1. 개요
이 글에서는 언어 모델의 대표적인 튜닝 방식인 SFT(Supervised Fine-Tuning)와 DPO(Direct Preference Optimization)를 비교합니다. 두 방식 모두 모델을 특정 작업에 맞춰 정렬(alignment)시키는 데 사용되며, 공정한 비교를 위해 동일한 훈련 환경과 태스크를 구성했습니다. 훈련 목적은 주어진 키워드를 반드시 포함한 문학적인 문장 생성입니다.
2. 배경
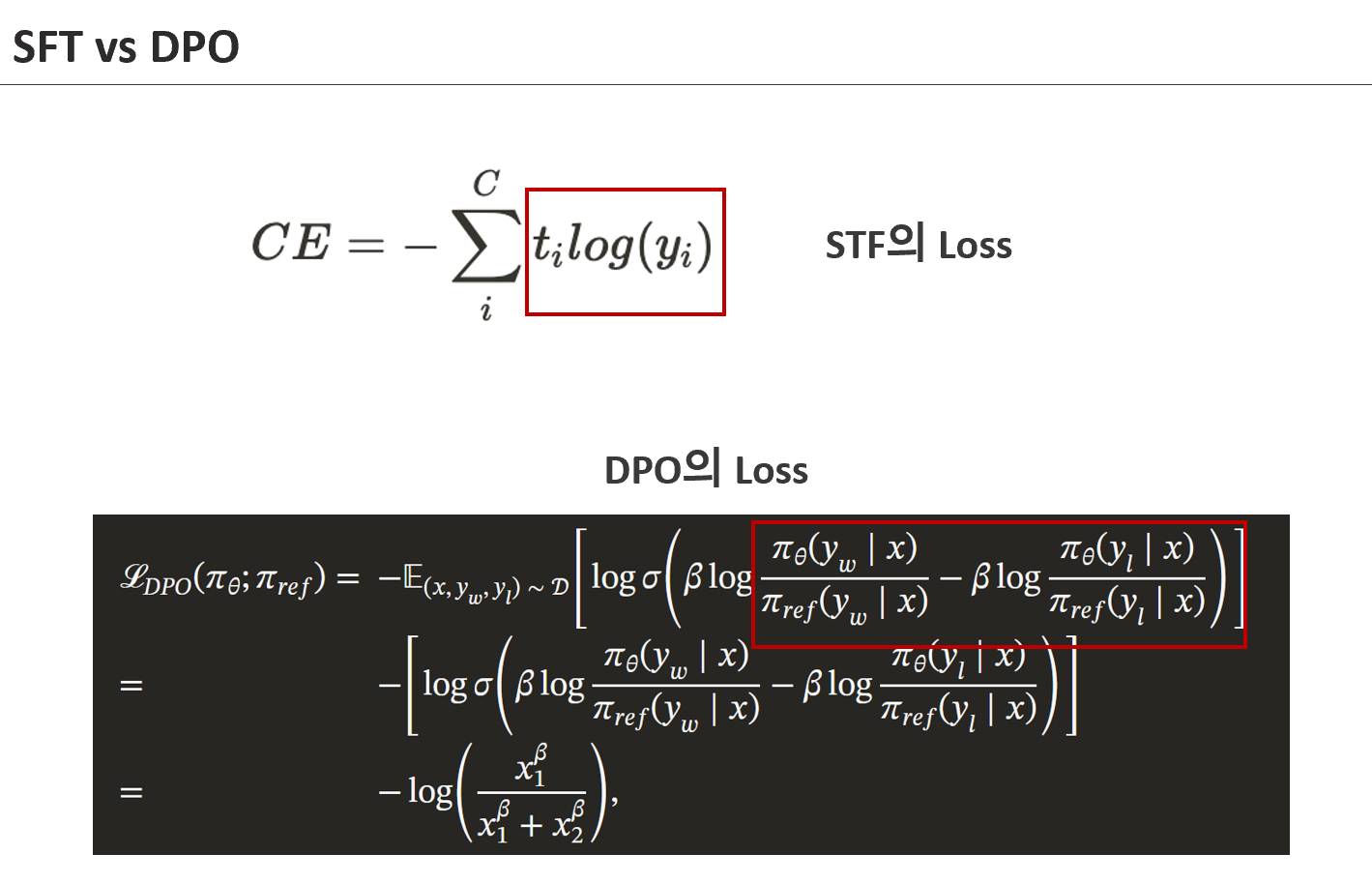
SFT와 DPO는 모두 언어 모델을 훈련하는 방식이라는 점에서 공통점을 갖습니다. Hugging Face의 공식 문서(링크)에서는 이 두 방식에 대한 개념과 코드 예시뿐 아니라, Chain-of-Thought, 분류기 훈련법, 프리트레이닝(pretraining) 같은 다양한 기법도 소개하고 있습니다. 그러나 본문에서는 SFT와 DPO에 집중하여 비교합니다.
