플러스 AI 과정
1.[플러스 AI] 1. 배치 사이즈와 metric의 관계: BGD vs Mini-batch GD vs SGD
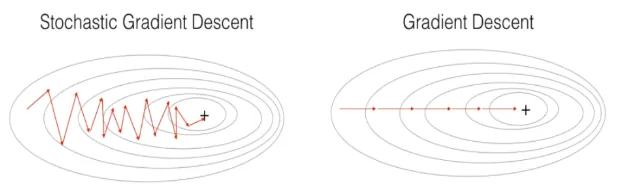
이번 글에서는 MNIST 손글씨 데이터를 선형 모델로 분류하면서, 학습 방식에 따라 성능이 어떻게 달라지는지를 실험합니다. 구체적으로는 Batch Gradient Descent, Stochastic Gradient Descent(SGD), Mini-Batch Gradi
2.[플러스 AI] 2. 트랜스포머 파라미터 수 계산하기
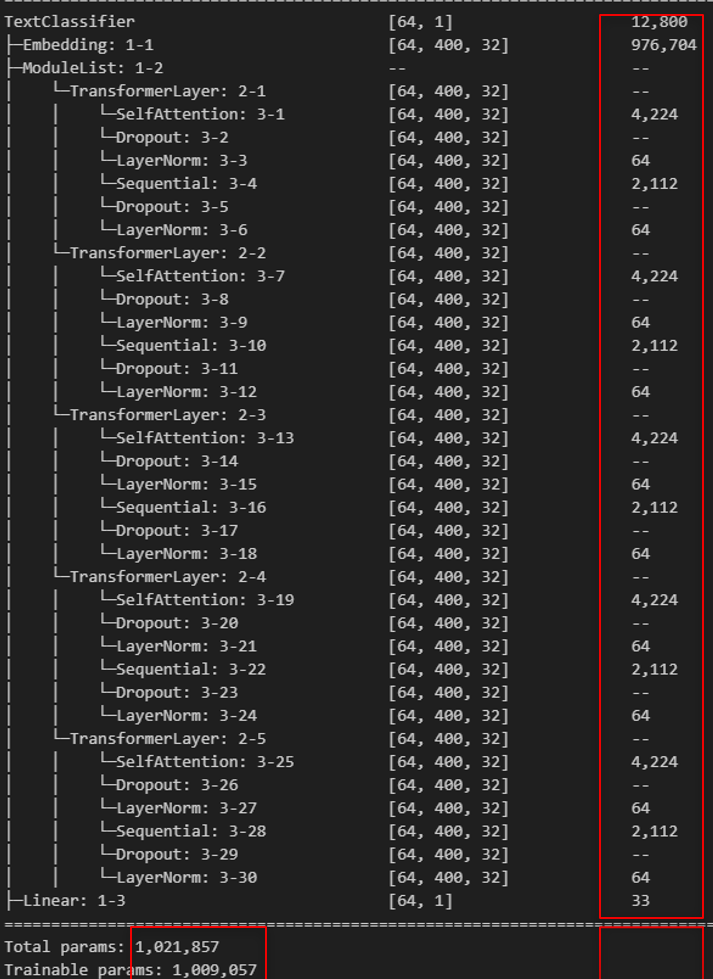
오늘은 Transformer 모델의 구조를 이해하기 위해, 실제로 각 레이어에서 발생하는 파라미터 수를 하나하나 계산해보는 시간을 가져보려고 합니다. 목표: 복잡한 트랜스포머 구조를 단순히 '이해'하는 것을 넘어, 실제로 어떤 층에서 몇 개의 파라미터가 발생하는지를
