Spark
Spark 데이터 처리
Spark 데이터 시스템 아키텍처
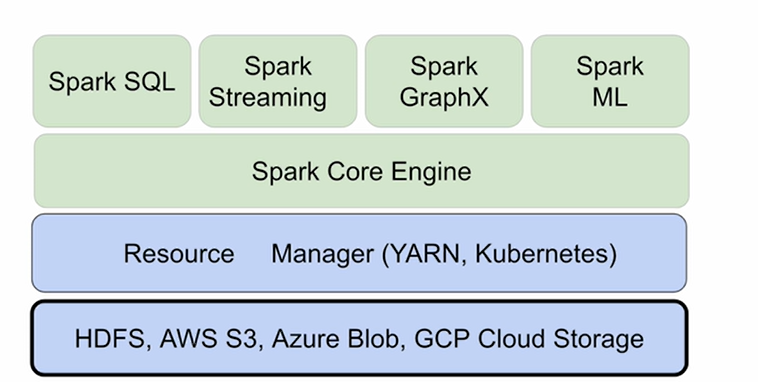
- 파일 시스템을 별도로 가지고 있진 않지만, 기존에 있는 분산 파일 시스템을 사용
- HDFS,S3,Azure Blob,GCP Cloud Storage가 있음 (내부 데이터)
- YARN이나 Kubernetes같은 Resource Manager를 사용
- 그위에 Spark가 사용됨.
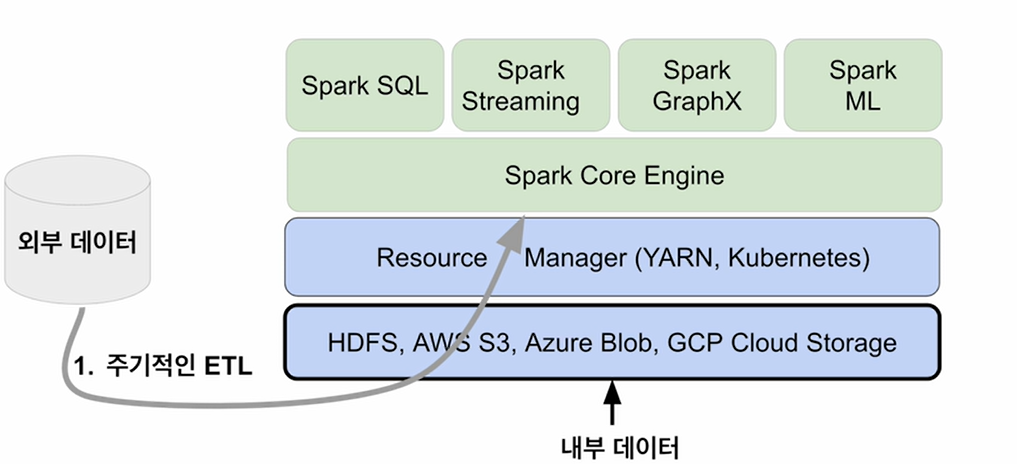
- 보통 ETL은 주기적으로 외부에서 옴(보통 Airflow 사용)
hadoop,spark의 특징 - 병렬처리
데이터 병렬처리가 가능하려면?
- 데이터가 먼저 분산되어야함.
- 하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록(default : 128MB)
- hdfs-site.xml에 있는 dfs.block.size 프로퍼티가 결정
- Spark에서는 이를 파티션이라 부름(Partition), 파티션의 기본크기도 128MB
spark.sql.files.maxPartitionBytes에 있는 파일을 읽어올 때만 적용
- 하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록(default : 128MB)
- 다음으로 나눠진 데이터를 각각 따로 동시 처리
- 맵리듀스에서 N개의 데이터 블록으로 구성된 파일 처리시 n개의 map 태스크가 실행
- spark에서는 파티션 단위로 메모리로 로드되어 Executor가 배정됨
처리 데이터를 나누기 -> 파티션 -> 병렬처리

Spark 데이터 처리 흐름
- 데이터프레임은 작은 파티션들로 구성
- 데이터프레임은 한 번 만들어지면 수정 불가
- 입력 데이터프레임을 원하는 결과 도출까지 다른 데이터 프레임으로 계속 변환
- Sort,group by, filter,map,join

- 파티션간에 데이터 이동 없이 계속 변환이 가능할까? -> 그 상황에서 나온 것이 셔플링
셔플링
- 셔플링 :
- 셔플링이 발생하는 경우
파티션간에 데이터 이동이 필요한 경우 발생- 명시적 파티션을 새롭게 하는 경우(예 : 파티션 수를 줄이기)
- 시스템에 의해 이뤄지는 셔플링
- 예를 들어 그룹핑 등의 aggregation이나 sorting
- 셔플링이 발생할 때 네트웍을 타고 데이터가 이동하게 됨
- 몇개의 파티션이 결과로 만들어질까?
spark.sql.shuffle.partitions이 결정- 기본값은 200이며 이는 최대 파티션 수
- operation에 따라 파티션 수가 결정됨
- random,hashing partition, range partition 등등.
-sorting의 경우 range partition이 사용됨
- random,hashing partition, range partition 등등.
- 또한 이때 Data Skew 발생 가능
- 몇개의 파티션이 결과로 만들어질까?
- 셔플링이 발생하는 경우
셔플링 : hashing partition

