목차
차원 축소란
고차원 데이터의 차원을 축소하여 저차원으로 줄이는 알고리즘
- 차원이 높을 수록 데이터를 보기에 더 어려워지고, 학습에 요구되는 데이터의 갯수도 증가되고, 데이터 활용이나 학습 난이도도 높아지고, 데이터 및 모델이 복잡해진다는 내용이 있다.
차원 축소 방법
- 특성 선택
- 원래 있던 특성들 중에서 가장 중요하거나 유의미하다고 판다되는 몇 개의 특성만 골라서 사용
- 특성 추출
- 원래 있던 특성들을 조합해서 새로운 특성을 만들어내는 방법
- 기존 특성들의 정보를 압축하고 변형해서 적은 수의 새로운 차원을 생성
- 세부기법 : PCA, LDA, LLE 등
주성분 분석(PCA)
Principal Component Analysis : 널리 사용되는 일종의 차원 축소 기법
- 데이터 변동성이 가장 큰 방향으로 새로운 축을 생성하여 데이터를 표현함으로써, 원본 데이터의 분포를 최대한 보존하면서 차원을 축소
⇒ 데이터의 분산을 최대한 보존하는 새로운 ‘주성분’들을 만들어내서 차원을 축소
예를 들어 다음과 같은 2차원 데이터가 있다고 해보자.
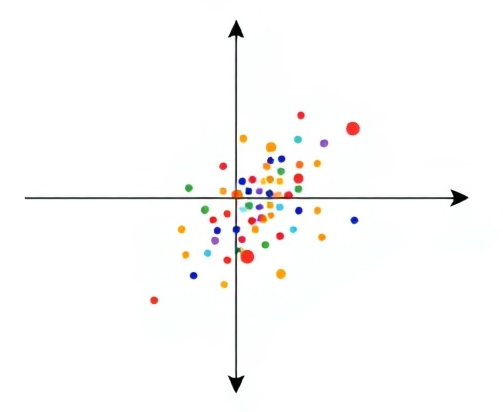 위 데이터 분포를 최대한 보존하면서 1차원 데이터로 나타내기 위해서는 어떻게 해야 할까?
위 데이터 분포를 최대한 보존하면서 1차원 데이터로 나타내기 위해서는 어떻게 해야 할까?
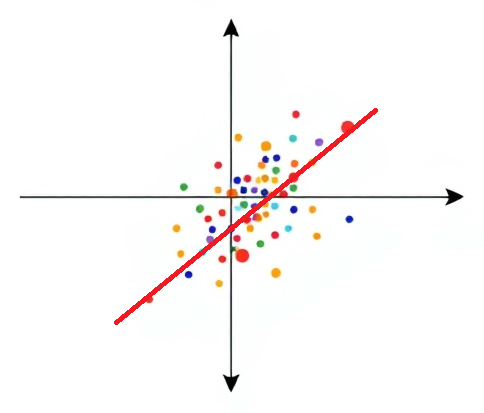
이렇게 새로운 축을 생성하는 게 가장 좋을 것이다.
왜일까?
각 데이터와 축까지의 잔차 제곱을 계산해봤을 때 위 그림과 같이 축을 만들어야 잔차 제곱을 최소화할 수 있기 때문이다.
이렇게 데이터 포인트들이 새로운 축에 투영되었을 때, 투영된 점들의 분산이 최대가 되는 축을 찾는 것이 PCA의 핵심이다.
이는 곧 원래 데이터 포인트들과 새로운 축 사이의 직교 거리 제곱의 합을 최소화하는 것과 동일한 결과이다
저렇게 잔차 제곱을 최소화해야 PCA의 핵심인 ‘분산을 최대화’할 수 있는 것이다.
참고 : 사실 저 그림은 쉽게 설명하기 위한 예시였고, 만약 저 알록달록한 데이터가 각 다른 특성들을 나타내고 있는 거라면 계산이 훨씬 복잡하다. (원리는 동일)
요인 분석
우리가 직접 측정한 데이터들(관찰 가능한 변수들) 뒤에 숨어 있는 잠재 요인을 찾아내는 통계 기법
- 예를 들어서 심리, 만족도, 행복, 지능, 성취도, 스트레스같은 ‘직접 측정하기 어려운 추상적개념’들을 여러 관찰 변수를 통해 간접적으로 파악하는 것
- 잠재 요인을 찾아내면 추상적인 개념의 실체를 더 명확하게 이해하고, 서로 상관관계가 높은 변수들까리 그룹화해줌으로써 복잡한 데이터를 단순화할 수 있음.
주성분 분석과 요인 분석의 차이
- PCA가 데이터 요약이라면, 요인 분석은 잠재요인 탐색
| 구분 | 주성분 분석 (Principal Component Analysis, PCA) | 요인 분석 (Factor Analysis, FA) |
|---|---|---|
| 주요 목적 | - 고차원 데이터의 변동성(variance)을 최대한 보존하면서 새로운 축(주성분)으로 데이터 요약 및 압축. - 데이터의 '중복 정보'를 제거하고 '주요 패턴'을 찾는 데 초점. | - 여러 관찰 변수들 뒤에 숨어있는, 관찰할 수 없는 소수의 '잠재 요인(latent factor)'을 탐색하고 확인. - 데이터의 '근원적인 구조'와 '숨겨진 원인'을 밝히는 데 초점. |
| 기본 가정 | - 모든 관찰 변수의 변동성은 추출된 주성분들로 100% 설명될 수 있다고 가정 (측정 오차 같은 '고유 분산'을 고려하지 않음). - 관찰 변수들이 주성분들의 선형 조합이라고 봄. | - 관찰 변수는 추출된 잠재 요인들(Common Factors)에 의해 설명되는 부분과, '측정 오차(Error Term)' 또는 '고유 분산(Unique Variance)'에 의해 설명되는 부분으로 구성된다고 가정. - 측정 오차의 존재를 인정함. |
| 추출된 것의 성격 | - 주성분(Principal Component): 원래 변수들의 선형 결합으로 만들어진 수학적인 구성물. - 데이터의 변동성을 최대로 설명하는 '요약된 새로운 변수'임. | - 잠재 요인(Latent Factor): 관찰 변수들 간의 상관관계를 '설명하는 근원적인 원인'이라고 가정되는 이론적인 개념임. |
| 관점 | - '데이터를 압축(요약)'하는 것에 중점. - 이미 존재하는 데이터를 '더 간결하게 만드는' 관점. | - '현상 뒤에 숨겨진 원인'을 찾아 '해석'하는 것에 중점. - 측정된 변수들 간의 관계를 '설명하는' 관점. |
| 주요 용도 | - 데이터 압축, 노이즈 제거, 데이터 시각화, 머신러닝 모델의 전처리 단계에서 과적합 방지 - 및 학습 속도 개선. | 직접 측정 어려운 개념의 정의 및 타당성 검증. |
| 해석의 용이성 | 추출된 주성분은 단순히 원래 변수들의 조합이므로 직접적인 의미 부여가 어려울 수 있음. 각 주성분이 '무엇을 의미하는지'는 분석가의 해석에 달려 있음. | 추출된 잠재 요인은 근원적인 개념을 가정하므로 해석에 더 용이할 수 있음. |

개발에 애정을 쏟는 연구자입니다