1. 개괄
이번 글에서는 항해 플러스 AI 3기에서 제가 맡고 있는 학습메이트 역할과 개인 프로젝트 “Correctly”의 중간 점검 내용을 공유드리려고 합니다.
2. 목표
우선 이번 기수를 시작하면서 저는 두 가지 목표를 세웠습니다.
첫 번째는, 매주 주어지는 과제를 단순히 수행하는 데 그치지 않고 기술 블로그로 정리하여 학습 내용을 되새기고 공유하는 것이었고, 두 번째는 함께 수강하는 분들과 소규모지만 의미 있는 개인 프로젝트 하나를 완수해 보는 것이었습니다.
프로젝트 볼륨을 과도하게 늘리면 지속하기 어렵다고 판단해, 핵심 기능만 담은 작은 규모로 기획했습니다. 여기에 MLOps 스터디에서 얻은 경험을 접목하면 좋겠다고 생각했습니다. 그래서 데이터 생성부터 모델 훈련, 그리고 서빙까지 자동화된 파이프라인을 구현하는 방향으로 콘셉트를 잡았습니다.
3. “Correctly” 프로젝트 개요
프로젝트 이름은 “Correctly”로, 어색한 영어 문장을 교정하고 교정 이유를 설명하는 챗봇을 만드는 것이 목표입니다.
