Tabular Data 정의
-
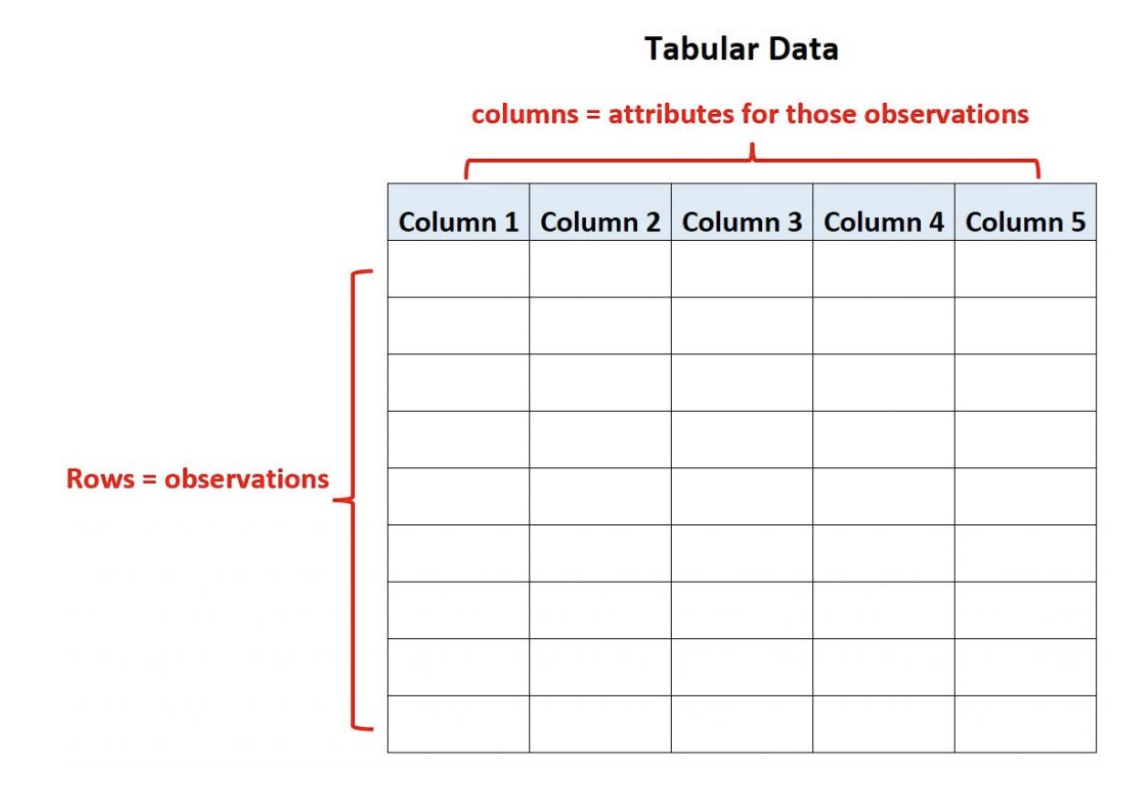
Tabular data란 산업 현장의 엑셀 시트에서 아주 흔하게 볼 수 있는 형태로, feature는 컬럼에, sample을 row 방향에 위치한 정형데이터 구조이다.
-
산업현장에서 주로 사용되는 RDMS(관계형 데이터베이스)는 하나 이상의 데이블로 이루어져 있으며, 각 테이블은 key와 value의 관계를 통해 표현하고 싶은 대상을 추상화한다.
-
간단히 설명하면, 테이블형태의 정형데이터를 우리는 tabular data라고 이해하면 될 거 같다.
머신러닝에서의 Tabular Data 활용
- 통상적인 머신러닝의 데이터로 tabular data가 제공되며 이것을 이용하여 캐글과 같은 대회에서 트리 계열의 boosting 방법론으로 좋은 성능을 보여주고 있다.
- 그 중 핵심은 feature selection, feature importance가 중요하다.
딥러닝
- 딥러닝 분야에서는 대부분 이미지, 음성, 언어와 같은 비정형 데이터에서 인상적인 성능을 보여준다.
- 정형데이터(tabular data)는 머신러닝을 이용한 트리기반의 모델들이 딥러닝만큼 좋은 성능을 내고 있어 주목받지 못하는 경우가 많다고 한다.
- 그래서 정형데이터를 딥러닝 장점을 활용한 모델들도 계속해서 연구되어 지고 있다. 그 중 Tabnet이라는 모델에 대해서 다음 기회에 포스팅 해보려고 한다.
참고
http://dmqm.korea.ac.kr/activity/seminar/327
https://inhovation97.tistory.com/65
이미지 출처 :https://www.statology.org/tabular-data/

부지런한 개발자가 되고싶은