커널 아카데미 16기
1.[커널아카데미 AI 부트캠프 16기] Git 강의(1)

1) cd : 폴더 이동에 사용이 됩니다.3) touch : 해당 명령어는 파일을 생성하는 명령어 입니다.5) cat : 해당 명령어는 cmd창 내에서 파일을 읽을 수 있게 해주는 명령어 입니다.6) mv : 파일이나 디렉토리를 이동 시킬때 사용하는 명령어입니다. 추
2.[ML Basic] 머신러닝의 정의
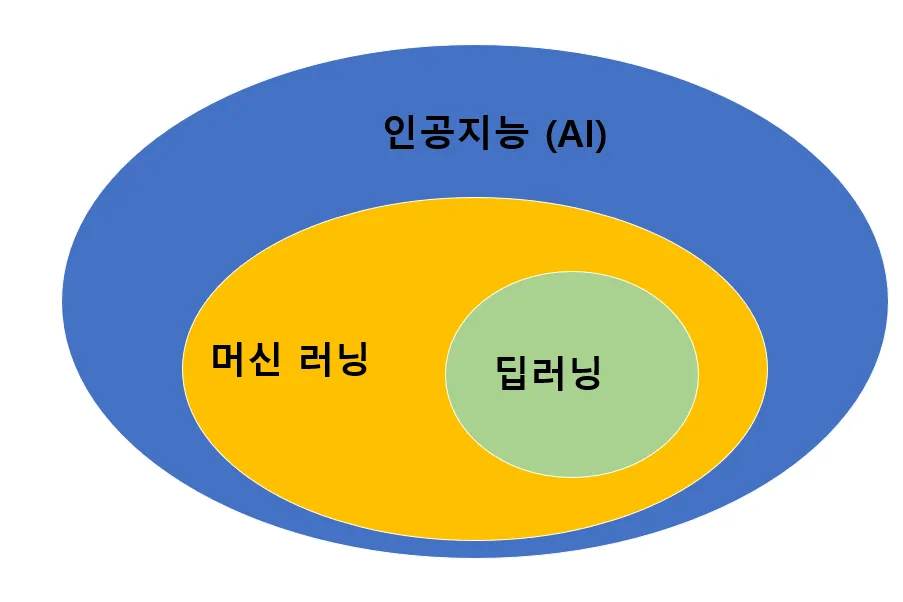
인공지능(AI), 머신러닝(ML), 딥러닝(DL)은 별개의 기술이 아니라 포함 관계에 있습니다.AI : "지능"을 목표로 하는 가장 큰 개념ML : 데이터에서 스스로 규칙을 학습하는 AI의 한 분야DL : 심층 신경망을 이용하는 ML의 세부 분야인공지능(AI)이란 인간
3.[ML Basic] ML 프로젝트의 구성요소
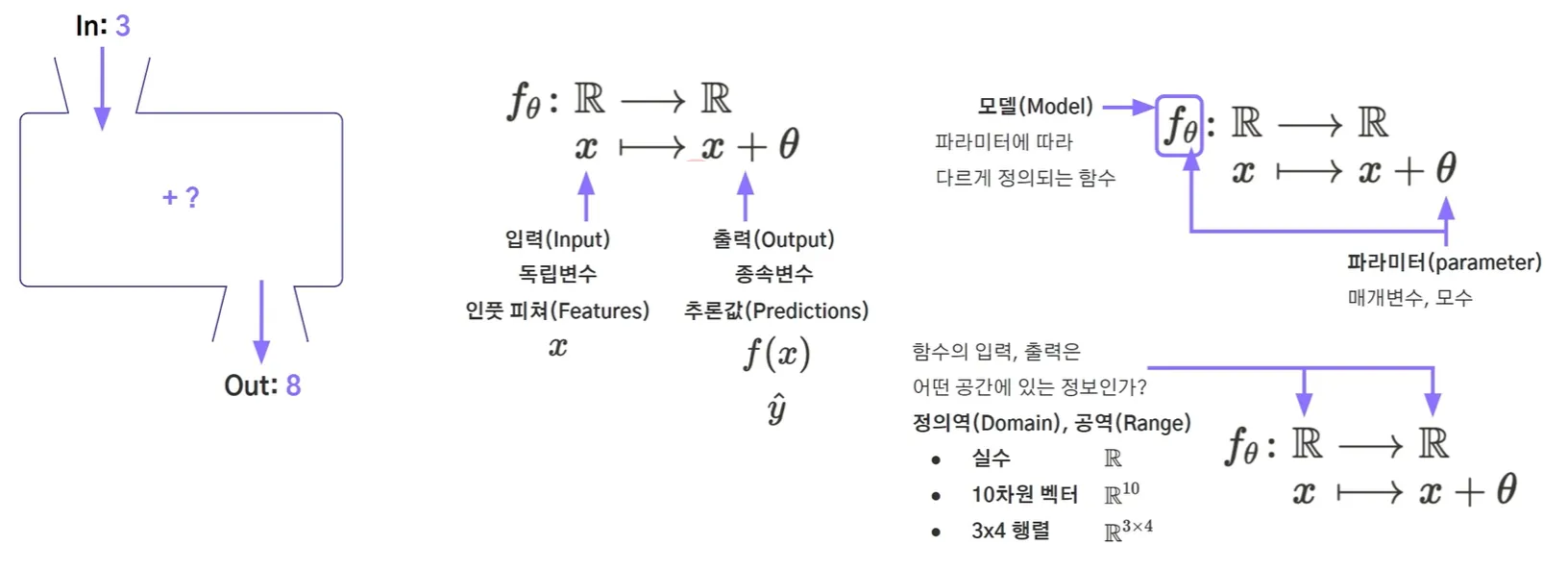
위 사진처럼 수식으로 함수를 수학적으로 표현할 수 있습니다. 추가로 결과는 y, 해당 값을 모델이 예측한 값을 y^(y hat)이라고 부릅니다.데이터셋(dataset)은 학습을 위한 "입력과 정답"을 모아둔 집합입니다.보통 하나의 데이터 포인트는 (x, y) 형태의 순
4.[ML Basic] 데이터의 다양한 형태와 도메인의 구분
