설명
LeetCode의 Network Delay Time 문제다.
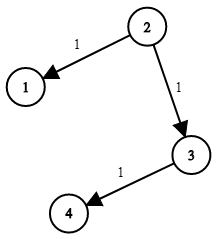 위의 그림처럼 n개의 노드로 이루어진 가중치 방향성 연결 그래프가 주어진다. 노드를 네트워크 상의 호스트라 하고 노드 간 가중치를 이동 시간이라고 할 때 지정된 한 노드에서 시작해서 다른 모든 노드에 데이터를 전송하기까지 얼마나 많은 시간이 걸리는지 계산하는 문제다.
위의 그림처럼 n개의 노드로 이루어진 가중치 방향성 연결 그래프가 주어진다. 노드를 네트워크 상의 호스트라 하고 노드 간 가중치를 이동 시간이라고 할 때 지정된 한 노드에서 시작해서 다른 모든 노드에 데이터를 전송하기까지 얼마나 많은 시간이 걸리는지 계산하는 문제다.
모든 노드에 데이터를 전송하려면 얼마나 많은 시간이 걸리는지는 제일 멀리 있는 노드에 도달하기까지 얼마나 많은 시간이 걸리는지를 계산하는 것과 동일하다. 그렇다고 일부러 길을 멀리 돌아갈 필요는 없는데 문제에서는 어떻게 하면 제일 많은 시간을 들여서 모든 노드에 데이터를 전달할 수 있는지 계산하는 게 아니기 때문이다.
네트워크에서 여러곳에 분산된 노드들에게 데이터를 전송할 때 멀리 돌아가는 경로의 패킷과 최적의 경로의 패킷 중 후자가 더 빨리 도달하는 것은 당연하다. 그렇기 때문에 시작 노드에서 가장 먼 노드까지의 최단 거리를 구하는 문제라고 이해할 수 있다.
풀이
DFS(실패)
이런 종류의 문제를 해결하는 데는 이전에도 사용했던 다익스트라 알고리즘을 이용할 수 있다. 그러나 처음에는 이 점을 눈치채지 못하고 DFS를 이용하여 시도했지만 실패하게 되었다.
import collections
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
# 노드 간 연결 관계 구축.
network = collections.defaultdict(list)
# 노드 간 이동 비용(가중치) 구축.
costs = [[]]
for _ in range(n):
costs.append([101]*(n+1))
# 방향성 그래프기 때문에 한쪽에만 추가.
for time in times:
fromNode, toNode, cost = time
network[fromNode].append(toNode)
costs[fromNode][toNode] = cost
# 방문했던 노드를 저장하는 집합.
visited = set()
# 최장거리를 저장하는 변수 cost
cost = 0
# DFS 탐색을 위한 스택(deque 클래스를 이용)
stack = collections.deque()
stack.append((0, k))
while stack:
# 방문하지 않았던 노드만 탐색.
currentCost, currentNode = stack.pop()
if currentNode in visited:
continue
# 현재 노드까지의 비용으로 최대 비용 갱신.
cost = max(cost, currentCost)
# 현재 노드의 이웃 노드도 탐색.
for neighbor in network[currentNode]:
# 현재 노드까지의 이동거리: currentCost
# 이웃 노드까지의 이동거리: costs[currentNode][neighbor]
stack.append((currentCost+costs[currentNode][neighbor], neighbor))
# 현재 노드는 방문 처리.
visited.add(currentNode)
# 방문했던 노드의 갯수가 모든 노드의 갯수와 다를 경우
# 모든 노드를 방문한 게 아니므로 문제의 조건에 따라 -1 반환.
if len(visited) != n:
return -1
# 그렇지 않을 경우 최대 비용 반환.
else:
return cost평범하게 현재 노드부터 이웃 노드를 탐색하며 스택에 추가하고 최장 거리를 업데이트하는 방식이다. 그러나 이런 방식으로 시도하면 아래와 같은 경우를 해결할 수 없다.
