spark 기타 기능 및 메모리 관리
Shuffling시 Skew 처리 방식과 Spark ML에 대한 파트
Broadcast Variable이란?
- 룩업 테이블등을 브로드캐스팅하여 셔플링을 막는 방식으로 사용
- 대부분 룩업 테이블을 executor로 전송하는 데 사용.
- 많은 DB에서 스타 스키마 혀애로 팩트 테이블과 디멘션 테이블을 분리
spark.sparkContext.broadcast를 사용
BroadCast Variable : 룩업 테이블(파일)을 UDF로 보내는 방법
- Closure
- Serialization이 태스크 단위로 일어남
- UDF 안에서 파이썬 데이터 구조를 사용하는 경우
- Broadcast
- Serialization이 Worker Node 단위로 일어남( 그안에서 캐싱되기에 훨씬 더 효율적)
- UDF안에서 브로드 캐스트된 데이터 구조를 사용하는 경우
- Boradcast 데이터 셋의 특징
- worker node로 공유되는 변경 불가 데이터
- worker node별로 한번 공유되고 캐싱됨
- 제약점은 task memory 안에 들어갈 수 있어야 함.
Broadcast Variable : 예제
- 가장 인기 있는 마블 슈퍼히어로를 찾는 예제
- 슈퍼히어로의 ID를 찾고 그에 해당하는 이름을 찾아야 함.
- 이 때 룩업 테이블을 DataFrame으로 로딩하고, 조인을 하는 것도 방법
- 아니면 룩업 테이블을 브로드 캐스트 하여 UDF안에서 사용하는 것도 방법
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
def my_func(code: str) -> str:
# return prdCode.get(code)
return bdData.value.get(code)
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Demo") \
.master("local[3]") \
.getOrCreate()
prdCode = spark.read.csv("data/lookup.csv").rdd.collectAsMap()
bdData = spark.sparkContext.broadcast(prdCode)
data_list = [("98312", "2021-01-01", "1200", "01"),
("01056", "2021-01-02", "2345", "01"),
("98312", "2021-02-03", "1200", "02"),
("01056", "2021-02-04", "2345", "02"),
("02845", "2021-02-05", "9812", "02")]
df = spark.createDataFrame(data_list) \
.toDF("code", "order_date", "price", "qty")
spark.udf.register("my_udf", my_func, StringType())
df.withColumn("Product", expr("my_udf(code)")) \
.show()
Accumluator란?
- 특정 이벤트의 수를 기록하는 데 사용됨 -> 일종의 전역 변수
- 하둡에서의 카운터
- 예를 들어 비정상적인 값을 갖는 레코드 수를 세는데 사용.
Accumulators 특징
- 변경 가능한 전역변수로 드라이버에 위치
- 이름있는 accumulator만 spark web UI에 나타남(스칼라로 코드 작성 해야함)
- recode 별로 세거나 합을 구하는데 사용
- 두 가지 방법으로 사용 가능하며 값의 정확도도 달라짐
- Transformation에서 사용
- 이 경우 값이 부정확할 수 있음.
- DataFrame/RDD Foreach에서 사용(추천)
- Transformation에서 사용
Accumuators - 예제
1. PySpark 세션 생성
PySpark를 사용하기 위해 세션을 생성함. 이 세션은 로컬 모드에서 동작하며, 'PySpark Accumulator'라는 애플리케이션 이름을 가짐.
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Accumulator')\
.getOrCreate()2. 데이터 준비
California 주의 도시와 zipcode 정보를 담은 데이터 리스트를 생성하고, 이를 DataFrame으로 변환함.
data_list = [
("California", "Sunnyvale", 9511),
("California", "Mountain View", 94111),
("California", "Cupertino", 94123),
("California", "San Jose", 951)
]
df = spark.createDataFrame(data_list) \
.toDF("state", "city", "zipcode")
df.show()출력:
+----------+-------------+-------+
| state| city|zipcode|
+----------+-------------+-------+
|California| Sunnyvale| 9511|
|California|Mountain View| 94111|
|California| Cupertino| 94123|
|California| San Jose| 951|
+----------+-------------+-------+3. Accumulator 생성
잘못된 zipcode의 개수를 세기 위해 accumulator를 생성함.
bad_zipcodes = spark.sparkContext.accumulator(0)4. UDF 함수 정의 및 등록
잘못된 zipcode를 처리하는 함수를 정의하고 UDF로 등록함. 이 함수는 zipcode가 5자리인지 확인하고, 그렇지 않으면 accumulator의 값을 1 증가시킴.
