들어가기 앞서서..
- 빅데이터 처리를 위해 하둡이라는 오픈소스가 등장
- 분산 파일 시스템과 분산 컴퓨팅 시스템으로 구성
- HDFS와 맵리듀스/YARN
- 맵리듀스 프로그래밍의 제약성으로 인해 SQL이 재등장
- 분산 파일 시스템과 분산 컴퓨팅 시스템으로 구성
- Spark는 대세 대용량 데이터 분산 컴퓨팅 기술
- Pandas + Scikit Learn의 스테로이드 버전
- SQL과 스트림 데이터와 그래픽 처리도 제공
빅데이터 정의와 예시
-
서버 한대로 처리할 수 없는 규모의 데이터
-
판다스로 처리해야할 데이터가 너무 커서 처리가 불가능하다면 어떻게 할 것인가? 이를 해결하기 위해 데이터 분산 컴퓨팅 기술 Spark 도입
-
기존에 소프트웨어(오라클,Mysql과 같은 RDMS)로 처리할 수 없는 규모의 데이터
- 기존 소프트웨어는 분산환경을 염두에 두지 않음
- 해봐야 Scale up을 선호(메모리 추가, cpu 추가, 디스크 추가..)
빅데이터 4가지 특징
- 4V(Volume,Velocity,Variety,Varecity)
- Volume : 데이터의 크기가 대용량인가?
- Velocity : 데이터의 처리 속도가 중요한가?
- Variety : 구조화/비구조화 데이터 둘 다인가? (형태 이야기)
- Veracity : 데이터의 품질이 중요함.
빅데이터 예시
디바이스
- 모바일 디바이스
- 위치정보 등등..
- 스마트 TV
- 각종 센서 데이터(IoT 센서..)
- 네트워킹 디바이스
웹
- 현재, 수 많은 웹 페이지가 존재
- 이는 웹 검색엔진 개발이 대용량 데이터 처리를 겸한다는 것을 의미
- 웹 페이지를 크롤하여 중요한 페이지를 찾아내고 인덱싱하고 서빙
- 구글이 빅데이터 기술의 발전에 지대한 공헌
- 사용자 검색어와 클릭 정보 자체도 대용량
- 이를 마이닝하여 개인화 혹은 별도 서비스 개발이 가능
- 요즘은 웹 자체가 NLP 거대 모델 개발의 훈련 데이터로 사용
빅데이터 처리의 특징과 해결 방안
데이터 저장
- 문제점 : 방대한 데이터를 손실 없이 보관해야 함.
- 해결 방안
- 스토리지 : 큰 데이터를 손실 없이 저장할 수 있는 분산 파일 시스템이 필요
처리 시간
- 문제점 : 데이터 처리 시간이 오래 걸림
- 해결 방안
- 병렬 처리 : 병렬 처리가 가능한 분산 컴퓨팅 시스템이 필요
데이터 유형
- 문제점 : 빅데이터는 비구조화된 데이터일 가능성이 높음.
- 해결 방안
- 비구조화 데이터 처리 : SQL만으로는 부족하기 때문에 비구조화 데이터를 처리할 방법이 필요
- 예시로는 웹 로그 파일이 있음
결론
- 큰 데이터 저장이 가능한 분산 파일 시스템.
- 병렬 처리가 가능한 분산 컴퓨팅 시스템
- 비구조화 데이터를 처리할 방법이 필요
- 위를 모두 충족하는 것이 다수의 컴퓨터로 구성된 프레임 워크
- 그러기 위해 나온 것이
대용량 분산 시스템
대용량 분산 시스템이란?
- 분산 환경 기반(1대 혹은 그 이상의 서버로 구성)
- 분산 파일 시스템과 분산 컴퓨팅 시스템이 필요
- Fault Tolerance
- 소수의 서버가 고장나도 동작해야함.