머신러닝(Machine Learning, ML) 모델을 만들기 위해서는 데이터를 사람이 이해하는 자연어, 이미지, 소리 형태에서 숫자 형태로 변환해야 합니다. 즉, 모델이 이해할 수 있는 벡터, 행렬, 텐서 형태로 표현하는 과정이 필요합니다.Input (입력): 모델이
5.[ML Basic] 데이터의 품질과 EDA
좋은 데이터란 단순히 많은 양의 데이터가 아니라, 모델이 일반화 가능한 패턴을 학습할 수 있도록 다양한 상황을 반영하고, 노이즈가 적은 데이터입니다.다양한 인풋을 포함하여 모델이 여러 상황에서 학습 가능불필요한 노이즈가 최소화되어 모델 학습을 방해하지 않음예: 소득수준
6.[ML Basic] ML 방법론의 분류
정의: 입력 데이터 x에 대해 사람이 직접 정답 라벨 y를 지정해주는 것.예시:사진(x) → 고양이/강아지(y)환자 데이터(x) → 질병 유무(y)정의: 입력값 x로부터 출력값 y를 예측할 수 있도록 함수 f(x)를 학습하는 방식.목표: 모델의 예측값이 실제 라벨에 가
7.[ML Basic] 회귀 모델의 정의와 개념 소개
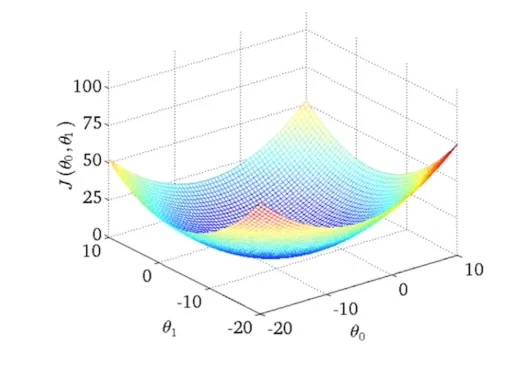
프랜시스 골턴(F.Galton)의 1885년 논문, “Regression toward Mediocrity in Hereditary Stature”(유전에 의한, 평균 신장으로의 회귀)에서 유래한 이름입니다.그런데 사실…이 논문의 제목, 주장은 회귀분석 방법론과는 전혀