2.1 Instruction 이란
SFT와 DPO는 사전학습(pretraining)이 완료된 모델을 특정 명령(instruction) 에 맞춰 조정하는 Instruction Tuning 방법입니다. 일반적인 open LLM은 다양한 언어에 대해 학습되어 있지만, 사용자가 원하는 특정 태스크에 대해서는 정렬되지 않은 경우가 많습니다. 따라서 명령의 의도와 목적을 모델에 주입하기 위해 SFT나 DPO 같은 튜닝 기법이 필요합니다.
2.2 SFT의 맹점: 정답이 하나일 때만 강하다
위의 이미지처럼 모델 이름 뒤에 -it이 붙어 있는 경우, 이는 Instruction Tuning이 적용되었다는 의미입니다. Instruction Tuning은 사전학습(pretraining)이 완료된 언어 모델에 특정 태스크 수행 능력을 부여하는 작업이며, SFT(Supervised Fine-Tuning)는 그 대표적인 방식입니다.
하지만 SFT에는 근본적인 한계가 있습니다. SFT는 하나의 입력(input)에 대해 단 하나의 정답(output)을 학습하도록 설계되어 있습니다. 문제는 실제 세계의 태스크 중 상당수는 정답이 하나가 아니며, 다양한 표현이 가능하다는 점입니다.
예를 들어 “주어진 키워드를 반드시 포함해 문학적인 문장을 생성하라”는 instruction을 생각해 봅시다. 이 경우 정답은 하나가 아니라 수십 가지가 될 수 있습니다. 하지만 SFT는 이 중 오직 하나만을 정답으로 보고, 나머지를 모두 틀린 것으로 간주하며 학습합니다. 결과적으로 모델이 자연스럽고 다양한 응답을 학습하기보다는 정답만 따라 하려는 경향이 생기고, 이는 오히려 성능 저하로 이어질 수 있습니다.

2.3 DPO의 접근: 정답이 아닌 선호를 학습한다
SFT가 단일한 정답을 강제로 학습시키는 방식이라면, DPO(Direct Preference Optimization)는 선호(preference) 를 중심으로 모델을 튜닝하는 접근입니다. 정답이 명확하지 않거나 표현의 다양성이 중요한 태스크라면, 하나의 응답을 정답으로 지정하는 것보다, 선호되는 응답과 덜 선호되는 응답을 구분해서 학습하는 편이 훨씬 효과적입니다.
DPO는 전통적인 강화학습(RL)처럼 별도의 보상 모델이나 정책(policy)을 학습하지 않아도 됩니다. 대신, 두 개의 응답(chosen, rejected)을 비교하는 방식으로 모델이 사용자 취향을 직접적으로 최적화할 수 있도록 합니다. 이러한 방식은 모델이 단순한 따라하기가 아닌, 어떤 응답이 더 자연스럽고 바람직한지를 구분하는 능력을 갖추도록 도와줍니다.
그래서 보통은 SFT와 DPO를 병행하여 학습합니다. SFT에서는 일반적인 작업 수행 능력을 부여하고 DPO에서는 사람의 선호도를 반영하여 보다 정교하고 자연스러운 응답을 생성하도록 만드는 것이죠.