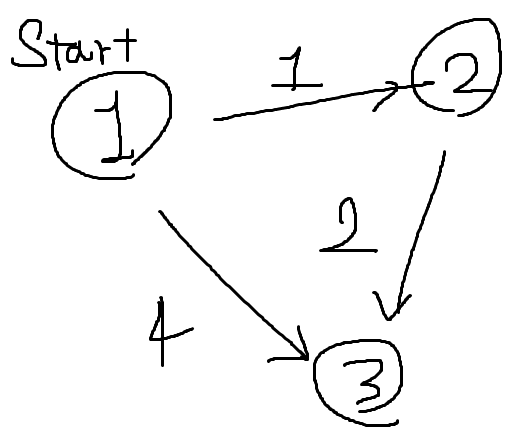 위처럼 1번, 2번, 3번 노드가 있고 1번 노드부터 시작할 때 DFS는 1번 노드에서 2번, 3번 노드를 스택에 삽입한다. 그리고 3번 노드로 이동하며 최장 거리를 1번에서 3번으로 이동하는 4로 갱신한다. 하지만 실제로 1번 노드에서 3번 노드로 이동하는 거리는 1번에서 2번, 2번에서 3번으로 이동하는 1 + 2 = 3이 된다.
위처럼 1번, 2번, 3번 노드가 있고 1번 노드부터 시작할 때 DFS는 1번 노드에서 2번, 3번 노드를 스택에 삽입한다. 그리고 3번 노드로 이동하며 최장 거리를 1번에서 3번으로 이동하는 4로 갱신한다. 하지만 실제로 1번 노드에서 3번 노드로 이동하는 거리는 1번에서 2번, 2번에서 3번으로 이동하는 1 + 2 = 3이 된다.
왜냐면 문제의 이름부터 그렇지만 네트워크 상에서 노드간 데이터 이동 시간을 계산하는 문제기 때문이다. 1번 노드에서 3번 노드로 4초동안 이동할 동안 1번, 2번, 3번 노드로 이동하면서 3초만에 3번 노드로 도달할 수 있기 때문에 이 네트워크에서 최장 거리는 3으로 판단해야 하는 것이다.
그러므로 위의 코드처럼 그냥 더 높은 값으로 갱신시켜가는 방식으로는 풀 수 없었다.
Dijkstra #1(단순 구현, 3408 ms)
DFS 풀이에서 막힌 후 좀 더 조사해보니 이 문제는 다익스트라 알고리즘을 이용하여 푸는 것을 알 수 있었다. 그런데 지난번에 배달 문제를 풀 때 놓친 점이 있었는데 다익스트라 알고리즘에서는 매 탐색마다 가장 가까운(smallest tentative distance) 노드를 기준으로 탐색한다는 것이다.
이 문제를 풀 때는 다른 사람의 풀이를 맹신했기 때문에 놓쳤던 부분이지만 위키피디아의 정의를 다시 읽어보면 다음처럼 가장 가까운 노드를 최우선으로 선택해서 탐색해야 한다는 조건이 있다.
Otherwise, select the unvisited node that is marked with the smallest tentative distance, set it as the new "current node", and go back to step 3.
그때는 가장 가까운 노드가 아닌 단순히 큐(데크)에서 노드를 하나씩 꺼내서 탐색해도 문제가 없었는데 이는 해당 코드에서 노드를 탐색할 때 새로 계산된 거리값(tentative)으로 탐색 대기 큐에 삽입할 지를 판단했기 때문이다.
...
# 기존에 파악된 비용과 현재 노드에서 다시 계산된 비용 비교.
cost = costs[current_village] + fees[current_village][neighbor]
...그래서 만약 과거에 조사한 경로보다 더 길다면 굳이 탐색할 필요가 없으므로 큐에 삽입하지 않아서 항상 최단거리만 탐색할 수 있었다.
