
JoyMall 프로젝트를 진행하던 중 상품 조회 쿼리에 대한 성능 개선 2번째입니다.
이번에 적용해볼 방법은 No Offset 방식과 커버링 인덱스입니다.
기존의 페이징 쿼리
일반적으로 페이징은 웹 페이지에서 기본적으로 제공하는 기능입니다.
기존에 적용되었던 코드를 살펴보겠습니다.
SELECT * FROM PRODUCT
WHERE 조건문
ORDER BY PRODUCT_ID DESC
OFFSET 페이지 번호
LIMIT 페이지 사이즈
;이와 같은 페이징 쿼리의 가장 큰 문제점은 다음과 같습니다.
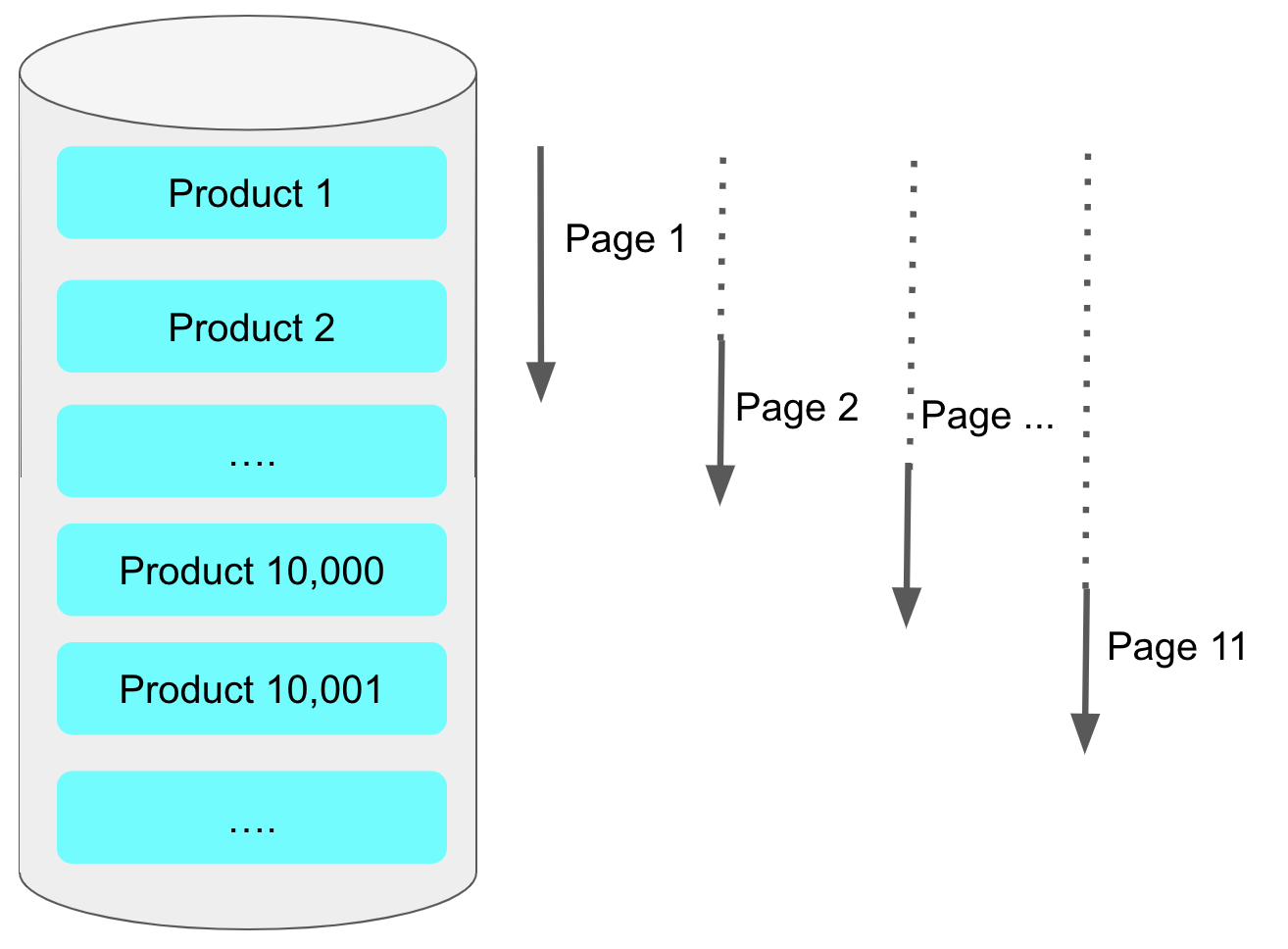
OFFSET 번호가 뒤로 갈수록 느려진다는 점인데, 그 이유는 일반적인 OFFSET 방식은 OFFSET + LIMIT 만큼의 행을 모두 읽어야 합니다.