8.[ML Basic] 분류 모델의 정의와 개념 소개
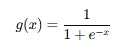
정의: 출력값이 두 가지 클래스(참/거짓, 0/1)로만 나오는 분류 문제.예시질병 검사 (양성/음성)이메일 필터링 (스팸/정상)선형회귀 문제점: 예측값이 0~1 범위를 벗어나 확률 해석 불가능.해결책: 로지스틱 함수(sigmoid)를 적용 → 출력값을 확률로 해석 가능
9.[MLOps] MLOps 개념 정리

머신러닝에서 학습(Learning)이란, 입력(자극, Stimulus)과 출력(반응, Response)의 관계를 데이터로부터 자동으로 찾아내는 과정이다.여기서 내부의 규칙이나 함수는 명시적으로 주어지지 않고, 블랙박스(Blackbox) 모델이 데이터를 통해 스스로 학습
10.[추석 연휴 커널로그 챌린지] 계획 만들기
MLOps 프로젝트를 하면서, 제가 직접했던 부분도 있었지만 제가 하지않고 다른 분들이 했던 부분이 있습니다. 해당 부분에 대한 공부와 자료 정리 및 로컬에서의 테스팅을 진행해볼 생각입니다!연휴 기간 동안 논문 하나를 읽고, 개인적인 리뷰를 남겨볼 생각입니다. AI를
11.[추석 연휴 커널로그 챌린지] MLFlow
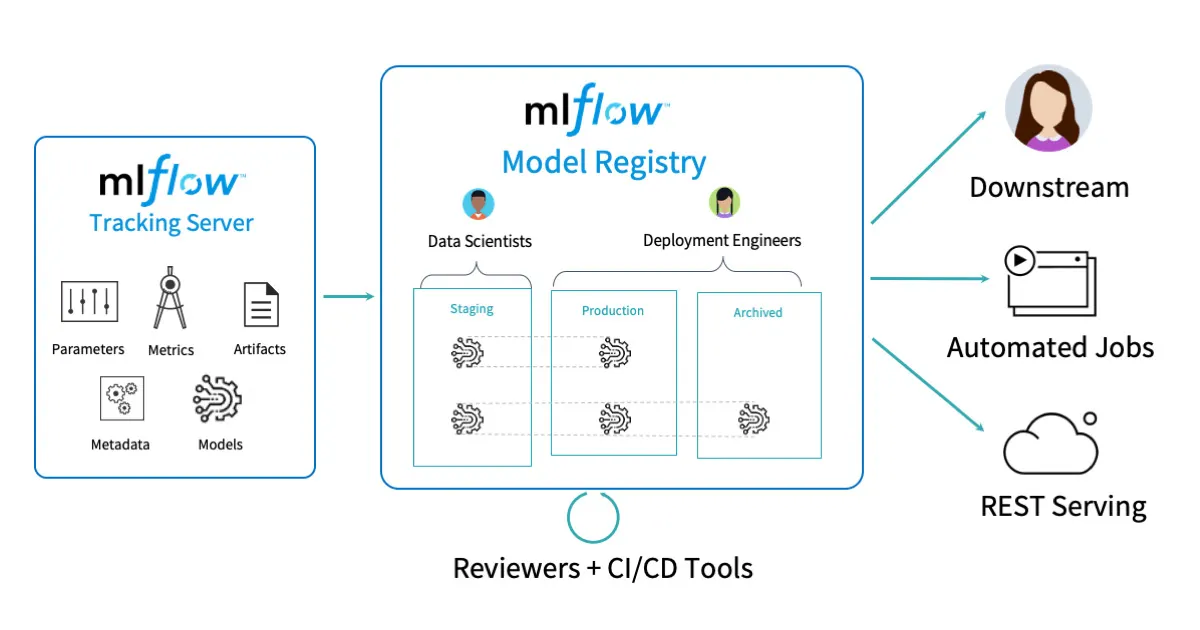