def handle_bad_zipcode(c: int) -> int:
if len(str(c)) != 5:
bad_zipcodes.add(1)
return None
return c
spark.udf.register("handle_bad_zipcode", handle_bad_zipcode, IntegerType())5. UDF 적용
UDF를 사용하여 zipcode를 검사하고, 잘못된 경우 null로 대체한 새로운 컬럼을 추가함.
df.withColumn("corrected_zipcode", expr("handle_bad_zipcode(zipcode)")) \
.show()출력:
+----------+-------------+-------+-----------------+
| state| city|zipcode|corrected_zipcode|
+----------+-------------+-------+-----------------+
|California| Sunnyvale| 9511| null|
|California|Mountain View| 94111| 94111|
|California| Cupertino| 94123| 94123|
|California| San Jose| 951| null|
+----------+-------------+-------+-----------------+6. 잘못된 zipcode 개수 출력
accumulator의 값을 출력하여 잘못된 zipcode의 개수를 확인함.
print("Bad Record Count:" + str(bad_zipcodes.value))출력:
Bad Record Count: 27. 데이터 정리
zipcode 컬럼을 수정하고, 잘못된 zipcode를 null로 대체한 DataFrame을 생성함.
df.withColumn("corrected_zipcode", expr("handle_bad_zipcode(zipcode)")). \
select("state", "city", "corrected_zipcode"). \
withColumnRenamed("corrected_zipcode", "zipcode").show()출력:
+----------+-------------+-------+
| state| city|zipcode|
+----------+-------------+-------+
|California| Sunnyvale| null|
|California|Mountain View| 94111|
|California| Cupertino| 94123|
|California| San Jose| null|
+----------+-------------+-------+8. DataFrame Foreach 예제
DataFrame의 각 값을 accumulator에 더하는 예제를 수행함.
data = [1, 2, 3, 4, 5]
df_test = spark.createDataFrame(data, "int").toDF("value")
accumulator = spark.sparkContext.accumulator(0)
def add_to_accumulator(row):
global accumulator
accumulator += row["value"]
df_test.foreach(add_to_accumulator)
print("Accumulator value: ", accumulator.value)출력:
Accumulator value: 159. 잘못된 zipcode 예제
DataFrame의 각 행을 검사하여 잘못된 zipcode를 찾는 예제를 수행함.
accumulator_zipcode = spark.sparkContext.accumulator(0)
def find_wrong_zipcode(row):
global accumulator_zipcode
accumulator_zipcode += 1 if len(str(row["zipcode"])) != 5 else 0
df.foreach(find_wrong_zipcode)
print("Wrong zipcode: ", accumulator_zipcode.value)출력:
Wrong zipcode: 2Speculative Execution
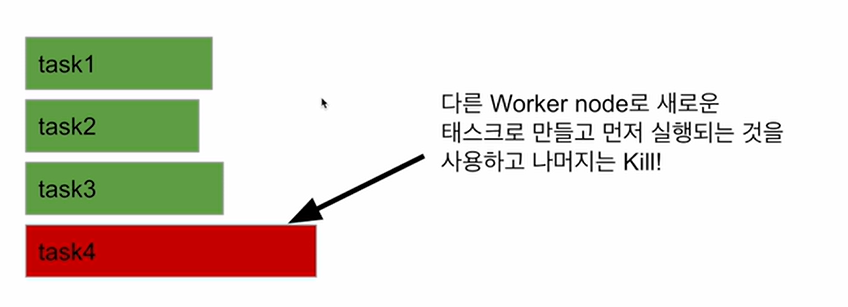
- 느린 태스크를 다른 Worker node에 있는 Executor에서 중복 실행
- 이를 통해 Worker noed의 하드웨어 이슈 등으로 느려지는 경우 빠른 실행을 보장
- 하지만 Data Skew로 인해 오래 걸린다면 도움이 안되고 리소스만 낭비하게 됨
Speculative Execution 제어 방식
- Spark.speculation으로 컨트롤 가능하며 기본은 False(비활성화)
- 하둡 MapReduce에서부터 있던 기능
- 다양한 환경 변수로 세밀하게 제어 가능
Spark 환경 변수 비교
| 환경 변수 이름 | Default 값 | LinkedIn 설정 값 |
|---|---|---|
| spark.speculation.interval | 100ms | 1 sec |
| spark.speculation.multiplier | 1.5 | 4 |
| spark.speculation.quantile | 0.75 | 0.9 |
| spark.speculation.minTaskRuntime | 100ms | 30 sec |
| spark.speculation.task.duration.threshold | None | None |
1. spark.speculation.interval
- 기능: 스파크가 작업의 사양 실행(speculative execution)을 검사하는 주기(interval)를 설정함.
