Unity에서 배열이 아니라 동적으로 자료를 저장하고 싶을 때 가장 대표적으로 사용한게 바로 list이다. 그래서 코드를 정말 쉽게 사용할 수 있었는데 C++에서도 STL에서 list를 지원하니 이 부분을 알아보려 한다.
List란?
STL에서 지원하는 list는 이중 연결 리스트(doubly linked list) 구조와 동일하다. 여기서 list는 다음과 같은 특징을 가진다.
- 데이터 삽입 / 삭제가 용이
연결 리스트의 특성상 노드를 삽입하거나 삭제할 때 해당 노드의 앞뒤 노드의 연결만 수정하면 되므로 효율적이다.
시간복잡도 : O(1);- 가변적 길이
list는 초기 크기가 고정되지 않고, 필요에 따라 크기를 자유롭게 늘리거나 줄일 수 있다.- 양방향 반복자를 제공한다.
반복자를 사용하여 양방향으로 원소를 탐색할 수 있다.
어찌 보면 이 부분이 가장 핵심적이고 반복자를 통해 원소를 접근하기 때문에 꼭 알아두자.
(iterator는 리스트의 핵심이라고 봐도 무방하니 꼭 외워두도록 하자.)
iterator
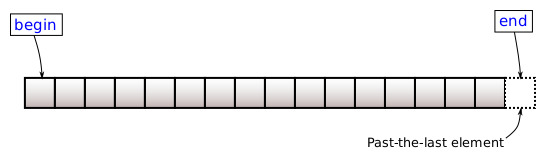
이 부분은 리스트를 사용하기 위해 반드시 외우고 가도록 해야 한다. 먼저 사진처럼 begin은 list의 첫 번째 원소의 위치를 나타내고 end는 list 마지막 다음 위치를 나타낸다.
예시로 문제를 냈는데 다음 결과를 예상해 보자.
- insert(iterator, Data) : iterator가 가리키는 위치에 Data를 삽입
- erase(iterator) : iterator가 가리키는 위치에 Data를 삭제
- auto : 데이터 타입 자동 맞춤
1.
list<char> ls; auto iter = ls.end(); ls.insert(iter, 'A'); ls.insert(iter, 'B'); ls.insert(iter, 'C'); for(auto i : ls) cout << i;2.
list<char> ls; auto iter = ls.end(); ls.insert(iter, 'A'); ls.erase(iter); ls.insert(iter, 'C'); for(auto i : ls) cout << i;
결과
- 출력 : ABC
- 1번은 출력이 왜 ABC인가? 간단하게 정리하자면 iter은 list의 마지막 원소의 뒤(다음)를 가리킨다. 그러나 처음에는 원소가 비어 있으므로 list의 처음과 마지막 위치는 동일하다.
(연결 리스트 특성을 생각해보자, head와 tail은 결국 처음에 원소가 비어 있으면 같은 위치를 가리킨다. 동일한 원리이다)
- ls.insert(iter, 'A'): A가 리스트에 추가되고, begin과 end가 수정된다.
- 리스트 상태: [A] (begin: A, end: A 다음 위치)
- ls.insert(iter, 'B'): iter는 여전히 A 다음 위치를 가리키므로, B는 리스트 끝에 삽입된다.
- 리스트 상태: [A, B] (begin: A, end: B 다음 위치)
- ls.insert(iter, 'C'): 동일한 원리로, C가 끝에 추가된다.
- 최종 리스트: [A, B, C]
여기서 중요한 점은 insert를 한다고 해서 iterator 수정되는게 아니다. 처음에는 list가 비어있으므로 begin == end였지만 지금은 A가 들어옴으로써 list의 begin과 end가 수정된다.
마찬가지로 insert(iter, 'B')를 진행해도 iter는 A의 다음이니 list : [A , B]가 되는 것이다. 여기서도 결국 begin = A 원소 위치, end = B 원소 다음 위치가 되므로 C도 동일하게 적용되어 출력이 ABC가 되는 것이다.
