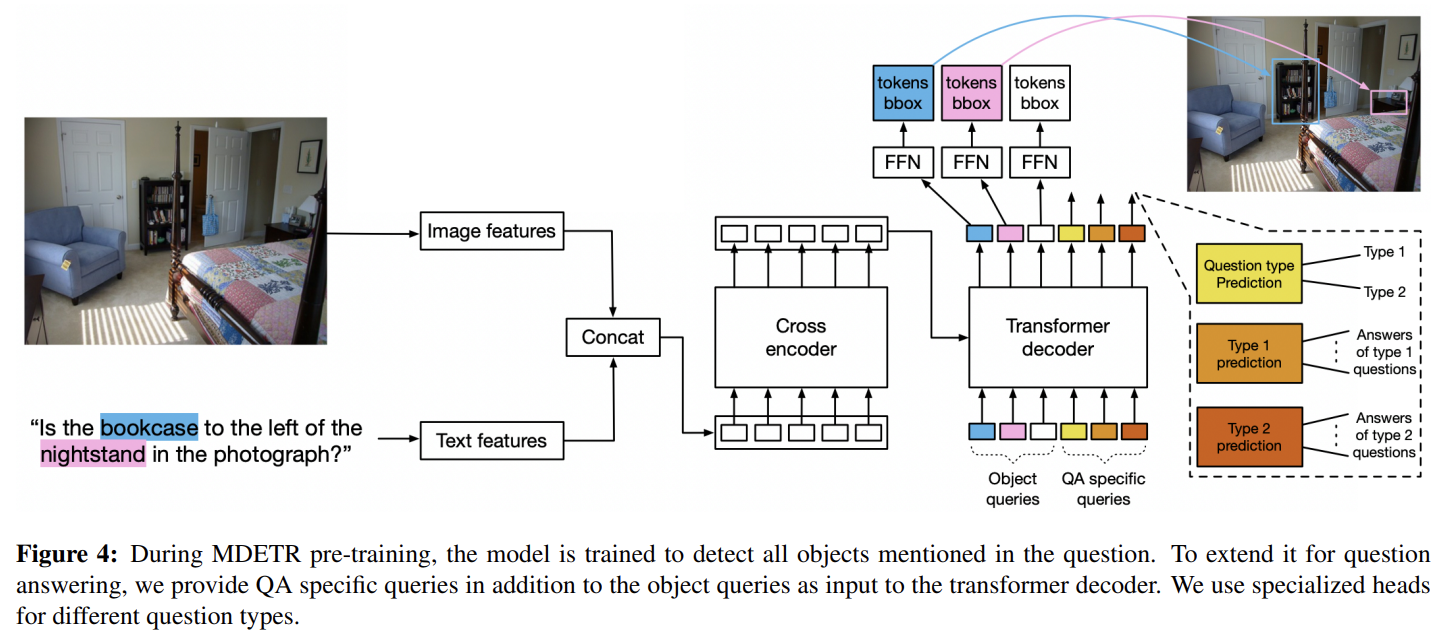
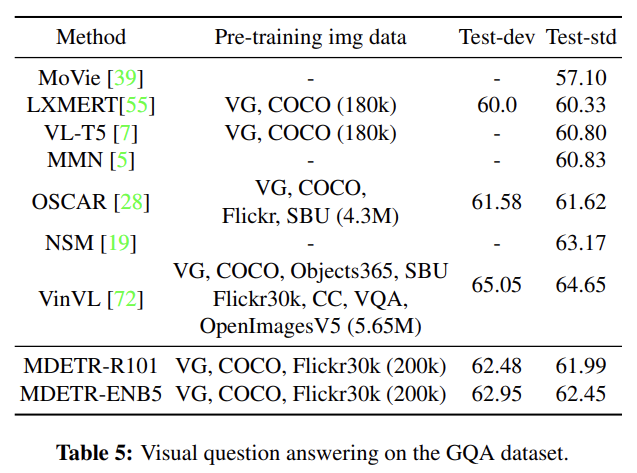

4 downstream tasks, 즉 referring expression comprehension and segmentation, visual question answering, phrase grounding에 평가한다. 설명은 생략한다.
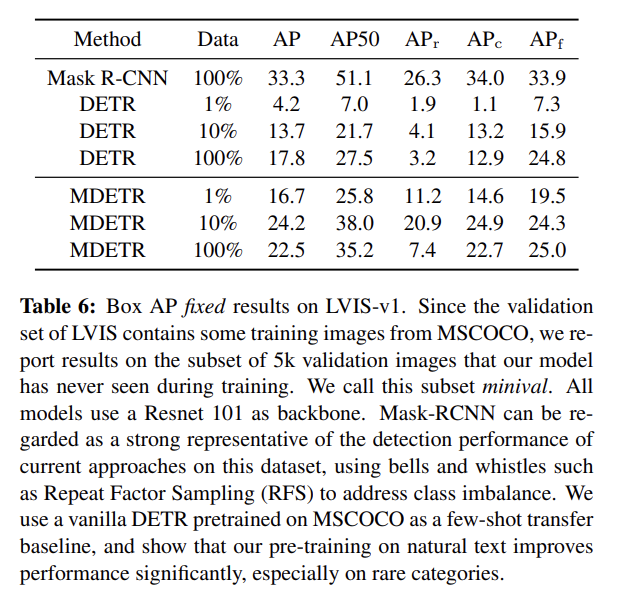
(Few-shot transfer for long-tailed detection 설명 생략)
DETR 논문을 먼저 볼 걸 그랬다.