Data Skew

- Data partitioning은 데이터 처리에 병렬성을 주지만 단점도 존재
- 이는 데이터가 균등하게 분포하지 않는 경우
- 주로 데이터 셔플링 후에 발생
- 셔플링을 최소화하는 것이 중요하고 파티션 최적화를 하는 것이 중요.
- 이는 데이터가 균등하게 분포하지 않는 경우
Spark 데이터 구조

이 사진은 Apache Spark의 SQL 엔진 아키텍처를 설명하는 다이어그램입니다. 각 구성 요소와 그 기능을 다음과 같이 설명할 수 있습니다:
-
상단 레이어:
- Spark SQL: SQL 쿼리를 실행하기 위한 API임.
- DataFrame: 데이터의 컬렉션을 분산된 형태로 표현한 API임.
- Dataset: DataFrame과 유사하지만, 타입 안정성이 보장된 구조화된 데이터 컬렉션을 제공하는 API임.
-
중간 레이어:
- Spark SQL Engine: SQL 쿼리나 DataFrame/Dataset 연산을 수행하는 엔진임. 다음의 네 가지 단계로 나뉨:
- Code Analysis: 입력된 쿼리나 연산에 대해 구문 분석을 수행함.
- Logical Optimization (Catalyst Optimizer): 쿼리의 논리적 실행 계획을 최적화함. Catalyst Optimizer를 사용하여 최적화된 논리적 계획을 생성함.
- Physical Planning: 논리적 계획을 물리적 실행 계획으로 변환함. 물리적 계획은 실제 데이터 처리 작업을 정의함.
- Code Generation (Project Tungsten): 물리적 실행 계획을 실제 코드로 변환하여 실행함. Project Tungsten은 메모리 및 CPU 효율성을 극대화하기 위한 최적화를 제공함.
- Spark SQL Engine: SQL 쿼리나 DataFrame/Dataset 연산을 수행하는 엔진임. 다음의 네 가지 단계로 나뉨:
-
하단 레이어:
- RDD API: 기본 데이터 처리 모델로, Spark의 핵심 API임. 분산된 데이터셋을 처리하기 위해 사용됨. DataFrame과 Dataset은 내부적으로 RDD를 사용하여 동작함.
이 다이어그램은 Spark SQL 엔진이 쿼리와 연산을 어떻게 처리하고 최적화하는지를 시각적으로 설명함. 각 단계는 데이터 처리의 효율성을 높이기 위해 중요한 역할을 함.
spark 데이터 구조 3가지 - RDD,DataFrame,Dataset(Immutable Distributed Data)
-
2016년에 데이터프레임과 Data set은 하나의 API로 통합
-
모두 파티션으로 나뉘어 Spark에서 처리됨

RDD (Resilient Distributed Dataset)
-
로우레벨 데이터로 클러스터내의 서버에 분산된 데이터를 지칭
-
레코드별로 존재하지만 스키마가 존재하지 않음
- 구조화된 데이터나 비구조화된 데이터 모두 지원
-
변경이 불가능한 분산 저장된 데이터
- RDD는 다수의 파티션으로 구성
- 로우레벨의 함수형 변환 지원(map,filter,flatMap)
-
일반 파이썬 데이터는 parallelize 함수로 RDD 변환
- 반대는 collect로 파이썬 데이터로 변환 가능

DataFrame과 Dataset
- RDD위에 만들어지는 RDD와는 달리 필드 정보를 갖고 있음(테이블 형태)
- Dataset은 타입 정보가 존재하며 컴파일 언어에서 사용 가능
- 컴파일 언어 : scala/java
- PySpark에서는 DataFrame을 사용
- 판다스의 데이터 프레임 혹은 관계형 데이터 베이스의 테이블과 거의 흡사
Spark program Structure
spark session 생성
- spark의 시작은 spark session 생성
- 프로그램마다 하나를 만들어 Spark Cluster와 통신 : Singleton 객체
- Spark 2.0에서 처음 소개됨
- Spark Session을 통해 Spark가 제공해주는 다양한 기능을 사용
- DataFrame, SQL, Streaming, ML API 모두 이 객체로 통신
- Config 메서드를 이용해 다양한 환경설정 가능
- 단 RDD와 관련된 작업을 할 때는 SparkSession 밑의 SparkContext 객체를 사용
예제 - PySpark, Spark session 생성
#pyspark는 Spark SQL Engine이 중심으로 동작
from pyspark.sql import SparkSession
# SparkSession은 싱글턴
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.getOrCreate()
…
spark.stop()
제공 기능
❖ pyspark.sql.SparkSession
❖ pyspark.sql.DataFrame
❖ pyspark.sql.Column
❖ pyspark.sql.Row
❖ pyspark.sql.functions
❖ pyspark.sql.types
❖ pyspark.sql.Window
Spark Session 환경 변수
- Spark Session을 만들 때 다양한 환경 설정이 가능함
- 몇 가지 예:
- executor별 메모리:
spark.executor.memory(기본값: 1g) - executor별 CPU 수:
spark.executor.cores(YARN에서는 기본값 1) - driver 메모리:
spark.driver.memory(기본값: 1g) - Shuffle 후 Partition의 수:
spark.sql.shuffle.partitions(기본값: 최대 200)
- executor별 메모리:
- 가능한 모든 환경변수 옵션은 사용하는 Resource Manager에 따라 다름
Spark Session 환경 설정 방법
- 환경 변수로 설정함
$SPARK_HOME/conf/spark_defaults.conf파일을 사용함spark-submit명령의 커맨드라인 파라미터를 사용함 (나중에 따로 설명함)SparkSession만들 때 지정함 (SparkConf객체 사용)
충돌 시 우선순위
- 아래일수록 우선순위가 높음
- 보통 Spark Cluster 어드민이 관리함
Spark 세션 환경 설정 방법 (1)
SparkSession생성 시 일일히 지정함
from pyspark.sql import SparkSession
# SparkSession은 싱글턴임
spark = SparkSession.builder \
.master("local[*]") \
.appName('PySpark Tutorial') \
.config("spark.some.config.option1", "some-value") \
.config("spark.some.config.option2", "some-value") \
.getOrCreate()- 이 시점의 Spark Configuration은 앞서 언급한 환경 변수와
spark_defaults.conf,spark-submit로 들어온 환경 설정이 우선순위를 고려한 상태로 정리된 상태임
Spark 세션 환경 설정 방법 (2)
SparkConf객체에 환경 설정하고SparkSession에 지정함
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
# SparkSession은 싱글턴임
spark = SparkSession.builder \
.config(conf=conf) \
.getOrCreate()전체적인 플로우