예를 들어 OFFSET이 10,000 이고 LIMIT가 10일 때, 100,10의 행을 읽고 앞의 10,000개의 행을 버립니다.
그렇다면 NO OFFSET 방식은 어떤 것이 다를까요?
NO OFFSET 방식
기존의 페이징 방식이 아래와 같이 페이지 번호(OFFSET)과 페이지 크기(LIMIT)를 기반이라면,

NO OFFSET은 아래와 같이 페이지 번호(OFFSET)이 없는 더보기 방식을 사용합니다.

NO OFFSET 방식의 쿼리를 살펴보겠습니다.
SELECT
*
FROM PRODUCT
WHERE 조건문
AND PRODUCT_ID < 100000 # 직전 조회 결과의 마지막 ID
ORDER BY PRODUCT_ID DESC
LIMIT 페이지 사이즈;위 쿼리에서 페이지 번호(OFFSET)이 없고, 직전 조회의 마지막 ID를 통해 PRODUCT_ID를 가져오는 조건문이 추가되었습니다. 이 방식이 왜 빠를까요?
불필요한 데이터 스캔 방지
NO OFFSET 방식은 필요한 데이터만 직접 접근하여 읽습니다. 즉 기존의 페이징 쿼리와 같이 100,10개의 행을 읽고 10,000개의 행을 버릴 필요가 없는거죠.
인덱스 효율성 증가
MYSQL에서는 clustered index(주로 PRIMARY KEY)는 데이터의 물리적 순서를 결정합니다. NO OFFSET 방식은 이 인덱스를 활용하여 특정 ID 이후의 데이터에 빠르게 접근합니다.
WHERE PRODUCT_ID < 100000의 조건문이 인덱스를 활용한 범위 스캔을 효과적으로 수행해줍니다.
그래서 NO OFFSET 방식을 사용하면 인덱스를 통해 필요한 범위의 데이터만 처리하므로 쿼리 실행 계획이 단순해지고, 메모리 사용이 효율적입니다.
아래 코드는 실제 적용된 코드입니다.
ProductService
public ProductPageResponse search(String keyword, Long lastProductId, int pageSize) {
List<ProductDTO> productDTOS = productRepository.findProductsByNameStartsWith(keyword, lastProductId, pageSize);
long total = productRepository.countProductsByNameRange(keyword);
boolean hasNext = productDTOS.size() == pageSize;
Long nextLastProductId = productDTOS.get(productDTOS.size() - 1).getProductId();
return new ProductPageResponse(productDTOS, total, hasNext, nextLastProductId);
}ProductRepository
@Query("SELECT * FROM PRODUCT WHERE name LIKE CONCAT(:keyword, '%') AND product_id < :lastProductId ORDER BY product_id DESC LIMIT :limit")
List<ProductDTO> findProductsByNameStartsWith(@Param("keyword") String keyword,
@Param("lastProductId") Long lastProductId,
@Param("limit") int limit);
200만건의 상품 데이터를 10,000개의 데이터를 조회했습니다.
적용한 코드의 레이턴시를 살펴보게 되면 기존 0.765초 -> 0.641초로 성능 개선된 것을 확인할 수 있습니다.
쿼리 실행 계획도 살펴보겠습니다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | PRODUCT | null | range | PRIMARY,idx_product_name | PRIMARY | 8 | null | 217748 | 25.24 | Using where; Backward index scan |
- possible_keys: PRIMARY,idx_product_name ➡ MYSQL이 사용을 고려한 인덱스입니다. PRIMARY KEY와 name에 적용된 인덱스들을 고려했습니다.
- key: PRIMARY ➡ 실제로 사용된 인덱스입니다. PRIMARY KEY를 사용하였고 NO OFFSET 방식이 잘 적용된 것을 확인할 수 있습니다.
- Extra: Using where; Backward index scan ➡ WHERE 조건문을 통해 행을 추가로 필터링하였고, 인덱스를 역순으로 스캔하였습니다. (ORDER BY PRODUCT_ID DESC 때문)
이 쿼리는 대량의 데이터에서도 효율적으로 동작할 것으로 보입니다. PRIMARY KEY를 이용한 범위 검색과 역순 인덱스 스캔을 통해 필요한 데이터에 빠르게 접근하고 있습니다.