하지만 알고리즘 정의 및 의사 코드에서는 우선순위 큐를 이용하여 제일 가까운 거리의 노드부터 우선 탐색했기 때문에 초반에 관련 문서를 찾아보면서 구현할 때 배달 문제의 코드가 계속 떠올라서 많이 헷갈렸다.
그래서 성능에 신경쓰지 않고 알고리즘의 정의를 기반으로 먼저 구현해보기로 했다. 탐색할 노드 중에서 가장 가까운 곳의 노드를 먼저 탐색한다는 점과 이미 방문한 노드는 다시 방문하지 않는다는 점에 집중하여 우선순위 큐를 사용하지 않고 구현하였다.
import collections
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
# 노드 간 연결관계.
network = collections.defaultdict(list)
# 노드 간 가중치.
costs = [[]]
for _ in range(n):
costs.append([101]*(n+1))
# 주어진 데이터를 기반으로 그래프 초기화.
for time in times:
fromNode, toNode, cost = time
network[fromNode].append(toNode)
costs[fromNode][toNode] = cost
# 시작 노드부터 다른 노드까지의 최종 거리.
pivotCosts = [10001] * (n+1)
pivotCosts[k] = 0
# 다익스트라 알고리즘을 위한 탐색 대기열.
queue = [] # (cost, node)
queue.append((0, k))
# 이미 방문한 노드 집합.
visited = set()
while queue:
# 시작 노드에서 가장 가까운 노드 탐색.
pivotCost, pivotNode, pivotIndex = 9999, None, -1
for index, (cost, node) in enumerate(queue):
if cost < pivotCost:
pivotCost, pivotNode, pivotIndex = cost, node, index
# 해당 노드는 대기열에서 삭제. 만약 기존에 방문했던 노드라면 무시.
queue.pop(pivotIndex)
if pivotNode in visited:
continue
# 해당 노드의 이웃 노드를 탐색 대기열에 등록.
for neighbor in network[pivotNode]:
# [i][k] > [i][j] + [j][k]
# 해당 이웃 노드를 이용한 경로가 기존 경로보다 짧을 경우
# 해당 노드를 탐색 대기열에 등록.
calculatedCost = pivotCost + costs[pivotNode][neighbor]
if pivotCosts[neighbor] > calculatedCost:
queue.append((calculatedCost, neighbor))
# 해당 노드는 이제 방문했고 다시 돌아오면 안되기 때문에 집합에 등록.
visited.add(pivotNode)
# 시작 노드부터 현재 노드까지의 거리는 최단 거리라고 가정한다.
pivotCosts[pivotNode] = pivotCost
# 모든 노드를 방문했는지 확인 후 가장 멀리 있는 노드의 거리를 반환.
if len(visited) != n:
return -1
else:
return max([cost for cost in pivotCosts if cost < 10001])다익스트라 알고리즘에 대한 이해가 부족했기 때문에 이 낮은 효율성의 코드를 작성하는 데도 어려움이 많았다. 중요한 점은 다익스트라 알고리즘에서는 한번 방문했던 노드는 최단 거리를 찾은 노드라는 점을 이해하는 것이었다.
이 부분이 굉장히 이해가 안 가는 부분이기도 했는데 당장 처음 시도했던 DFS 풀이의 반례였던 그림을 보면 노드 1에서 탐색을 시작하면 이웃 노드인 노드 2, 노드 3을 탐색하게 되는데 노드 1에서 노드 3을 탐색했을 때 아래처럼 거리가 4라고 판단하게 된다면 이게 최단 거리가 아니지 않나 하는 부분이었다.
