Spark ML
Spark ML 소개
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- Classification, Regression, Clustering, Collaborative Filtering, Dimensionality
Reduction - 딥러닝 지원은 아직 미약
- Classification, Regression, Clustering, Collaborative Filtering, Dimensionality
spark.mllibvsspark.mlspark.mllib가 RDD 기반이고,spark.ml은 데이터프레임 기반spark.mllib는 RDD 위에서 동작하는 이전 라이브러리로 더 이상 업데이트 안됨
- 항상
spark.ml을 사용할 것import pyspark.ml
Spark ML의 장점
- 원스톱 ML 프레임 워크
- 데이터프레임과 SparkSQL등을 이용해 전처리
- spark MLlib를 이용해 모델 빌딩
- ML Pipeline을 통해 모데 빌딩 자동화
- MLflow로 모델 관리하고 서빙
- 대용량 데이터도 처리 가능
MLflow
- 모델 개발과 테스트와 관리와 서빙까지 제공해주는 end to end 프레임 워크
- 파이썬,자바,R,API 지원
- tracking,models,project를 지원
실습 : 머신러닝 모델 만들기
보스턴 주택가격 예측 : Regression
사전 정보
- 1970년 대 미국 인구조사 서비스엣 ㅓ보스턴 지역의 주택 가격 데이터를 수집한 데이터를 기반으로 모델 빌딩
train set info
https://docs.google.com/spreadsheets/d/1OYWPijmIhvVpvbSA-79DlInydidPrbfynfbsbINXmKw/edit?gid=880912933#gid=880912933
- 총 506개의 레코드로 구성, 13개의 feature와 필드
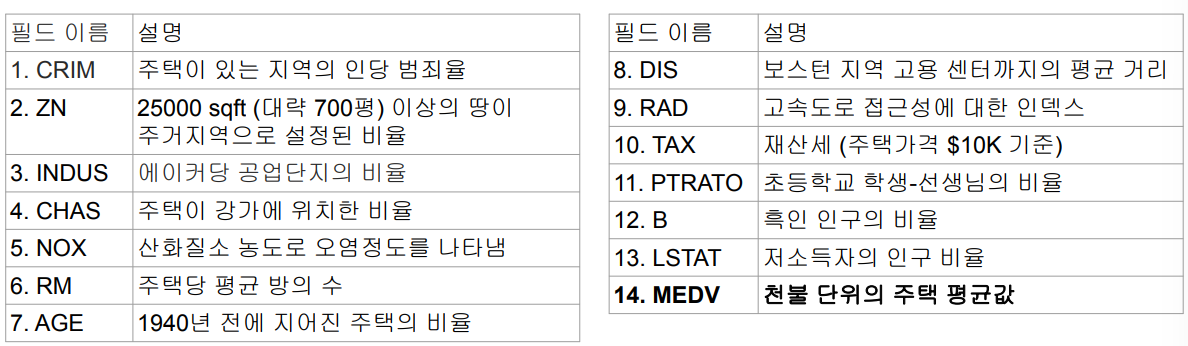
- 14번째 필드가 예측해야하는 중간 주택 가격.
순서
Regression사용- 연속적인 주택가격을 예측이기에 Classification 사용불가.
이 코드는 Google Colab에서 PySpark를 사용하여 보스턴 주택 가격 예측 모델을 구축하는 과정을 다루고 있음. 각 셀에서 수행되는 작업을 단계별로 요약하면 다음과 같음.
1. PySpark 및 Py4J 설치
!pip install pyspark==3.3.1 py4j==0.10.9.5PySpark와 Py4J 패키지를 설치함. Py4J는 Python에서 Java 객체에 접근할 수 있게 해줌.
2. SparkSession 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Boston Housing Linear Regression example") \
.getOrCreate()SparkSession 객체를 생성하여 SparkContext를 초기화하고 애플리케이션 이름을 지정함.
3. 데이터 다운로드 및 읽기
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/boston_housing.csv
data = spark.read.csv('./boston_housing.csv', header=True, inferSchema=True)
data.printSchema()
data.show()데이터셋을 다운로드하고 Spark DataFrame으로 읽어들임. 스키마와 데이터를 출력함.