커버링 인덱스 방식
NO OFFSET을 사용하게 되면 여러 제약사항들이 발생합니다. (UI 구조상 페이징이 필요한 경우, 총 페이지 번호를 알아야 하는 경우 등)
이런 상황이라면 커버링 인덱스를 사용하여 성능을 개선할 수 있습니다.
커버링 인덱스란, 쿼리의 모든 열을 포함하는 인덱스를 말합니다. 즉, SELECT, WHERE, ORDER BY, GROUP BY 등에서 사용되는 모든 열이 인덱스에 포함되어 있는 경우를 말합니다.
쿼리를 먼저 살펴보겠습니다.
SELECT * FROM PRODUCT P
JOIN
(
SELECT PRODUCT_ID FROM PRODUCT
WHERE 조건문
ORDER BY PRODUCT_ID DESC
OFFSET 페이지 번호
LIMIT 페이지 사이즈
) P2
ON P.PRODUCT_ID = P2.PRODUCT_ID;위 쿼리의 JOIN 되고 있는 쿼리를 살펴보면 조회 결과 PRODUCT_ID의 행들을 가져오게 됩니다. 일반적으로 DB는 인덱스를 통해 레코드를 찾은 후, 실제 데이터가 있는 데이터 페이지에 접근합니다.
커버링 인덱스 적용 전
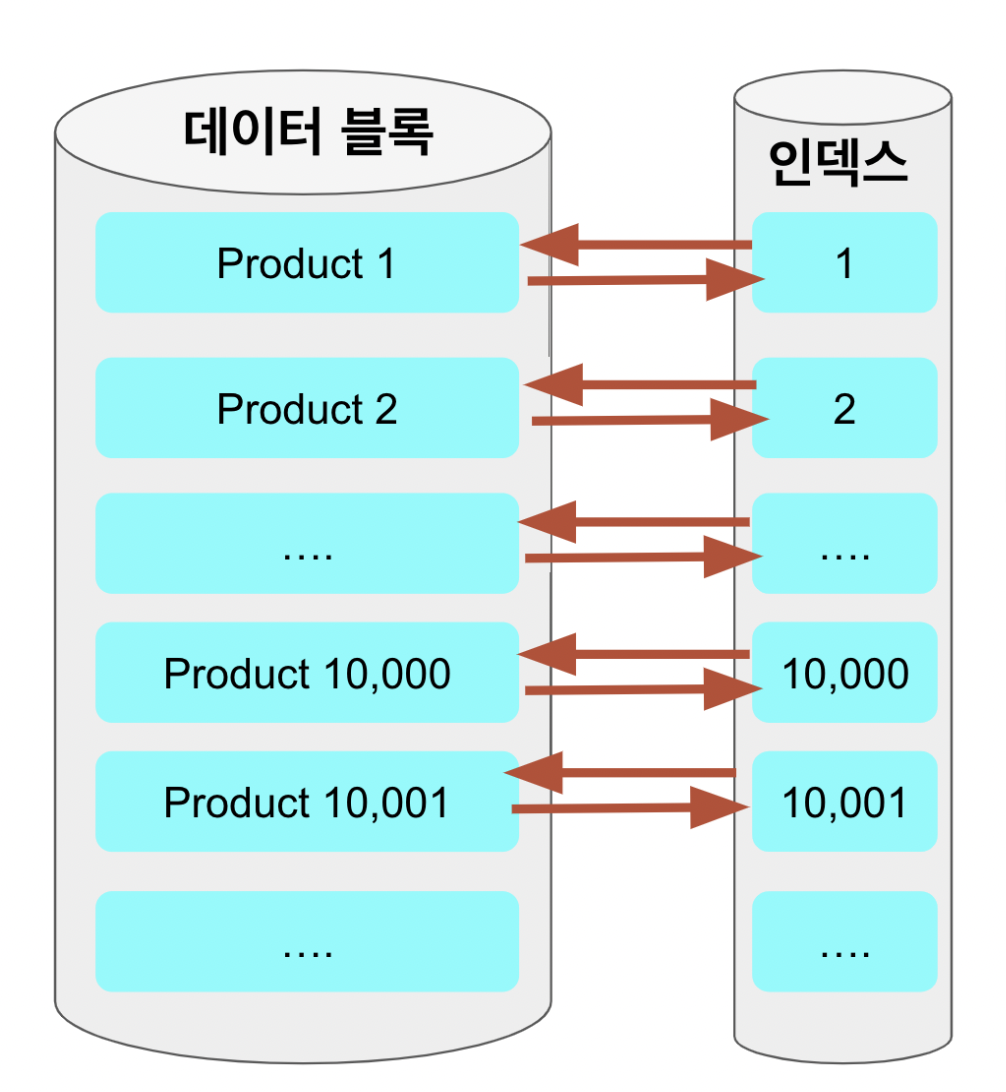
즉, 커버링 인덱스를 사용하게 되면 데이터 페이지 접근 없이 인덱스만으로 쿼리를 해결할 수 있습니다. 이는 디스크 I/O를 줄여 성능을 향상 시킵니다. 쉽게 말해 필터링 된 레코드들에 대해서만 데이터 페이지에 접근하기 때문에 성능상의 이점을 얻게 됩니다.