MLflow는 머신러닝(ML) 실험을 관리하고, 모델을 추적·배포할 수 있게 해주는 오픈소스 플랫폼입니다. 머신러닝 프로젝트를 진행할 때 "실험 관리 + 모델 저장 + 배포"를 한 번에 지원하는 도구라고 보면 됩니다.MLflow의 워크플로우는 위 그림과 같습니다.먼저
12.[추석 연휴 커널로그 챌린지] Feast 개념
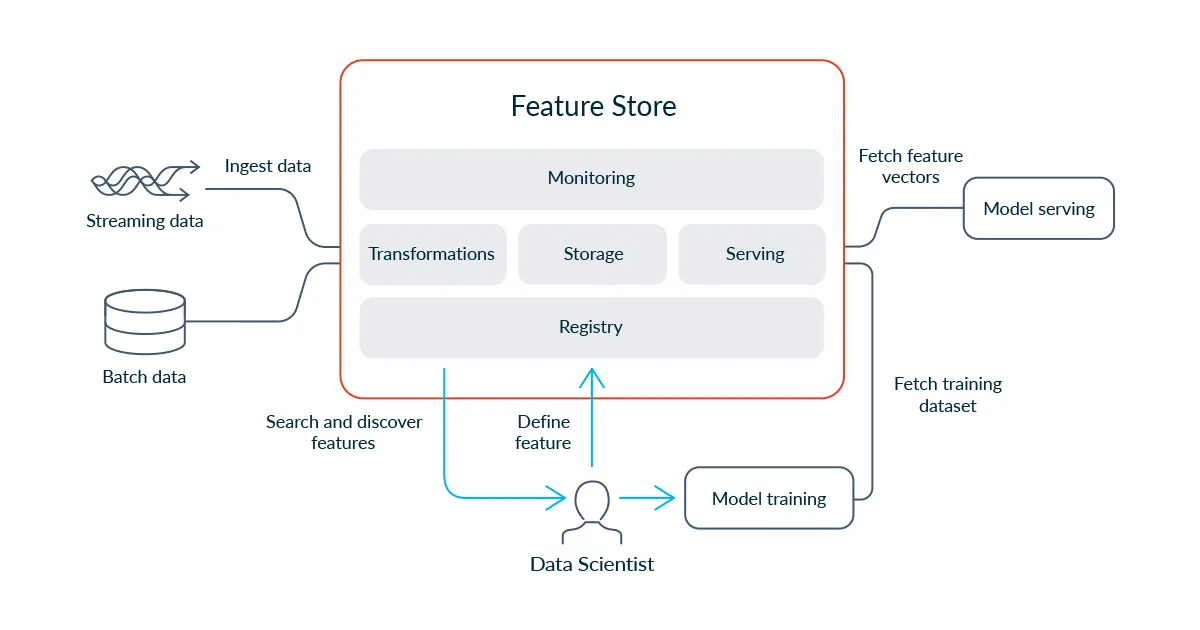
Feature Store는 운영형 머신러닝을 위한 전용 데이터 인프라입니다. 머신러닝 모델과 데이터를 연결하는 인터페이스로, 특징을 생성하고 저장하며 학습과 추론에 일관되게 제공합니다. 이를 통해 training-serving skew 문제를 방지하고, 모델 성능을 안
13.[추석 연휴 커널로그 챌린지] Feast 실습
특성 저장소 만들기피처 정의를 등록하고 피처 스토어를 설정UI 보기Feast 레포의 프로젝트 이름과 설명을 정의합니다.프로젝트 단위로 FeatureView, Entity, FeatureService 등을 관리합니다.엔티티(Entity)는 ML 피처의 주 키(primar
14.[추석 연휴 커널로그 챌린지] Airflow 개요 및 간단 설명