4. 피쳐 벡터 생성
from pyspark.ml.feature import VectorAssembler
feature_columns = data.columns[:-1]
assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")
data_2 = assembler.transform(data)
data_2.show()VectorAssembler를 사용하여 피쳐 벡터를 생성함. features라는 컬럼에 모든 피쳐를 묶음.
5. 데이터 분할 및 모델 학습
train, test = data_2.randomSplit([0.7, 0.3])
from pyspark.ml.regression import LinearRegression
algo = LinearRegression(featuresCol="features", labelCol="medv")
model = algo.fit(train)데이터를 훈련용과 테스트용으로 분할하고, Linear Regression 모델을 학습시킴.
6. 모델 평가
evaluation_summary = model.evaluate(test)
evaluation_summary.meanAbsoluteError
evaluation_summary.rootMeanSquaredError
evaluation_summary.r2모델을 평가하고, Mean Absolute Error, Root Mean Squared Error, R-squared 값을 출력함.
7. 모델 예측 및 저장
predictions = model.transform(test)
predictions.show()
model.save("boston_housing_model")테스트 데이터에 대한 예측을 수행하고, 결과를 출력함. 모델을 저장함.
8. 모델 로드 및 재평가
from google.colab import drive
drive.mount('/content/gdrive')
model_save_name = "boston_housing_model"
path = F"/content/gdrive/My Drive/boston_housing_model"
model.save(path)
from pyspark.ml.regression import LinearRegressionModel
loaded_model = LinearRegressionModel.load(path)
predictions2 = loaded_model.transform(test)
predictions2.show()Google Drive에 모델을 저장하고, 저장된 모델을 다시 로드하여 테스트 데이터에 대한 예측을 수행함.
최종 요약
이 코드 셀들은 PySpark를 사용하여 보스턴 주택 가격 예측 모델을 구축하는 전 과정을 보여줌. 데이터 다운로드, 전처리, 모델 학습 및 평가, 모델 저장 및 로드 단계를 포함함. Google Colab 환경에서 실행되도록 구성되어 있음.
타이타닉 승객 생존 예측 : Classification
사전 정보
- 머신러닝의 hello world급의 유명한 data set
- 생존 혹은 비생존을 예측.
- True Positive Rate와 False Positive Rate 계산. (생존한 경우, 얼마나 맞게 예측했는지, 생존하지 못한 경우 얼마나 생존한다고 얼마나 예측했는지)
train set info
https://www.kaggle.com/c/titanic/data

이 코드는 Google Colab에서 PySpark를 사용하여 타이타닉 생존 예측 모델을 구축하는 과정을 다루고 있음. 각 셀에서 수행되는 작업을 단계별로 요약하면 다음과 같음.
1. PySpark 및 Py4J 설치
!pip install pyspark==3.3.1 py4j==0.10.9.5PySpark와 Py4J 패키지를 설치함. Py4J는 Python에서 Java 객체에 접근할 수 있게 해줌.
2. SparkSession 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Titanic Binary Classification example") \
.getOrCreate()SparkSession 객체를 생성하여 SparkContext를 초기화하고 애플리케이션 이름을 지정함.
3. 데이터 다운로드 및 읽기
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/titanic.csv
data = spark.read.csv('./titanic.csv', header=True, inferSchema=True)
data.printSchema()
data.show()데이터셋을 다운로드하고 Spark DataFrame으로 읽어들임. 스키마와 데이터를 출력함.
4. 데이터 클린업
final_data = data.select(['Survived', 'Pclass', 'Gender', 'Age', 'SibSp', 'Parch', 'Fare'])
final_data.show()사용하지 않을 컬럼을 제거하고 필요한 컬럼만 선택함.
5. 결측치 처리
from pyspark.ml.feature import Imputer
imputer = Imputer(strategy='mean', inputCols=['Age'], outputCols=['AgeImputed'])
imputer_model = imputer.fit(final_data)
final_data = imputer_model.transform(final_data)
final_data.select("Age", "AgeImputed").show()Imputer를 사용하여 Age 컬럼의 결측치를 평균값으로 대체함.
6. 성별 정보 인코딩
from pyspark.ml.feature import StringIndexer
gender_indexer = StringIndexer(inputCol='Gender', outputCol='GenderIndexed')
gender_indexer_model = gender_indexer.fit(final_data)
final_data = gender_indexer_model.transform(final_data)
final_data.select("Gender", "GenderIndexed").show()StringIndexer를 사용하여 성별을 숫자로 인코딩함.