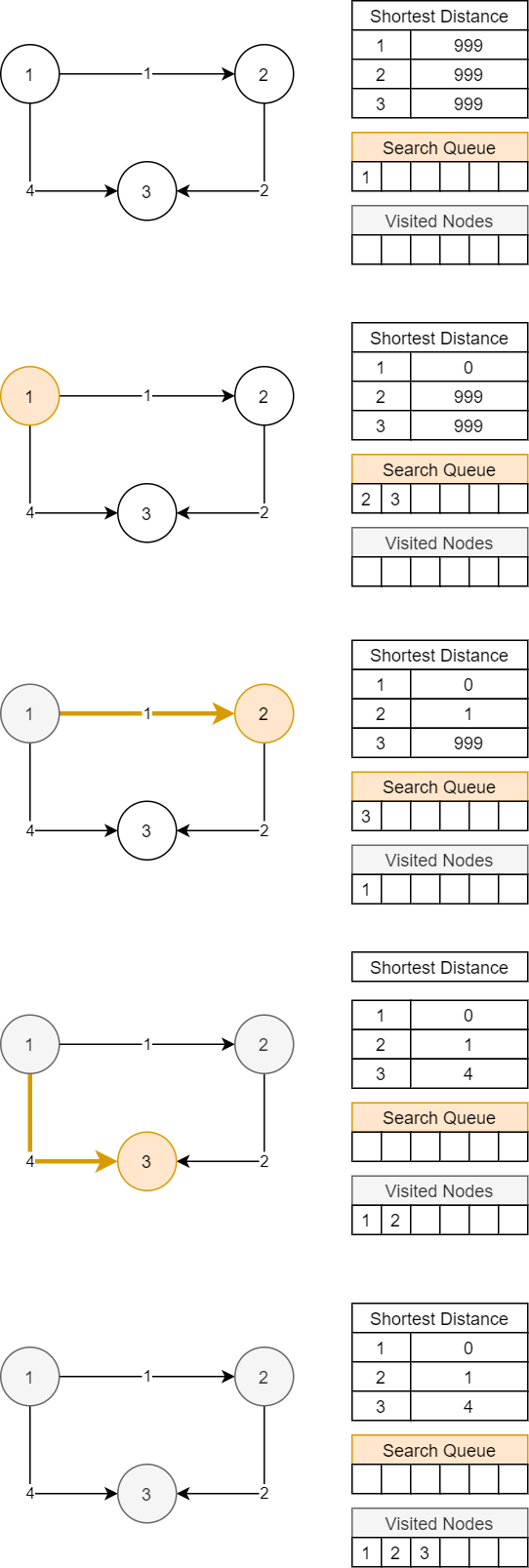 하지만 이는 내가 알고리즘의 중간 과정을 생략하고 결과에만 집중해서 발생한 문제였다. 거기다가 기준 노드에서 가장 가까운 노드를 먼저 탐색한다는 Greedy한 기본 개념을 숙지하지 못했기 때문에 위의 그림처럼 BFS처럼 생각해서 이해가 어려웠던 것이다.
하지만 이는 내가 알고리즘의 중간 과정을 생략하고 결과에만 집중해서 발생한 문제였다. 거기다가 기준 노드에서 가장 가까운 노드를 먼저 탐색한다는 Greedy한 기본 개념을 숙지하지 못했기 때문에 위의 그림처럼 BFS처럼 생각해서 이해가 어려웠던 것이다.