- Spark 세션(SparkSession)을 만들기
- 입력 데이터 로딩
- 데이터 조작 작업 (판다스와 아주 흡사함)
- DataFrame API나 Spark SQL을 사용함
- 원하는 결과가 나올 때까지 새로운 DataFrame을 생성함
- 최종 결과 저장
Spark Session이 지원하는 데이터 소스
spark.read(DataFrameReader)를 사용하여 데이터프레임으로 로드함DataFrame.write(DataFrameWriter)를 사용하여 데이터프레임을 저장함- 많이 사용되는 데이터 소스들:
- HDFS 파일: CSV, JSON, Parquet, ORC, Text, Avro
- Hive 테이블
- JDBC 관계형 데이터베이스
- 클라우드 기반 데이터 시스템
- 스트리밍 시스템
개발 실습 환경 소개
Spark 개발 환경 옵션
- Local Standalone Spark + Spark Shell
- Python IDE - PyCharm, VS 등등..
- Databricks Cloud
- 다른 노트북 - 주피터 노트북, 구글 colab, 아나콘다 등등.. 일단 여기선 구글 Colab을 사용할 예정
Local Standalone Spark
- Spark Cluster Manager로 local[n] 지정
- master를 local[n]으로 지정
- master는 클러스터 매니저를 지정하는데 사용
- 주로 개발이나 간단한 테스트 용도
- 하나의 JVM에서 모든 프로세스를 실행
- 하나의 driver와 하나의 Executor가 실행됨
- 1+ 쓰레드가 Executor 안에서 실행됨
- Executor 안에 생성되는 쓰레드 수
- local : 하나의 쓰레드만.
- local[*]: 컴퓨터 cpu 수만큼 쓰레드 생성

구글 Colab에서 Spark 사용
- PySpark + Py4J 설치
- 구글 Colab 가상서버 위에 로컬 모드 Spark 실행
- 개발 목적으로 충분하나, 큰 데이터 처리 불가
- Spark web UI는 기본적으로 접근 불가
- Py4J
- Python에서 jvm내에 있는 자바 객체 사용 가능
실습
!pip install pyspark==3.3.1 py4j==0.10.9.5pyspark,py4j사용
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.getOrCreate()- spark sesson은 spark 2.0부터 엔트리 포인트로 사용, Spark Sesson을 이용해 DD,데이터 프레임등을 만듬.
- SparkSession은 SparkSession.builder를 호출하여 생성하며 다양한 함수들을 통해 세부 설정이 가능.
- local[*] Spark가 하나의 JVM으로 동작, 그 안에 컴퓨터의 코어 수만큼 스레드가 Executor로 동작
spark 호출시의 결과

!lscpu의 결과

- CPU 모델, 코어 수, 스레드 수, 클럭 속도 등의 정보
!grep MemTotal /proc/meminfo의 결과

- 시스템의 총 물리적 메모리(RAM) 용량을 출력
실습 - Python <> RDD <> DataFrame
#python list 생성
name_list_json = [ '{"name": "keeyong"}', '{"name": "benjamin"}', '{"name": "claire"}' ]
for n in name_list_json:
print(n)
# 파이썬 리스트를 RDD로 변환
# RDD로 변환되는 순간 Spark 클러스터의 서버들에 데이터가 나눠 저장됨 (파티션)
rdd = spark.sparkContext.parallelize(name_list_json)
rdd
rdd.count()- 결과는 3
import json
parsed_rdd = rdd.map(lambda el: json.loads(el))
- RDD의 각 요소를 json 문자열에서 파이썬 딕셔너리로 변환
- map 함수는 rdd의 각 요소에 json.lads를 적용하여 새로운 RDD를 생성.
- 결과로는 각 요소가 json 문자열에서 파이썬 딕셔너리로 변환된 RDD가 나옴
parsed_rdd.collect()
- 클러스터의 모든 노드에서 RDD의 모든 요소를 수집하여 드라이버 프로그램으로 반환, 그러면 파이썬 딕셔너리로 변환된 요소들이 포함된 리스트를 반환
parsed_name_rdd = rdd.map(lambda el:json.loads(el)["name"])
- 딕셔너리의 name 필드 값을 추출하여 새로운 RDD 생성
parsed_name_rdd.collect() 을 통해 name 필드 값들이 포함된 리스트 반환

