🤦♂️ 2주차 위클리 페이퍼
📅 주간 현황 및 보고
1-0. 작성 목적 및 목차
이번 2주차 Weekly Paper에서는
- 이번주 강의 후기 및 스스로에 대한 피드백
- 브라우저가 어떻게 동작하는지
를 다룹니다!!
1-1. 강의 후
여전히 나는 깡통이다
음.. 뭐라 해야 하지 뭔가 정보가 들어오는 게 많다!
요즘은 어제는 물론 뭐 엄청나게 많았지만.
뭐 이것저것 배웠다..
또 다시 찾아보면 이렇게 짧게 할 만한 게 아닌 거 같기도 하고..
암튼 결국 반년만에 무슨 코드를 봐도 일단 볼 줄은 알아야 하는 개발자를 만들어야 하니까
진도가 빠른 것도 무조건 이해할 수 있다!
근데 사실 당연한 게 반년만에 관련전공자랑 비슷한 수준으로 갈 수 있으면
대학교를 왜 가겠는가? 그냥 모조리 부트캠프가지ㅋㅋ..
관련전공자들은 4년 치 건물을 내용물까지 꽉꽉 쌓는다고 치면
부트캠프는 3년 치 건물을 외관만 짓는 느낌이다
내용물은 내가 알아서 쌓아야 하는 것이고! 열심히 배워야지
아마 깡통 티 안나게 하려면 적어도 3년은 해야하지 않을까 ?
1-2. 주간실기
이번주 주간실기는.. 딱히 스샷올릴게 없어보임
미디어쿼리로 반응형좀 구현해봤고!
아마 다음주랑 통합으로해서 올릴것같다.
😎 브라우저란?
웹사이트에 접속하기 위한 응용 프로그램!
2-0. 브라우저가 그래서 어떻게 동작하는가?
브라우저가 어떻게 동작하는가를 알려면 일단 기본적으로
브라우저가 어떤 애들을 데리고 일을 하는지 알아야 하지 않겠는가?
챕터 2는 이에 대해서 다룬다
2-1. 사용자 인터페이스 (UI)
우리들이 아무리 웹사이트를 이동하고 어디를 가도 바뀌지 않는 것.
뒤로 가기, 앞으로 가기, 새로고침.. 주소표시줄 등등!
그것을 우리가 바로 사용자 인터페이스라고 부르는 것들!
현재 쓰고있는 브라우저인 Arc의 유저 인터페이스 !
2-2. 브라우저 엔진(Browser Engine)
이 친구는 위아래에 있는 사용자 인터페이스와 렌더링 엔진 사이에서
사용자가 뒤로 가기 버튼을 누르거나, 어디 다른 사이트로 이동할 때
렌더링 엔진에게 "야! 사용자 뒤로 가기 눌렀음!", "야! 사용자 유튜브본대!"를
알려주는 역할!
2-3. 렌더링 엔진(Rendering Engine)
간단하게.. 웹 사이트를 그려주는 엔진이다!
설명하면 간단 하지만.. 꽤나 많은 일을 함!
Arc가 그려준 웹사이트 Google!
2-3-1. 통신
렌더링을 하려면.. 그러면 일단 결국 통신이 되어야 하지 않는가?
결국 "어떻게 그리시오"라고 받아와야 하니까!
그렇다면.. 우리는 어떻게 얘가 "통신" 하고 있다는 걸 가시적으로 볼 수 있을까?
사실.. 도메인으로 뭔가 되고 있다는 사실이 "통신"하고 있다는 사실이란 건 알고 있지만..
그래도 눈으로 딱 보이는 얘가 뭘 하고 있다! 나는걸 보려면 뭘 해야 하지?