Airflow는 워크플로우(작업 흐름) 관리 도구로, 복잡한 데이터 파이프라인을 스케줄링, 모니터링, 관리할 수 있게 해줍니다. DAG(Directed Acyclic Graph) 형태로 작업 의존성을 정의하여 자동화된 ETL, 데이터 처리, 모델 학습등을 체계적으로 관
15.[추석 연휴 커널로그 챌린지] Parquet에 대해서 알아보자
Parquet은 열(Columnar) 기반의 저장 형식(Columnar Storage Format) 으로,대규모 데이터를 효율적으로 저장하고 분석할 수 있도록 설계된 오픈소스 파일 포맷입니다.Apache Hadoop 생태계에서 주로 사용되며, Apache Arrow 기
16.[추석 연휴 커널로그 챌린지] MLOps 프로젝트 정리
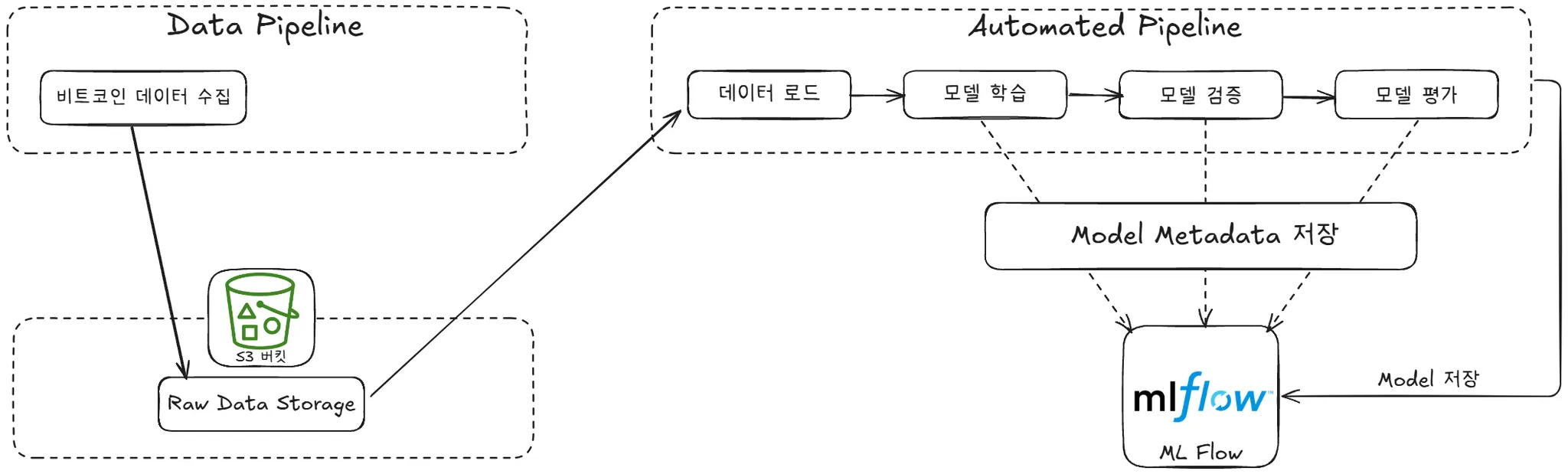
“비트코인 및 주요 코인 1시간 단위 시세 예측 및 실시간 UI 제공 시스템”목표:새로 고침 시간을 기준으로 해당 날의 1시간 단위 시세를 예측코인별 모델을 사용해 가격 변동 차이 고려예측할 코인비트코인(KRW-BTC)도지코인(KRW-DOGE)이더리움(KRW-ETH)리
17.[MLOps 프로젝트] 프로젝트 회고록
목표:새로 고침 시간을 기준으로 해당 날의 1시간 단위 시세를 예측코인별 모델을 사용해 가격 변동 차이 고려예측할 코인비트코인(KRW-BTC)도지코인(KRW-DOGE)이더리움(KRW-ETH)리플(KRW-XRP)예측 결과를 웹 UI에서 직관적으로 확인 가능핵심 포인트단기