7. 피쳐 벡터 생성
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=['Pclass', 'SibSp', 'Parch', 'Fare', 'AgeImputed', 'GenderIndexed'], outputCol='features')
data_vec = assembler.transform(final_data)
data_vec.show()VectorAssembler를 사용하여 피쳐 벡터를 생성함. features라는 컬럼에 모든 피쳐를 묶음.
8. 데이터 분할 및 모델 학습
train, test = data_vec.randomSplit([0.7, 0.3])
from pyspark.ml.classification import LogisticRegression
algo = LogisticRegression(featuresCol="features", labelCol="Survived")
model = algo.fit(train)데이터를 훈련용과 테스트용으로 분할하고, Logistic Regression 모델을 학습시킴.
9. 모델 평가
predictions = model.transform(test)
predictions.select(['Survived','prediction', 'probability']).show()테스트 데이터에 대한 예측을 수행하고, 결과를 출력함.
10. 모델 성능 측정
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(labelCol='Survived', metricName='areaUnderROC')
evaluator.evaluate(predictions)BinaryClassificationEvaluator를 사용하여 모델 성능을 평가함. Area Under ROC 값을 출력함.
최종 요약
이 코드 셀들은 PySpark를 사용하여 타이타닉 생존 예측 모델을 구축하는 전 과정을 보여줌. 데이터 다운로드, 전처리, 모델 학습 및 평가 단계를 포함함. Google Colab 환경에서 실행되도록 구성되어 있음.
SparkML Pipeline
- 모델빌딩과 테스트 과정을
관련 문제
- 트레이닝 셋의 관리가 잘 안됨.
- 모델 훈련 방법이 기록이 안됨
- 어떤 트레이닝 셋, 피쳐, 하이퍼 파라미터를 사용했는지?
- 모델 훈련에 많은 시간 소요
- 모델 훈련이 자동화가 안된 경우 매 스텝을 일일히 수행해야함
- 에러 발생할 여지가 많음
ML Pipeline
- 자동화를 통해 에러 소지를 줄이고 반복을 빠르게 가능하게 해줌
개념
-
머신러닝 알고리즘에 관계없이 일관된 형태의 API를 사용하여 모델링이 가능
-
ML 모델개발과 테스트를 반복가능해줌
- Transformer와 Estimator로 구성
-
4개의 요소로 구성
-
dataframe : 데이터 저장 구조
-
Transformer : DF를 입력받아 변환된 DF 반환 객체
-
Estimator : DF를 입력받아 학습된 모델을 반환. 예를 들어 LogisiticRegression은 Estimator이고, LogisticRegression.fit()를 호출하면, 머신 러닝 모델(Transformer)을 만들어냄
-
Parameter : 2와 3의 설정값.
-
이제 PySpark에서 ML Pipeline을 사용할 때 중요한 구성 요소인 DataFrame, Transformer, Estimator, Parameter에 대해 설명하겠음. 위에서 작성한 코드를 이러한 구성 요소를 사용하여 다시 작성해보겠음.
ML Pipeline 구성 요소
- DataFrame: 데이터를 저장하는 구조.
- Transformer: DataFrame을 입력받아 변환된 DataFrame을 반환하는 객체. 예: StringIndexer, VectorAssembler.
- Estimator: DataFrame을 입력받아 학습된 모델을 반환하는 객체. 예: LogisticRegression.
- Parameter: Transformer와 Estimator의 설정값을 의미.
ML pipeline - 타이타닉
아래는 위의 구성 요소를 사용하여 타이타닉 생존 예측 모델을 ML Pipeline으로 구현한 코드임.