커버링 인덱스 적용 후
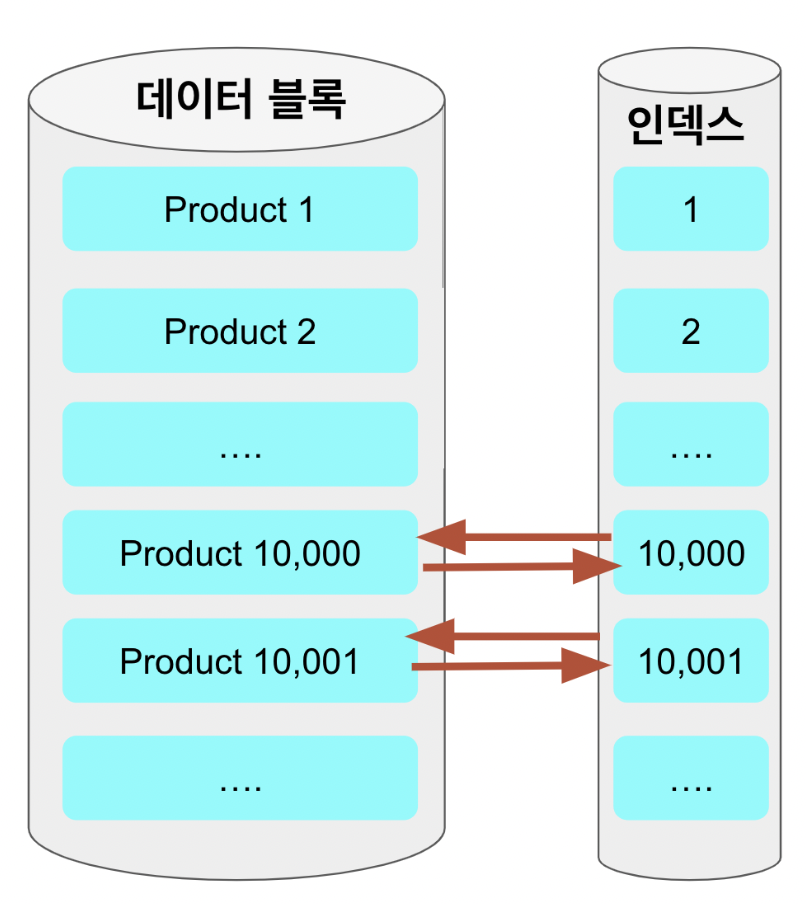
따라서 페이지 작업까지는 커버링 인덱스로 빠르게 id를 조회해 오고, 마지막에 데이터가 필요한 레코드에 대한 처리를 해주는 것입니다.
적용된 코드를 살펴보겠습니다.
ProductService
public ProductPageResponse search(String keyword, Pageable pageable) {
List<ProductDTO> productDTOS = productRepository.findProductsByNameStartsWith(keyword, pageable.getPageSize(), pageable.getOffset());
long total = productRepository.countProductsByNameRange(keyword);
Page<ProductDTO> productPages = new PageImpl<>(productDTOS, pageable, total);
return ProductPageResponse.from(productPages);
}ProductRepository
@Query("SELECT P.* FROM PRODUCT P " +
"JOIN (" +
" SELECT PRODUCT_ID FROM PRODUCT " +
" WHERE NAME LIKE CONCAT(:keyword, '%') " +
" ORDER BY PRODUCT_ID DESC " +
" LIMIT :limit OFFSET :offset" +
") P2 ON P.PRODUCT_ID = P2.PRODUCT_ID")
List<ProductDTO> findProductsByNameStartsWith(@Param("keyword") String keyword,
@Param("limit") int limit,
@Param("offset") long offset);아래는 코드를 적용한 레이턴시 결과입니다.