- Default 값: 100ms
- LinkedIn 설정 값: 1 sec
2. spark.speculation.multiplier
- 기능: 작업의 사양 실행을 결정하기 위한 임계값(threshold)을 설정하는 데 사용되는 배수. 작업이 이 배수만큼 예상 완료 시간보다 오래 걸릴 경우, 스파크는 해당 작업의 사양 실행을 시작함.
- Default 값: 1.5
- LinkedIn 설정 값: 4
3. spark.speculation.quantile
- 기능: 전체 작업의 몇 퍼센트가 완료된 후에 사양 실행을 시작할지 결정함. 예를 들어, 0.75로 설정된 경우 전체 작업의 75%가 완료된 후에 사양 실행을 시작함.
- Default 값: 0.75
- LinkedIn 설정 값: 0.9
4. spark.speculation.minTaskRuntime
- 기능: 작업이 최소한으로 실행되어야 하는 시간을 설정함. 이 시간보다 짧게 실행된 작업은 사양 실행의 대상으로 고려되지 않음.
- Default 값: 100ms
- LinkedIn 설정 값: 30 sec
5. spark.speculation.task.duration.threshold
- 기능: 특정 작업의 사양 실행을 고려하기 위한 최대 실행 시간을 설정함. 이 값을 넘으면 사양 실행이 시작될 수 있음. 이 값이 설정되지 않은 경우 기본적으로 사양 실행의 최대 실행 시간이 없음.
- Default 값: None
- LinkedIn 설정 값: None
Spark Resource 할당(스케줄링)
크게 2개의 관점이 있음.
- Spark Application들 간의 리소스 할당
- 기반이 되는 리소스 매니저가 결정
- YARN은 세 가지 방식 지원 : FIFO, FAIR, CAPACITY - 한 번 리소스를 할당받으면 해당 리소스를 끝까지 들고 가는 것이 기본.
- 기반이 되는 리소스 매니저가 결정
- 하나의 Spark Application 안에서 잡들간의 리소스 할당
- FIFO 형태로 처음 잡이 필요한대로 리소스를 받아서 쓰는 것이 기본.
Spark Application의 리소스 요구/릴리스 방식
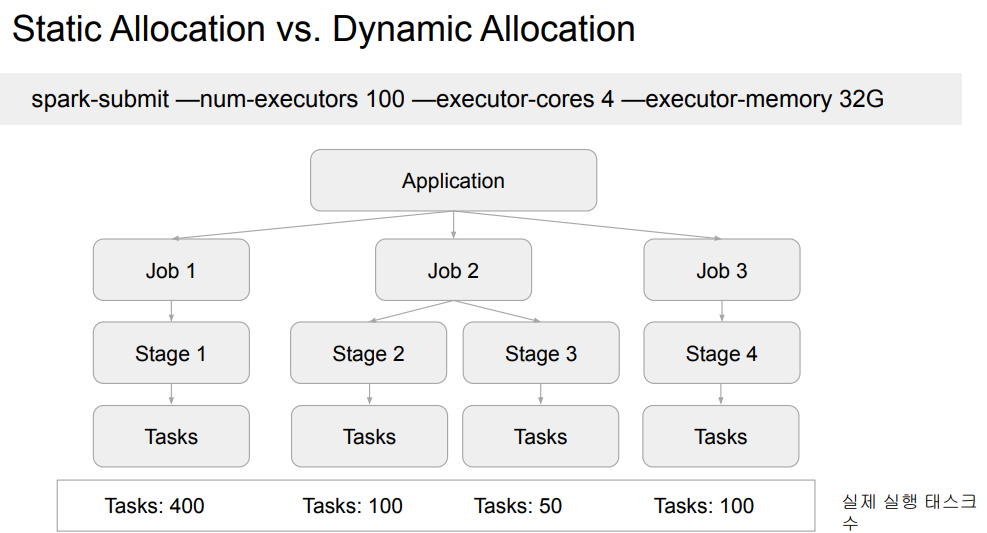
- static Allocation (기본 동작)
- Spark Application은 리소스 매니저로부터 받은 리소스를 보통 끝까지 들고감.
