결정 트리란?
목차
트리 구조를 기반으로 의사결정 규칙을 만들어 데이터를 분석하는 모델
예/아니오 이렇게 확실한 답(and 한 번에 하나의 속성을 선택)이 나오는 질문들을 하고, 이 질문들에 답해나가면서 분류
이 때, 좋은 질문을 던져야 한다! 명확하게 질문하고 명확하게 답을 얻어야 불순도를 낮출 수 있다!
참고 :
-
명확하게 답을 얻는다란? 질문에 의해 나눠지는 답변의 카테고리가 확실한 것. 이것이 “정보획득”이고, “정보획득”의 계산 방법은 지니 계수와 엔트로피가 있다.
-
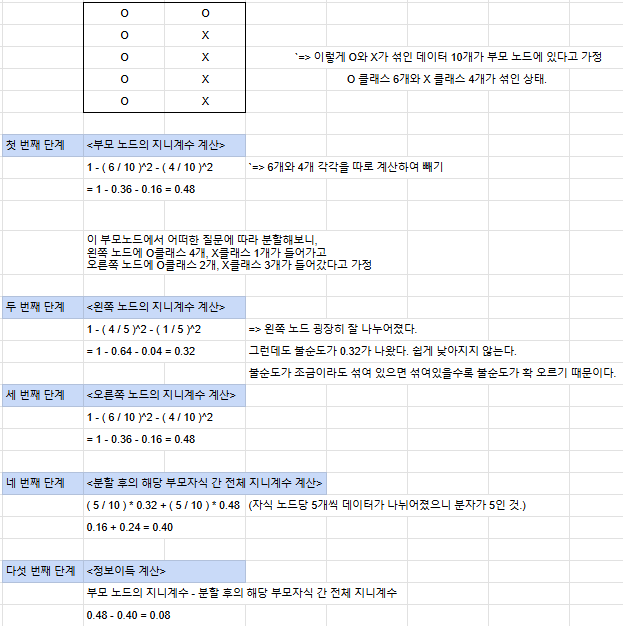
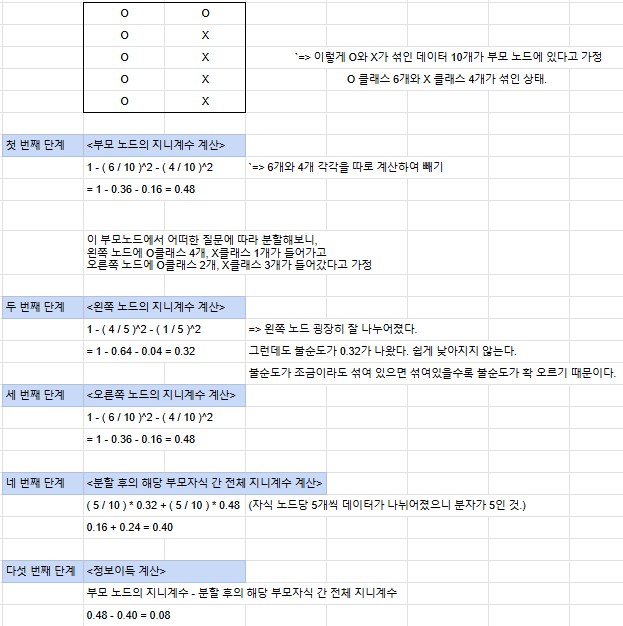
지니 불순도 : 데이터셋 안에 서로 다른 분류들이 얼만큼 섞여있는지 나타내는 지표로서, 작을수록 좋다.
-
지니 불순도가 얼마나 줄어드는지 확인하는 정보이득 공식 : (분할 전 부모 노드의 지니계수) - (
(왼쪽 자식 노드의 데이터 수)/(분할 후 전체 데이터 수)(분할 후 왼쪽 자식 노드의 지니계수) +
(오른쪽 자식 노드의 데이터 수)/(분할 후 전체 데이터 수)(분할 후 오른쪽 자식 노드의 지니계수)
)
밑은 계산 예시
저렇게 섞인 데이터에서 바로 불순도를 낮추기 위해 대각선으로 나누면 좋겠지만, 질문 하나에 가로or세로 직선 하나씩 생긴다.

이렇게 점점 분류되는 것이다.
결정 트리는 단순 수직선을 그리되, 이 수직선을 계속해서 그려나감으로써 복잡한 경계선을 만들어나가는 방법론이다.
스무 고개처럼 계속해서 질문을 하고, 수직선을 그려나간다.
장점
- 데이터를 분류하는 방법이 직관적이다.
- 어떤 속성이 얼마나 중요하게 사용됐는지 쉽게 알 수 있다.
단점
위에서 언급했듯, 결정 트리는 반복적 분할 방법론으로 학습을 진행한다.
따라서 훈련세트에 대하여 과적합(Overfitting)이 일어나기 쉽다.
이를 해결하기 위해 가지치기 방법론을 추가한다.
가지치기 방법은 여러 가지가 있다.
- 트리의 최대 깊이(max_depth)를 설정하여 분할 횟수 제한하기
- 노드가 분할되기 위한 최소 샘플 수(min_samples_split)를 설정해주기
- 리프 노드가 되기 위한 최소 샘플 수(min_samples_leaf)를 설정해주기