- 확장이 용이
- Sacle out이 되어야 함.(컴퓨터를 추가하는 식으로)
Hadoop
- 다수의 노드로 구성된 클러스터 시스템
- 마치 하나의 거대한 컴퓨터처럼 동작
- 사실은 다수의 컴퓨터들이 복잡한 소프트웨어로 통제됨
- Opensource software
- distributed sotrage (분산 파일 시스템 HDFS)
- distributed processing(분산 컴퓨팅 시스템인 MapRedsuce)
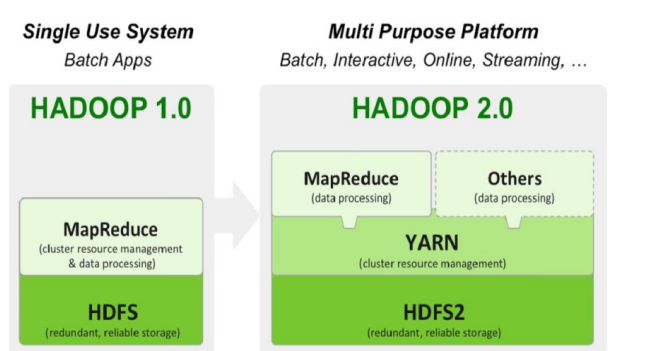
하둡의 발전(1.0)
- 하둡 1.0은 HDFS위에 MapReduce라는 분산컴퓨팅 시스템이 도는 구조
- MapReduce 위에서 다양한 컴퓨팅 언어들로 만들어짐.
하둡의 발전(2.0)
- 리소스 관리 효율성가 확장성, 다양한 데이터 처리 요구로 인해 1.0에서 2.0으로 개선(이는 YARN과 HDFS 개선을 중심으로 이뤄짐)
- 하둡 2.0에서 아키텍처가 크게 변경
- 하둡은 YARN이란 이름의 분산처리 시스템 위에서 동작하는 애플리케이션
- Spark는 YARN(리소스 효율성 관련) 위에서 애플리케이션 레이어로 실행
HDFS - 분산 파일 시스템
- 데이터 저장 방식
- 데이터를 블록 단위로 나누어 저장하며, 기본 블록 크기는 128MB
- 블록 복제 방식(Replication)
- 각 블록은 세 군데에 중복 저장되어, Fault Tolerance를 보장
- 노드 이중화(High Availability)
- 하둡 2.0에서는 Active와 Standy라는 내임 노드가 존재하며, 둘 사이에 share edit log가 있음
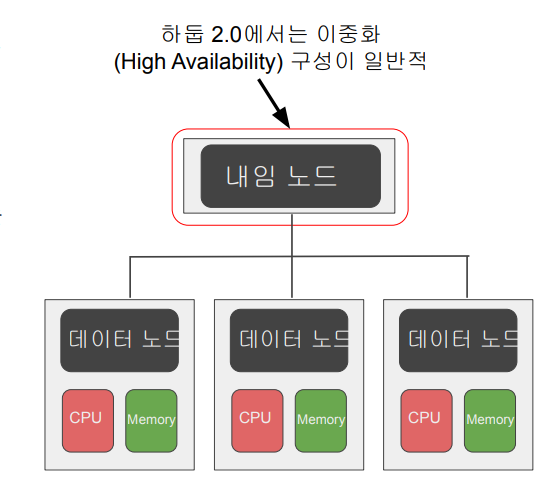
- 하둡 2.0에서는 Active와 Standy라는 내임 노드가 존재하며, 둘 사이에 share edit log가 있음
- 마스터 슬레이브 구조에서 마스터 역할을 하는 것이 내임 노드
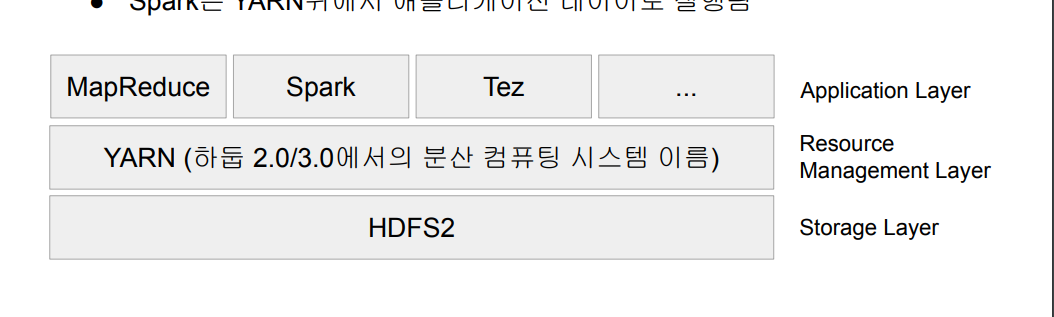
MapReduce - 분산 컴퓨팅 시스템
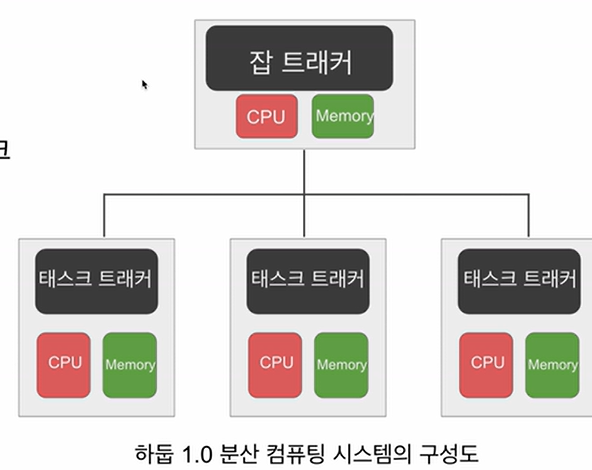