이 코드는 파이썬 리스트를 PySpark 데이터프레임으로 변환하고, 해당 데이터프레임의 정보와 내용을 확인하는 과정을 보여줌. 각 코드 셀을 단계별로 설명함.
pythonlist -> DataFrame
1. 데이터프레임 생성
from pyspark.sql.types import StringType
df = spark.createDataFrame(name_list_json, StringType())- 설명:
name_list_json이라는 파이썬 리스트를 PySpark 데이터프레임으로 변환함. StringType: 데이터프레임의 컬럼 타입을 문자열로 지정함.createDataFrame: PySpark 데이터프레임을 생성하는 메소드임.
2. 데이터프레임의 레코드 수 확인
df.count()- 설명: 데이터프레임의 총 레코드 수를 세어 반환함.
- 결과: 데이터프레임에 3개의 레코드가 있음을 확인함.
3. 데이터프레임의 스키마 확인
df.printSchema()- 설명: 데이터프레임의 스키마(컬럼의 데이터 타입)를 출력함.
- 결과: 데이터프레임에 하나의 컬럼
value가 있으며, 타입은string이고 nullable(널 값을 허용)함을 확인함.
4. 데이터프레임의 모든 데이터를 수집하여 출력
df.select('*').collect()- 설명: 데이터프레임의 모든 컬럼(
*)을 선택하고,collect()메소드를 사용하여 모든 데이터를 드라이버 프로그램으로 수집하여 출력함. - 결과: 데이터프레임의 모든 레코드가 출력됨. 각 레코드는 파이썬 딕셔너리 형태의 문자열로 되어 있음.
[Row(value='{"name": "keeyong"}'), Row(value='{"name": "benjamin"}'), Row(value='{"name": "claire"}')]
RDD를 DF로 변환
df_parsed_rdd = parsed_rdd.toDF()
-
toDF메서드는 RDD를 DF로 변환
-
결과로 df_parsed_red라는 DF 생성
df_parsed_rdd.printSchema() -
스키마(컬럼 데이터 타입) 확인

df_parsed_rdd.select('name').collect()
의 결과
[Row(name='keeyong'), Row(name='benjamin'), Row(name='claire')]- Dataframe의 컬럼을 name으로 선택하고 collect 메서드를 사용하여 출력
Spark 데이터 프레임으로 로드해보기
1. CSV 파일 다운로드
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv- 설명:
wget명령어를 사용하여name_gender.csv파일을 다운로드함. - 결과:
name_gender.csv파일이 현재 디렉토리에 저장됨.
2. CSV 파일을 데이터프레임으로 로드
df = spark.read.csv("name_gender.csv")
df.printSchema()- 설명:
spark.read.csv메소드를 사용하여name_gender.csv파일을 데이터프레임으로 로드함. - 결과: 기본적으로 헤더가 없는 파일로 인식하여
_c0,_c1등의 이름으로 컬럼이 지정됨.
3. 헤더가 있는 CSV 파일을 데이터프레임으로 로드
df = spark.read.option("header", True).csv("name_gender.csv")
df.printSchema()- 설명:
option("header", True)를 추가하여 헤더가 있는 CSV 파일로 로드함. - 결과:
name,gender컬럼이 지정됨.
4. 데이터프레임의 데이터를 확인
df.show()- 설명: 데이터프레임의 데이터를 출력함.
- 결과: 데이터프레임의 첫 몇 개의 레코드가 출력됨.
5. 데이터프레임의 첫 5개의 행 출력
df.head(5)- 설명: 데이터프레임의 첫 5개의 행을 출력함.
- 결과: 첫 5개의 행이
Row객체로 반환됨.[Row(name='Adaleigh', gender='F'), Row(name='Amryn', gender='Unisex'), Row(name='Apurva', gender='Unisex'), Row(name='Aryion', gender='M'), Row(name='Alixia', gender='F')]
6. 그룹화 및 집계
df.groupby(["gender"]).count().collect()- 설명:
gender컬럼을 기준으로 그룹화하고 각 그룹의 개수를 세어 수집함. - 결과: 각 성별별 이름의 개수가
Row객체로 반환됨.[Row(gender='F', count=65), Row(gender='M', count=28), Row(gender='Unisex', count=7)]
7. 파티션 수 확인
df.rdd.getNumPartitions()- 설명: 데이터프레임의 RDD가 몇 개의 파티션으로 나누어져 있는지 확인함.
- 결과: 파티션 수가 1임을 확인함.
데이터프레임을 테이블로 만들어서 Spark SQL로 처리해보기
1. 임시 테이블 생성
df.createOrReplaceTempView("namegender")- 설명: 데이터프레임을 임시 테이블로 등록함.
- 결과:
namegender라는 이름의 임시 테이블이 생성됨.
2. Spark SQL을 사용하여 데이터 처리
namegender_group_df = spark.sql("SELECT gender, count(1) FROM namegender GROUP BY 1")
namegender_group_df.collect()- 설명: Spark SQL을 사용하여
gender컬럼을 기준으로 그룹화하고 각 그룹의 개수를 셈. - 결과: 각 성별별 이름의 개수가
Row객체로 반환됨.[Row(gender='F', count=65), Row(gender='M', count=28), Row(gender='Unisex', count=7)]
3. 현재 존재하는 테이블 목록 확인
spark.catalog.listTables()- 설명: 현재 세션에서 사용 가능한 테이블 목록을 확인함.
- 결과:
namegender임시 테이블이 목록에 포함되어 있음을 확인함.[Table(name='namegender', database=None, description=None, tableType='TEMPORARY', isTemporary=True)]
파티션의 수 계산해보기
1. 파티션 수 변경
two_namegender_group_df = namegender_group_df.repartition(2)- 설명:
namegender_group_df데이터프레임을 2개의 파티션으로 나눔. - 결과:
two_namegender_group_df데이터프레임이 2개의 파티션으로 나뉨.
2. 파티션 수 확인
two_namegender_group_df.rdd.getNumPartitions()- 설명:
two_namegender_group_df데이터프레임의 파티션 수를 확인함. - 결과: 파티션 수가 2임을 확인함.
Spark 설치
실습 - 예제
실습 전 사전정보
Dataframe의 컬럼 지칭
from pyspark.sql.functions import col, column
stationTemps = minTemps.select(
"stationID",
col("stationID"),
column("stationID"),
minTemps.stationID
)실습 - 헤더 없는 csv 파일 처리
- 입력 데이터 : 헤더 없는 csv 파일
- 데이터에 스키마 지정
- SparkConf 사용해보기
- measure_type 값이 TMIN인 레코드 대상으로 stationld별 최소 온도 찾기
순서
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/1800.csv
- 처리할 데이터 파일을 먼저 다운 받기
ls -tl