3.[플러스 AI] 3. Knowledge Distillation의 과거와 현재
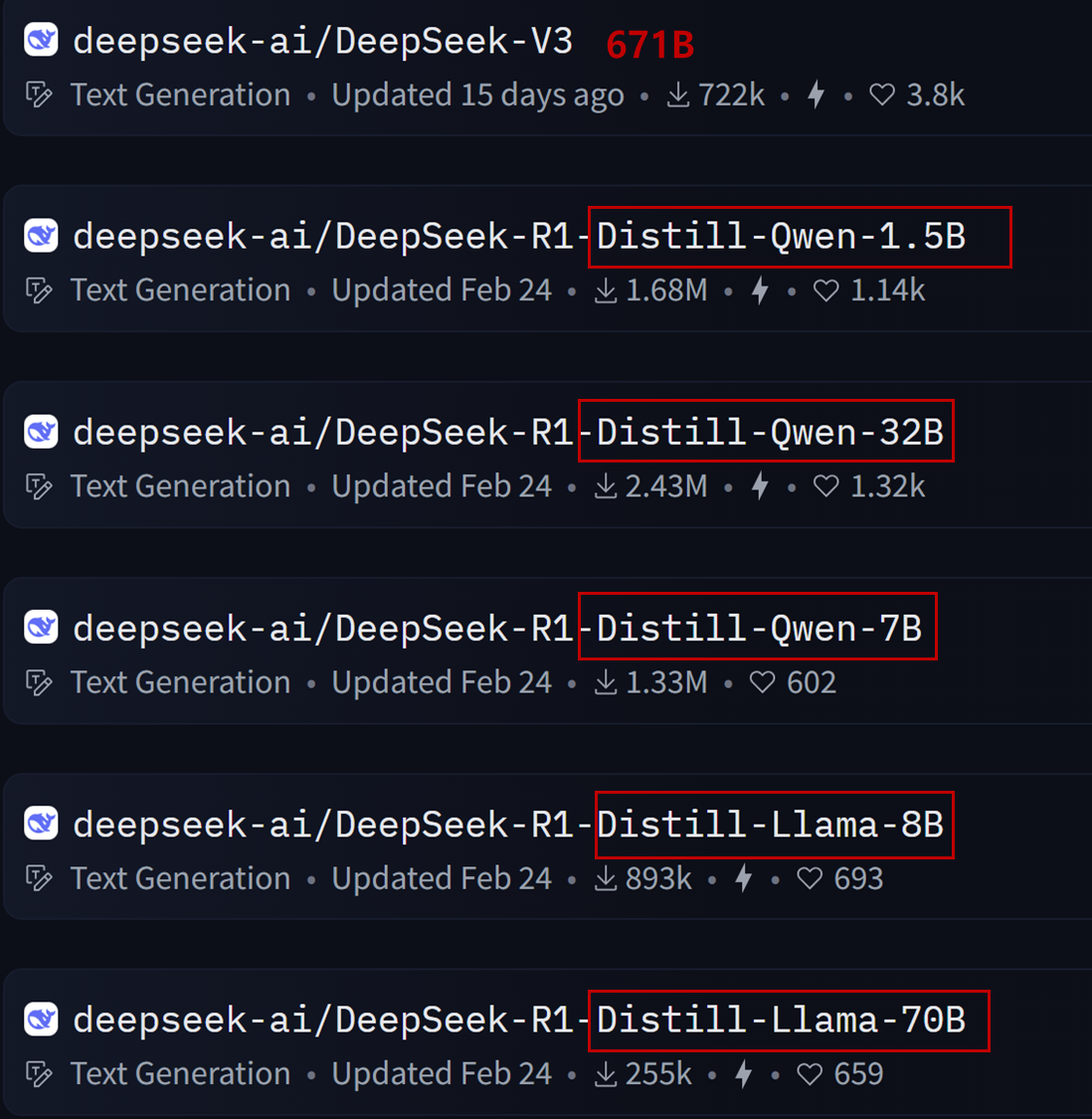
22025년 초 공개된 DeepSeek 모델에서 가장 주목할 만한 점은 첫째, R1이라는 고성능 추론 모델의 소스가 공개되었다는 점과 둘째, 671B 규모의 모델을 distillation 기법을 통해 효과적으로 경량화했다는 점이었습니다. 특히 LLM 시장의 경쟁이 치열
4.[플러스 AI] 4. F1과 ROC-AUC
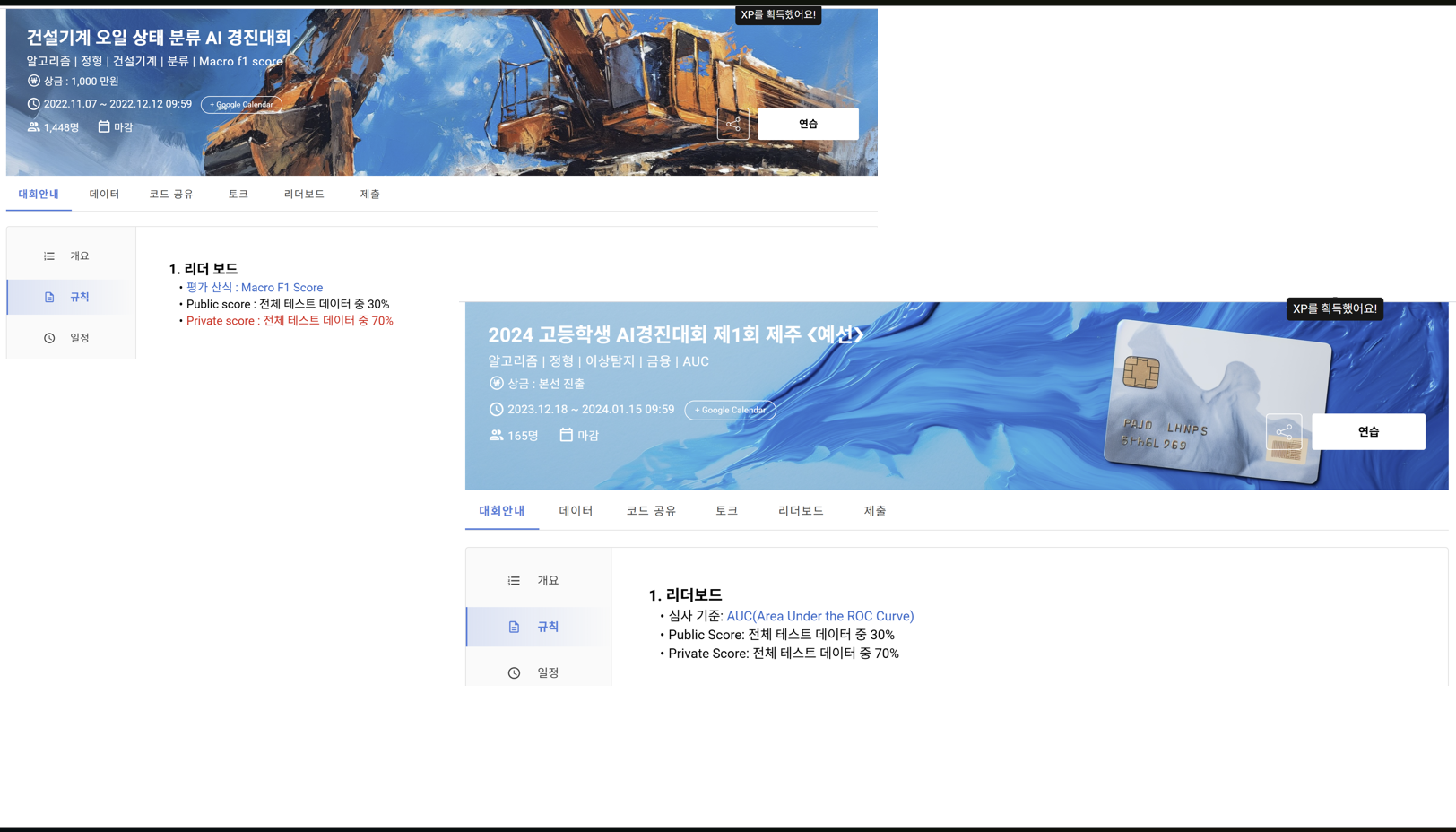
데이콘이나 캐글과 같은 데이터 분석 경진 대회에서는 분류 문제를 평가할 때 주로 F1-score나 ROC-AUC를 평가 지표(metric)로 사용합니다. 이 두 지표는 모두 분류 모델의 성능을 나타내지만, 측정하는 관점이 다릅니다. 후술하겠지만, F1-score는 정
5.[플러스 AI] 5. Correctly 중간 점검