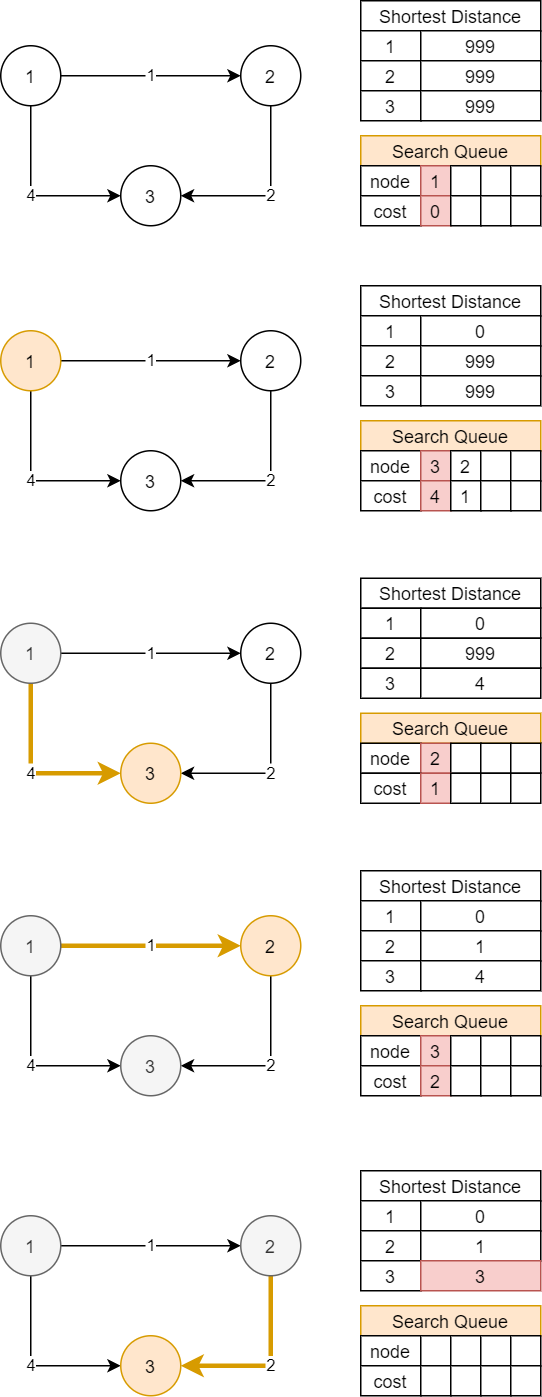
만약 위 그림의 Search Queue가 우선순위 큐라면 어떨까? 이 경우 위와는 달리 시작 노드에서 해당 노드까지의 거리를 기반으로 먼저 탐색할 노드를 고르게 된다.
 3번째 그림을 자세히 보자. Search Queue에서 cost가 더 낮은 노드를 우선으로 탐색하고 있다. 그 결과 1번 노드에서 3번 노드로 가는 4의 비용이 드는 비효율적인 경로 대신 1번, 2번, 3번 노드로 가는 1 + 2 = 3의 비용이 드는 더 효율적인 경로를 진행할 수 있게 된다.
3번째 그림을 자세히 보자. Search Queue에서 cost가 더 낮은 노드를 우선으로 탐색하고 있다. 그 결과 1번 노드에서 3번 노드로 가는 4의 비용이 드는 비효율적인 경로 대신 1번, 2번, 3번 노드로 가는 1 + 2 = 3의 비용이 드는 더 효율적인 경로를 진행할 수 있게 된다.
4번째 그림에서 노드 3은 이미 다익스트라 알고리즘에 의해 최단거리가 탐색된 노드기 때문에 처리되지 않고 무시된다. 이를 위의 코드에서는 pop 연산으로 삭제한 후 visited 집합에 들어있는 노드면 continue로 무시하는 로직으로 구현한 것이다.
그렇다면 왜 배달 문제에서는 이런 방문한 노드를 기억하는 코드가 필요없었던 것일까? 언급했듯이 기존에 파악된 비용과 현재 노드에서 계산된 비용을 비교하여 탐색 여부를 결정했기 때문이다.
위의 예제에서는 현재 노드에서 계산된 비용 4의 노드 3 탐색을 진행할 시점(5번째 그림)이 되면 이미 초기 노드에서 노드 3까지의 최단 거리가 기존에 파악된 비용 3으로 산정(4번째 그림)되어 있다. 그래서 현재 노드에서 계산된 비용이 기존에 파악된 비용보다 더 크다면 이미 다익스트라 알고리즘에 의해 최단거리가 탐색된 비효율적인 경로라고 판단, 탐색하지 않는 방식으로 구현된 것이다.