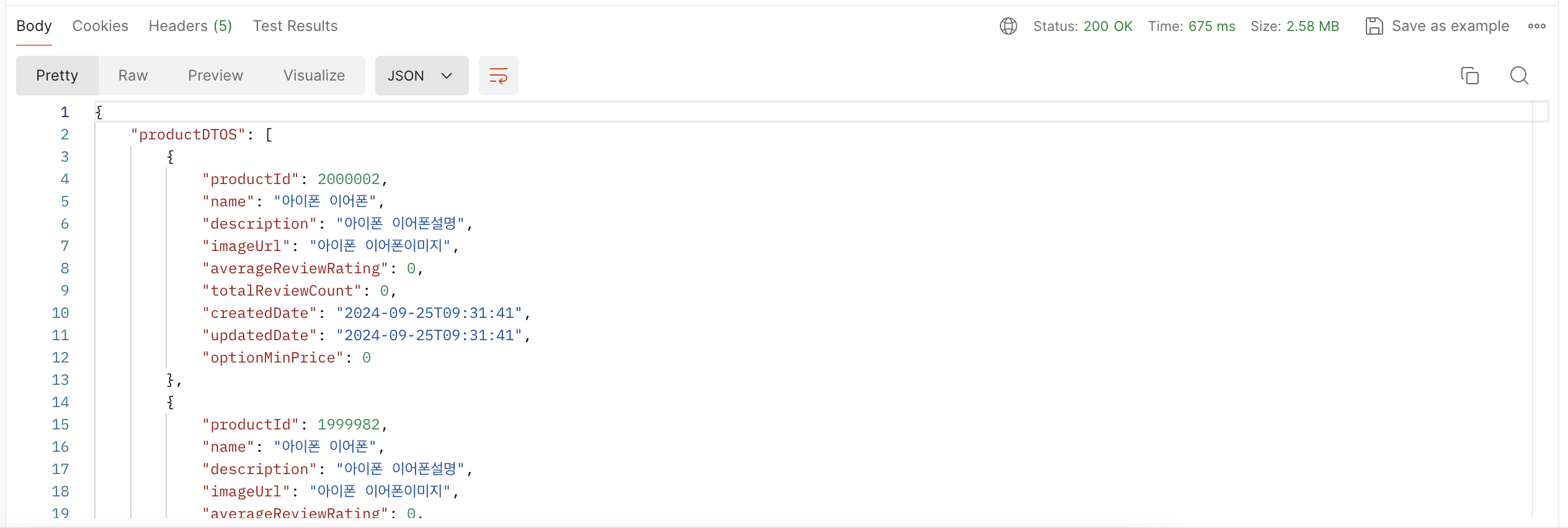
적용한 코드의 레이턴시를 살펴보게 되면 기존 0.765초 -> 0.675초로 성능 개선된 것을 확인할 수 있습니다.
아래는 쿼리 실행 계획 결과입니다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | <derived2> | null | ALL | null | null | null | null | 100000 | 100 | null |
| 1 | PRIMARY | P | null | eq_ref | PRIMARY | PRIMARY | 8 | P2.PRODUCT_ID | 1 | 100 | null |
| 2 | DERIVED | PRODUCT | null | range | idx_product_name | idx_product_name | 1022 | null | 500270 | 100 | Using where; Using index; Using filesort |
- possible_keys: idx_product_name ➡ MySQL이 사용을 고려한 인덱스입니다. name 컬럼에 적용된 인덱스를 고려했습니다.
- key: idx_product_name ➡ 실제로 사용된 인덱스입니다. name 컬럼의 인덱스를 사용하여 커버링 인덱스 방식이 잘 적용된 것을 확인할 수 있습니다.
- Extra: Using where; Using index; Using filesort ➡ WHERE 조건문을 통해 행을 필터링하였고, 인덱스만으로 쿼리를 해결하였습니다(커버링 인덱스). 추가적인 정렬 작업이 필요함을 나타냅니다.
마치며
이번 성능 개선 과정을 통해 페이징을 적용할 때의 DB 레벨에서 어떻게 해결할 수 있는지 알게 되었습니다.
NO OFFSET은 불필요한 레코드들의 조회 없이 필요한 레코드들만 조회할 수 있지만, 페이지 번호에 대한 처리를 못한다는 점
커버링 인덱스는 JOIN 쿼리에 인덱스가 적용된 레코들을 조회온 후, 데이터 페이지를 접근하여 I/O에 대한 효율적인 사용을 이룰 수 있다는 점
등을 알 수 있었습니다. 다음 시간에는 캐시을 도입하여 성능 개선을 해 볼 생각입니다.