!head -5 1800.csv
- 데이터 확인

import pandas as pd
pd_df = pd.read_csv(
"1800.csv",
names=["stationID", "date", "measure_type", "temperature"],
usecols=[0, 1, 2, 3]
)- 판다스 데이터 프레임으로 처리해보기
pd_df.head()

Pandas 사용
# Filter out all but TMIN entries
pd_minTemps = pd_df[pd_df['measure_type'] == "TMIN"]
pd_minTemps.head()
# Select only stationID and temperature
pd_stationTemps = pd_minTemps[["stationID", "temperature"]]
# Aggregate to find minimum temperature for every station
pd_minTempsByStation = pd_stationTemps.groupby(["stationID"]).min("temperature")
pd_minTempsByStation.head()pd_df: Pandas DataFrame으로 로드된 CSV 파일pd_minTemps:measure_type이TMIN인 행만 필터링pd_stationTemps:stationID와temperature열만 선택pd_minTempsByStation: 각stationID별로 최소 온도를 계산
PySpark 사용
1. Spark 세션 설정
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark DataFrame #1")
conf.set("spark.master", "local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()SparkConf를 사용하여 Spark 애플리케이션 설정SparkSession을 생성하여 Spark 클러스터와 통신
2. CSV 파일 로드 및 스키마 설정
df = spark.read.format("csv").option("inferSchema", "true").load("1800.csv")\
.toDF("stationID", "date", "measure_type", "temperature", "_c4", "_c5", "_c6", "_c7")
# 혹은 명시적으로 스키마를 지정
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
schema = StructType([
StructField("stationID", StringType(), True),
StructField("date", IntegerType(), True),
StructField("measure_type", StringType(), True),
StructField("temperature", FloatType(), True)
])
df = spark.read.schema(schema).csv("1800.csv")
df.printSchema()- CSV 파일을 DataFrame으로 로드하고 스키마를 설정
inferSchema옵션을 사용하여 자동으로 스키마를 추론하거나, 명시적으로 스키마를 지정
3. TMIN 항목 필터링 및 최소 온도 계산
# Filter out all but TMIN entries
minTemps = df.filter(df.measure_type == "TMIN")
# Aggregate to find minimum temperature for every station
minTempsByStation = minTemps.groupBy("stationID").min("temperature")
minTempsByStation.show()measure_type이TMIN인 행만 필터링- 각
stationID별로 최소 온도를 계산
4. 결과 수집 및 출력
# Collect, format, and print the results
results = minTempsByStation.collect()
for result in results:
print(result[0] + "\t{:.2f}F".format(result[1]))- 결과를 수집하고 형식화하여 출력
5. Spark SQL로 처리
df.createOrReplaceTempView("station1800")
results = spark.sql("""
SELECT stationID, MIN(temperature)
FROM station1800
WHERE measure_type = 'TMIN'
GROUP BY stationID
""").collect()
for r in results:
print(r)- DataFrame을 임시 뷰로 등록하여 SQL 쿼리로 처리
- SQL을 사용하여 각
stationID별 최소 온도를 계산하고 출력
요약
- Pandas를 사용한 경우, DataFrame의 필터링과 그룹화 기능을 이용하여 각 스테이션의 최소 온도를 계산함.
- PySpark를 사용한 경우, DataFrame API 및 SQL을 이용하여 대용량 데이터셋에서 동일한 작업을 병렬로 처리함.
- 두 접근 방식 모두 데이터를 필터링하고, 필요한 열을 선택하고, 그룹화하여 최소 값을 계산하는 동일한 기본 단계를 따름.