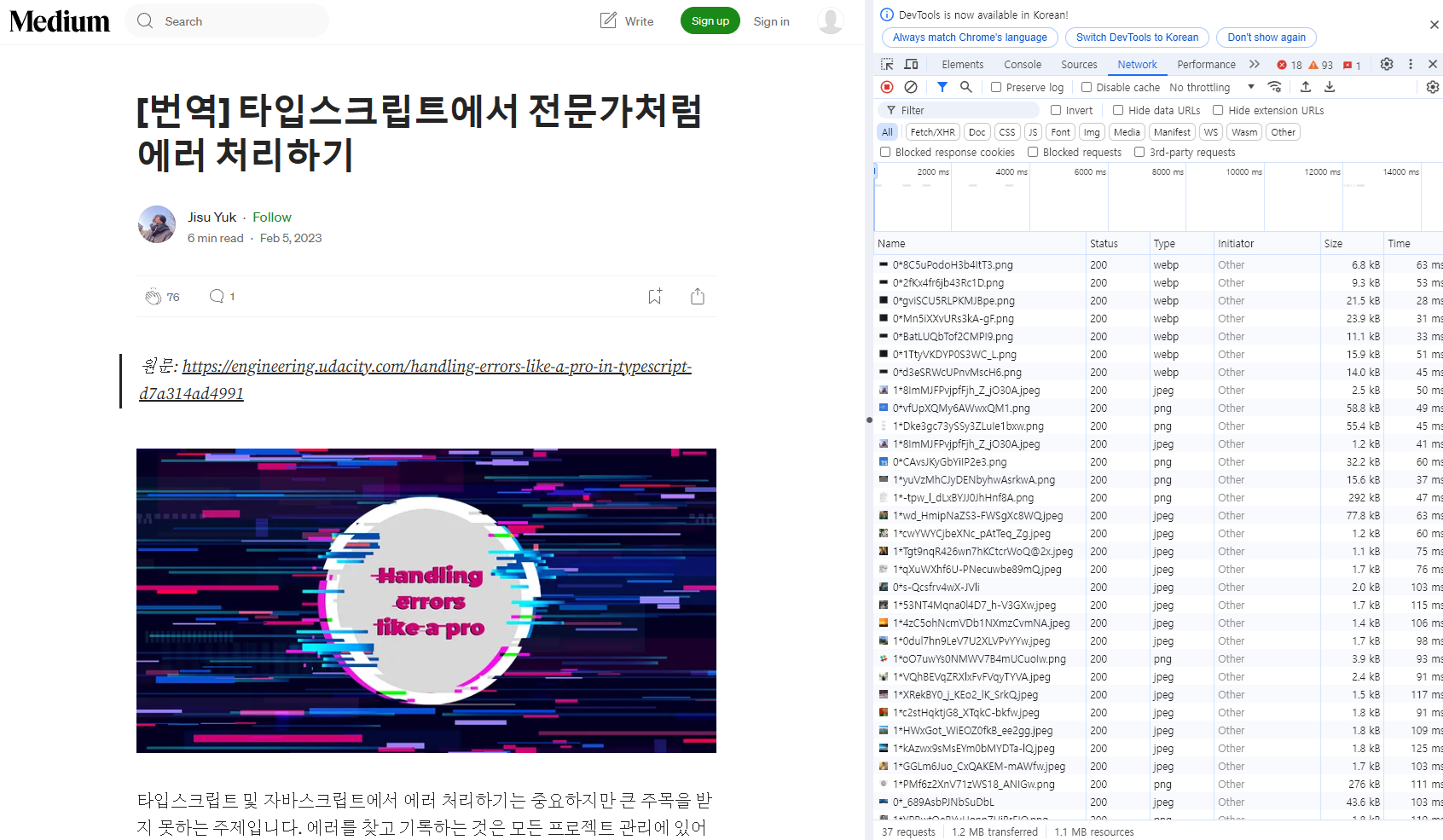
새로운 이미지나 무언가 나올 때마다 열심히 사진을 받아내고 있다!
개발자도구의 Network를 들어가면
"아~ 얘가 지금 무슨 사진을 받았구나!"를 알 수 있다
2-3-2. 자바스크립트 해석기
우리 브라우저는 자바스크립트를 이해할 수 있다!
사실 자바스크립트를 이해 못 하면 내가 JS를 배울 이유가... 좀 사라지지 않을까?
아무튼 자바스크립트 해석기로 JS가 "A를 해!" 하는 거를 이해할 수 있는 것이고!
지금 사용하고 있는 Arc 브라우저는 V8엔진을 쓰고 있었다.
2-3-3. UI 백엔드
select라던가 input 같은 유저와 사이트 간의 상호작용도구를 그리는
플랫폼에서 명시하지 않은 일반적인 인터페이스로서
입력이라던가, 마우스의 움직임, 클릭 등을 담당한다
2-3-4. 자료 저장소
브라우저도 정보를 저장할 수 있다!
예를들어서 Local Storage, Session Storage, Cookie들이 이에 속하는데.