안녕하세요, 김경호입니다. 이번 글에서는 항해 플러스 AI 3기에서 제가 맡고 있는 학습메이트 역할과 개인 프로젝트 “Correctly”의 중간 점검 내용을 공유드리겠습니다. 우선 이번 기수를 시작하면서 저는 두 가지 목표를 세웠습니다.첫 번째는, 매주 주어지는 과제
6.[플러스 AI] 6. SFT vs DPO
이번 글은 SFT와 DPO에 대한 비교 글을 작성하려고 합니다. 언어 모델 훈련 방법의 대표적 방법론인 SFT와 DPO에 대해 각각 알아보고 공통점과 차이점을 서술하는 것을 일차적인 목표로 삼을 예정입니다. 정확한 비교를 위해 훈련 환경은 동일하게 구성하였고 훈련할 t
7.[플러스 AI] 7. 마지막: 항해 플러스 AI 2기 수강생부터 3기 학습메이트까지

저는 누구였냐면... 개발하기 전 저는 대학시절 내내 저는 수학 강사로 활동을 해왔습니다. 대학 전공이 수학과였던 것도 수학 강사로 활동했던 것도, 그리고 대학 생활을 등한시할 정도로 수학 강사에 집중했던 것도 모두 수학 자체에 대한 관심도가 높았기 때문일 것입니다