실습 2. 헤더 없는 CSV 파일 처리하기 (PySpark)
이 실습에서는 Pandas와 유사한 방식으로 PySpark를 사용하여 CSV 파일을 처리하는 방법을 다룸. 주요 작업은 CSV 파일에서 고객별로 지출 금액의 합계, 최대값, 평균값을 계산하는 것임.
1. PySpark 설치 및 SparkSession 생성
!pip install pyspark==3.3.1 py4j==0.10.9.5
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark DataFrame #2')\
.getOrCreate()- PySpark와 Py4J를 설치하고, SparkSession을 생성하여 로컬 모드에서 실행함.
2. 데이터 다운로드 및 확인
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/customer-orders.csv
!ls -tl
!head -5 customer-orders.csvcustomer-orders.csv파일을 다운로드하고, 첫 5개의 행을 확인함.
3. 스키마 정의 및 데이터 로드
from pyspark.sql import functions as func
from pyspark.sql.types import StructType, StructField, StringType, FloatType
schema = StructType([
StructField("cust_id", StringType(), True),
StructField("item_id", StringType(), True),
StructField("amount_spent", FloatType(), True)
])
df = spark.read.schema(schema).csv("customer-orders.csv")
df.printSchema()- 스키마를 정의하여 CSV 파일을 DataFrame으로 로드하고, 스키마를 출력함.
4. 고객별 지출 금액의 합계 계산
df_ca = df.groupBy("cust_id").sum("amount_spent")
df_ca.show()- 고객별로
amount_spent의 합계를 계산하고 출력함.
5. 컬럼 이름 변경 및 다양한 집계 계산
df_ca = df.groupBy("cust_id").sum("amount_spent").withColumnRenamed("sum(amount_spent)", "sum")
df_ca.show(10)
import pyspark.sql.functions as f
df_ca = df.groupBy("cust_id") \
.agg(f.sum('amount_spent').alias('sum'), f.max('amount_spent').alias('max'), f.avg('amount_spent').alias('avg'))
df_ca.show(5)sum(amount_spent)컬럼의 이름을sum으로 변경하고, 고객별로 지출 금액의 합계(sum), 최대값(max), 평균값(avg)을 계산함.
6. Spark SQL로 처리
df.createOrReplaceTempView("customer_orders")
results = spark.sql("""
SELECT cust_id, SUM(amount_spent) sum, MAX(amount_spent) max, AVG(amount_spent) avg
FROM customer_orders
GROUP BY cust_id
""").head(5)
print(results)- DataFrame을 임시 뷰로 등록하고, SQL 쿼리를 사용하여 고객별로 지출 금액의 합계, 최대값, 평균값을 계산함.
7. 테이블 목록 확인
spark.catalog.listTables()- 현재 세션에서 사용 가능한 테이블 목록을 확인함.
요약
- PySpark 설치 및 설정: PySpark와 Py4J를 설치하고, SparkSession을 생성함.
- 데이터 다운로드 및 확인: CSV 파일을 다운로드하고, 파일의 첫 몇 줄을 확인함.
- 스키마 정의 및 데이터 로드: 명시적인 스키마를 정의하여 데이터를 DataFrame으로 로드함.
- 데이터 집계: 고객별로 지출 금액의 합계, 최대값, 평균값을 계산함.
- Spark SQL 사용: SQL 쿼리를 사용하여 동일한 집계를 수행하고, 결과를 출력함.
- 테이블 목록 확인: 현재 세션에서 사용 가능한 테이블 목록을 확인함.
이 실습을 통해 PySpark를 사용하여 대용량 데이터셋을 효율적으로 처리하고 집계하는 방법을 배울 수 있음.


실습 3. 텍스트 파일 파싱 및 구조화된 데이터로 변환하기 (PySpark)

