AI
1.선형대수학이란 어떤 학문이며, 왜 머신러닝에 필요한가?

선형대수학이란? 데이터란? 머신러닝이란? 무슨 관계가 있을까
2.EDA(Exploratory Data Analysis)란 무엇인가?

EDA란? 왜 필요한가?
3.대표적인 데이터 전처리 방법 : 결측값, 중복값, 이상치 처리

전처리의 필요성( 기본 전처리 모듈( 전처리 방법들 정리(전처리에 대해서 정말 중요한 말이 있다. 바로 “Garbage In, Gargabe Out” 이다.의미있고 좋은 데이터들이 있어야 그만큼 좋은 결과가 나오는 것이다.만약 전처리과정없이 모든 데이터를 전부
4.지도 학습과 비지도 학습의 차이
Learning의 4종류( - 1. Supervised Learning( - 1. 분류 문제( - 2. 회귀 문제( - 2. Unsupervised Learning( - 3. Semi-Supervised Lea
5.손실 함수(loss function)란 무엇이며, 왜 중요한가?
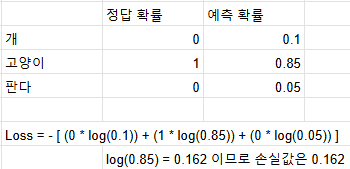
모델이 예측한 “예측값”과 “실제값” 차이를 측정하는 함수즉, “틀림의 정도”를 알려준다.이 차이가 얼만큼인지 봄으로써 모델의 성능을 평가할 수 있고, 모델의 개선점도 계산할 수 있다.당연히 예측값과 실제값의 차이가 없을 수록 좋은 모델이라는 뜻이므로 이 손실함수의 값
6.모델 학습 시 발생할 수 있는 편향과 분산
편향(Bias)이란?편향을 줄이는 방법?분산(Variance)이란?분산을 줄이는 방법?
7.K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점

데이터를 한 번만 나눠서 평가하면, 나눈 데이터의 내용에 따라 모델 점수가 다르게 나올 수 있다.따라서 학습,
8.결정 트리의 장점과 단점
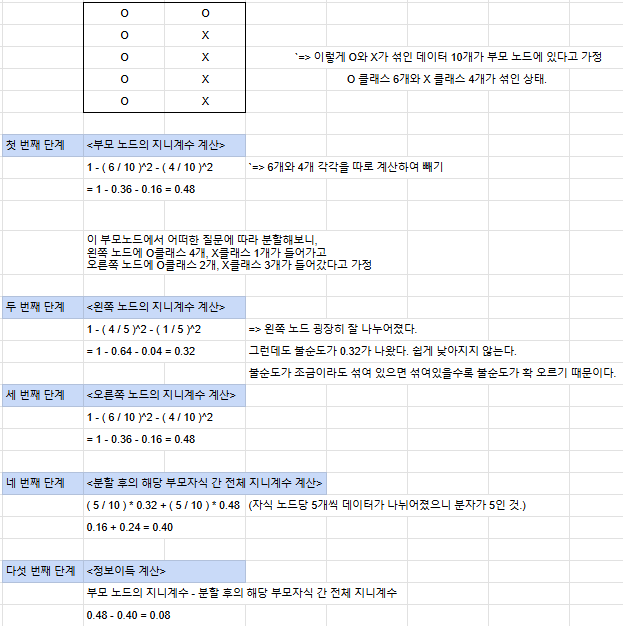
결정 트리란?장점?단점?
9.앙상블 기법 - 부스팅 모델의 특징과 장단점
앙상블 기법? (보팅, 배깅, 부스팅, 스태킹), 부스팅 모델의 특징과 장단점?
10.차원 축소 - 주성분 분석과 요인 분석의 차이
차원 축소란? 차원 축소 방법? 주성분 분석(PCA)? 요인 분석(FA)? 주성분 분석과 요인 분석의 차이?
11.딥러닝과 머신러닝 간의 포함관계
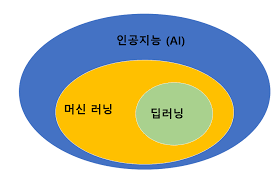
모든 딥러닝은 머신러닝이다. 하지만, 모든 머신러닝이 딥러닝은 아니다.
12.딥러닝의 성능향상을 위해 고려하는 하이퍼파라미터의 종류
하이퍼파라미터들의 종류와 뜻을 보자
13.딥러닝 프레임워크인 PyTorch와 TensorFlow를 비교해보자
사용성, 모델 개발 및 연구 친화성, 배포 및 프로덕션 환경, 생태계 및 커뮤니티, 대표적 사용 사례, 요약 비교, 결론 정리
14.PyTorch에서 텐서란 무엇이고, NumPy의 Array(배열)과 어떤 차이가 있나?
PyTorch에서 텐서(Tensor)란 무엇인가? NumPy Array(ndarray)란 무엇인가? 공통점과 차이점?
15.CNN을 구성하는 각 레이어의 역할
CNN이란? 레이어란? 각 레이어의 역할
16.오토 인코더란? 언제가 적용되기 적합한 상황일까?
오토 인코더를 구성하는 인코더와 디코더란? 오토 인코더가 사용되기 적합한 상황은?
17.딥러닝 이미지 전처리 : 리사이징(Resizing)과 정규화(Normalization)
리사이징과 정규화란? 왜 해야 하는가?
18.이미지 데이터를 다룰 때 - 데이터 증강이란?
데이터 증강에 대해 알아보자
19.이미지 분류에서 - 전이 학습이란?
전이 학습이란
20.YOLO(You Only Look Once) 모델의 주요 특징과 장점
YOLO란 객체 탐지를 하나의 회귀 문제로 정의하여 수행하는 딥러닝 모델이다. 특징과 장점은 뭘까?
21.객체 인식에서 mAP(mean Average Precision)이 활용되는 법
mAP란? 어떻게 쓰이나?
22.Semantic Segmentation과 이미지 분류(Classification)의 차이
1Semantic Segmentation이란? 2. 이미지 분류(Classification)와의 차이 3.핵심 차이 비교
23.Fully Convolutional Networks(FCN)의 주요 특징과 기존 CNN 기반 분류 모델과의 차이점
Fully Convolutional Network란?
24.GAN에서 생성자(Generator)와 판별자(Discriminator)의 역할
GAN? Generator와 Discriminator의 관계?
25.이미지 생성에서 Diffusion 모델의 활용과 장점
Diffusion 모델이란? 이미지 생성에서의 활용 방식은 뭘까