
JoyMall 프로젝트를 진행하던 중 상품 조회 쿼리에 대한 성능 개선을 경험해보았습니다.
기존 코드
@Table("PRODUCT")
@Getter
@NoArgsConstructor
@ToString
public class Product {
private static final int INITIAL_REVIEW = 0;
@Id
@Column("PRODUCT_ID")
private Long id;
@Column("SELLER_ID")
private Long sellerId;
private String name;
private String description;
private String imageUrl;
private LocalDateTime createdDate;
private LocalDateTime updatedDate;
@MappedCollection(idColumn = "PRODUCT_ID")
private Set<ProductCategory> productCategories = new HashSet<>();
@MappedCollection(idColumn = "PRODUCT_ID")
private Set<ProductOption> productOptions = new HashSet<>();
@Column("PRODUCT_ID")
private ProductReviewSummary productReviewSummary;
public Product(Long sellerId, String name, String description, String imageUrl) {
this(sellerId, name, description, imageUrl, LocalDateTime.now(), LocalDateTime.now());
}
@Builder
public Product(Long sellerId, String name, String description, String imageUrl, LocalDateTime createdDate, LocalDateTime updatedDate) {
this.sellerId = sellerId;
this.name = name;
this.description = description;
this.imageUrl = imageUrl;
this.createdDate = createdDate;
this.updatedDate = updatedDate;
this.productReviewSummary = new ProductReviewSummary(INITIAL_REVIEW, INITIAL_REVIEW);
}
public void addCategory(Category category) {
productCategories.add(createProductCategory(category));
}
public ProductCategory createProductCategory(Category category) {
return new ProductCategory(id, category.getId());
}
public void addProductOption(ProductOption productOption) {
productOptions.add(productOption);
}
}위와 같이 구성된 엔티티에서 200만건의 Product가 존재할 때 상품명을 통해 조회해오는 것을 목표로 했습니다.
@Service
@RequiredArgsConstructor
public class ProductService {
private final ProductRepository productRepository;
public ProductPageResponse search(String keyword, Pageable pageable) {
Page<Product> products = productRepository.findByNameContainingIgnoreCase(keyword, pageable);
return ProductPageResponse.from(products);
}
}public interface ProductRepository extends CrudRepository<Product, Long> {
Page<Product> findByNameContainingIgnoreCase(String keyword, Pageable pageable);
}또한 Spring Data JDBC의 queryMethod를 이용하여 findByNameContainingIgnoreCase를 사용하였습니다.

Spring Data JDBC 공식문서에서 볼 수 있듯이 Like '%' + name + '%' 쿼리가 발생하게 됩니다.
문제점
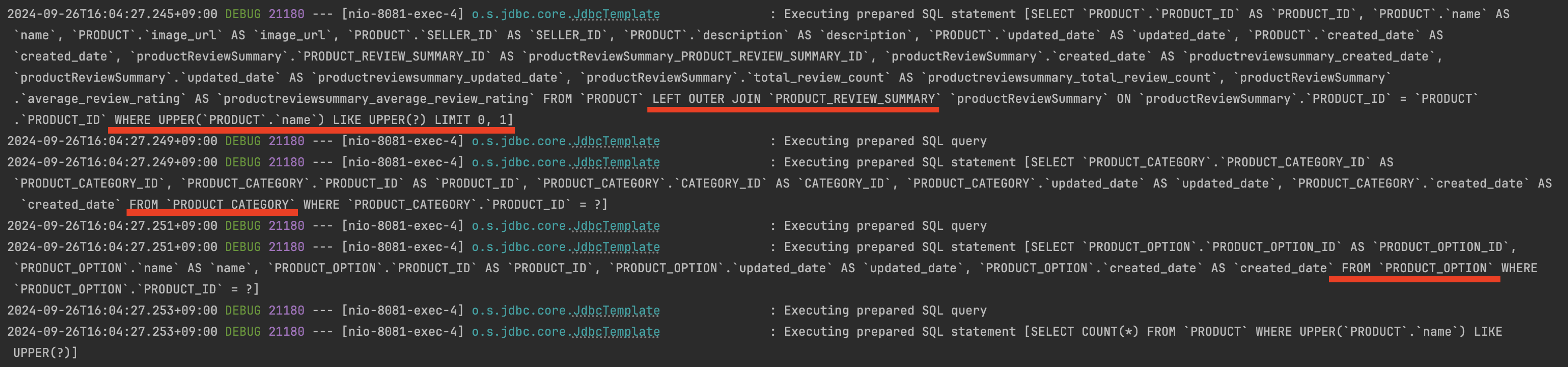
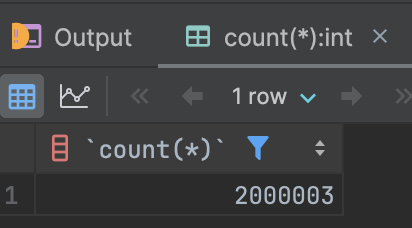
조회를 하게 되면 문제점 발생했습니다.