이런 필요한 자료들을 저장하는곳!
📀그래서 많은일을 하는 렌더링엔진은?
우리가 딱 어딘가를 접속하는순간.
렌더링엔진이 무슨일을 하게되는걸까?
3-1. 그래서 걔 어디사는데? (DNS)
DNS 서버로!
우리는 https://www.google.com/ 으로 접속을 한다.
근데 접속한다고
이 브라우저가 "아~ 구글로 가라고? 확인~" 하면서 바로 가지 않는 것.
www.google.com이라는 이름은 결국 우리가 보기 편하게 이름 지어놓은 거고
그 자체를 브라우저가 이해하지는 못한다.
브라우저가 이해하는 건 "IP주소"인 것.
그래서 브라우저가 일단 처음 해야 하는 것은 구글의 IP주소를 찾는 것!
일단 우리 Local DNS에 구글 도메인 IP주소가 있는지 체크를 한다.
없다면 브라우저는 구글이라는 도메인을 들고 DNS 마을에 찾아간다.
DNS마을은 모든 주민들이 각각의 도서관을 관리하면서 살아가고 있다다

그 도서관에는 빽빽하게 채워진 책들 표지에
"야후는 ~~ 다, 구글은 ~~ 다, 카카오는 ~~ 다"와 같이다
하나하나 사이트에 대응되는 IP주소가 대응되어 있는데.
그 많은 도서관들을 하나하나 돌아다니면서 묻는 것이다.
일단 처음으로 루트 DNS에게 물어본다.
브라우저 : "루트님, 구글 IP 주소 아세요?"
Root DNS : "구글?. com 이네? 닷컴 네임서버로 가보세요~"
브라우저 : "닷컴님, 구글 IP 주소 아세요?"
. com DNS : "구글? 아~ 그거 여기 어디 담당자 계시는데 거기로 가세요~"
의 과정을 구글 IP주소를 찾을 때까지 반복하며 찾고 나서야 돌아오는 것!
이 과정, 글로만 봐도 엄청나게 길어 보이지 않는가?
이런 힘들게 얻은 귀한 IP주소는 컴퓨터에 저장을 해두게 된다.
DNS Cache에다가 저장을 하고, 다음번에는 바로 가져올 수 있도록!
3-2. 아저씨, 저 브라우저인데 HTML좀 주세요 (리소스)
Google을 그려야 하는데!
Google의 집주소는 알아냈다.
그렇다면 일단 뭔가 그릴건 받아야 하지 않겠는가?
가서 문을 두드리면 Google선생님이 우리 브라우저에게 그릴 자료를 주신다.
근데, 그냥 우리가 보는 헤드, 바디 그런 게 아니라
![]()
이런형태로 준다..
이런 ByteStream 형태로 받게.. 되는데!
(우리 입장에서는 어려운데, 컴퓨터 입장에선 그게 더 쉽긴하다)
이걸 받고나서! 다시 인코딩을 한다.
우리는 한국인이고, 한국어쓰기도 하니까
좀 범세계적으로 다양한 언어를 지원하는 UTF-8 인코딩을 주로 채택한다
<meta chatset="utf-8">이거, 항상 하지않는가?
위의 과정이 있으니까
우리가 HTML파일 구성할때 인코딩 방식도 우리가 언급을 해두는것!
3-3. 문자를.. 읽을수는 있다! (토큰화)
이제 인코딩도 끝났고, 뭔가 사람이 읽을수있는 숫자로 변경이 되기는 했다.
근데 그렇다고 렌더링이 끝나냐? 그건 또 아닌것.
그러면 브라우저는 우리가 보는 HTML 파일을 같이 보면서
아.. 여기가 head고, 저기가 body고, 이건 div고.. 하면서 해석하는데!
이 과정을 우리는 "토큰화" 라고 부른다!
그래서 뭘 하느냐? 진짜 말그대로 "하나씩 읽는다"
< | d | i | v | > | 안 | 녕 | 요 | < | / | d | i | v | >이것들을 하나씩 읽으면서, " < "를 만나면 "어? 뭔가 열렸다!"라고 인지하고.
d.. i.. v.. 읽다가 " > "를 만나면 "어? 태그 닫혔다!"라고 인지하며.
div이라는 Start Tag를 토큰화시키는 데 성공하는 것!