-
단일 테스크: 다양한 대화 상황을 가정하기보다 ‘학습·교정’이라는 하나의 테스크에 집중
-
모델 구성:
- 교정 모델로는 Gemma3 1B
- 검증 모델로는 GPT-4o-mini 와 같은 api 를 통한 gpt 계열 언어모델을 사용할 예정입니다.
-
환경 구성:
- Docker & Docker Compose로 컨테이너화
- PostgreSQL에 메타데이터 저장
- Airflow DAG로 배치 학습 자동화
- MLflow로 실험 추적
- OpenWebUI를 활용한 프론트엔드 검증


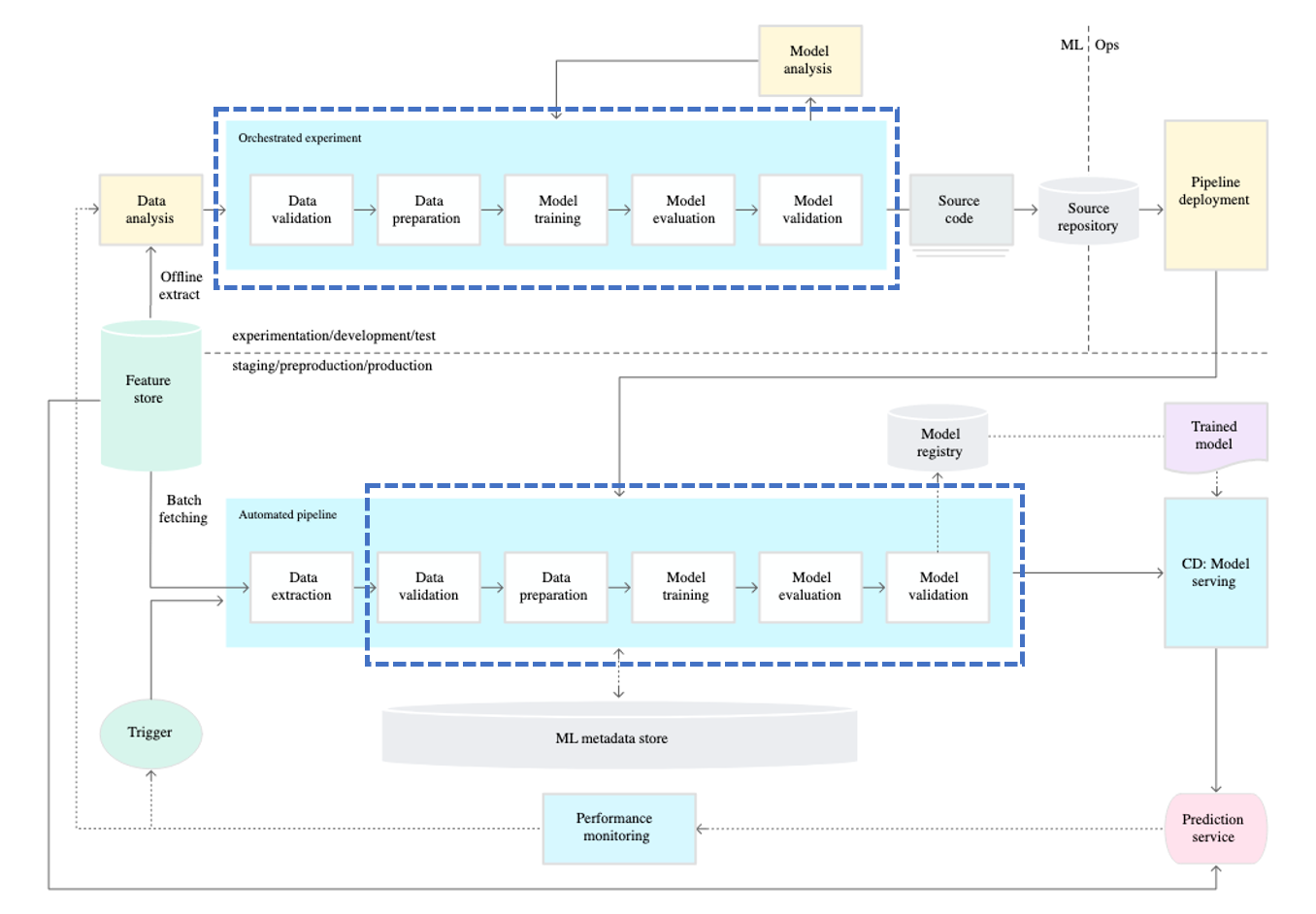
이 흐름을 유지하면서, MLOps Level 1.5에 맞춰 코드·데이터 버전 관리 → 배치 학습 자동화 → 실험 기록을 구현했습니다.
참고 MLOPS 단계 구성


4. 지금까지 달성한 네 가지 기능
-
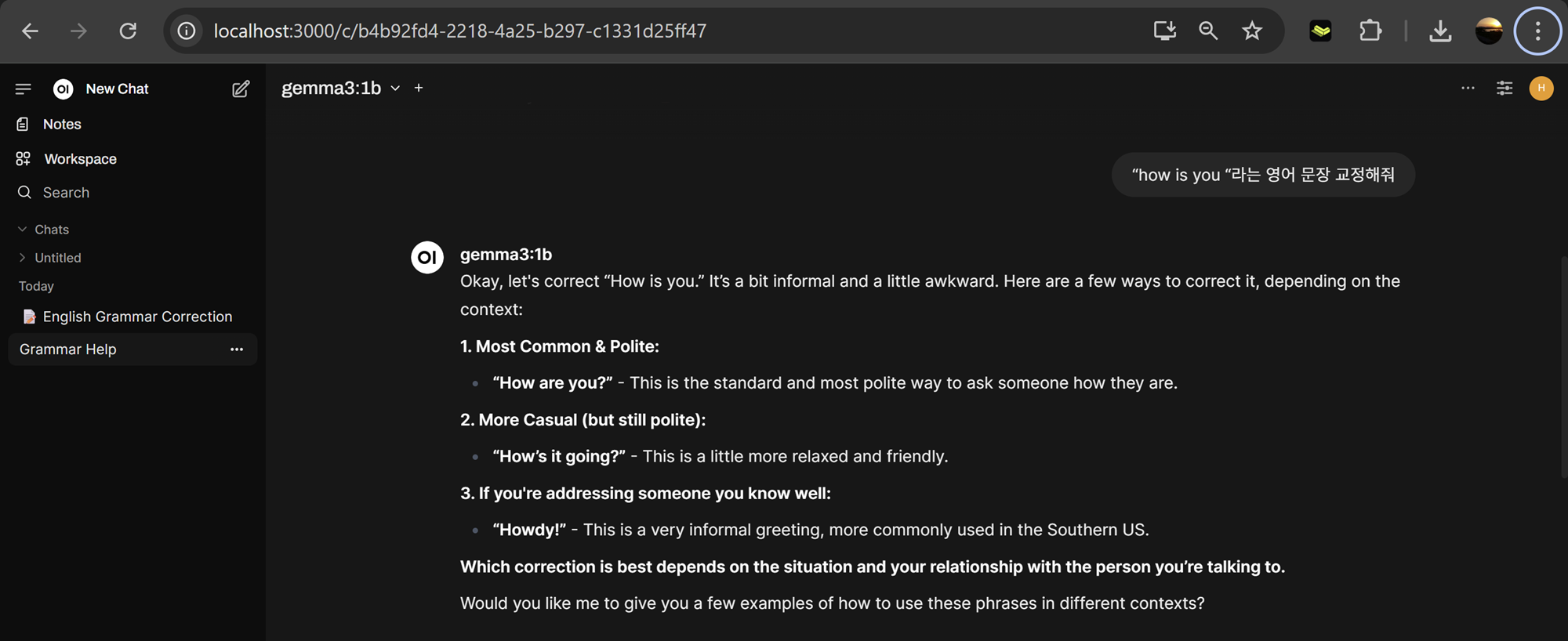
OpenWebUI 기반 정성 평가 프로세스 마련