꽤나 먼 길을 돌아오게 된 풀이였지만 이걸로 다익스트라 알고리즘을 이해하는 데 한층 더 가까워질 수 있었다.
Dijkstra #2(Priority Queue, 484ms)
첫번째 다익스트라 방식은 대기열에서 직접 제일 낮은 비용의 노드를 탐색했기 때문에 효율성이 좋지 않았다. 그래서 이번에는 도서와 LeetCode의 솔루션을 참고하여 우선순위 큐를 활용하여 구현하였다.
import collections
import heapq
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
# 노드 간 연결 관계.
network = collections.defaultdict(list)
# 노드 간 가중치.
costs = [[]]
for _ in range(n):
costs.append([10001]*(n+1))
# 그래프 초기화.
for time in times:
fromNode, toNode, cost = time
network[fromNode].append(toNode)
costs[fromNode][toNode] = cost
# 초기 노드부터 다른 노드까지의 거리.
pivotCosts = [10001] * (n+1)
pivotCosts[k] = 0
# 우선순위 큐(heapq 클래스 활용).
queue = [] # (비용, 노드) 형태의 튜플로 저장.
queue.append((0, k))
# 방문한 노드를 기억하는 집합.
visited = set()
while queue:
# 우선순위 큐에서 제일 낮은 비용의 노드를 추출.
# heapq의 heappop 메서드는 무조건 오름차순으로 반환.
# 튜플 간 비교 시 첫번째 원소, 즉 비용으로 비교하게 됨.
pivotCost, pivotNode = heapq.heappop(queue)
# 만약 방문했던 노드라면, 즉 이미 최단거리가 파악된 노드라면 무시.
if pivotNode in visited:
continue
# 해당 노드의 이웃 노드를 큐에 삽입.
for neighbor in network[pivotNode]:
calculatedCost = pivotCost + costs[pivotNode][neighbor]
heapq.heappush(queue, (calculatedCost, neighbor))
# 해당 노드를 방문, 즉 최단거리가 파악된 상태로 처리.
visited.add(pivotNode)
# 다익스트라 알고리즘에 의해 파악된 최단거리를 반영.
pivotCosts[pivotNode] = pivotCost
# 모든 노드를 방문했다면 가장 먼 노드의 거리를 반환.
if len(visited) != n:
return -1
else:
return max([cost for cost in pivotCosts if cost < 10001])개선된 로직과 heapq 클래스로 우선순위 큐를 이용하여 훨씬 더 빠르고 간략한 코드를 작성할 수 있었다.
Dijkstra #3(Priority Queue, 504ms)
여기서 더 코드를 줄여서 배달 문제처럼 방문한 노드를 기억하지 않고 그냥 비용으로만 비교할 수 있을까? 충분히 가능하다. 위의 코드에서 약간만 변형하면 된다.
import collections
import heapq
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
# 노드 간 연결관계.
network = collections.defaultdict(list)
# 노드 간 가중치.
costs = [[101]*(n+1) for _ in range(n+1)]
# 시작 노드에서 다른 노드까지의 거리.
# 이번에는 현재 노드까지의 거리를 0으로 초기화하지 않는다.
# 밑의 반복문에서 최단 거리를 갱신하는 로직으로 초기화해야 하기 때문.
pivotCosts = [10001] * (n+1)
# 그래프 초기화.
for time in times:
fromNode, toNode, cost = time
network[fromNode].append(toNode)
costs[fromNode][toNode] = cost
# 우선순위 큐
queue = []
queue.append((0, k))
while queue:
# 우선순위 큐에서 꺼낸 경로 pivotNode의 비용 pivotCost
# 기존에 파악된 pivotNode의 비용 pivotCosts[pivotNode]
# 경로를 비교하여 기존에 파악된 경로가 더 효율적이라면 무시.
pivotCost, pivotNode = heapq.heappop(queue)
if pivotCost >= pivotCosts[pivotNode]:
continue
# 그렇지 않다면 현재 노드의 이웃 노드를 큐에 삽입.
for neighbor in network[pivotNode]:
calculatedCost = pivotCost + costs[pivotNode][neighbor]
heapq.heappush(queue, (calculatedCost, neighbor))
# 현재 경로를 최단 경로로 설정.
pivotCosts[pivotNode] = pivotCost
# 모든 노드를 탐색한 경우 최장거리 반환.
visited = [cost for cost in pivotCosts if cost < 10001]
if len(visited) != n:
return -1
else:
return max(visited)기존보다 확실히 변수가 줄어들고 코드도 간단해진 것을 볼 수 있다. 배달 문제도 그렇고 위의 코드에서 중요한 부분은 큐에서 꺼낸 경로를 기존에 탐색된 경로와 비교하는 것이다. 위의 코드와 비교해 봐도 알겠지만 꺼낸 경로를 비교하는 부분이 visited 변수에 현재 노드가 들어있는지 확인하는 부분과 일치한다. 역시 다익스트라 알고리즘의 이미 방문한 노드는 최단거리가 탐색된 노드라는 법칙이다.
한 노드는 여러 노드에 연결되어 있을 수 있고 그 노드로 이어진 경로가 대기열에서 머무르는 도중에 다른 경로에서 최단거리가 발견됐을 수 있기 때문에 비교해줘야 한다는 것을 잊지 말자. 스택오버플로우의 답변을 읽어보면 좋다.
Dijkstra #4(Queue, 708ms)
별로 좋은 방법은 아니지만 #3처럼 비용으로 비교한다면 일반 큐를 사용해도 문제를 해결할 수 있긴 하다.
import collections
class Solution:
def networkDelayTime(self, times: List[List[int]], n: int, k: int) -> int:
# 노드 간 연결관계.
network = collections.defaultdict(list)
# 노드 간 가중치.
costs = [[101]*(n+1) for _ in range(n+1)]
# 시작 노드와 다른 노드 간 거리.
pivotCosts = [10001]*(n+1)
# 그래프 초기화
for time in times:
fromNode, toNode, cost = time
network[fromNode].append(toNode)
costs[fromNode][toNode] = cost
# 일반 큐(데크)
queue = collections.deque()
queue.append((0, k))
while queue:
# 큐에서 경로 추출.
pivotCost, pivotNode = queue.popleft()
# 현재 경로가 최단거리가 아니라면 무시.
if pivotCost >= pivotCosts[pivotNode]:
continue
# 현재 노드의 이웃 노드를 큐에 삽입.
for neighbor in network[pivotNode]:
queue.append((pivotCost + costs[pivotNode][neighbor], neighbor))