그럼 쭉쭉 읽어나가서, "안", "녕", "요"라는 캐릭터 토큰도 만들어내고.
div의 End Tag 토큰 또한 만들어내게 되며 하나하나 의미를 해석해 나가고.
이과정을 토큰화 과정이라고 한다!
3-4. 토큰의 객체화 (노드)
이렇게 읽고서 토큰을 만들었으면,
그 친구들을 뭔가 의미 있는 값으로 재해석해야 한다.
이 친구는 div고.. 안에 뭐 있고, 무슨 속성을 가지고 있고.. 등등등
이것들을 객체화시킨 것을 우리는 "노드"라고 부른다.
이 기다란 문서를 보조리 읽었으니, 이것들 중 의미 있는 태그가 무엇이 있는지?
"HTML태그 있고, div태그 있고, p태그 있고, 안녕요라는 텍스트 있고.."
등의 의미 있는 노드를 만듭니다!
3-5. 객체의 관계화 (DOM Tree)
<html>
<body>
<div>
<input> </input>
하이하이~
<button> </button>
</div>
</body>
</html>이걸 보면 우리는 바로 "아 HTML안에 body있고, 그안에 div있고, 자식 두개있네"
각각 이런 태그안에 관계를 설정하는데, 이 관계를 주는걸 "모델" 이라고 한다!
그래서 우리는 이걸 "DOM(Document Object Model)" 이라고 하는것
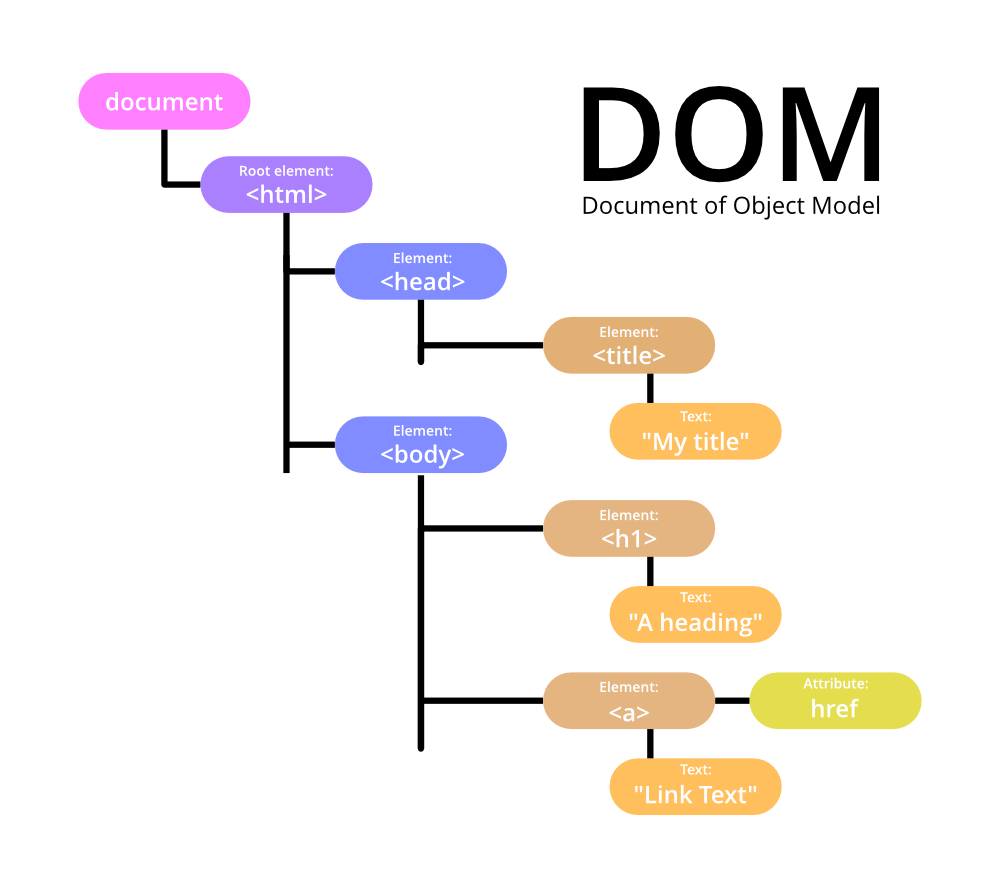
이것이 DOM Tree
나무처럼 생겼다! 그래서 Tree라고 부르는데
이 Tree는 자료의 형태(자료구조)의 하나다.