# 필요한 라이브러리 설치
!pip install pyspark==3.3.1 py4j==0.10.9.5
# SparkSession 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Titanic Binary Classification Pipeline") \
.getOrCreate()
# 데이터 다운로드 및 읽기
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/titanic.csv
data = spark.read.csv('./titanic.csv', header=True, inferSchema=True)
# 데이터 클린업
final_data = data.select(['Survived', 'Pclass', 'Gender', 'Age', 'SibSp', 'Parch', 'Fare'])
# 결측치 처리
from pyspark.ml.feature import Imputer
imputer = Imputer(strategy='mean', inputCols=['Age'], outputCols=['AgeImputed'])
# 성별 정보 인코딩
from pyspark.ml.feature import StringIndexer
gender_indexer = StringIndexer(inputCol='Gender', outputCol='GenderIndexed')
# 피쳐 벡터 생성
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=['Pclass', 'SibSp', 'Parch', 'Fare', 'AgeImputed', 'GenderIndexed'], outputCol='features')
# Logistic Regression 모델
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol="features", labelCol="Survived")
# Pipeline 생성
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[imputer, gender_indexer, assembler, lr])
# 데이터 분할
train, test = final_data.randomSplit([0.7, 0.3])
# 모델 학습
model = pipeline.fit(train)
# 예측 수행
predictions = model.transform(test)
# 모델 성능 평가
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(labelCol='Survived', metricName='areaUnderROC')
auc = evaluator.evaluate(predictions)
print(f"Area Under ROC: {auc}")
# 예측 결과 출력
predictions.select(['Survived','prediction', 'probability']).show()구성 요소 설명
-
DataFrame:
data = spark.read.csv('./titanic.csv', header=True, inferSchema=True) final_data = data.select(['Survived', 'Pclass', 'Gender', 'Age', 'SibSp', 'Parch', 'Fare'])데이터를 로드하고 필요한 컬럼만 선택하여 DataFrame을 만듦.
-
Transformer:
-
Imputer:
from pyspark.ml.feature import Imputer imputer = Imputer(strategy='mean', inputCols=['Age'], outputCols=['AgeImputed'])Age 컬럼의 결측치를 평균값으로 대체하는 Transformer.
-
StringIndexer:
from pyspark.ml.feature import StringIndexer gender_indexer = StringIndexer(inputCol='Gender', outputCol='GenderIndexed')Gender 컬럼을 숫자로 인코딩하는 Transformer.
-
VectorAssembler:
from pyspark.ml.feature import VectorAssembler assembler = VectorAssembler(inputCols=['Pclass', 'SibSp', 'Parch', 'Fare', 'AgeImputed', 'GenderIndexed'], outputCol='features')여러 피처 컬럼을 하나의 벡터로 결합하는 Transformer.
-
-
Estimator:
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="features", labelCol="Survived")Logistic Regression 모델을 정의하는 Estimator.
-
Pipeline:
from pyspark.ml import Pipeline pipeline = Pipeline(stages=[imputer, gender_indexer, assembler, lr])Transformer와 Estimator를 연결하여 하나의 Pipeline을 만듦.
-
Parameter:
각 Transformer와 Estimator에는 설정값을 지정하는 Parameter가 있음. 예를 들어, Imputer의strategy파라미터, StringIndexer의inputCol및outputCol파라미터, VectorAssembler의inputCols및outputCol파라미터, LogisticRegression의featuresCol및labelCol파라미터 등이 있음.
이 코드는 PySpark를 사용하여 데이터 전처리, 피처 변환, 모델 학습 및 평가를 ML Pipeline을 통해 자동화한 예시임. DataFrame, Transformer, Estimator, Parameter를 사용하여 구성됨.
Spark EMR 론치
- AWS Spark 클러스터 론치
- AWS Spark 클러스터 상에서 Pyspark 잡 실행
AWS에서 spark를 실행하려면?
- EMR(Elastic MapReduce) 위에서 실행하는 것이 일반적.
- EMR은 hadoop 서비스.