- Product 엔티티와 연관된 엔티티들을 조회해온다. (N+1 문제 발생)
- 현재 쿼리의 경우 'name' 컬럼에 인덱스를 설정하게 되면 이점을 얻을 수 없다.
'LIKE '%name%' 가 인덱스의 이점을 얻을 수 없는 이유
- MySQL의 인덱스는 B+Tree로 이루어져있습니다. 모든 데이터를 리프 노드에 저장하여 범위 검색에 효율적입니다.
- B+Tree는 키의 정렬된 순서를 이용해 빠르게 검색합니다. 'LIKE '%name%'의 경우 시작점을 특정할 수 없어, 이 정렬 순서를 이용할 수 없습니다. (ex: '%a%' 는 banana, apple 모두 포함됩니다.)
- Upper(), Lower()는 컬럼의 형 변환을 하기 때문에 기존 컬럼 값에 대한 인덱스를 생성하게 된다면 이점을 얻을 수 없습니다.
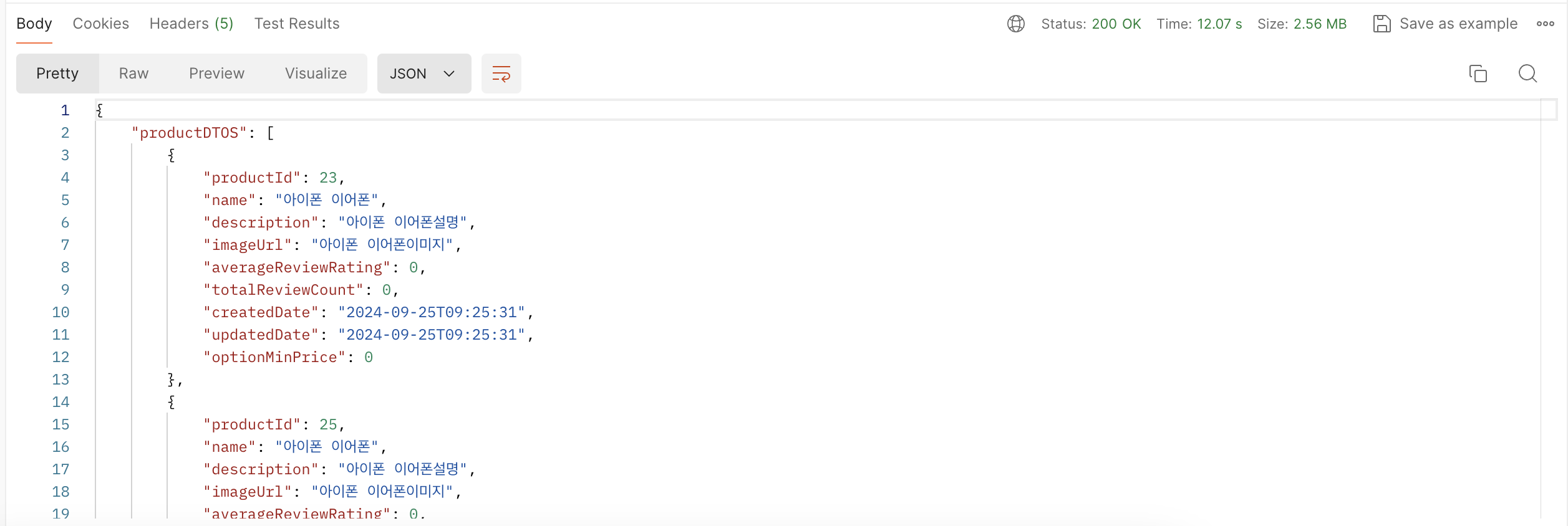
따라서 '아이폰 이어폰'이라는 상품명을 10,000개의 데이터를 조회해오게 되면 12초라는 너무 긴 레이턴시가 발생하게 됩니다. 따라서 우선 이 쿼리를 수정해보겠습니다.