그래서 HTML의 최종 목표는 뭐다? DOM Tree를 그리는것!
3-6. CSSOM Tree
근데 그렇다고, HTML만 다 그렸다고해서 끝난건가?
그건 또 아니다.. CSS가 있음!
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" herf="style.css">
<title>Document</title>
</head>
<body>
<div id="root"></div>
</body>
</html>이런 코드가 있다면? 위에서부터 막~ 열심히 컴퓨터가 읽어나가다가
중간에 link를 딱 만난순간
"엥? 스타일이네? style.css 가져오라고?" 라고 생각하며
또다시 우리가 가져온 IP주소에 요청을 한다.
3-2가 반복되는데
이번에는 "아저씨, 방금받은 HTML보니까 CSS필요하다는데 CSS파일 좀 주세요"
같이 재요청을 보내는것!
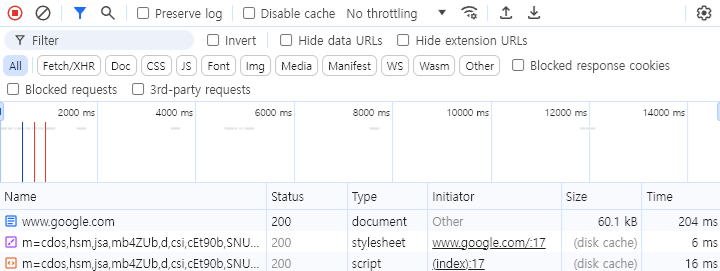
사진에 보이다시피
Document - StyleSheet - Script 순으로 요청되어있음!
이렇게 요청을 완료하면, HTML과 같이
ByteStream을 받고 -> 인코딩하고 -> 토큰화 ->
노드로 만들고 -> CSSOM Tree 라는걸 구성하게 되는것!

이것이 CSSOM Tree
바디안의 div, div에는 무슨 스타일이 등등등.. 을 구성하는것!
3-7. Script 불러오기
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" herf="style.css">
<title>Document</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="index.js"></script> " 여기! "
</body>
</html>흠.. 뭔가 생겼다, script가 필요하다는데?
또 다시 "아저씨, 방금받은 HTML보니까 JS도 필요하다는데 JS 좀 주세요!" 를 반복
다시 자바스크립트도 불러오게된다.
근데, 그때?
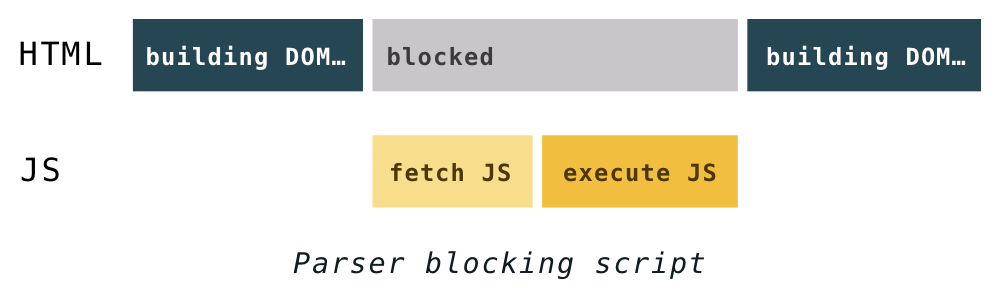
근데 놀랍게도, JS실행중에는 DOM이 Parsing을 멈춘다!
왜 그럴까?
JS는 상당히 강력해서
createElement Method만 사용해도 HTML 안쓰고도 노드를 만들수있고
내용도 바꿀수있고, CSS도 바꿀수있다.
HTML 입장에서는
이미 DOM 다 그려둔거 뒤늦게 바꿔버리면 바뀐만큼 낭비가 되는것 !
그래서 이렇게 된다.
"불러왔어? 그럼 일단 JS하고싶은거 일단 좀 다 들어보자."