- 하둡 1.0에서 사용
- 하나의 잡 트래커와 다수의 태스크 트래커로 구성
- 잡 트래커가 일을 나눠서 다수의 태스크 트래커에게 분배(로드 밸런서 같은거)
- 태스크 트래커에서 병렬처리
- MaReduce만 지원(general한 것은 아님)
YARN - 하둡 2.0에서 등장, 리소스 관련
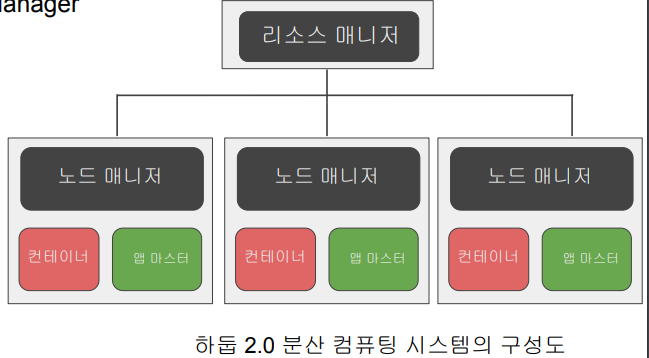
- 하둡 2.0에서 쓰는 분산 컴퓨팅 시스템임
- 세부 리소스 관리가 가능한 범용 컴퓨팅 프레임 워크
- 리소스 매니저
- job scheduler, application Manager
- 노드 매니저
- 컨테이너
- 앱 마스터
- 태스크
- Spark가 이 위에서 구현됨
- 리소스 매니저
YARN - 동작 과정
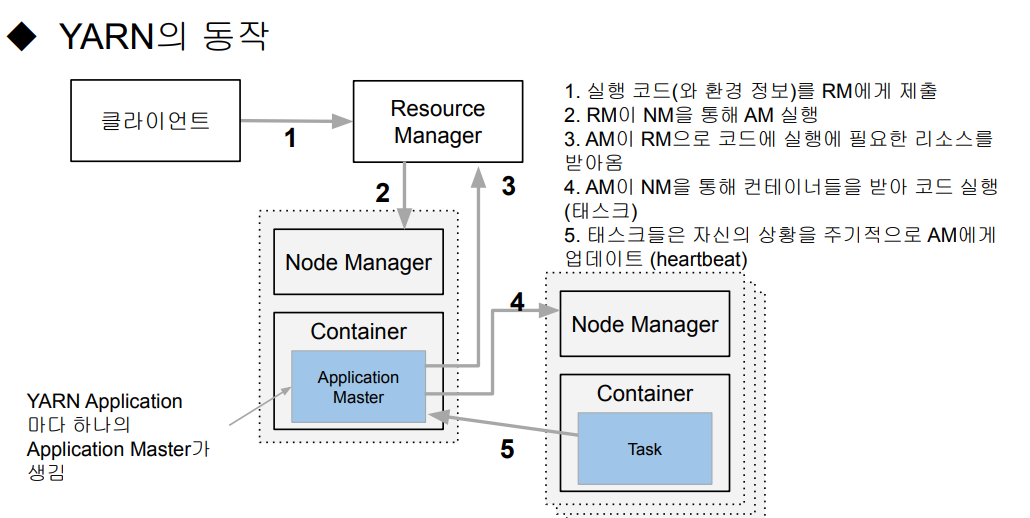
- 실행하려는 코드와 환경 정보를 RM(Resource Manager)에게 넘김
- 실행에 필요한 파일들은 application Id에 해당하는 HDFS 폴더에 미리 복사
- RM은 NM(Node Manager)으로부터 컨테이너를 받아 AM 실행
- AM은 프로그램 마다 하나씩 할당되는 프로그램 마스터에 해당
- AM은 입력 데이터 처리에 필요한 리소스를 RM에게 요구
- RM은 data locality를 고려해서 리소스(컨테이너)ㄹ르 할당
- AM은 할당받은 리소스를 NM을 통해 컨테이너로 론치하고 그 안에서 코드를 실행
- 이 때 실행에 필요한 파일들이 HDFS에서 Container가 있는 서버로 먼저 복사
- 각 태스크는 상황을 주기적으로 AM에게 보고 (hearbeat)
- 태스크가 실패하거나 보고가 오랜 시간 없으면 태스크를 다른 컨테이너로 재실행
하둡 3.0
- YARN 2.0을 사용
- YARN 프로그램들의 논리적인 그룹(flow)으로 나눠서 자원관리가 가능. 이를 통해 데이터 수집 프로세스와 데이터 서빙 프로세스를 나눠서 관리 가능
- 타임 라인 서버에서 HBase를 기본 스토리지로 사용
- 파일 시스템
- 내임노드의 경우 다수의 스탠바이 내임노드를 지원