챗봇의 교정 품질을 검증하기 위해 UI 상에서 직접 문장을 입력하고, 교정 결과와 이유를 정성적으로 평가할 예정입니다. 사용자가 실제 대화하듯 플로우를 점검하면서, 교정 결과의 자연스러움과 설명의 명확성을 확인할 것입니다.기대하는 바는, 최소한 영어 문장을 교정하는 단일한 데이터 input에서 작은 모델로도 제가 원하는 방향으로 훈련이 된다는 것을 실증하는 것입니다. 범용성에서는 비할 바가 없겠지만
-
MLOps Level 1.5 파이프라인 구성
Airflow DAG로 데이터 생성 절차를 자동화했습니다. 단 훈련에 사용할 데이터가 아닌 훈련 데이터를 생성하기 위한 example_data
-
범용적인 DB 스키마 설계
텍스트 저장소(Text Repository)와 교정 스크립트(Correction Script)를 분리한 스키마를 만들었습니다. Text Repository에는 Form, Tone/Sentiment, Length 같은 공통 속성을, Correction Script에는 Style, Key Expression, Speaker Details 같은 개별 속성을 저장하도록 설계했습니다.나아가 훈련 데이터를 생성할 때엔 example 데이터를 기반으로 train 데이터를 생성하는 one shot prompt 기법을 사용하여 데이터를 사용할 것입니다. 즉 모든 train 데이터는 example 데이터를 기반으로 생성이 될 예정입니다.
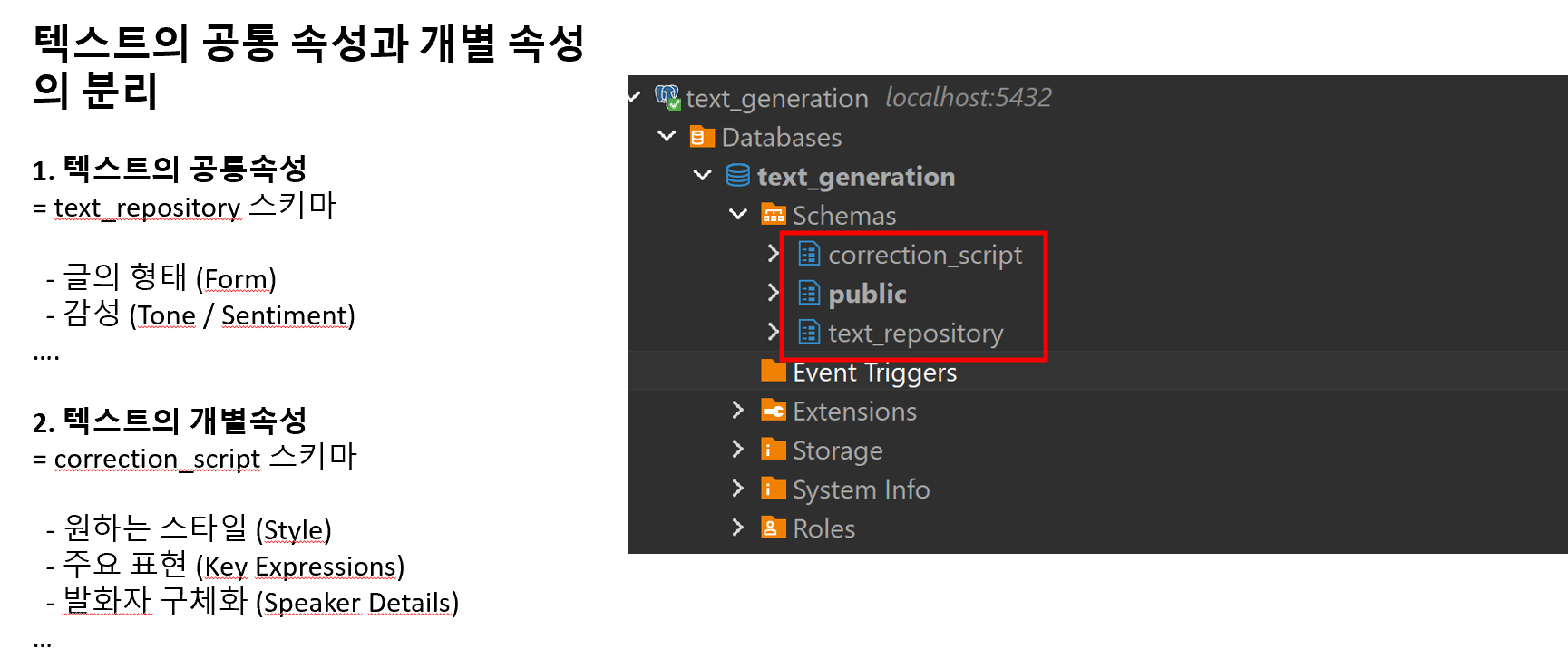
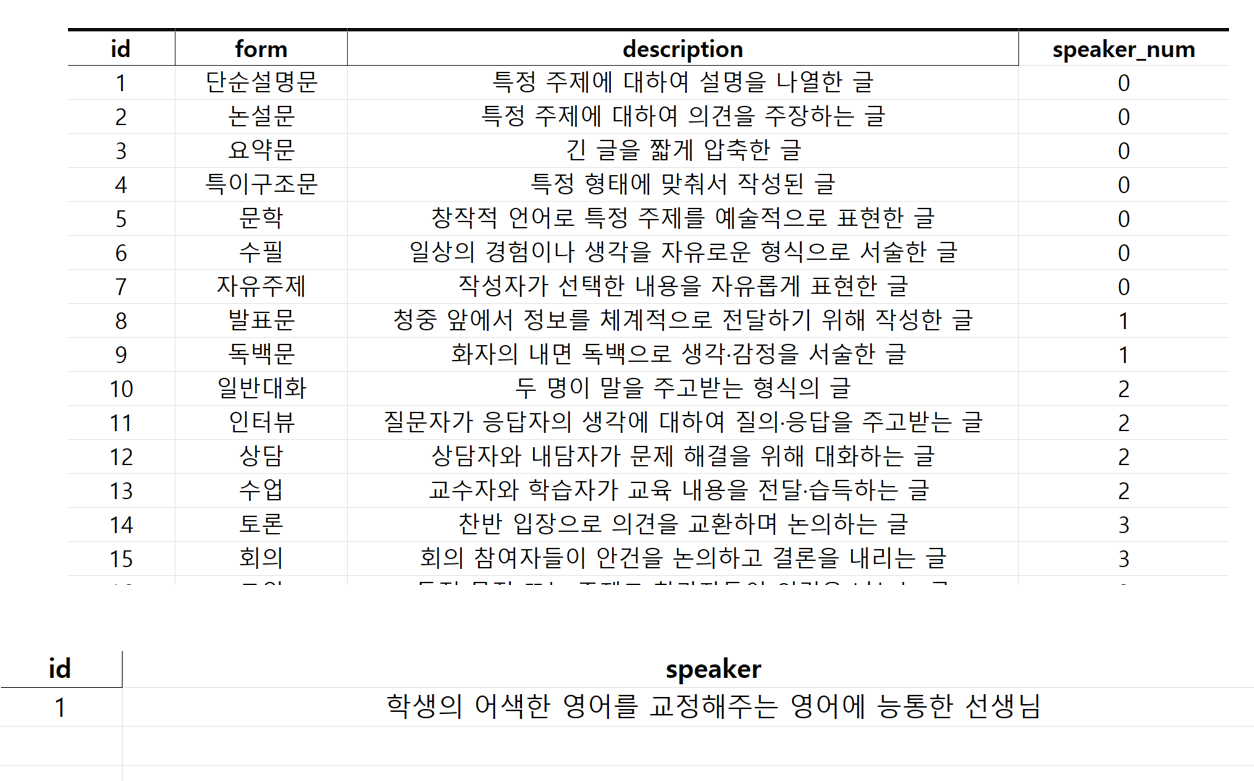
상단은 text_repository라는 형태에서 글의 형태를 분류하는 공통적인 속성입니다. 하단은 correctly라는 프로젝트에서 전용으로 사용할 데이터의 특성을 분류한 예시입니다.
- Airflow DAG를 이용한 예시 데이터 자동 생성
example테이블에 들어갈 샘플 데이터를 Airflow DAG로 자동 삽입하도록 구현했습니다. Docker 환경에서 스케줄링 테스트를 완료하여, 예시 데이터 생성 작업이 안정적으로 실행되는 것을 확인했습니다.