"뭐를 모조리 들은뒤 그걸 모두 모아서 한번에 DOM을 그리는게 낫겠다"
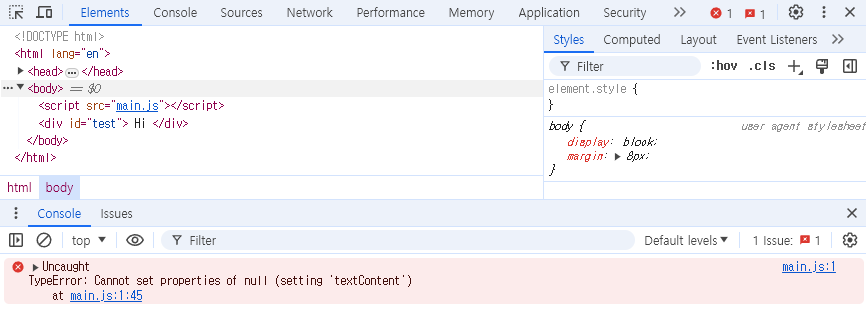
실례로 위 사진을 보면
JS로 "div태그의 Hi라는 텍스트를 바꿔줘!" 라는 요청사항을 넣었는데.
에러가 발생했다!
"너가 말하는 div를 못 찾겠는데 textContent를 어떻게 설정함?"
왜 그럴까?
바로 Script 태그가 div보다 먼저 나왔기 때문
HTML은 Script 태그를 본 순간 멈춰버리고
그대로 아래에있는 div태그를 보지 못한것이다!
당연히, div태그는 보지도못했으니 가져올수도 없고, 이런 에러가 발생한것.
"스크립트 태그는 바닥에두고, CSS태그는 위에다 둬라" 라는게 이러한 이유 때문이다.
JS가 DOM의 생성을 막지많게 하는 옵션(defer, async)도 있는데.
이거는 따로 다룰예정..
3-7-1. 그러면.. CSS는 왜 위에다 둘까 + CSS의 경량화
CSS는 돔의 생성을 막지 않는다. 이것도 이유지만!
DOM이 완성됐다고 웹사이트는 바로 보이지 않는다.
왜냐면 DOM은 CSSOM의 완성을 기다리고 있고,
둘 다 완성되어야 다음 단계로 진행이 가능하기 때문!
"그러면 CSSOM을 빠르게 만들어야 뭐라도 하겠네?"
그래서! CSSOM이 웹사이트 성능에 중요한 역할을 한다.
CSS가 너~무 무거우면 CSSOM을 오래 기다려야 하니
아무리 DOM이 빨리 완성되어도 의미가 없는 것..

총기시건함 이중자물쇠와 같다, 열쇠가 하나만있어선 열지못함!
그러면 이걸 어떻게 개선해야 할까?
결국 DOM CSSOM 둘 다 필요한 건 절대로 안 바뀔 것이고..
그렇다면 CSSOM 구성을 가볍게 만들면 되겠다!
단순하게 말해 "필요한 것만 가져와라!" 인 것.
데스크톱화면에서 모바일 버전 스타일을 굳이 챙길 필요가 있을까?
모바일화면에서 굳이 데스크톱 스타일을 챙길 필요가 있을까?
그건 아니기 때문에! style 파일을
각각 따로 만들어서 필요할 때만 그때그때 불러오는 것으로 가볍게 만드는 것이다!
3-8. Render Tree의 구성
DOM도 있고, CSSOM도 있다.
이제는 합쳐야한다!
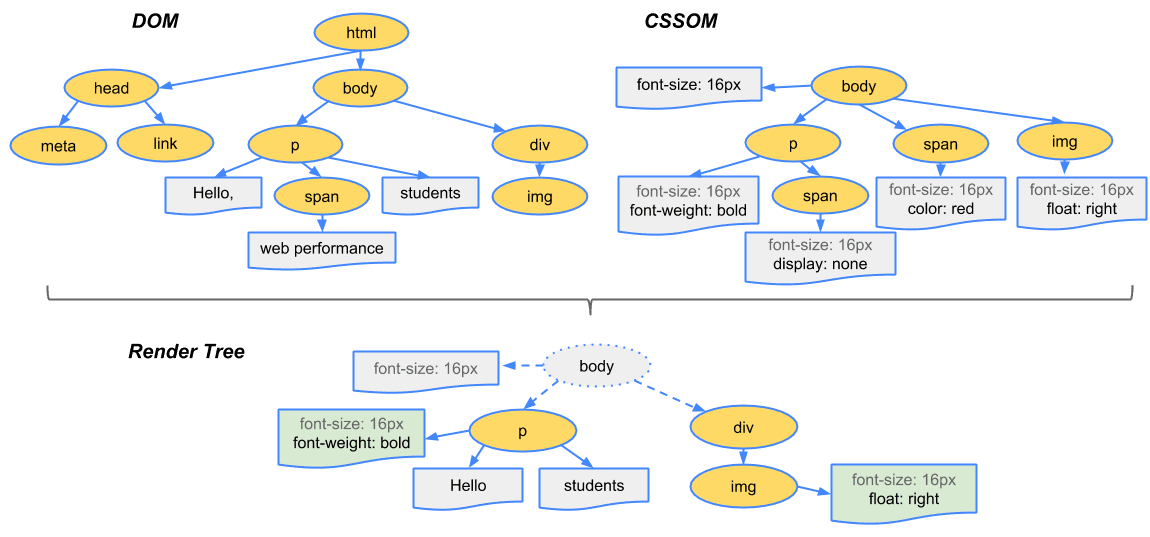
말 그대로 Rendering 할 준비가 완료되어 있는 Tree들,
DOM Tree에 있던 내용과, CSSOM Tree에 있던 스타일을 합친 것.
