🏠 보스턴 주책 가격 예측
문제 정의
1970년대 보스턴 지역의 주택 가격을 예측하는 회귀(연속적인 값) 문제
보스턴 주택 가격 데이터셋 다운로드
from tensorflow.keras.datasets.boston_housing import load_data
(X_train, y_train), (X_test, y_test) = load_data(path='boston_housing.npz', test_split = 0.2, seed=777)
X_train.shapeX_train.shape -> (404,13)
데이터 전처리 및 검증 데이터셋 만들기
import numpy as np
# 1) feature 전처리 -> 정규화 -> 표준화(Standardization) -> 실제 값을 평균(mean)으로 뺀 다음 표준편차 나누는 것
mean = np.mean(X_train, axis=0) # 모든 row를 반영한 평균
std = np.std(X_train, axis=0)
X_train = (X_train - mean) / std
X_test = (X_test - mean) / std

from sklearn.model_selection import train_test_split
# 2) 훈련 데이터셋 / 검증 데이터셋 분리
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.33, random_state=777)모델 구성하기
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(13,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(1)) # 하나의 출력 값 activation default : linear모델 설정, 학습하기
model.compile(optimizer='adam', loss='mse', metrics=['mae', 'mse'])
history = model.fit(X_train, y_train, epochs=300, validation_data=(X_val, y_val))모델 결과 그리기
import matplotlib.pyplot as plt
his_dict = history.history
mse = his_dict['mse']
val_mse = his_dict['val_mse'] # 검증 데이터가 있는 경우 ‘val_’ 수식어가 붙습니다.
epochs = range(1, len(mse) + 1)
fig = plt.figure(figsize = (10, 5))
# 훈련 및 검증 손실 그리기
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, mse, color = 'blue', label = 'train_mse')
ax1.plot(epochs, val_mse, color = 'orange', label = 'val_mse')
ax1.set_title('train and val mse')
ax1.set_xlabel('epochs')
ax1.set_ylabel('mse')
ax1.legend()
mae = his_dict['mae']
val_mae = his_dict['val_mae']
# 훈련 및 검증 정확도 그리기
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, mae, color = 'blue', label = 'train_mae')
ax2.plot(epochs, val_mae, color = 'orange', label = 'val_mae')
ax2.set_title('train and val mae')
ax2.set_xlabel('epochs')
ax2.set_ylabel('mae')
ax2.legend()
plt.show()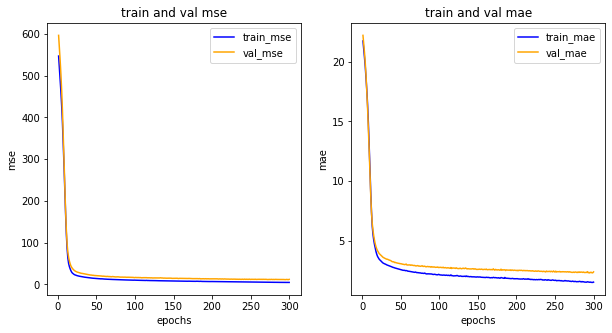
모델 평가하기
model.evaluate(X_test, y_test)
모델 예측결과 그리기
test_predictions = model.predict(X_test).flatten()
plt.scatter(y_test, test_predictions)
plt.xlabel('True Values [Price]')
plt.ylabel('Predictions [Price]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])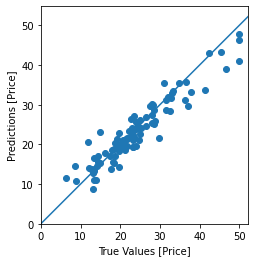
K-Fold 사용하기
- 데이터 개수가 적은 경우 성능을 향상시킬 수 있는 좋은 방법 : 교차검증
- 결과를 확인해보면 모든 모델이 전부 좋은 성능을 가지지는 않음
-> 각 폴드에서 사용한 학습, 검증 데이터가 다르기 때문
-> 두번째 모델은 상대적으로 테스트 모델과 더 비슷한 분포의 데이터를 학습했다고 볼 수 있음- 이 때문에 최종 학습 결과는 평균을 사용
from tensorflow.keras.datasets.boston_housing import load_data from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense import numpy as np from sklearn.model_selection import KFold (x_train, y_train), (x_test, y_test) = load_data(path='boston_housing.npz', test_split=0.2, seed=777) # 데이터 표준화 mean = np.mean(x_train, axis = 0) std = np.std(x_train, axis = 0) # 여기까진 전부 동일합니다. x_train = (x_train - mean) / std x_test = (x_test - mean) / std #---------------------------------------- # K-Fold를 진행해봅니다. k = 3 # 주어진 데이터셋을 k만큼 등분합니다. # 여기서는 3이므로 훈련 데이터셋(404개)를 3등분하여 # 1개는 검증셋으로, 나머지 2개는 훈련셋으로 활용합니다. kfold = KFold(n_splits=k) # 재사용을 위해 모델을 반환하는 함수를 정의합니다. def get_model(): model = Sequential() model.add(Dense(64, activation = 'relu', input_shape = (13, ))) model.add(Dense(32, activation = 'relu')) model.add(Dense(1)) model.compile(optimizer = 'adam', loss = 'mse', metrics = ['mae']) return model mae_list = [] # 테스트셋을 평가한 후 결과 mae를 담을 리스트를 선언합니다. # k번 진행합니다. for train_index, val_index in kfold.split(x_train): # 해당 인덱스는 무작위로 생성됩니다. # 무작위로 생성해주는 것은 과대적합을 피할 수 있는 좋은 방법입니다. x_train_fold, x_val_fold = x_train[train_index], x_train[val_index] y_train_fold, y_val_fold = y_train[train_index], y_train[val_index] # 모델을 불러옵니다. model = get_model() model.fit(x_train_fold, y_train_fold, epochs = 300, validation_data = (x_val_fold, y_val_fold)) _, test_mae = model.evaluate(x_test, y_test) mae_list.append(test_mae) print(np.mean(mae_list))
🚙 자동차 연비 예측
모델 구성
- 회귀는 가격이나 확률 같이 연속된 출력 값을 예측하는 것이 목적
- 1970년대 후반과 1980 초반의 자동차 연비 예측하는 모델 만들기
- 두번째 층 Dense 레이어 개수 64, 활성화 함수 relu 마지막 출력 Dense 연비 예측으로 출력 뉴런이 1개, 활성화 함수 linear
모델 학습과정 설정
- loss='mse', optimizer=RMSprop(0.001), metrics=['mae','mse']
라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Dense
from tensorflow.keras.optimizers import RMSprop
import warnings
warnings.filterwarnings('ignore')데이터 준비
dataset_path = tf.keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
#연비, 실린더, 배수량, 마력, 중력, 가속, 연식, 제조국(1;USA, 2;Europe, 3;Japan)
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight', 'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names, na_values='?', comment='\t', sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()👀
- na_values = 특정 기호(여기서는 '?') 들을 null 처리
- comment = '\t' 부터나오는 특정 문자는 주석으로 간주하여 읽지 않음
- sep = 어떤 기준으로 읽어들일지
- skipinitialspace : True의 경우, delimiter의 직후에 있는 공백은 무시
데이터 전처리
dataset.isna().sum()- Horsepower 에 6개 존재