- 이는 리소스 사용률에 악영향을 줄 가능성이 높음.
- Dynamic Allocation
- spark Application이 상황에 따라 executor를 릴리스하기도 하고, 요구하기도 함.
- 다수의 Spark Application들이 하나의 리소스 매니저를 공유한다면 활성화하는 것이 좋음.
Dynamic Resource Allocation
Dynamic Resource Allocation은 스파크 클러스터에서 실행 중인 애플리케이션의 자원을 동적으로 조절하여 효율성을 극대화하는 기능임. 아래 환경 변수들로 제어됨.
1. spark.dynamicAllocation.enabled
- 기능: Dynamic Resource Allocation 기능을 활성화할지 여부를 설정함.
- 값:
true또는false - 설명:
true로 설정하면 Dynamic Resource Allocation이 활성화되어 실행 중인 애플리케이션이 필요에 따라 자원을 동적으로 조절함.
2. spark.dynamicAllocation.shuffleTracking.enabled
- 기능: Shuffle 서비스를 추적하여 사용되지 않는 executors를 자동으로 제거하는 기능을 활성화함.
- 값:
true또는false - 설명:
true로 설정하면 Dynamic Resource Allocation이 shuffle 데이터를 추적하고, shuffle 데이터가 더 이상 필요하지 않으면 해당 executors를 해제함.
3. spark.dynamicAllocation.executorIdleTimeout
- 기능: 사용되지 않는 executor가 해제되기 전까지 대기하는 시간.
- Default 값: 60초
- 설명: executor가 지정된 시간 동안 유휴 상태일 경우 해제됨. 이 값을 통해 유휴 상태인 executors를 유지하는 시간을 제어함.
4. spark.dynamicAllocation.schedulerBacklogTimeout
- 기능: 스케줄러 대기열에 대기 중인 작업이 있는 경우 추가 executor를 요청하기까지의 시간.
- Default 값: 1초
- 설명: 스케줄러 대기열에 작업이 쌓이기 시작한 후 지정된 시간만큼 대기한 후 추가 executor를 요청함. 이를 통해 빠르게 자원을 확장할 수 있음.
5. spark.dynamicAllocation.minExecutors
- 기능: 애플리케이션에 할당될 최소 executor 수를 설정함.
- 설명: Dynamic Resource Allocation이 활성화된 경우 최소한 몇 개의 executors를 유지할지 설정함. 이 값보다 적은 수의 executors는 유지되지 않음.
6. spark.dynamicAllocation.maxExecutors
- 기능: 애플리케이션에 할당될 최대 executor 수를 설정함.
- 설명: Dynamic Resource Allocation이 활성화된 경우 최대 몇 개의 executors를 사용할지 설정함. 이 값을 초과하는 수의 executors는 요청되지 않음.
7. spark.dynamicAllocation.initialExecutors
- 기능: 애플리케이션 시작 시 초기 executor 수를 설정함.
- 설명: 애플리케이션이 시작될 때 처음에 할당될 executors의 수를 설정함. 초기 실행 환경을 설정하는 데 유용함.
8. spark.dynamicAllocation.executorAllocationRatio
- 기능: 현재 사용 중인 executor의 비율을 기반으로 새로운 executor를 요청할지 여부를 결정함.
- 설명: 예를 들어, 이 값이 0.5로 설정된 경우, 현재 사용 중인 executor의 50%가 작업을 수행하고 있으면 추가 executor를 요청함. 이를 통해 자원 사용률을 최적화함.
Spark Scheduler
- 하나의 Spark Application 내의 잡들에 리소스를 나눠주는 정책
- Spark Application들간에 리소스를 나눠주는 방식은 리소스 매니저에게 달려 있음.
- 다음 2가지가 존재
- FIFO
- 리소스를 처음 요청한 job에게 리소스 우선 순위
- FAIR
- 라운드로빈 방식으로 모든 잡에게 고르게 리소스를 분배하는 방식.
