
제목만 보면 이번 포스팅은 좀 짤막하진 않을 수 있습니다. 그러나 짤막 시리즈의 목적은 언제든 꺼내어 먹을 수 있는 간단한 포스팅이 목적이기 때문에
"왜 그렇게 되는데?" 에 대한 대답은 최대한 자제하고 과정만 간단하게 설명하겠습니다. 왜 그런지에 대한 대답을 보고 싶으신 분들은 제 Naver Blog의 "Let's Deep" 시리즈를 보시면 됩니다.
구조
모든 딥러닝 모델들은 신경망을 기초로 합니다. 그리고 그 신경망은 아래와 같은 구조로 되어있죠.
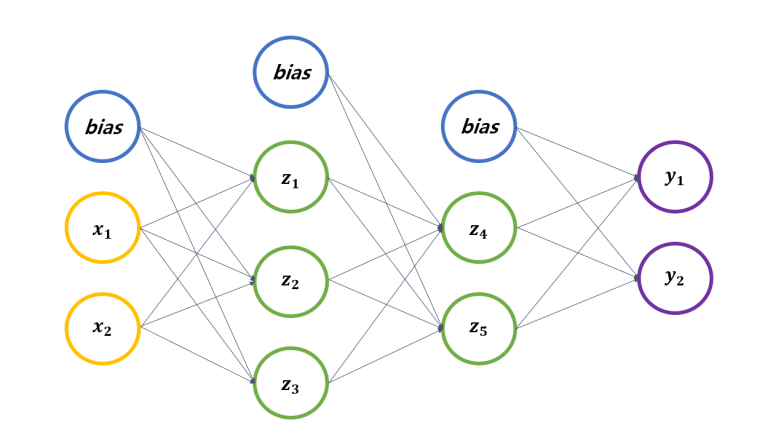
한 Layer 마다 Input, Weight, Bias, Output이 계산되고 그 Layer들이 반복되는 구조입니다.
그 반복되는 구조의 마지막엔 y1과 y2로 표현된 최종 Output이 있네요.
이런 식으로 다양한 input을 한번에 나타내는 방법은 아래처럼 "행렬"로 나타내는 겁니다.
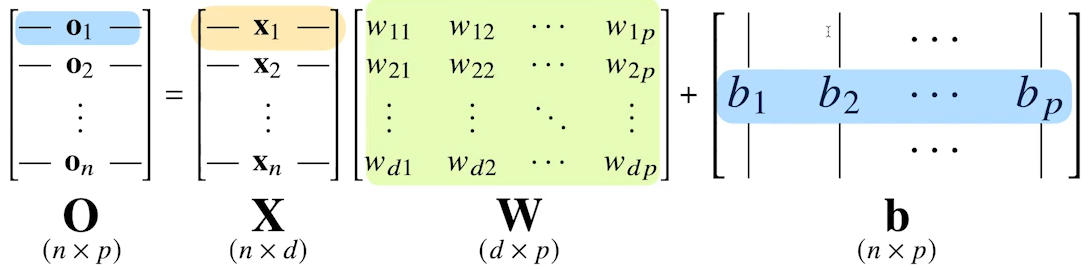
이런식으로 한 Layer의 Input(X), Weight(W), Bias(b) 그리고 Output(O)로 나타낼 수 있는 것이죠. 각 행렬의 차원도 확인해보시면 좋습니다.
X는 d개의 column으로 되어있는 n개의 Data Point들이고
W는 그 d개 column에 대한 정보를 받아 p개의 잠재변수 column으로 표현하는 행렬이라고 생각하셔도 될 것같습니다.
우리는 이제 W와 b를 적당히 조절해나가면서 최적의 Output을 얻어내는 겁니다.
Softmax
들어온 Vector에 대해 확률로 해석할 수 있게 출력해주는 함수입니다.
