🐼 정보
디카프리오 : 3등실 탑승, 남성, 19살, 형제 없고, 부모나 자녀 없음, 싼 가격으로 표 구매
윈슬렛 : 1등실 탑승, 여성, 17살, 운임은 비싸게 주었고, 부모와 함께 탑승하고, 약혼자 있음문제정의
- 타이타닉 탑승자 명단을 통해 생존자 분석 -> 타이타닉 주인공들 생존 확률 구해보기 !
- 6개 독립변수 : 'pclass', 'sex', 'age', 'sibsp','parch','fare'
- 1개 종속변수 : 'survived'
🐼 데이터 준비
import pandas as pd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.optimizers import RMSprop
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
df = pd.read_excel('/content/titanic.xlsx',header=0, engine='openpyxl') # 엑셀파일 열기위한 코드
df.head()
📈 차트
사망자와 생존자 비율 시각화
👀 0(사망) , 1(생존)
- 파이차트
explodes =(0.1, 0)
df['survived'].value_counts().plot.pie(autopct='%.2f%%', explode=(0.1,0))
plt.title("Survived")
plt.show()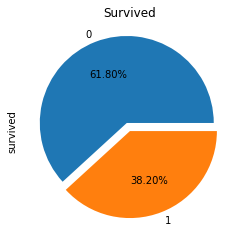
- 바차트
sns.countplot(data=df, x='survived')
plt.title("Survived")
plt.show()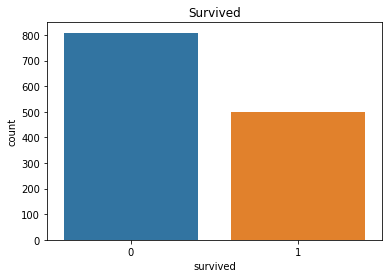
객실 등급별 생존자
sns.barplot(x="pclass", y="survived", data=df);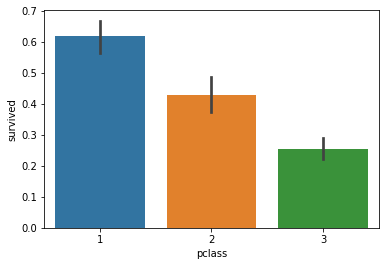
성별별 생존자
sns.barplot(x="sex", y="survived", data=df);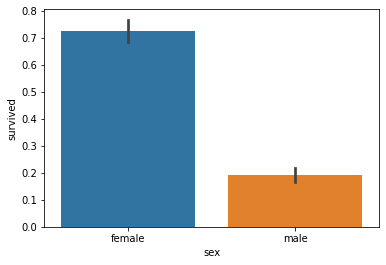
💫 데이터 전처리
dataset = df.loc[:, ['pclass', 'sex', 'age', 'sibsp','parch','fare','survived']]
dataset.isna().sum()- NaN이 age와 fare 컬럼에 있음을 알 수 있다.
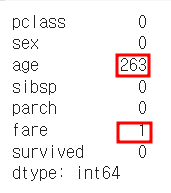
다음의 코드를 추가하면 age와 fare컬럼의 NaN값이 있는 행을 제거가능
dataset = dataset.dropna(subset=['age','fare'], how='any', axis=0)data의 age컬럼을 보면 여자는 female, 남자는 male로 되어 있는데 이를 여자는 1, 남자는 0으로 라벨링 해준다. 다음의 코드를 추가한다
dataset['sex'] = df.apply(lambda x: 0 if x['sex'] == 'male'
else 1, axis = 1)
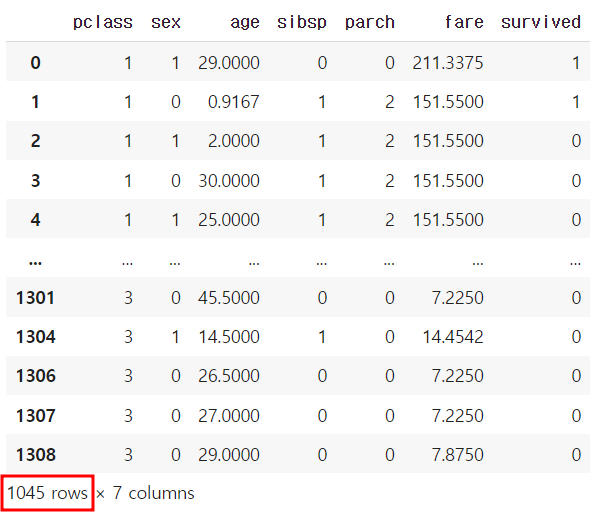
- 최종적으로 1308건에서 1045건의 데이터로 변경되었다.
