🐼 문제 정의
- 독립변수 : 4개 변수(꽃받침길이, 꽃받침너비, 꽃잎길이, 꽃잎너비)
- 종속변수 : 아이리스 품종 3가지(Iris Setosa, Iris Versicolour, Iris Virginica)
- 데이터셋 총 수 150 (각 품종 별 50개 데이터)
- 4개 변수(각 꽃의 길이 너비 등)를 독립변수로 보고 아이리스 품종을 분류하는 다중 분류 문제로 정의
라이브러리 임포트
import pandas as pd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.optimizers import RMSprop
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
데이터 준비
dataset_path = tf.keras.utils.get_file("iris.data", "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data")- 원본 파일을 보면 컬럼명이 나와있지 않기 때문에 컬럼명을 지정해주고 열기
column_names = ['sepal length','sepal width','petal length','petal width','class']
raw_dataset = pd.read_csv(dataset_path, names=column_names)
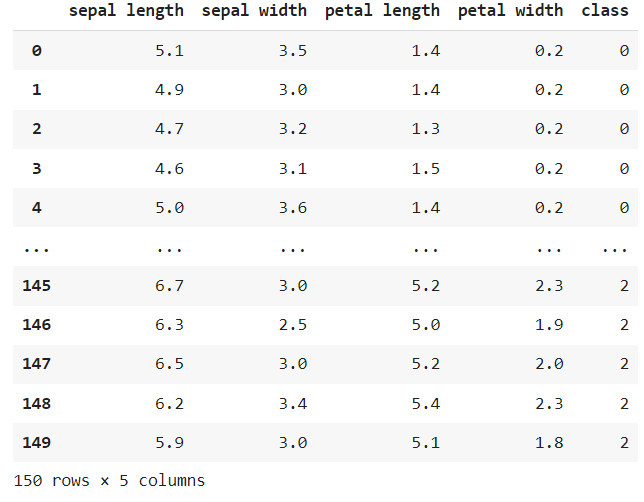
dataset = raw_dataset.copy()- dataset
데이터 전처리
Iris-setosa -> 0
Iris Versicolour -> 1
Iris-virginica -> 2
label_encoder = preprocessing.LabelEncoder()
l_class = label_encoder.fit_transform(dataset['class'])
dataset['class'] =l_class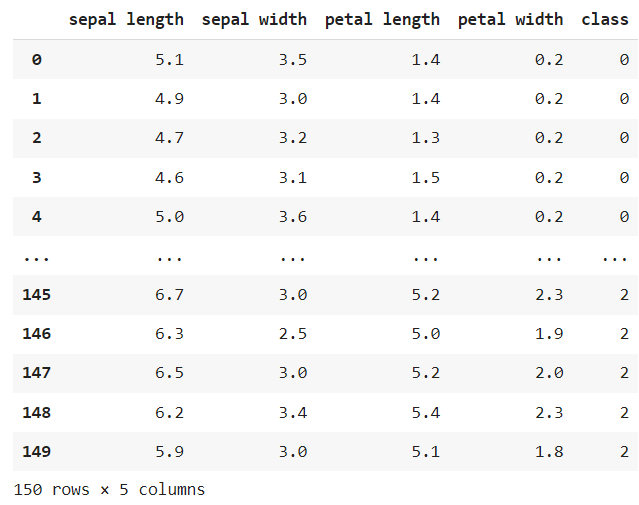
데이터셋 생성
X = dataset[['sepal length','sepal width','petal length','petal width']]
y = dataset['class']
# 학습 데이터: 120건(80%), 테스트 데이터: 30건(20%)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=7)class 원-핫인코딩
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)- y_trai을 출력해보면 다음과 같이 적용되었다.

모델 구성
np.random.seed(7)
model = Sequential()
# 입력뉴런 4개, 퍼셉트론 개수 16, 활성화함수 relu
model.add(Dense(16, input_shape=(4, ), activation='relu'))
# 출력뉴런 3개, 활성화함수 softmax
model.add(Dense(3, activation='softmax'))모델 학습
# 손실함수(loss): categorical_crossentropy , optimizer(하이퍼파라미터) : Adam , metrics : accuracy
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=200, batch_size=10)모델 평가
scores = model.evaluate(X_test, y_test)
print("%s: %2.f%%" %(model.metrics_names[1], scores[1]*100))
👩🏻🎓 [참고] 교수님코드
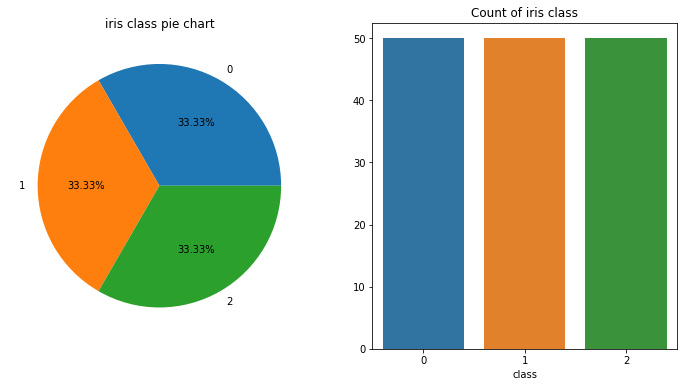
📊 차트
f, ax = plt.subplots(1,2, figsize=(12,6)) dataset['class'].value_counts().plot.pie(explode=None, autopct='%1.2f%%', ax=ax[0]) ax[0].set_title('iris class pie chart') ax[0].set_ylabel('') sns.countplot('class', data=dataset, ax=ax[1]) ax[1].set_title('Count of iris class') ax[1].set_ylabel('') plt.show()
🔧 레이블을 범주형 형태로 변경하는 방법
from sklearn.preprocessing import LabelEncoder from keras.utils import np_utils encoder = LabelEncoder() encoder.fit(y) Y_encodered = encoder.transform(y) # 라벨링 Y = np_utils.to_categorical(Y_encodered)

배고파용.