3. 실험 계획
이번 실험은 SFT와 DPO가 정답이 하나로 고정되지 않은 생성 태스크에 어떻게 반응하는지를 비교하는 데 목적이 있습니다. 실험에 사용된 태스크는 특정 키워드를 입력으로 받아 해당 키워드를 반드시 포함한 문학적인 글 한 편을 생성하는 작업으로, 다양한 표현 방식이 가능한 것이 특징입니다. 이는 SFT처럼 단일 정답을 학습하는 방식보다, 선호 기반으로 학습하는 DPO가 더 적합할 수 있는 대표적인 상황입니다. 이러한 특성을 바탕으로, 동일한 데이터셋 구조와 조건에서 두 방식을 비교하기 위해 실험을 설계했습니다.
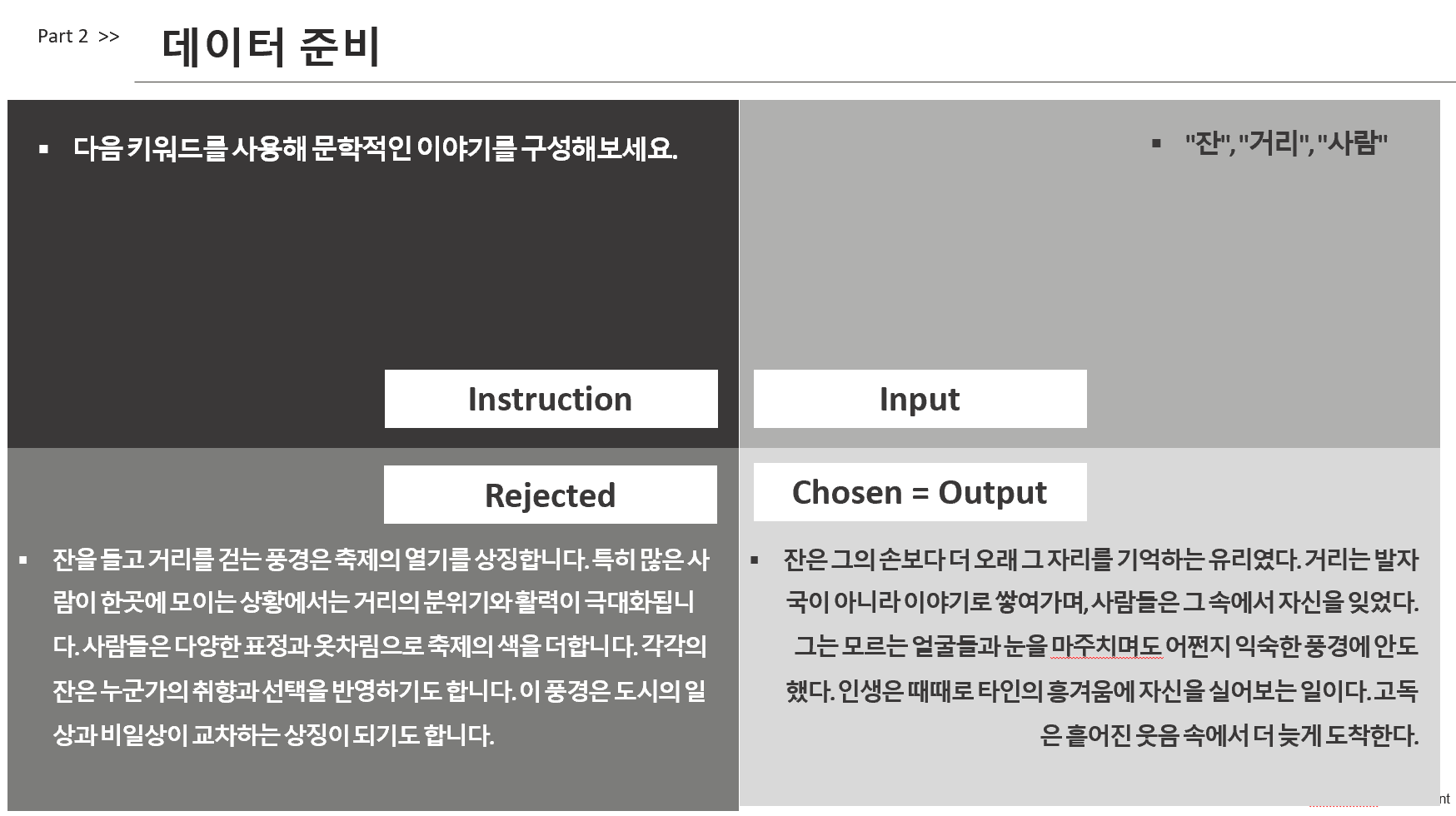
실험에는 Gemma 3:1B 모델을 사용하였으며, 전체 175개의 데이터 중 140개를 학습에, 35개를 검증에 활용하였습니다. 학습은 총 5 에폭(epoch)에 걸쳐 진행되었고, 배치 사이즈는 8로 설정했습니다. SFT 방식에는 input과 output으로 구성된 일반적인 튜닝 데이터를 사용하였고, DPO 방식에는 prompt, chosen, rejected의 