-HDFS,S3,Azure Storage 이외에도 Azure Data Lake Sotrage 등을 지원
- 내임노드의 경우 다수의 스탠바이 내임노드를 지원
기존 프로그래밍과 MapReduce 프로그래밍의 차이
기존 프로그래밍
- 단일 시스템 처리: 데이터 처리를 단일 컴퓨터나 서버에서 수행.
- 데이터 모델: 다양한 데이터 모델과 구조를 지원.
- 유연한 연산: 여러 가지 프로그래밍 연산과 논리적 처리가 가능.
- 입출력: 주로 메모리 및 로컬 디스크 기반의 입출력.
MapReduce 프로그래밍
- 분산 시스템 처리: 데이터를 분산 파일 시스템(HDFS)에 저장하고 여러 컴퓨터에서 병렬로 처리.
- 데이터 모델: Key-Value 쌍의 불변(immutable) 데이터 셋으로 작업.
- 연산 제한: Map과 Reduce 두 가지 오퍼레이션으로만 데이터 조작이 가능.
- Map: 입력된 키-값 쌍을 새로운 키-값 쌍 리스트로 변환.
- Reduce: 같은 키를 가진 값들을 그룹화하고 새로운 키-값 쌍으로 변환.
- 셔플링(Shuffling): Map의 결과를 네트워크를 통해 Reduce 단으로 이동시키는 과정.
- 디스크 기반 입출력: 모든 중간 결과와 최종 결과는 디스크에 저장됨, 이는 대규모 데이터 배치 처리에 적합.
- Fault Tolerance: 일부 노드의 고장이 전체 작업에 영향을 주지 않도록 설계됨.
- 낮은 생산성: 프로그래밍 모델의 융통성이 부족하고 튜닝 및 최적화가 어려움. (데이터 분포가 균등하지 않는 경우)
주요 차이점 요약
-
처리 방식:
- 기존: 단일 시스템에서 처리.
- MapReduce: 분산 시스템에서 병렬 처리.
-
데이터 모델:
- 기존: 다양한 데이터 모델.
- MapReduce: Key-Value 불변 데이터 셋.
-
연산 제한:
- 기존: 다양한 연산 지원.
- MapReduce: Map과 Reduce 오퍼레이션만 지원.
-
입출력 방식:
- 기존: 메모리 및 로컬 디스크 기반.
- MapReduce: 디스크 기반 입출력.
-
성능 최적화:
- 기존: 다양한 최적화 가능.
- MapReduce: 셔플링과 디스크 입출력으로 인해 최적화 어려움.