- EC2 서버들을 worker node로 사용하고 S3를 HDFS로 사용
- AWS 내의 다른 서비스들과 연동이 쉬움
Spark on EMR 실행 및 사용 과정
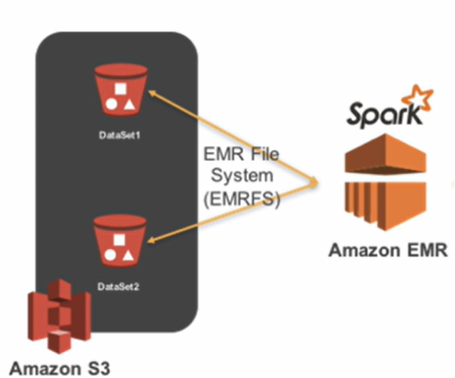
- AWS의 EMR 클러스터 생성
- EMR 생성시 Spark을 실행(옵션으로 선택)
- S3를 기본 파일 시스템으로 사용
- EMR의 마스터 노드를 드라이버 노드로 사용
- 마스터 노드를 SSH로 로그인
- spark-submit를 사용
- Spark Cluster 모드에 해당
- 마스터 노드를 SSH로 로그인

- Spark 클러스터 매니저와 실행 모델 요약
step 1
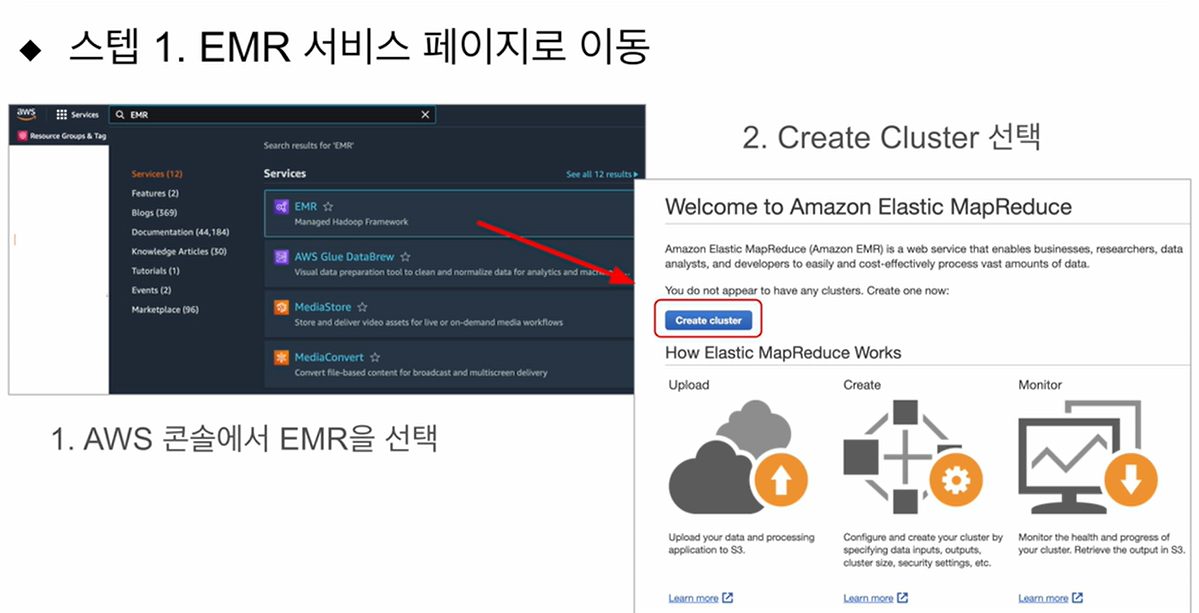
step 2
- EMR 클러스터 생성하기, 이름과 기술 스택 선택
- cluster name 적당히 지정
- software configuration
- spark에 들어갈 옵션 선택
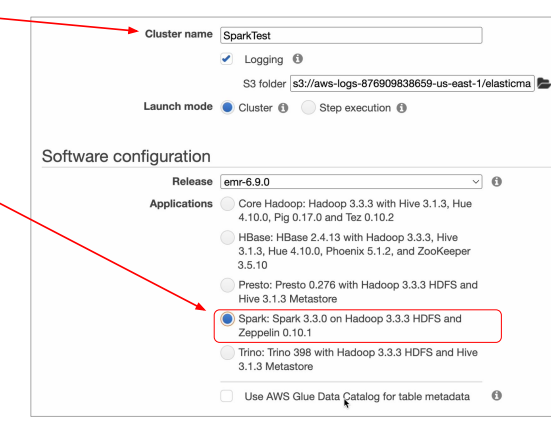
step 3
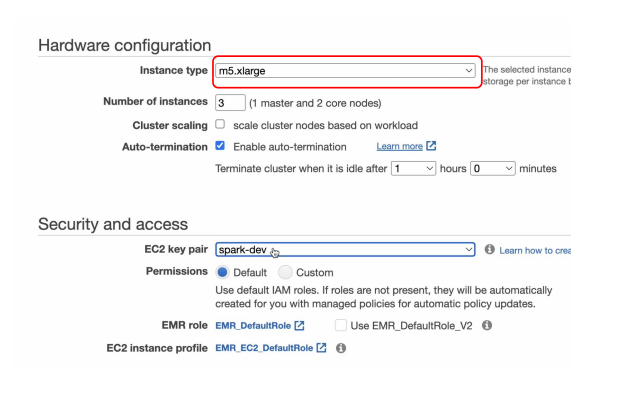
- EMR 클러스터 생성하기 - 클러스터 사양 선택 후 생성
- m5.xlarge 노드 3개 선택 -> 하루 35달러 비용 발생
- 4 CPU x2 , 16 GB x2