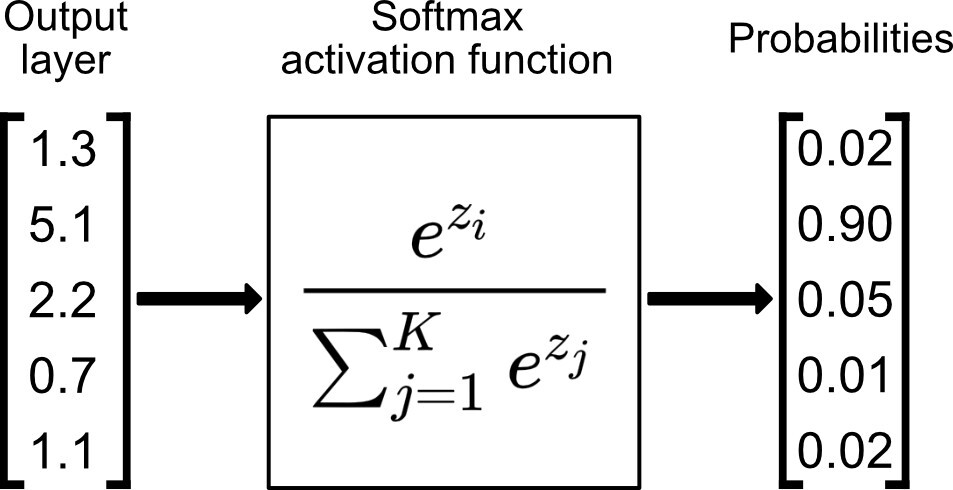
수식 안 봐도 됩니다. 그냥 들어온 값들을 합해서 1이 되게 해주니까 각 요소들은 확률로 생각될 수 있다는 아이디어 입니다.
[1, 2, 3, 4, 5] 라는 Vector가 들어오면 [0.1, 0.1, 0.2, 0.1, 0.5] 이런 식으로 합이 1이 되게 만들어줌으로써 각 class로 분류될 확률을 구할 수 있는 겁니다.
Sigmoid를 아시는 분은 Sigmoid의 확장판이라고 생각하시면 너무나도 편하죠.
그럼 최종적으로 나온 Output Node에 softmax를 적용하면 그 출력값을 확률로 해석할 수 있게 되겠죠? 이걸 활용할 수 있게 되는 겁니다.
물론 학습을 할 때는 Softmax를 이용하고(loss 계산을 위해) 실제로 Inference를 할 때는 output 값에서 가장 큰 값만 뽑아오는 one-hot 을 이용하기 때문에(by argmax) 학습시에만 사용하게 됩니다.
활성화 함수
위에서 설명한 Softmax는 신경망의 결과로 나오게 된 Output 들을 종합적으로 넣습니다.
그러나 각 Node(동그라미, z1, z2...)에서도 이와 비슷한 과정을 거치게 되는데 이때 등장하는 것이 활성화 함수(Activation Functin)입니다.
활성화 함수 : Vector가 아닌 실수를 Input으로 받아 새로운 잠재 Vector를 형성하는 역할
신경망에 "비선형성"을 부여한다. 딥러닝을 딥러닝스럽게 만드는 역할.
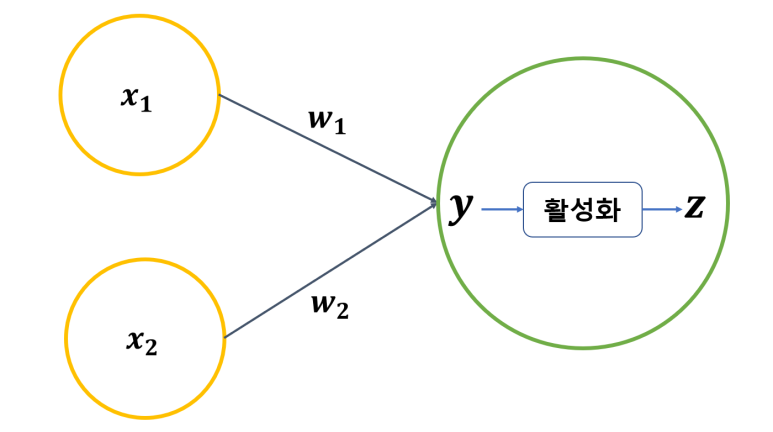
이런 식으로 x1w1 + x2w2의 결과인 y를 활성화 함수에 넣어 최종 결과물인 z를 출력하게 됩니다.
이런 z들을 모은 것을 잠재 Vector라고 하고 이들을 다시 다음 Layer의 Input으로써 활용하는 과정을 반복하는 것이 바로 신경망의 핵심이자 그 작동 원리입니다.
이러한 여러 Layer들로부터 나온 결과로 세상에 있는 다양한 것을 "표현"할 수 있는 것이죠.
여기까지 요약
- Input의 행렬인 X가 들어온다
- 가중치 행렬인 W를 곱해주고 bias 행렬을 더해준다.
- 2번의 계산인 행렬 Y의 "각 요소"에 활성화 함수를 적용함으로써 "비선형성"을 부여한다.