MapReduce : 프로그래밍 예제
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- TokenizerMapper 클래스
- Mapper 클래스를 상속받아 구현
- Map메서드는 입력 값(text)를 단어로 분리하고, 각 단어에 대해(단어,1) 형태의 키 - 값 쌍을 출력으로 보냄
- StringTokenizer를 이용해 입력 문자열을 단어 단위로 분리
- IntSumReducer 클래스
- Reducer 클래스를 상속받아 구현
- reduce 메서드는 같은 키(단어)를 가진 값들(1의 리스트)을 모두 합산하여 단어의 빈도수 계산
- 결과는 (단어, 빈도수) 형태의 키 - 값 쌍으로 출력
- main 메서드
- main 메서드는 haddop Mapreduce 작업을 설정하고 실행
- Configuration 객체를 생성하고, GenericOptionsParser를 이용해 입력 인수를 파싱
- 최소 2개 이상의 인수가 필요하며 입력 파일 경로들과 출력 디렉터리 경로를 포함
- job 객체를 생성하고, Mapper와 Reducer 클래스를 설정
- 입력 경로와 출력 경로를 설정
- 작업이 완료될 때까지 기다리고, 성공 여부에 따라 종료 코드를 반환
MapReduce 대안들의 등장
- 더 범용적인 대용량 데이터 처리 프레임 워크들의 등장
- YARN,Spark
- SQL의 컴백 : Hive, Presto 등이 등장
- Hive
- MapReduce위에서 구현, Throughput에 초점, 대용량 ETL에 적합
- Presto
- Low Latncy에서 초점, 메모리를 주로 사용, Adhoc 쿼리에 적합
- AWS Athena가 Presto 기반
- Hive
Hadoop 설치
ssh -i 파일.pem host.amazaon.com" 으로 로그인
Spark
- spark는 하둡보다 발전한 빅데이터 처리 기술
- YARN등을 분산환경으로 사용
- Scala로 작성됨
Spark 3.0의 구성
Spark 3.0의 구성 요소 설명
-
Spark Core:
- Spark의 기본 실행 엔진으로, 메모리 내 연산과 분산 작업 스케줄링을 담당함.
-
Spark SQL:
- SQL 쿼리를 통해 구조화된 데이터를 조작할 수 있게 함으로써, 데이터프레임 및 테이블 형식의 데이터 처리를 지원함.
-
Spark ML:
- 머신러닝 라이브러리로, 데이터 분석 및 예측 모델을 구축할 수 있게 함.
- Spark MLlib: RDD 기반의 초기 머신러닝 라이브러리로, 현재는 데이터프레임 기반의 Spark ML로 통합됨.
-
Spark Streaming:
- 실시간 데이터 스트리밍을 처리함으로써, 지속적으로 들어오는 데이터 스트림을 배치 단위로 처리함.
-
Spark GraphX:
- 그래프 및 그래프 병렬 처리 라이브러리로, 그래프 구조를 처리하고 분석할 수 있게 함.
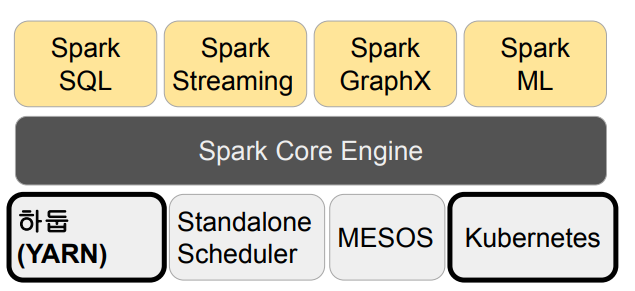
Spark vs MapReduce
- Spark는 기본적으로 메모리 기반
- 메모리가 부족해지면 디스크 사용
- MapReduce는 디스크 기반
- MapReduce는 하둡(YARN)위에서만 동작
- spark는 하둡 이외에도 다른 분산 컴퓨팅 지원(K8s, Mesos)
- MapReduce는 키와 벨류 기반 데이터 구조만 지우너
- Spark는 판다스 데이터 프레임과 개념적으로 동일한 데이터 구조 지원
- Spark는 다양한 방식의 컴퓨팅 지원
- 배치 데이터 처리, 스트림 데이터 처리, SQL, 머신러닝, 그래피 분석 등등
Spark 프로그래밍 API 요약
RDD (Resilient Distributed Dataset)
- 특징: 로우레벨 프로그래밍 API로 세밀한 제어가 가능하나, 코딩 복잡도가 증가함.