이 실습에서는 PySpark를 사용하여 텍스트 파일을 읽고, 데이터를 파싱하여 구조화된 데이터로 변환한 후 CSV 및 JSON 형식으로 저장하는 방법을 다룸.
1. PySpark 설치 및 SparkSession 생성
!pip install pyspark==3.3.1 py4j==0.10.9.5
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark DataFrame #3")
conf.set("spark.master", "local[*]")
spark = SparkSession.builder\
.config(conf=conf)\
.getOrCreate()- PySpark와 Py4J를 설치하고, SparkSession을 생성하여 로컬 모드에서 실행함.
2. 데이터 다운로드 및 확인
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/transfer_cost.txt
!ls -tl
!head -5 transfer_cost.txttransfer_cost.txt파일을 다운로드하고, 첫 5개의 행을 확인함.
3. 스키마 정의 및 데이터 로드
import pyspark.sql.functions as F
from pyspark.sql.types import *
schema = StructType([StructField("text", StringType(), True)])
transfer_cost_df = spark.read.schema(schema).text("transfer_cost.txt")
transfer_cost_df.show(truncate=False)- 스키마를 정의하여 텍스트 파일을 DataFrame으로 로드하고, 데이터를 출력함.
4. 정규 표현식을 사용하여 데이터 파싱
from pyspark.sql.functions import *
regex_str = r'On (\S+) the cost per ton from (\d+) to (\d+) is (\S+) at (.*)'
df_with_new_columns = transfer_cost_df\
.withColumn('week', regexp_extract('text', regex_str, 1))\
.withColumn('departure_zipcode', regexp_extract(column('text'), regex_str, 2))\
.withColumn('arrival_zipcode', regexp_extract(transfer_cost_df.text, regex_str, 3))\
.withColumn('cost', regexp_extract(col('text'), regex_str, 4))\
.withColumn('vendor', regexp_extract(col('text'), regex_str, 5))
df_with_new_columns.printSchema()- 정규 표현식을 사용하여 텍스트 데이터를 파싱하고, 새로운 컬럼을 생성함.
5. 텍스트 컬럼 제거 및 CSV 형식으로 저장
final_df = df_with_new_columns.drop("text")
final_df.write.csv("extracted.csv")
!ls -tl
!ls -tl extracted.csv/
!head -5 extracted.csv/part-00000-a909db0a-d743-4a0c-96fc-60c1a8eef076-c000.csvtext컬럼을 제거하고, 데이터를 CSV 형식으로 저장함.- 저장된 CSV 파일을 확인함.
6. JSON 형식으로 저장
final_df.write.format("json").save("extracted.json")
!ls -tl extracted.json/
!head -1 extracted.json/part-00000-104f95b9-f2c6-4f77-a170-583c78106e11-c000.json- 데이터를 JSON 형식으로 저장함.
- 저장된 JSON 파일을 확인함.
요약
- PySpark 설치 및 설정: PySpark와 Py4J를 설치하고, SparkSession을 생성함.
- 데이터 다운로드 및 확인: 텍스트 파일을 다운로드하고, 파일의 첫 몇 줄을 확인함.
- 스키마 정의 및 데이터 로드: 명시적인 스키마를 정의하여 텍스트 데이터를 DataFrame으로 로드함.
- 정규 표현식을 사용하여 데이터 파싱: 텍스트 데이터를 파싱하여 구조화된 형태로 변환함.
- 텍스트 컬럼 제거 및 CSV 형식으로 저장: 파싱된 데이터를 CSV 형식으로 저장함.
- JSON 형식으로 저장: 파싱된 데이터를 JSON 형식으로 저장함.
이 실습을 통해 PySpark를 사용하여 텍스트 데이터를 파싱하고, 구조화된 데이터로 변환한 후 다양한 형식으로 저장하는 방법을 배울 수 있음.

실습 4. Stackoverflow 서베이 기반 인기 언어 찾기 (PySpark)

이 실습에서는 PySpark를 사용하여 Stackoverflow 설문조사 데이터를 분석하고, 가장 많이 사용되는 언어와 가장 배우고 싶은 언어를 찾는 방법을 다룸.
1. PySpark 설치 및 SparkSession 생성
!pip install pyspark==3.3.1 py4j==0.10.9.5
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark DataFrame #4')\
.getOrCreate()- PySpark와 Py4J를 설치하고, SparkSession을 생성하여 로컬 모드에서 실행함.
2. 데이터 다운로드 및 확인
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/survey_results_public.csv
!ls -tlsurvey_results_public.csv파일을 다운로드하고, 파일이 제대로 저장되었는지 확인함.
3. 데이터 로드 및 스키마 확인
df = spark.read.csv("survey_results_public.csv", header=True, inferSchema=True)
df.printSchema()- CSV 파일을 DataFrame으로 로드하고, 스키마를 출력함.
4. 가장 많이 사용되는 언어 찾기
df_language_have = df.select(
df.ResponseId,
F.explode(F.split(df.LanguageHaveWorkedWith, ";")).alias("language_have")
)
df_language_have.show(5)
df_language50_have = df_language_have.groupby("language_have").count().orderBy('count', ascending=False).limit(50)
df_language50_have.write.mode('overwrite').csv("language50_have")LanguageHaveWorkedWith열을 기반으로 데이터를 분리하여 각 언어를 추출함.- 가장 많이 사용되는 상위 50개 언어를 계산하고, 결과를 CSV 파일로 저장함.
5. 가장 배우고 싶은 언어 찾기
df_language_want = df.select(
df.ResponseId,
F.explode(F.split(df.LanguageWantToWorkWith, ";")).alias("language_want")
)
df_language_want.show(5)
df_language50_want = df_language_want.groupby("language_want").count().orderBy('count', ascending=False).limit(50)
df_language50_want.write.mode('overwrite').csv("language50_want")LanguageWantToWorkWith열을 기반으로 데이터를 분리하여 각 언어를 추출함.- 가장 배우고 싶은 상위 50개 언어를 계산하고, 결과를 CSV 파일로 저장함.
6. 저장된 결과 확인
!ls -tl language50_have/
!cat language50_have/part-00000-d133bb73-6f57-4c38-a963-0c9ddf10dabf-c000.csv
!ls -tl language50_want/
!cat language50_want/part-00000-c59aa8f9-e4cc-4425-8ff0-368152be6934-c000.csv- 저장된 CSV 파일을 확인하여 결과를 출력함.
요약
- PySpark 설치 및 설정: PySpark와 Py4J를 설치하고, SparkSession을 생성함.
- 데이터 다운로드 및 확인: Stackoverflow 설문조사 데이터를 다운로드하고, 파일이 제대로 저장되었는지 확인함.
- 데이터 로드 및 스키마 확인: CSV 파일을 DataFrame으로 로드하고, 스키마를 출력함.
- 가장 많이 사용되는 언어 찾기:
LanguageHaveWorkedWith열을 분리하여 각 언어를 추출하고, 상위 50개 언어를 계산하여 CSV 파일로 저장함. - 가장 배우고 싶은 언어 찾기:
LanguageWantToWorkWith열을 분리하여 각 언어를 추출하고, 상위 50개 언어를 계산하여 CSV 파일로 저장함. - 저장된 결과 확인: 저장된 CSV 파일을 확인하여 결과를 출력함.
이 실습을 통해 PySpark를 사용하여 대규모 설문조사 데이터를 분석하고, 인기 있는 프로그래밍 언어를 파악하는 방법을 배울 수 있음.


