🐼 pandas 🐼
- panel datas의 약자
- 파이썬을 활용한 데이터 분석에서 가장 많이 활용됨
- Series : 1차원 배열 형태의 데이터구조
- DataFrame : 2차원 배열 형태의 데이터구조
🐶 DataFrame 🐶
- 행과 열로 구분
- 인덱스 : 행을 구분, 별도로 지정하지 않으면 정수로 지정(한번 설정되면 변경불가)
- 컬럼 :열을 구분
- 셀과 셀 연산이 가능
🐼 데이터준비
🐻❄️ pandas문법
loc, iloc : 데이터프레임의 row 또는 column에 접근하는 방법
loc : label이나 boolean array로 접근
- 참고 : https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.html
iloc : index값으로 접근
- 참고 : https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
axis
- axis=0 : 행 방향을 축으로 계산
- axis=1 : 열 방향을 축으로 계산

🦁 데이터 읽어오기
import pandas as pd
df = pd.read_csv('/content/age_2019.csv', encoding='utf-8')🐯 데이터 전처리
# 행정구역 컬럼의 행정코드를 삭제하고 주소 데이터만 사용
# ex) 서울특별시 종로구 삼청동(111105400) -> 서울특별시 종로구 삼청동
names_split = df['행정구역'].str.split('(')
df['행정구역'] = names_split.str.get(0)
# 행정구역을 제외한 컬럼명 변경
columns_list = df.columns
final_col = {}
for col in columns_list[1:]: # slice 이유? 행정구역 제외하고 실행
final_col[col] = col.split('_')[2] # dictionary 문법
# 컬럼명 변경
df.rename(columns=final_col, inplace=True)
# 데이터 콤마 제거하고 숫자형태로 변환
df.replace('[^\w]','', regex=True, inplace=True) # 정규식을 사용한 모든 컬럼의 특수기호 제거
# 인덱스 변경 0, 1, 2 -> 서울특별시, 서울특별시 종로구 . .
df.set_index(keys=['행정구역'], inplace=True)
# 형변환
df = df.astype('int')
df.info()
df.isna().sum() # NaN 데이터 확인
df.dropna(inplace=True) # NaN 데이터 제거🦒 비율계산 / 불필요데이터 삭제
# 전체데이터 / 총인구수
df = df.div(df['총인구수'], axis=0)