쿼리 개선1 - N+1 해결, 전위 검색
Spring Data JDBC는 JPA처럼 fetch join을 지원하지 않기 때문에 엔티티의 연관관계를 직접적으로 해제를 시켜줘야합니다. 하지만 그렇게 되면 영향 가는 코드가 많기 때문에 Repository 단에서 엔티티로 return 받지 않고 DTO로 return 받을 수 있도록 수정하였습니다.
public ProductPageResponse search(String keyword, Pageable pageable) {
List<ProductDTO> productDTOS = productRepository.findProductsByNameStartsWith(keyword, pageable.getPageSize(), pageable.getOffset());
long total = productRepository.countProductsByNameRange(keyword);
Page<ProductDTO> productPages = new PageImpl<>(productDTOs, pageable, total);
return ProductPageResponse.from(productPages);
} @Query("SELECT * FROM PRODUCT WHERE name LIKE CONCAT(:keyword, '%') LIMIT :limit OFFSET :offset")
List<ProductDTO> findProductsByNameStartsWith(@Param("keyword") String keyword,
@Param("limit") int limit,
@Param("offset") long offset);
@Query("SELECT COUNT(*) FROM PRODUCT WHERE name LIKE CONCAT(:keyword, '%')")
long countProductsByNameRange(@Param("keyword") String keyword);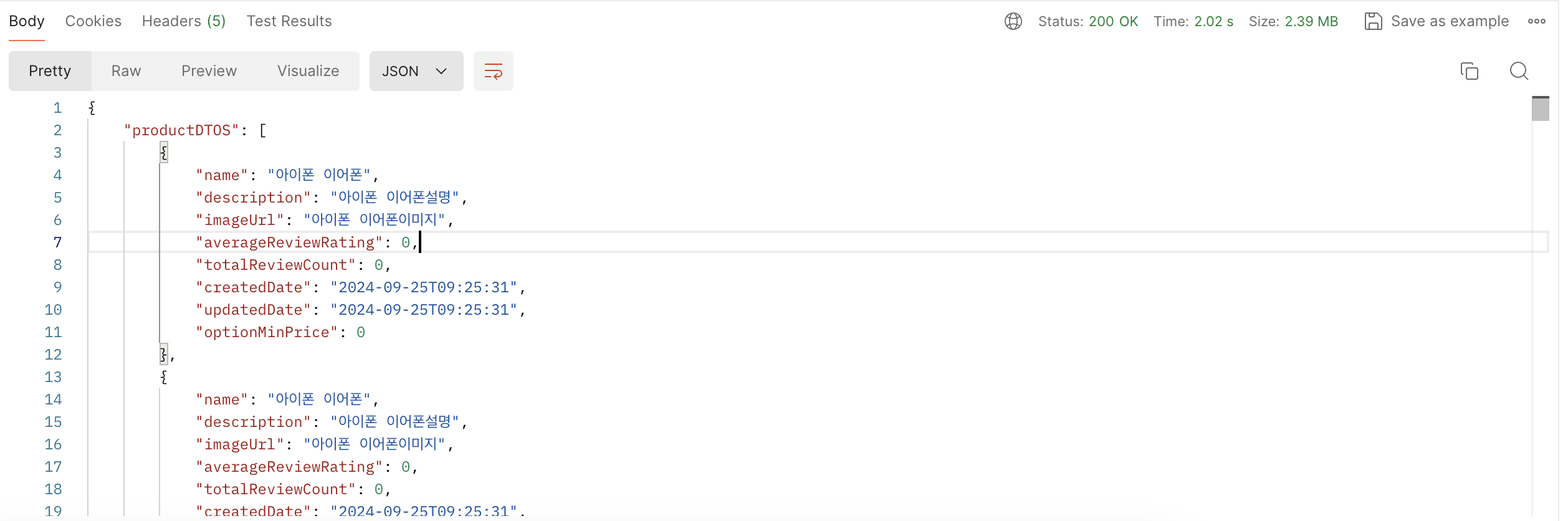
수정한 쿼리의 결과 12초 -> 2초 6배 성능 개선이 되었습니다. 이제 여기에서 인덱스까지 설정 후 성능을 보겠습니다.
쿼리 개선2 - 인덱스 설정
우선 인덱스 설정 전 실행 계획을 살펴보겠습니다.
EXPLAIN SELECT * FROM PRODUCT WHERE name LIKE '아이폰 충전기%' LIMIT 100000 OFFSET 0;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | PRODUCT | null | ALL | null | null | null | null | 1981728 | 11.11 | Using where |
실행 계획을 살펴보면
- type: ALL ➡ 전체 테이블 스캔
- possible_keys: null ➡ 사용 가능한 인덱스가 없음
- rows: 1,981,728 ➡ 약 198만개의 행을 검사해야한다고 예측
- filtered: 11.11 ➡ 검사한 행 중 11.11% 만이 조건을 만족할 것으로 예상합니다.