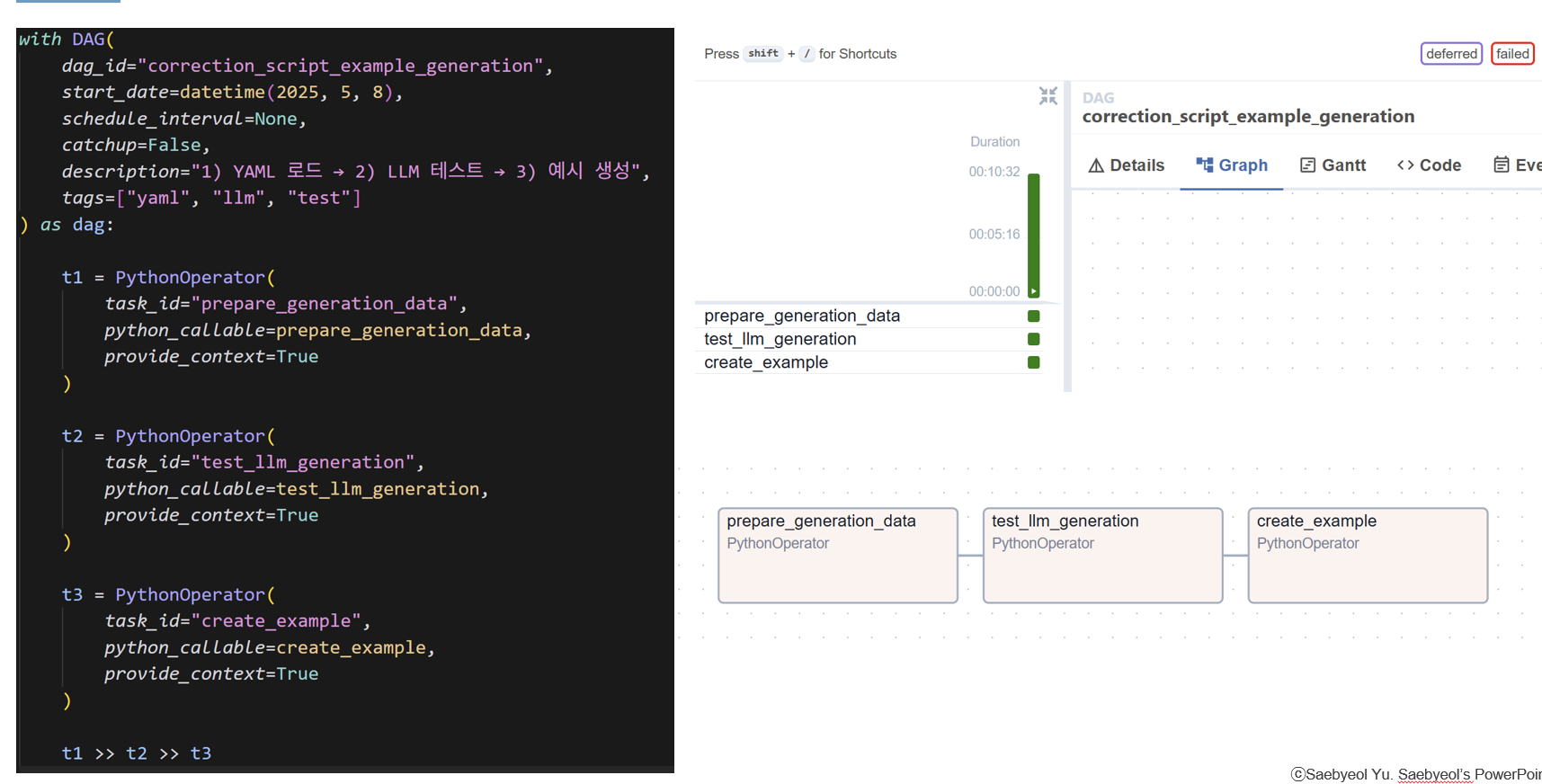
5. 남은 두 가지 과제
아직 마무리하지 못한 부분도 있습니다.
- 훈련 데이터 생성 자동화: 예시 데이터를 넘어 실제 학습에 사용할 대규모 훈련 데이터를 만드는 DAG을 완성해야 합니다.
- 훈련 파이프라인 완전 자동화: DAG가 데이터를 만들고 학습까지 실행하도록 연계하고, Trigger 기반으로 재학습을 수행하는 시스템을 구축할 예정입니다.
이 두 가지 작업을 마치면, 초기 목표로 삼았던 데이터 생성 → 학습 → 배포 파이프라인이 완전 자동화됩니다. 남은 기간동안 아직 달성하지 못한 과제들에 집중하여 프로젝트를 완성해볼 계획입니다.

발표자료 링크: https://docs.google.com/presentation/d/1HsfcRl3A0XM8rGEy0z5TW2G6ZBG1qzPxQ9rJG7ovw2M/edit?usp=sharing