DataFrame & Dataset
- 특징: 하이레벨 프로그래밍 API로 많이 사용됨. 구조화된 데이터 조작 시 보통 Spark SQL을 사용함.
- 사용 상황: ML 피쳐 엔지니어링, Spark ML 사용, SQL만으로 처리 불가능한 경우.
Spark SQL
- 특징: SQL로 구조화된 데이터 처리, 데이터프레임을 SQL처럼 처리 가능.
- 성능: Hive 쿼리보다 최대 100배 빠른 성능(단, 최근 Hive 개선 고려).
Spark ML
- 특징: 다양한 머신러닝 알고리즘 및 유틸리티 제공.
- 버전: RDD 기반의
spark.mllib과 데이터프레임 기반의spark.ml존재.spark.ml사용 권장. - 장점: 원스톱 ML 프레임워크로, 데이터 전처리부터 모델 빌딩, 자동화 및 관리 가능.
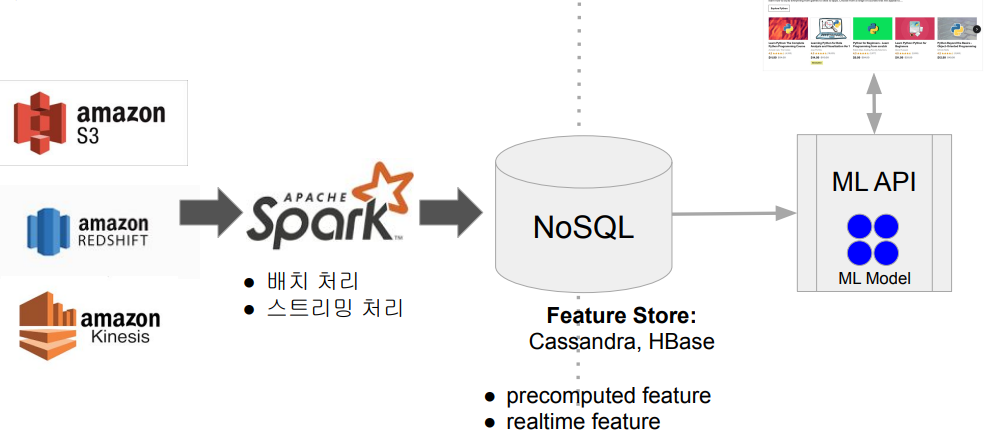
Spark 데이터 시스템 사용 예시
- 대용량 비구조화 데이터 처리 (ETL/ELT)
- 대용량 피쳐 처리 (배치/스트림)
- 대용량 훈련 데이터 모델 학습 (Spark ML 사용)
Spark 데이터 시스템 사용 예시
-
ETL 혹은 ELT와 같이 대용량 비구조화된 데이터 처리하기 (Hive 대체)
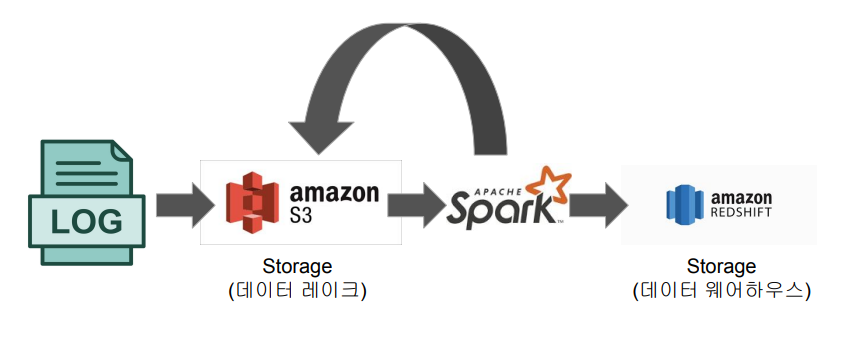
-
ML 모델에 사용되는 대용량 피쳐 처리
번외
단어 정리
- NLP
- Pandas + Scikit Learn의 스테로이드 버전

개인공부용(업데이트 중단)