dataset = dataset.dropna()
dataset.isna().sum()- 삭제됨
# Origin(제조국) 수치형 -> 범주형 변경 -> 원핫인코딩
origin = dataset.pop('Origin') # 잘라내고 복사하기
dataset['USA'] = (origin == 1) * 1.0
dataset['Europe'] = (origin == 2) * 1.0
dataset['Japan'] = (origin == 3) * 1.0- dataset.head()
훈련 데이터와 테스트 데이터로 분할
train_dataset = dataset.sample(frac=0.8, random_state=0) # 80%를 임의 추출
test_dataset = dataset.drop(train_dataset.index) # 80%를 임의추출한 index를 삭제하고 남은20% 담기X(특성, 독립변수, 문제집) y(레이블, 종속변수, 정답지)로 분리
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
train_dataset
데이터 정규화 -> 표준화
mean = np.mean(train_dataset, axis=0)
std = np.std(train_dataset, axis=0)
train_dataset = (train_dataset - mean) / std
test_dataset = (test_dataset - mean) / std
train_dataset.head()
학습 모델 만들기
몇개의 feature -> len(train_dataset.keys())
np.random.seed(7)
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]))
model.add(Dense(64, activation='relu'))
model.add(Dense(1)) # linear모델 설정, 학습
# 설정
model.compile(optimizer=RMSprop(0.001), loss='mse', metrics=['mae','mse'])
# 학습
history = model.fit(train_dataset, train_labels, epochs=500)모델 그리기
import matplotlib.pyplot as plt
his_dict = history.history
mse = his_dict['mse']
epochs = range(1, len(mse) + 1)
fig = plt.figure(figsize = (10, 5))
# 훈련 및 검증 손실 그리기
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, mse, color = 'blue', label = 'train_mse')
ax1.set_title('train mse')
ax1.set_xlabel('epochs')
ax1.set_ylabel('mse')
ax1.legend()
mae = his_dict['mae']
# 훈련 및 검증 정확도 그리기
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, mae, color = 'blue', label = 'train_mae')
ax2.set_title('train mae')
ax2.set_xlabel('epochs')
ax2.set_ylabel('mae')
ax2.legend()
plt.show()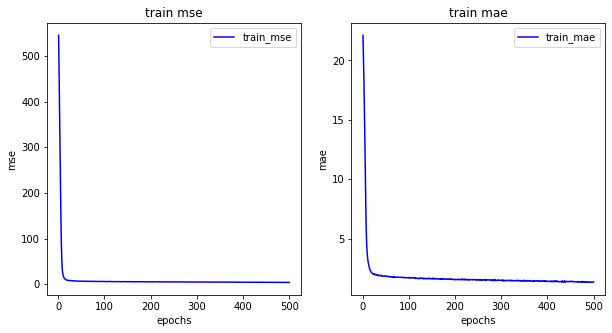
모델 평가하기
loss, mae, mse = model.evaluate(test_dataset, test_labels)
print('테스트셋의 평균 절대 오차 : {:5.2f} MPG'.format(mae))
모델 예측 그리기
test_predictions = model.predict(test_dataset).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])
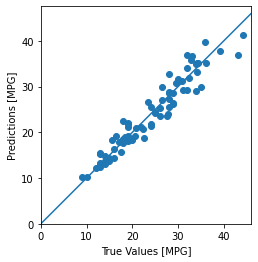
👀
연비가 높아질수록 정확도가 떨어짐
연비가 낮은 모델들은 feature들이 잘 반영됨

배고파용.