# 총 인구수와 연령구간 인구수 삭제
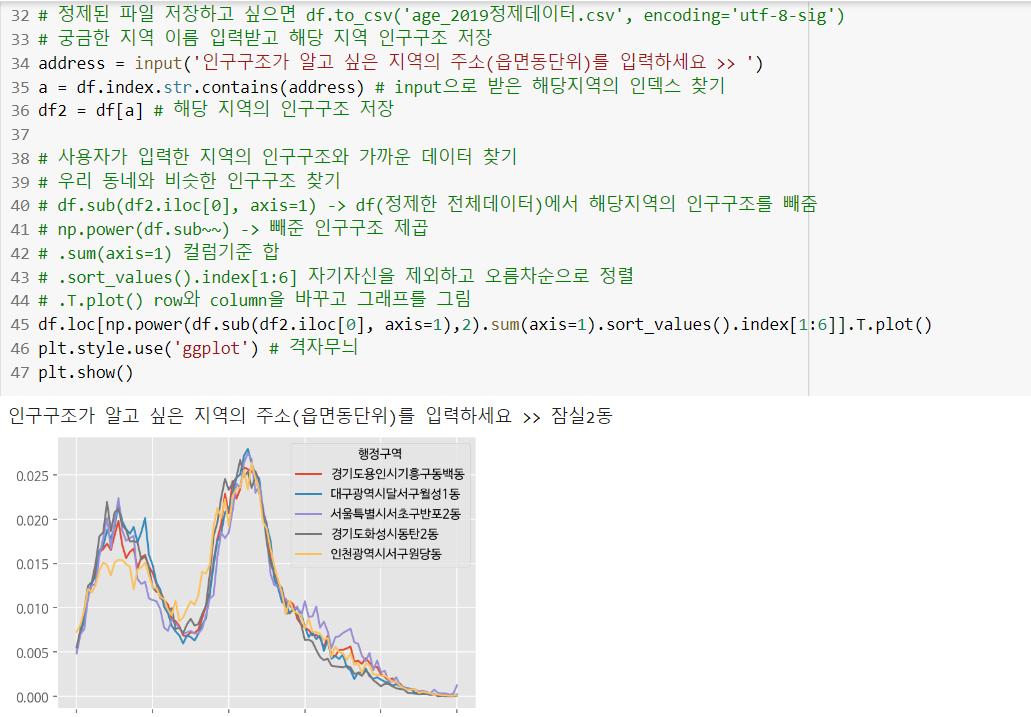
del df['총인구수'], df['연령구간인구수']➕ 정제된 파일 저장 df.tocsv('2019인구구조_정제데이터.csv', encoding='utf-8-sig')
🐮 인구구조 저장/ 시각화
🐷 비슷한 인구구조 찾기/시각화
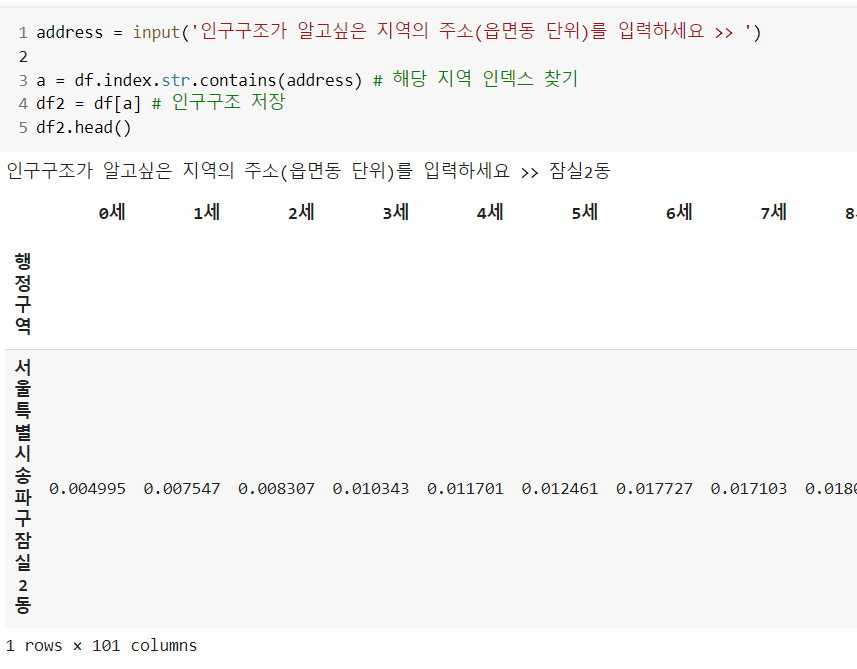
# 사용자가 선택한 인구구조와 가까운 데이터 찾기 home - away
df.sub(df2.iloc[0], axis=1)
# 우리동네와 비슷한 인구구조 찾기
import numpy as np
np.power(df.sub(df2.iloc[0],axis=1),2).sum(axis=1).sort_values().index[1:6] # 자기자신은 빼고
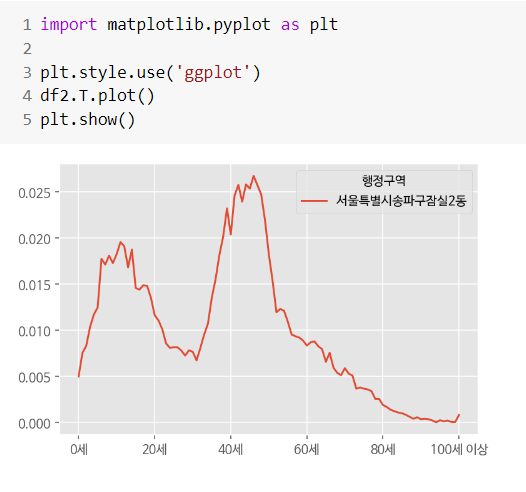
# 우리동네와 비슷한 인구구조 시각화
df.loc[np.power(df.sub(df2.iloc[0],axis=1),2).sum(axis=1).sort_values().index[1:6]].T.plot()
plt.show()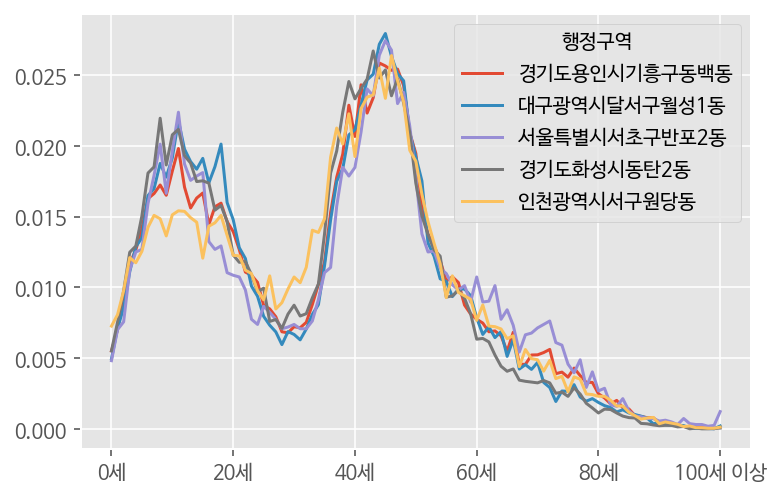
# 데이터 읽어오기 import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('/content/age_2019.csv', encoding='utf-8') # csv파일 가져오기 # 데이터 전처리 name_split = df['행정구역'].str.split('(') # 행정구역 컬럼을 string형태로 변환 후 ( 기준으로 나눔 df['행정구역'] = name_split.str.get(0) # 나눠진 name_split의 0번째 컬럼만을 행정구역으로 지정 # 행정구역 제외 컬럼명 변경 columns_list = df.columns # 컬럼 명들을 저장 final_col = {} # 딕셔너리 형태 for col in columns_list[1:]:# 행정구역을 제외한 컬럼명들만 final_col[col] = col.split('_')[2] # _기준 두번째를 딕셔너리의 value로 지정 # 컬럼명 변경 df.rename(columns=final_col, inplace=True) # inplace = True : 바로 실행해라 # 데이터들을 콤마를 제거하고 숫자형태로 변환 df.replace('[^\w]','', regex=True, inplace=True) # regex=True 정규 표현식으로 문자열 치환을 원하는 부분만 # 인덱스 변경 df.set_index(keys=['행정구역'], inplace=True) # 인덱스를 0,1,2..