- 비선형성이 부여된 행렬 Y를 Z라고 부르기로 한다.
- 이 Z는 다음 Layer의 Input이 되며 이 과정을 반복한다.
- 최종 Output Vector들을 Softmax 함수에 넣음으로써 확률로 해석할 수도 있다.
여기까지의 과정을 바로 순전파(Forward Propagation)라고 합니다.
위의 과정들을 한 마디로 요약하면
순전파 : 들어온 Input을 신경망에 넣고 출력까지 시키는 과정
이라고 매우 간단하게 요약할 수 있겠네요.
역전파
근데 생각해보니 한번만으로는 제대로 된 결과나 나올 리가 없습니다. 아까 보니 Weigt와 Bias를 조정해준다고 하는데 이를 조정해주는 과정을 역전파(Backward Propagation)라고 합니다.
경사하강법에 대해 알고 있다는 전제 하에(미분을 이용하여 특정 함수의 최저점을 찾아가는 알고리즘) 간단하게 설명하고 넘어가면
모든 weight와 bias에 대해 경사하강법을 적용합니다. 그러나 Output Layer부터 순차적으로 적용하면서 Input Layer까지 Loss Functin이라는 함수의 값을 줄어들게 만드는 방향으로 Weight와 Bias를 조정하게 됩니다.
이때 조절할 수 있게 만들어주는 정말 고마운 기법이 바로 Chain Rule인 것이구요.
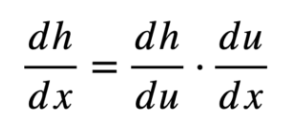
간단하게 말하면
Output에 대한 특정 변수 x1의 영향력(미분)을 계산하기 위해서 가장 최근에 Output에 영향을 주었던 것에 대한 영향력을 계산해나가면서 x1의 영향력을 계산해나가는 겁니다.
알기 쉽게 비유하면
지금 내가 왜 이렇게 됐지,,? 를 따지기 위해
아 내가 얼마전에 A라는 선택을 했고.. 그 A라는 선택은 3년전 B라는 선택에 의해 그런 거고.. B라는 선택은 10년전의 C라는 선택에 의해 그런 거고....
이런 식으로 생각해나가는 거랑 똑같다고 생각하시면 됩니다.
뭐 어쨌든 이런 식으로 Weight와 Bias를 조절해나갈 수 있는 근거도 확보했습니다.
역전파를 하기 위해서는 미분값을 알고 있는 것이 중요하기 때문이 각 노드에 대한 미분값들을 모두 저장하게 됩니다. 말만 들어도 엄청난 계산량을 저장해야 한다는 것을 직감할 수 있죠?
Optimizer
위에서 이제 Weight과 Bias를 조정해나갈 때 얼마나 조정할 지를 결정하는 친구를 말합니다.
그레이디언드(GD)도 이 Optimizer의 일종이라고 할 수 있죠.
어차피 GD의 개념만 알고 있으면 SGD, Adam 계열을 이해하는 건 어렵지 않으니,
Weight와 Bias를 조절하는 역할 정도로 알고 넘어가시면 좋을 것같습니다.
총 요약
이제 친구들한테 AI 학습 원리로 잘난척 하고 싶으면 이렇게 말하면 됩니다.
(순한맛)
1. 순전파와 역전파가 있는데
2. 순전파 과정에서 Data들의 Weight와 Bias를 계산해서 결과를 내놓고
3. 역전파 과정에서 그 Weight들과 Bias들을 조정해나가면서 최적의 결과를 내는 거야~
(신라면맛)
1. 데이터 행렬 X와 가중치 행렬 W, 편향 행렬 b를 이용해서 행렬 O를 계산해내는데
2. 이 행렬 O를 다시 똑같은 과정을 통해서 새로운 행렬 O를 만들어 내는 걸 여러번 해 그게 순전파야
3. 물론 그 과정에서 활성화 함수를 통해 신경망에 비선형성을 부여하고
4. 이렇게 나온 결과물이 한번으로는 절대 좋은 성능이 안 날 거 아냐?
5. 그래서 지금까지 계산해 사용했던 Weight와 Bias들을 조정해 나가는데 이 과정을 역전파라고 해
6. 역전파를 수행하면서 Weight와 Bias를 어떤 방법으로 조정 시키는지를 결정하는 애들이 Optimizer라고 하는 거고~
7. 이제 이 순전파라고 하는 과정과 역전파라고 하는 과정을 계~~~속 반복하는 거야~
이제 그림이 좀 그려지나요?