# 현재 경로를 최단 경로로 표시.
pivotCosts[pivotNode] = pivotCost
# 모든 노드를 방문했다면 최장거리 반환.
visited = [pivotCost for pivotCost in pivotCosts if pivotCost < 10001]
if len(visited) != n:
return -1
else:
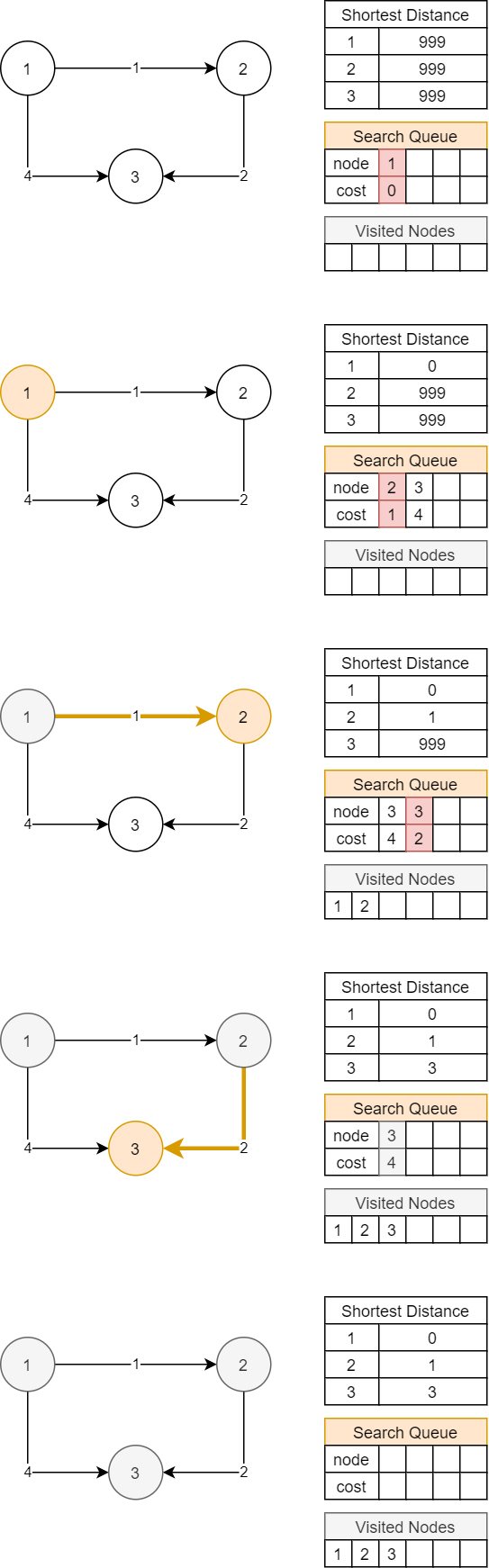
return max(visited)대신 이렇게 우선순위 큐가 아닌 일반 큐를 사용하면 어떤 문제가 있을까? 제일 먼저 생각나는 점은 한 노드에 대한 최단거리가 여러번 갱신될 수 있다는 것이다.
 위의 그림처럼 방문한 노드를 무시하는 로직 대신 최단경로를 항상 갱신하기 때문에 처음에 잘못 산정된 최단경로(노드 3 - 비용 4)라도 나중에 다시 갱신(노드 3 - 비용 3)될 수 있다는 특징이 있다.
위의 그림처럼 방문한 노드를 무시하는 로직 대신 최단경로를 항상 갱신하기 때문에 처음에 잘못 산정된 최단경로(노드 3 - 비용 4)라도 나중에 다시 갱신(노드 3 - 비용 3)될 수 있다는 특징이 있다.
이 정도까지 오면 처음에 탐색한 경로가 최단경로라는 다익스트라 알고리즘의 기본 원리에 위배되는게 아닌가 싶다. 확실한 점은 우선순위 큐가 아니기 때문에 Greedy하지 않아 처음 탐색한 경로가 최단경로인지 확신할 수 없다. 그래서 계속 확인해야 하느라 시간도 좀 더 걸리긴 하지만 일단 풀리긴 하므로 신기할 따름이고 배달 문제도 이런 원리로 풀렸던 게 아닐까 생각한다.
후기
다익스트라 알고리즘은 Greedy 알고리즘에 속한다고 한다. 항상 현재 상황에서 최적의 해만 찾아가는 알고리즘이 어떻게 최단 거리를 찾을 수 있는 것인가라는 의문이 있었는데 현재 상황이 단순히 현재 노드와 인접한 이웃 노드간 거리가 아니라 지금까지 소모한 비용까지 종합해서 판단하는 방식이라는 것을 이제서야 알게되었다.
이전에 프로그래머스 문제를 풀 때 다른 사람의 풀이를 베끼면서 나름대로 이해할 수 있었다고 생각했지만 이번에 문제를 풀면서 내 생각이 틀렸다는 것을 알 수 있었다. 앞으로 좀 더 꼼꼼히 학습해야 할 것이다.