형태로 선호 정보를 포함한 페어 데이터를 구성하여 학습을 진행하였습니다. 이로써 동일한 모델, 동일한 조건, 동일한 태스크 하에서 SFT와 DPO의 성능 차이를 비교할 수 있는 기반을 마련하였습니다.
참고: 훈련 로그
sft와 dpo로 훈련했을 때의 로그
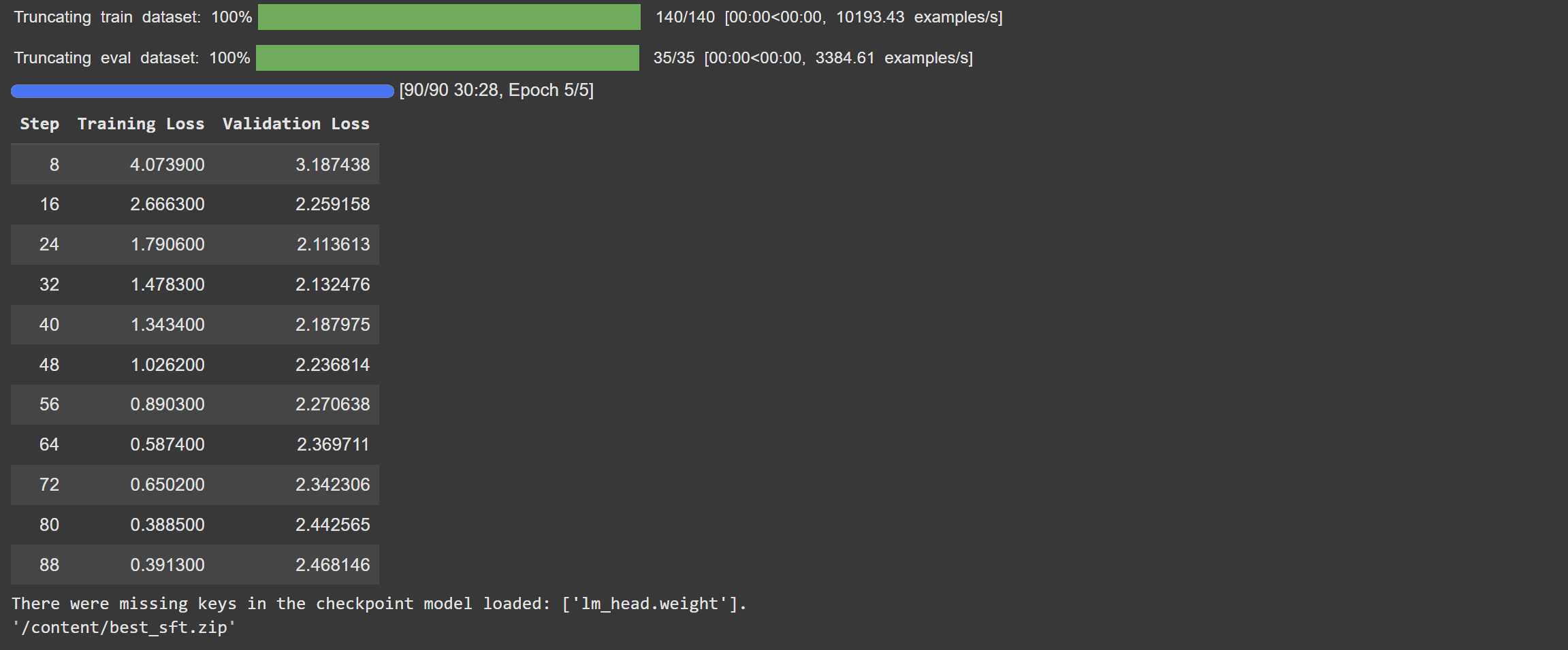
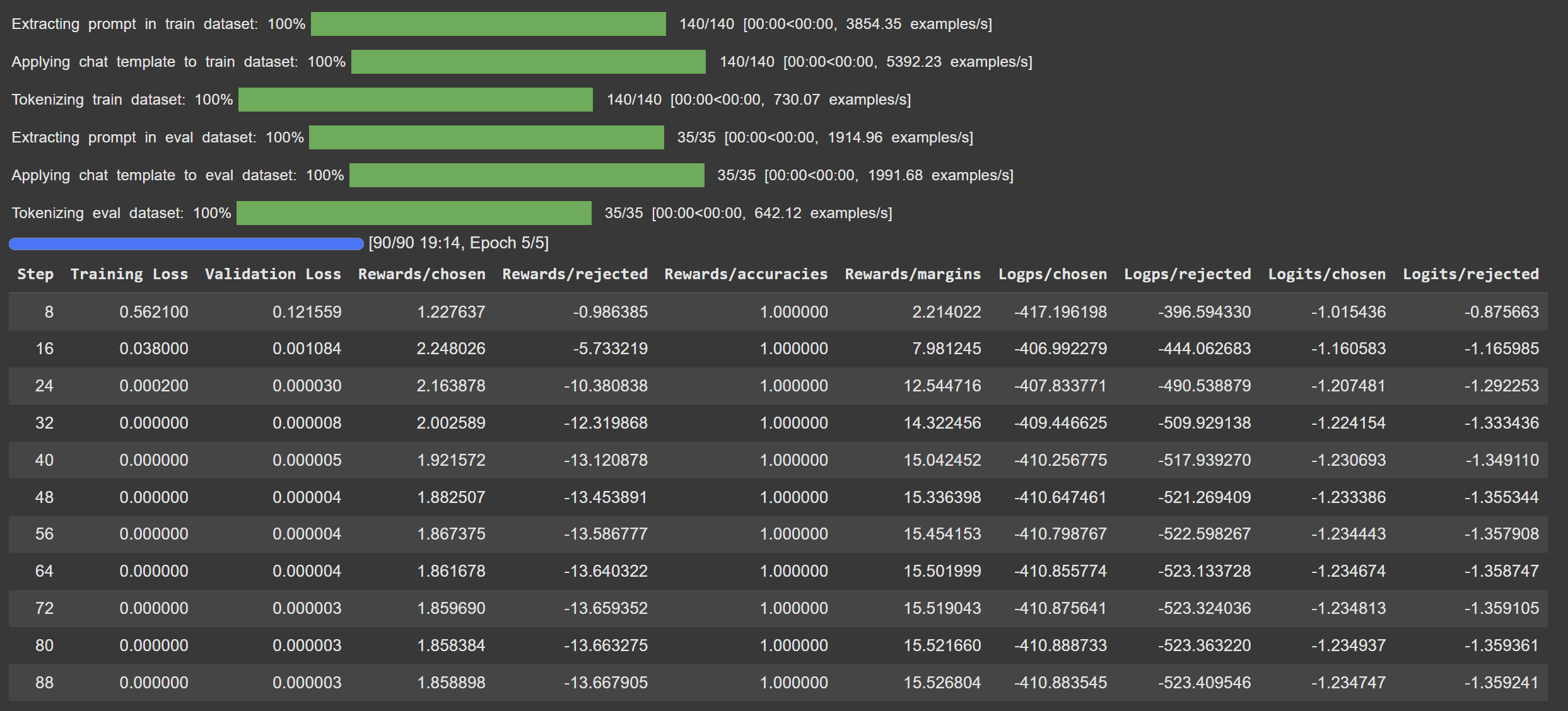
3.1 훈련 전 데이터
훈련 이전엔 이와 같은 데이터가 추론되었습니다.