모델 구성
- 훈련 셋 940건(90%), 테스트 셋 105건 (10%)
– Dense 레이어만을 사용하여 신경망 모델을 구성데이터 준비하기
– 속성 6개 : 입력 뉴런 6개, Dense 레이어 개수 255, 활성화 함수 relu - 마지막 출력 Dense 레이어 이진 분류이기 때문에 0~1사이의 값을 나타내는 출력 뉴런 : 1개
- 활성화 함수 sigmoid
#dataset -> X,y 독립변수 종속변수 분리
X = dataset[['pclass', 'sex', 'age', 'sibsp','parch','fare']]
y = dataset['survived']
np.random.seed(777)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.1,random_state=7)정규화
mean = np.mean(X_train, axis=0) # 모든 row를 반영한 평균
std = np.std(X_train, axis=0)
X_train = (X_train - mean) / std
X_test = (X_test - mean) / std# 모델 구성하기
model = Sequential()
model.add(Dense(255, input_shape=(6,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 설정하기
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
# 모델 학습하기
history = model.fit(X_train, y_train, epochs=300)모델 평가
score = model.evaluate(X_test, y_test)
print('%s: %.2f%%' %(model.metrics_names[1], score[1] * 100))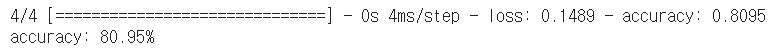
💔디카프리오, 윈슬렛의 경우💔
- 'pclass', 'sex', 'age', 'sibsp','parch','fare' 순서
- 디카프리오 : 3등실 탑승, 남성, 19살, 형제 없고, 부모나 자녀 없음, 싼 가격으로 표 구매
- 윈슬렛 : 1등실 탑승, 여성, 17살, 운임은 비싸게 주었고, 부모와 함께 탑승하고, 약혼자 있음
dicaprio = np.array([3., 0., 19., 0., 0., 5.])
winslet =np.array([1., 1., 17., 1., 2., 100.])
dicaprio = (dicaprio - mean) / std
winslet = (winslet - mean) / std
dicaprio = np.array(dicaprio).reshape(1,6)
winslet = np.array(winslet).reshape(1,6)
d_predict = model.predict(dicaprio)
w_predict = model.predict(winslet)
print('디카프리오 생존 예측 : %.2f%%' %(d_predict * 100))
print('윈슬렛의 생존 예측 : %.2f%%' %(w_predict * 100))디카프리오 생각보다높당

👩🏻🎓 교수님 코드
f, ax = plt.subplots(1,2, figsize=(12,6))
df['survived'].value_counts().plot.pie(explode=[0,0.1], autopct='%1.2f%%', ax=ax[0])
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('survived', data=df, ax=ax[1])
ax[1].set_title('Survived')
plt.show()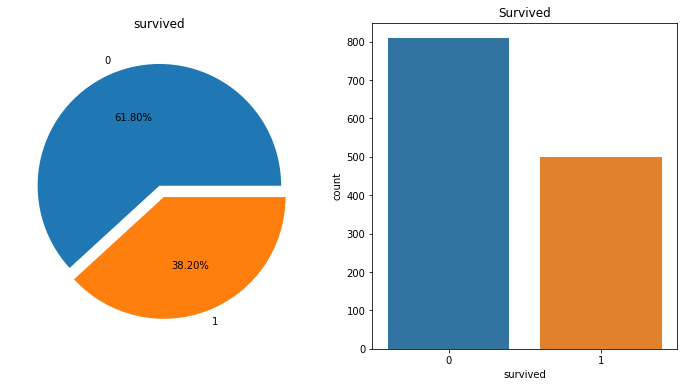
f, ax = plt.subplots(1,2, figsize=(12,6))
sns.countplot('sex', data=df, ax=ax[0])
ax[0].set_title('Count of Passengers by Sex')
sns.countplot('sex', hue='survived', data=df, ax=ax[1])
ax[1].set_title('Sex:Survived vs Dead')
plt.show()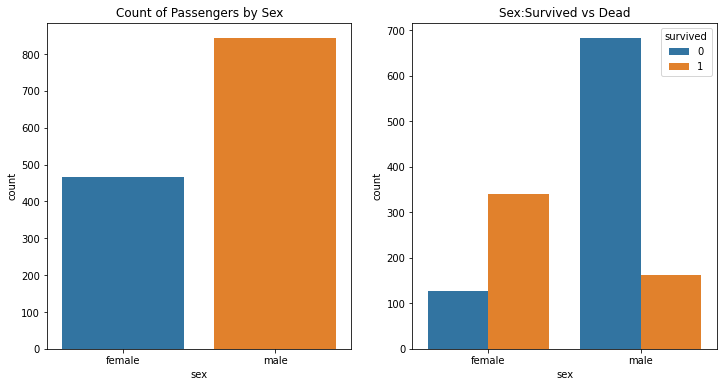
age_category 컬럼 추가
df['age_cat'] = pd.cut(df['age'], bins=[0,10,20,50,100], include_lowest=True, labels=['baby','teenage','adult','old'])
df[['age', 'age_cat']]
plt.figure(figsize=[12,4])
plt.subplot(131) # 한 줄에 세개 중 첫번째
sns.barplot('pclass','survived',data=df)
plt.subplot(132)
sns.barplot('age_cat','survived', data=df)
plt.subplot(133)
sns.barplot('sex','survived', data=df)
plt.subplots_adjust(top=1, bottom=0.1, left=0.10, right=1, hspace=0.5, wspace=0.5)
plt.show()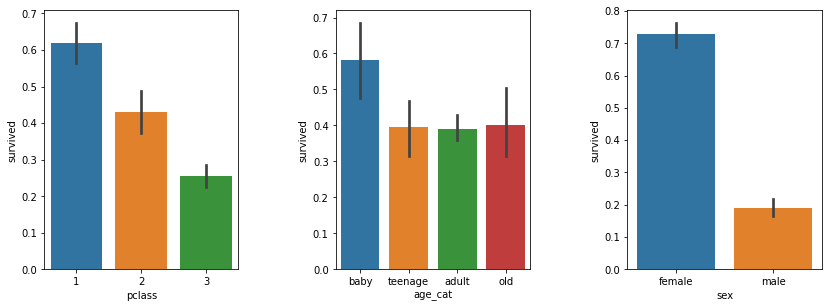

배고파용.