이게 바로 웹사이트를 그리기 위한 마지막 설계도인 것!
필요한 것들만 남겨두고, 필요 없는 것들은 모조리 쳐낸다.
Head태그, 물론 필요하지만 지금 우리 화면을 그리는데 필요할까?
"No!"
바로 쳐낸다! Body만 들고 가는 것.
A라는 태그의 display가 None이라면
A태그, 지금 우리 Render Tree에 필요한가?
"No!"
A태그로 된 것들? 모조리 쳐낸다!
화면에 필요 없는 요소들은 모조리 빼내고,
정말 최종적으로 화면을 구성하기에 필요한 요소만으로 Render Tree를 만든다.
3-9 Layout
우리가 이런 정말 효율적이고 완벽한 설계도를 준비했다고 해서
바로 그릴 수는 없다.
"어디에 그릴 거냐?"라는 걸 알아야 한다
반응형 웹사이트 같은 걸 만들면서 % 단위를 많이 쓰는데
그 %가 실질적으로 보여주는 크기는 화면에 따라 바뀐다.
PC에선 50%가 대충 900px 될 수도 있겠고
모바일에서는 200px가 될 수도 있는 것.
같은 50%여도 환경에 따라 정확한 px값이 다르기 때문에
계산하는 단계가 바로 Layout 단계이다.
3-10 Paint & Composite
드디어 실제로 그리는 단계!
픽셀 하나하나를 Layout이 "어디에 그려" 라고 지정한곳에 하나하나 그리는데.
이걸 한번에 싹~그려버리는게 아니라

이런식으로 여러겹의 레이어로 나눠서 그린다.
나누는 이유는
그림을 한페이지에 다 그려버리면 하나의 요소가 바뀌었다고 했을때
모조리 새로 그려야하기 때문에
레이어별로 나눠서 바뀐부분의 레이어만 찾아가 바꿀수 있도록 효율을 위해서!
이렇게 오른쪽처럼 나눠서 그린것들을
하나로 합쳐서 왼쪽처럼 보여주는 과정이 Composite
Medium 디자인 정말 예쁘다
그러면 이렇게 User들 화면에선 한 페이지처럼 보이는 것.
그리고 Layout - Paint - Composite 단계는 유저가 웹사이트를 사용할 때
계속 반복되어서 사용된다. 이러한 과정을 Reflow라고 부르고!
대표적인 "Reflow" 될 때로는
초기렌더링, Viewport의 크기변경, 노드의 추가제거, 요소의 위치변경 등이 있겠다
Reflow는 생각보다 무거운 과정이기 때문에
잦은 Reflow는 사이트의 성능저하를 불러온다는 점을 생각하길!
🏷️ 마무리
아직도 뭔가 막 정리를 해놓긴 했는데, 정확하게 이해가 가지는 않는다.
아마 아는게 부족해서 그런거같은데.
마치 "A는 A입니다" 라는 말을 듣고 "A는 A구나" 이해하는정도?
그냥 "아 그렇구나" 정도..
좀 더 공부하다보면 이해할수있을것 같다!
#코드잇스프린트 #스프린트풀스택1기 #취업까지달린다

내용이 체계적인거같네요 ㅎㅎ 이번주도 고생하셨습니다!
아마 3주차부터는 더 빡세질거같은데.. 파이팅입니다!!