실습 5. Redshift 연결 및 데이터 처리 (PySpark)
이 실습에서는 PySpark를 사용하여 Amazon Redshift 데이터베이스에 연결하고, 데이터를 로드한 후 분석하는 방법을 다룸.
1. PySpark 설치 및 Redshift JDBC 드라이버 다운로드
!pip install pyspark==3.3.1 py4j==0.10.9.5
!cd /usr/local/lib/python3.8/dist-packages/pyspark/jars && wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.20.1043/RedshiftJDBC42-no-awssdk-1.2.20.1043.jar- PySpark와 Py4J를 설치하고, Redshift JDBC 드라이버를 다운로드함.
2. SparkSession 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("PySpark DataFrame #5") \
.getOrCreate()- SparkSession을 생성하여 PySpark 작업을 수행할 준비를 함.
3. Redshift와 연결하여 테이블 로드
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234") \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234") \
.option("dbtable", "raw_data.session_timestamp") \
.load()- Redshift 데이터베이스에서
raw_data.user_session_channel및raw_data.session_timestamp테이블을 로드함.
4. 스키마 확인 및 파티션 수 확인
df_user_session_channel.printSchema()
df_user_session_channel.rdd.getNumPartitions()
df_session_timestamp.printSchema()
df_session_timestamp.rdd.getNumPartitions()- 로드한 데이터프레임의 스키마를 확인하고, 파티션 수를 확인함.
5. 데이터프레임 조인 및 스키마 확인
join_expr = df_user_session_channel.sessionid == df_session_timestamp.sessionid
session_df = df_user_session_channel.join(df_session_timestamp, join_expr, "inner")
session_df.printSchema()
session_df.show(5)- 두 데이터프레임을
sessionid를 기준으로 조인하고, 조인 결과의 스키마와 일부 데이터를 확인함.
6. 조인 후 필요한 컬럼 선택 및 집계
session_df = df_user_session_channel.join(df_session_timestamp, join_expr, "inner").select(
"userid", df_user_session_channel.sessionid, "channel", "ts"
)
channel_count_df = session_df.groupby("channel").count().orderBy("count", ascending=False)
channel_count_df.show()- 조인된 데이터프레임에서 필요한 컬럼만 선택하고,
channel별로 데이터 수를 집계하여 출력함.
7. 월별 활성 사용자 수 계산
from pyspark.sql.functions import date_format, asc, countDistinct
session_df.withColumn('month', date_format('ts', 'yyyy-MM')).groupby('month').\
agg(countDistinct("userid").alias("mau")).sort(asc('month')).show()ts컬럼을 기반으로 월을 추출하여, 월별로 활성 사용자 수(MAU)를 계산함.
8. Spark SQL을 사용한 처리
df_user_session_channel.createOrReplaceTempView("user_session_channel")
df_session_timestamp.createOrReplaceTempView("session_timestamp")
channel_count_df = spark.sql("""
SELECT channel, count(distinct userId) uniqueUsers
FROM session_timestamp st
JOIN user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1
""")
channel_count_df.show()
mau_df = spark.sql("""
SELECT
LEFT(A.ts, 7) AS month,
COUNT(DISTINCT B.userid) AS mau
FROM session_timestamp A
JOIN user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC""")
mau_df.collect()- 데이터프레임을 임시 뷰로 등록하고, SQL 쿼리를 사용하여
channel별로 고유 사용자 수를 계산함. - SQL 쿼리를 사용하여 월별 활성 사용자 수(MAU)를 계산하고 결과를 수집함.
요약
- PySpark 설치 및 Redshift JDBC 드라이버 다운로드: PySpark와 Py4J를 설치하고, Redshift JDBC 드라이버를 다운로드함.
- SparkSession 생성: SparkSession을 생성하여 PySpark 작업을 수행할 준비를 함.
- Redshift와 연결하여 테이블 로드: Redshift 데이터베이스에서 두 개의 테이블을 로드함.
- 스키마 확인 및 파티션 수 확인: 로드한 데이터프레임의 스키마와 파티션 수를 확인함.
- 데이터프레임 조인 및 스키마 확인: 두 데이터프레임을 조인하고, 조인 결과의 스키마와 일부 데이터를 확인함.
- 조인 후 필요한 컬럼 선택 및 집계: 조인된 데이터프레임에서 필요한 컬럼만 선택하고,
channel별로 데이터 수를 집계하여 출력함. - 월별 활성 사용자 수 계산:
ts컬럼을 기반으로 월을 추출하여, 월별로 활성 사용자 수(MAU)를 계산함. - Spark SQL을 사용한 처리: 데이터프레임을 임시 뷰로 등록하고, SQL 쿼리를 사용하여
channel별 고유 사용자 수와 월별 활성 사용자 수(MAU)를 계산함.
이 실습을 통해 PySpark를 사용하여 Redshift 데이터베이스와 연동하고, 데이터를 분석하는 방법을 배울 수 있음.