같은값들이 아닌 행정구역 명으로 지정해줌 # 형변환 df = df.astype('int') # df의 type을 int(정수형)로 변경 df.dropna(inplace=True) #NaN데이터 제거 # 전체 데이터 / 총 인구수 => 비율계산 df = df.div(df['총인구수'], axis=0) # 전체 데이터를 총 인구수로 나눔 # 총 인구수, 연령구간 인구수 삭제(비율로 계산하기 때문에 모두 그 값이 1이므로 필요없음 ) del df['총인구수'], df['연령구간인구수'] # 정제된 파일 저장하고 싶으면 df.to_csv('age_2019정제데이터.csv', encoding='utf-8-sig') # 궁금한 지역 이름 입력받고 해당 지역 인구구조 저장 address = input('인구구조가 알고 싶은 지역의 주소(읍면동단위)를 입력하세요 >> ') a = df.index.str.contains(address) # input으로 받은 해당지역의 인덱스 찾기 df2 = df[a] # 해당 지역의 인구구조 저장 # 사용자가 입력한 지역의 인구구조와 가까운 데이터 찾기 # 우리 동네와 비슷한 인구구조 찾기 # df.sub(df2.iloc[0], axis=1) -> df(정제한 전체데이터)에서 해당지역의 인구구조를 빼줌 # np.power(df.sub~~) -> 빼준 인구구조 제곱 # .sum(axis=1) 컬럼기준 합 # .sort_values().index[1:6] 자기자신을 제외하고 오름차순으로 정렬 # .T.plot() row와 column을 바꾸고 그래프를 그림 df.loc[np.power(df.sub(df2.iloc[0], axis=1),2).sum(axis=1).sort_values().index[1:6]].T.plot() plt.style.use('ggplot') # 격자무늬 plt.show()
🚩 소감 🚩
 처음 pandas를 이용해서 데이터분석 수업을 진행하셨는데, 어제까지 배운 과정보다는 간단해진건 확실한데 처음배우는 문법 .. ?이라 이해하기 어려웠다. 특히 데이터전처리하는 부분에서 혼이 쏙 빠졋당ㅎ.ㅎ.ㅎ....ㅎ............아직 뭔가 내 머릿속에서 정리가 안된것같아서 정리하는 시간을 가져야 할 것 같다.
처음 pandas를 이용해서 데이터분석 수업을 진행하셨는데, 어제까지 배운 과정보다는 간단해진건 확실한데 처음배우는 문법 .. ?이라 이해하기 어려웠다. 특히 데이터전처리하는 부분에서 혼이 쏙 빠졋당ㅎ.ㅎ.ㅎ....ㅎ............아직 뭔가 내 머릿속에서 정리가 안된것같아서 정리하는 시간을 가져야 할 것 같다.

배고파용.
글을 보니 이미 Pandas에 대한 정리를 잘 한 것 같은데.. 무려 은주의 인장은 판다인데 ㅎㅎ 판다의 장인이 되어 봅시다 ㅎㅎ