- create Cluster
step 4
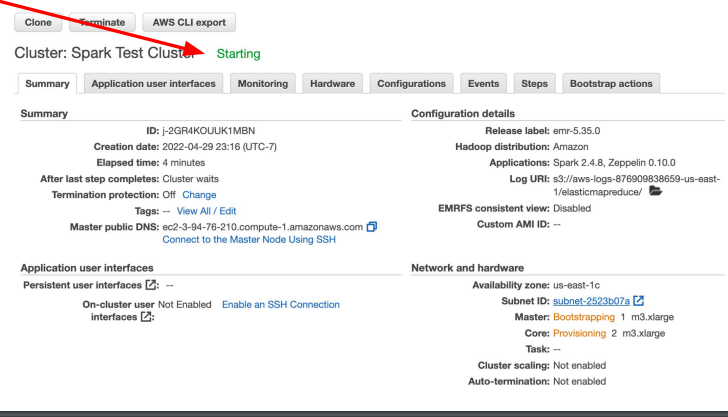
- cluster가 waiting 으로 변할 때 까지 대기
step 5
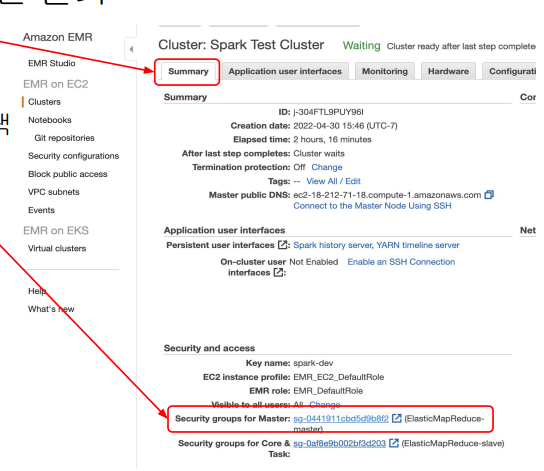
-
EMR 클러스터 summary 탭 선택
-
Security groups for master 링크 선택
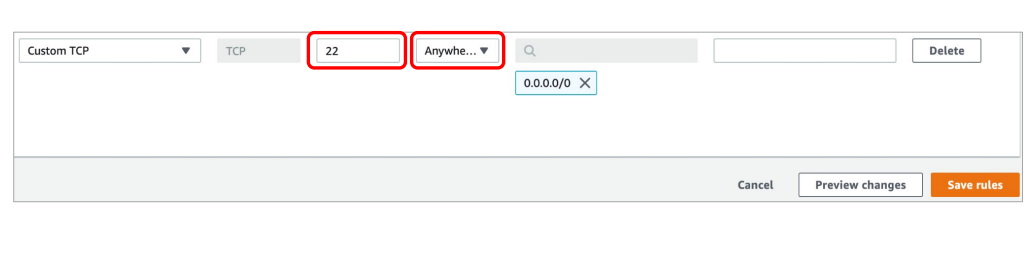
-
Security Group 페이지에서 마스터 노드의 security gorup id를 클릭
-
edit inbound rules에서 포트번호22 오픈
AWS spark 클러스터 상에서 PySpark 잡 실행
시작
- Spark master node에서 ssh로 로그인
- 이를 위해 마스터노드의 TCP port number 22번을 오픈
- spark-submit을 이용해서 실행하면서 디버깅
- 2개의 job을 aws emr 상에서 실행해볼 예정
- csv 파일을 s3 버킷으로 업로드
PySpark 잡 실행
- spark 마스터 노드에 ssh로 로그인하여 spark-submit을 통해 실행
- 앞서 다운로드 받은 .pem 파일을 ㅏㅅ용하여 ssh 로그인
spark-submit --master yarn python_file.py