- Extra: Using where ➡ WHERE 조건을 사용해 행을 필터링합니다.
create index idx_product_name on product(name);| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | PRODUCT | null | range | idx_product_name | idx_product_name | 1022 | null | 500270 | 100 | Using index condition; Using MRR |
실행 계획을 살펴보면
- type: range ➡ 인덱스를 사용한 범위 검색을 수행합니다.
- possible_keys: idx_product_name ➡ 'name' 컬럼에 생성한 인덱스를 사용합니다.
- rows: 500270 ➡ 약 50만개의 행을 검사한다고 예측
- filtered: 100 ➡ 검사한 모든 행이 조건을 만족합니다.
- Extra: Using index condition; Using MRR ➡ 인덱스를 사용해 조건을 평가, MRR(Multi-Range-Read) 최적화를 사용해 디스크 읽기를 최소화한다.
결론적으로 인덱스 설정을 통해 성능에 대한 이점을 기대할 수 있습니다. 실제 실행한 레이턴시의 결과는 어떻게 되었을까요?
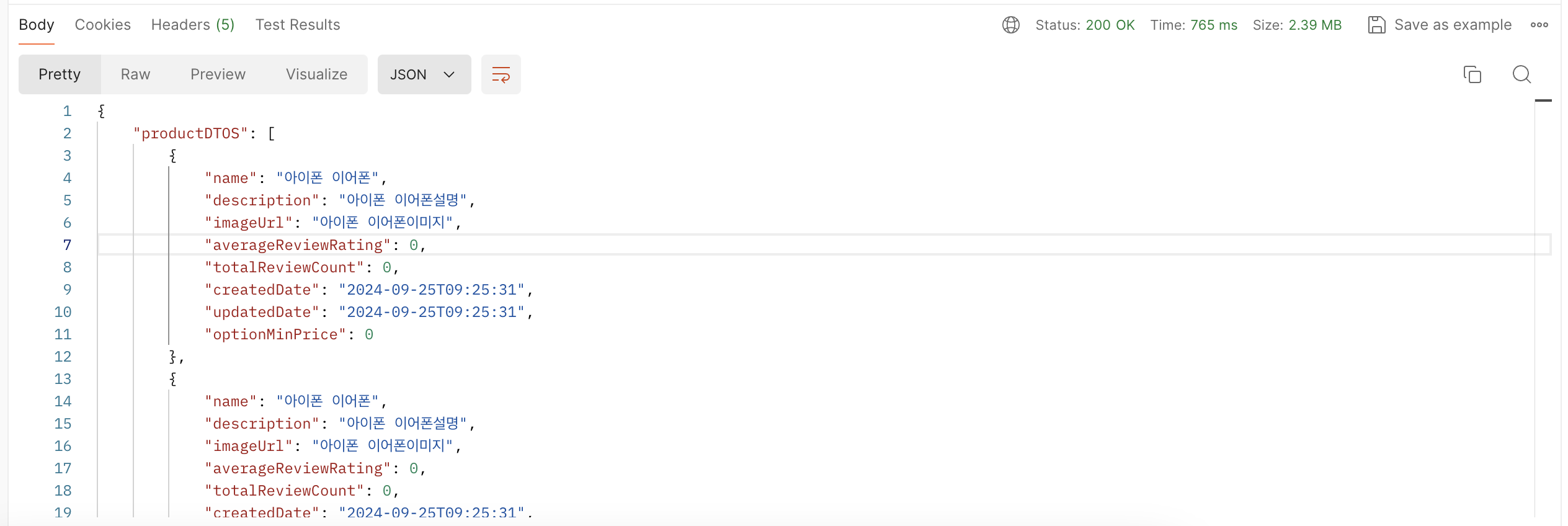
2초 -> 0.7초로 성능 향상이 된걸 확인할 수 있었습니다.
마치며
성능 개선을 통해 이것 저것 알 수 있었습니다.
사실 FULLTEXT INDEX와 Like '%' + name + '%' 등도 실험해가보면서 여러가지를 해보았지만, 글에 담을 만한 정도가 안되는거 같아 적진 않았습니다.
어쨋든 쿼리 튜닝의 기초는 최대한 Table Full Scan을 지양하고, 조건문에 대한 인덱스를 적절히 설정해주는 것만으로도 큰 성능 향상을 얻을 수 있습니다. 또한 인덱스의 동작 원리가 필수적일거 같습니다.
