함수의 수학적 표현
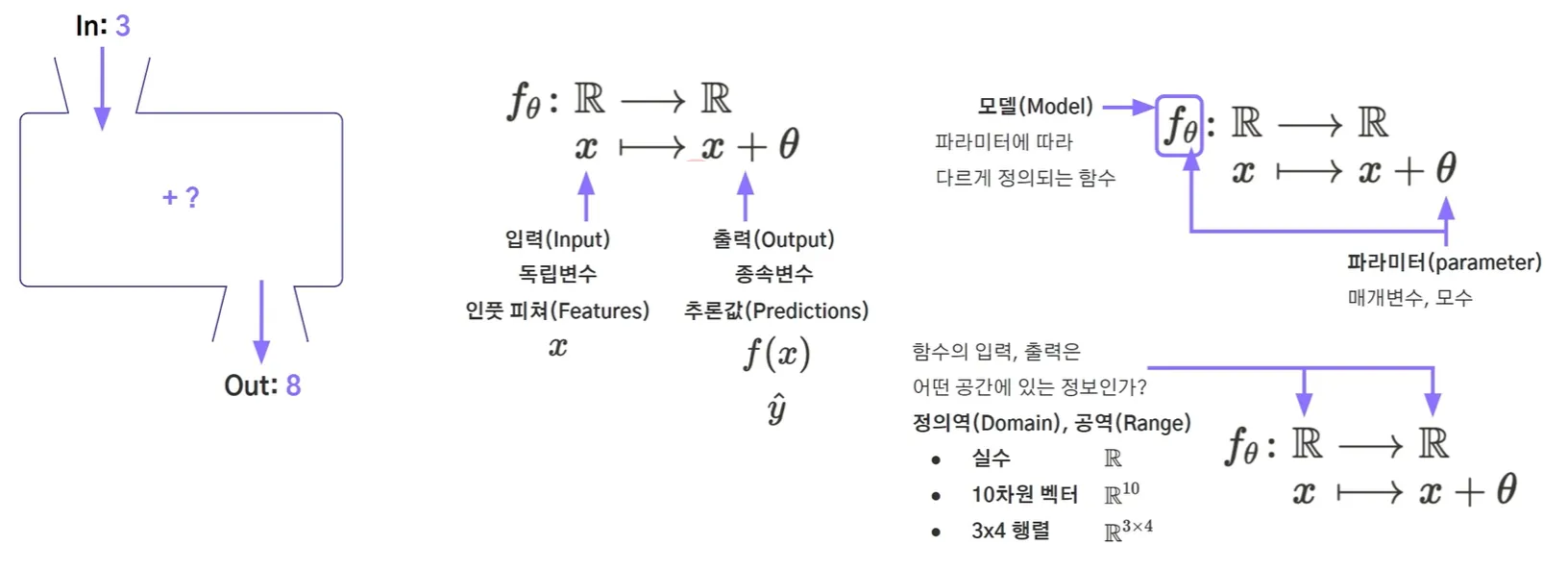
위 사진처럼 수식으로 함수를 수학적으로 표현할 수 있습니다. 추가로 결과는 y, 해당 값을 모델이 예측한 값을 y^(y hat)이라고 부릅니다.
데이터와 모델의 학습
데이터셋
데이터셋(dataset)은 학습을 위한 "입력과 정답"을 모아둔 집합입니다.
보통 하나의 데이터 포인트는
(x, y)형태의 순서쌍으로 표현됩니다.
x: 입력 데이터 (예: 이미지, 텍스트, 센서 값 등)y: 정답 라벨 (예: 고양이/강아지, 긍정/부정, 수치값 등)
데이터셋은 머신러닝 모델이 "경험"을 쌓는 학습 자료이자, 모델의 성능을 검증하는 기준이 됩니다.
Train-Test 데이터셋 분할
- 머신러닝에서는 데이터 전부를 학습에 사용하지 않고, 일부를 테스트용으로 남겨둡니다.
- 이렇게 하는 이유는, 모델이 학습 데이터만 잘 외우는 과적합(overfitting) 문제를 피하고, 새로운 데이터에도 잘 일반화되는지 확인하기 위함입니다.
- 일반적인 분할 비율:
- Train: 70~80% (모델 학습용)
- Validation: 10~15% (하이퍼파라미터 조정 및 조기 종료 판단)
- Test: 10~15% (최종 성능 평가)
예를 들어 이미지 분류 과제를 한다면, 전체 데이터에서 일부 이미지는 절대 학습에 사용하지 않고, 오직 테스트 단계에서만 사용해야 모델의 진짜 실력을 알 수 있습니다.
머신러닝에서 학습의 의미
학습(Learning)이란, 모델이 주어진 데이터에서 규칙을 찾아내는 과정입니다.
좀 더 구체적으로 정리하면:
- 모델(Model) :
- 수학적으로는 입력 → 출력으로 매핑하는 파라미터화된 함수입니다.
- 예: 선형회귀
y = w·x + b→ 파라미터는(w, b).
- 손실 함수(Loss Function) :
- 모델이 예측한 값과 실제 라벨의 차이를 수치로 표현.
- 예: 평균제곱오차(MSE), 교차엔트로피(Cross-Entropy) 등.
- 최적화(Optimization) :
- 손실 함수를 최소화하는 방향으로 파라미터 θ를 업데이트.
- 보통 경사하강법(Gradient Descent) 기반 알고리즘을 사용.
머신러닝 방법론의 차이점
머신러닝의 다양한 방법론들은 주로 다음 요소들에 의해 구분됩니다:
- 모델 구조: 선형 모델, 결정 트리, 신경망 등.
- 파라미터 형태: 가중치 행렬, 트리 분할 규칙, 확률 분포 등.
- 입출력 형태:
- 입력: 벡터, 이미지, 시계열, 그래프
- 출력: 클래스 라벨, 실수 값, 확률 분포 등
- 손실 함수: 문제 유형에 따라 달라짐.
- 분류: 크로스 엔트로피
- 회귀: 평균제곱오차
- 강화학습: 보상 함수 기반 손실
- 데이터 제공 방식:
- 지도학습(Supervised)
- 비지도학습(Unsupervised)
- 준지도학습(Semi-supervised)
- 강화학습(Reinforcement Learning)
머신러닝 시스템의 확장성
Universal Approximation Theorem (보편 근사 정리)
보편 근사 정리란, "적당히 큰 신경망 하나만 있으면 임의의 연속적인 함수도 근사할 수 있다"는 이론입니다.
- 1989년 Cybenko와 Hornik 등이 수학적으로 증명.
- 의미: 신경망이 충분히 크고(층, 뉴런 수) 적절히 학습된다면, 이론적으로는 어떤 복잡한 함수도 표현 가능.
- 하지만 실제로는:
- 네트워크 깊이와 너비에 따른 계산량 한계
- 최적화 어려움 (local minima, gradient vanishing/exploding)
- 데이터 부족 문제
때문에 항상 좋은 결과를 보장하지는 않음.
즉, 신경망은 잠재적으로 무한한 표현 능력을 가지지만, 실제 성능은 데이터와 학습 방법론에 크게 좌우됩니다.