- FIFO
Spark Scheduler를 활용한 병렬성 증대
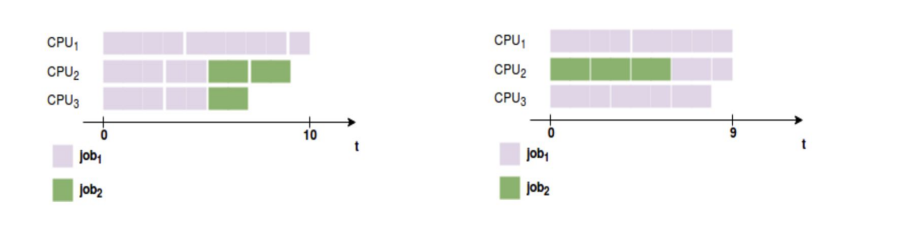
- 병렬성 증대를 위해선 Thread 활용이 필요
- 이는 FAIR 모드의 스케줄러인 경우 더 효과적
- 관련 환경 변수
Spark.schheduler.mode: FIFO(default) 혹은 FAIRspark.scheduler.allocation.file: "FAIR"인 경우 필요하며, 풀을 정의해놓은 형태로 사용됨.
Driver
Driver는 스파크 애플리케이션의 중심 역할을 하며, 스파크 클러스터와 상호작용하고 애플리케이션 실행을 관리함.
1. 애플리케이션의 시작 및 초기화
- 스파크 애플리케이션을 시작하고 초기화하는 역할을 담당함.
- 스파크 세션 또는 스파크 컨텍스트를 생성하여 클러스터와의 통신을 시작함.
2. DAG (Directed Acyclic Graph) 생성
- 사용자가 정의한 작업을 DAG로 변환함.
- DAG는 실행해야 할 작업을 단계별로 표현한 그래프 구조로, 작업의 의존성을 명확히 함.
3. 작업 스케줄링
- DAG를 기반으로 작업을 여러 스테이지로 나누고, 각 스테이지를 스케줄링하여 실행함.
- 각 스테이지는 태스크로 구성되며, 이 태스크들을 실행하기 위해 클러스터의 워커 노드에 분배함.
4. 클러스터와의 통신
- 클러스터 매니저(예: YARN, Mesos, Kubernetes)와 통신하여 리소스를 요청하고 할당받음.
- 워커 노드와 상호작용하여 태스크를 분배하고 모니터링함.
5. 작업 모니터링 및 오류 처리
- 태스크의 실행 상태를 모니터링하고, 실패한 태스크를 재시도하는 등 오류를 처리함.
- 작업의 진행 상태를 추적하고, 필요에 따라 자원을 동적으로 조정함.
6. 결과 수집 및 반환
- 각 태스크의 실행 결과를 수집하고, 최종 결과를 사용자에게 반환함.
- 사용자의 액션(예:
collect,save,count)을 처리하여 최종 데이터를 제공함.
7. 사용자 인터페이스 제공
- 스파크 UI를 통해 애플리케이션의 실행 상태, 리소스 사용량, 작업 진행 상황 등을 실시간으로 모니터링할 수 있는 인터페이스를 제공함.
Executor
Executor는 스파크 애플리케이션에서 실제 작업을 수행하는 구성 요소로, 주로 다음과 같은 역할을 함:
1. 태스크 실행
- 스파크 드라이버가 할당한 태스크를 실행함.
- 각 태스크는 RDD의 일부분을 처리하거나 DataFrame의 일부분을 처리하는 작업 단위임.
2. 데이터 저장
- 각 태스크의 중간 결과를 메모리나 디스크에 저장함.
- 저장된 데이터는 이후의 작업에서 재사용될 수 있으며, 특히 캐시된 데이터는 반복적인 작업에서 성능을 향상시킴.
3. 태스크 상태 보고
- 태스크의 실행 상태와 결과를 드라이버에 보고함.
- 성공적으로 완료된 태스크의 결과와 실패한 태스크의 오류 정보를 드라이버에게 전달함.
4. 리소스 관리
- 실행 중인 태스크가 사용하는 CPU, 메모리 등 리소스를 관리함.
- 메모리 내에서 데이터를 효율적으로 관리하여 JVM의 가비지 컬렉션 영향을 최소화하려고 노력함.
5. 오류 복구
- 태스크 실행 중 발생하는 오류를 처리하고, 필요에 따라 드라이버의 지시에 따라 태스크를 재시도함.
- 일반적으로 태스크가 실패하면, 드라이버가 동일한 태스크를 다른 Executor에 재할당하여 재시도함.