- 런타임 에러 발생
- 2번은 런타임 에러가 발생하였다 왜일까? 답은 의외로 간단하다. 범위를 넘어갔기 때문이다.
- ls.insert(iter, 'A'): A가 리스트에 추가되고, begin과 end가 수정된다.
- 리스트 상태: [A] (begin: A, end: A 다음 위치)
- ls.erase(iter) : iter는 A 다음 위치이지만 A 다음 위치엔 들어온 원소가 없으므로 런타임 에러 발생.
결국 A 다음 원소 위치에는 현재 원소가 존재하지 않으므로 iter가 찾아갈 수 없어 생기는 오류인 것이다. 그러면 어떻게 수정해야할까?
ls.erase(iter) → iter = ls.erase(--iter);로 수정하면 된다.
내용이 조금 많이 어려웠다. 그래도 iterator에 대해 공부하게 되어 list를 사용할 때 도움이 많이 될 것 같다.
iterator 순환?
문제를 풀면서 신기한 부분을 발견했다. 바로 iterator의 순환되는 부분이다.
#include <bits/stdc++.h>
using namespace std;
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
list<char> ls;
auto iter = ls.end();
ls.insert(iter, 'A');
iter--;
iter--;
ls.insert(iter, 'B');
ls.insert(iter, 'C');
iter++;
ls.insert(iter, 'D');
ls.insert(iter, 'E');
for(auto i : ls) cout << i;
return 0;
}출력 : DEABC
이 코드의 결과는 조금 충격적이었다. 위에서 정리한 내용을 바탕으로 문뜩 든 생각은 begin과 end를 지정하는 iterator는 이해했다 그러면 iterator가 begin보다 더 앞으로 가면 어떻게 될까? 라는 생각이 문뜩 들었다. 즉 begin = 맨 앞의 원소보다도 더 앞으로 간다면? 오류가 뜰까 아니면 색다른 결과를 나타낼까?
답은 위와 같이 다시 돌아온다고 봐도 될듯하다.
- A insert → list ['A'] / iter : 'A'의 다음 위치
- iter-- → iter : 'A'의 위치
- iter-- → iter : 'A'의 앞의 위치 → 'A'가 맨 앞임으로 맨 뒤로 이동
- 생략...
다시 공부해보니 이 부분은 begin()을 넘어가므로 정의되지 않은 영역 UV라고 한다. 이 부분은 라이브러리에서 보장된 정의가 아니므로 안전한 코드가 아니라고한다.
List의 장단점
장점 :
- 데이터 삽입 / 삭제가 용이함 (시간복잡도 : O(1))
- 연속적인 메모리를 가지는게 아니므로 빈번한 삽입 / 삭제에서 vector보다 용이
- 양방향 반복자를 이용하여 양쪽 방향 순회 가능
단점 :
- 메모리가 연속적이지 않아 중간 데이터 접근이 비교적 느림
- 노드의 포인터를 가지므로 메모리가 vector보다 많이 필요
사용법
- list.begin() : 첫 번째 원소 위치
- list.end() : 마지막 원소의 다음 위치
- list.insert(iterator, data) : iterator가 가르키는 위치에 data를 삽입 및 해당 iterator를 반환
- list.erase(iterator) : iterator가 가르키는 위치에 d원소를 삭제 및 해당 iterator를 반환
- *iterator : iterator가 가르키는 원소를 반환
- list.front() : 맨 앞의 원소를 반환
- list.back() : 맨 뒤 원소를 반환
- list.push_front(data) : 맨 앞에 원소를 추가
- list.push_back(data) : 맨 뒤에 원소를 추가
- list.pop_front() : 맨 앞에 원소를 제거
- list.pop_back() : 맨 뒤에 원소를 제거
우선 기본적인 명령어는 이 정도만 알아두도록 하고 필요하면 더 정리해 보도록 하자.
Reference
[C++] std::iterator, 왜 사용할까? - SCRIPTS BY