실험 결과, 사용한 모델이 1B 파라미터 규모이다 보니 전체적으로 어색한 표현이 자주 등장했고, 주어진 세 단어를 유기적으로 통합하여 하나의 완결된 글로 구성하는 데에는 어려움이 있었습니다. 이는 저희가 기대한 “문학적인 한 편의 글”이라는 결과물의 형태와는 다소 거리가 있었습니다. 따라서 출력 결과가 원하는 형식에 얼마나 부합하는지를 중심으로, 훈련 효과를 분석해보았습니다.
3.2 훈련 후 데이터


정성적으로 비교했을 때, SFT와 DPO 간에는 학습 양상에서 뚜렷한 차이가 드러났습니다. SFT 모델은 학습이 거의 이루어지지 않아 같은 문장을 반복하는 현상, 즉 전형적인 악성 반복(mode collapse) 을 보였습니다. 이는 학습이 제대로 진행되지 않았다는 신호로 해석됩니다. 반면, DPO는 제한된 데이터와 짧은 학습 시간에도 불구하고 문학적 문체와 구성의 톤을 일정 부분 학습한 모습을 보였습니다. 아직 완성도는 부족하지만, 적어도 목표한 출력 형식에서 벗어나지 않으려는 경향이 확인되었습니다. 이는 DPO가 적은 학습량에서도 방향성 있는 튜닝이 가능함을 시사합니다.
4. 결론
이번 실험을 통해 SFT와 DPO는 동일한 조건과 동일한 모델, 동일한 태스크 하에서도 훈련 방식의 차이에 따라 매우 다른 결과를 유도한다는 사실을 확인할 수 있었습니다. 특히 정답이 하나로 수렴되지 않는 창작성 기반 태스크에서는, SFT는 표현 다양성을 포착하지 못하고 오히려 문장 반복 현상 등 학습 실패의 양상을 보인 반면, DPO는 제한된 자원에도 불구하고 사용자의 선호도를 반영하며 형식과 문체의 일관성을 유지하는 방향성 있는 출력을 생성했습니다.
이는 단순한 튜닝 기법 선택이 아닌, 태스크 특성에 맞는 훈련 전략의 선택이 필수적임을 시사합니다. 정형화된 답변이 요구되는 태스크에는 여전히 SFT가 효과적일 수 있지만, 창의성, 다양성, 사용자 선호가 중요한 태스크에서는 DPO가 더 나은 대안이 될 수 있습니다. 앞으로는 SFT를 기반으로 모델을 정렬한 뒤, 후속적으로 DPO를 적용하여 미세한 정렬과 자연스러움을 강화하는 하이브리드 방식이 더욱 일반화될 것으로 예상됩니다.
참고자료
1) DPO 훈련 코드: https://drive.google.com/file/d/1SK3tY_XnDfLBtxmgGnErL67KQONkGyus/view?usp=sharing
2) SFT 훈련 코드: https://drive.google.com/file/d/1JOomO7meDWxhtmPyT0rWkCughDj4yq7S/view?usp=sharing
3) 생성 데이터:
https://drive.google.com/file/d/1vce0jzN1R9iinUkDp2SosnsgilTEo1-s/view?usp=sharing