6. 사용자 정의 함수 실행
- 사용자가 정의한 함수(예: map, reduce, filter 등)를 각 태스크에서 실행함.
- 사용자 정의 UDF(User Defined Functions)나 UDAF(User Defined Aggregate Functions)도 실행함.
7. 네트워크 통신
- 다른 Executor와 데이터를 교환하여 셔플 작업을 수행함.
- 셔플 작업은 데이터 재분배를 포함하며, 큰 스파크 작업의 중요한 부분임.
요약
Executor는 스파크 애플리케이션에서 실제 데이터 처리를 담당하는 구성 요소임. 다음과 같은 역할을 수행함:
- 태스크 실행 및 중간 결과 저장
- 태스크 상태 및 결과 보고
- 자원 관리 및 오류 복구
- 사용자 정의 함수 및 네트워크 통신
이러한 역할을 통해 Executor는 스파크 클러스터에서 대규모 데이터를 분산 처리하고, 높은 성능을 유지함.
Driver와 Executor 발생가능 메모리 이슈 정리
Spark memory issue (OOM) - Driver

- Drvier OOM(out of memory)
- 큰 데이터 셋에서 coolect 실행
- 큰 데이터셋을 Broadcast join
- python이나 R 등으로 작성된 코드
- 너무 많은 태스크들.
Spark Out of Memory Error 해결 사례
1. Spark 세션 생성
Spark 세션을 생성하여 로컬 모드에서 3개의 코어를 사용하도록 설정함.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.master("local[3]") \
.appName("Spark Driver OOM Demo") \
.getOrCreate()2. 작은 데이터셋 생성 및 수집
작은 범위의 데이터를 생성하고 이를 수집하여 정상 작동을 확인함.
df = spark.range(1000)
d = df.collect()3. 큰 데이터셋 생성 및 수집 시도
대규모 데이터를 생성하고 이를 수집하려고 시도함. 이로 인해 메모리 부족 문제가 발생함.
df = spark.range(100000000)
d = df.collect()4. 발생한 오류
오류 메시지 (Out of Memory 부분):
Caused by: java.lang.OutOfMemoryError: Java heap space
at java.base/java.util.Arrays.copyOf(Arrays.java:3745)
at java.base/java.io.ByteArrayOutputStream.grow(ByteArrayOutputStream.java:120)
at java.base/java.io.ByteArrayOutputStream.ensureCapacity(ByteArrayOutputStream.java:95)
at java.base/java.io.ByteArrayOutputStream.write(ByteArrayOutputStream.java:156)
at net.jpountz.lz4.LZ4BlockOutputStream.flushBufferedData(LZ4BlockOutputStream.java:225)
at net.jpountz.lz4.LZ4BlockOutputStream.write(LZ4BlockOutputStream.java:178)
at java.base/java.io.DataOutputStream.write(DataOutputStream.java:107)
at org.apache.spark.sql.catalyst.expressions.UnsafeRow.writeToStream(UnsafeRow.java:542)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:367)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
...원인 분석 및 해결 방안
원인
- 데이터셋의 크기가 너무 커서 Driver의 힙 메모리가 부족해짐.
collect()연산은 모든 데이터를 드라이버 메모리로 가져오므로 대규모 데이터셋의 경우 메모리 부족 문제가 발생할 수 있음.
해결 방안
-
메모리 증가: 드라이버와 실행기의 메모리를 증가시켜 문제를 해결할 수 있음.
spark = SparkSession \ .builder \ .master("local[3]") \ .appName("Spark Driver OOM Demo") \ .config("spark.driver.memory", "4g") \ .config("spark.executor.memory", "4g") \ .getOrCreate() -
데이터 처리를 분산시킴:
collect()대신 다른 방식으로 데이터를 처리하여 메모리 부담을 줄임.df = spark.range(100000000) df.write.csv("/path/to/output") -
필요한 데이터만 수집: 필요한 데이터만 필터링하여 수집함.
filtered_df = df.filter(df.id < 1000) d = filtered_df.collect()
이를 통해 메모리 부족 문제를 해결하고 대규모 데이터셋도 효율적으로 처리할 수 있음.
Spark memory issue (OOM) - Executor
- Executor OOM
- 너무 큰 executor.cores 값
- high concurrency
- Data Skew (Big Partition)
- 즉 너무 병렬성을 높이려고 코어를 마구잡이로 높이면 안됨.
- 너무 큰 executor.cores 값
