📌 이진분류와 다양한 분류 알고리즘 정리
1. 이진분류 (Binary Classification)
- 정의: 출력값이 두 가지 클래스(참/거짓, 0/1)로만 나오는 분류 문제.
- 예시
- 질병 검사 (양성/음성)
- 이메일 필터링 (스팸/정상)
2. 로지스틱 회귀 (Logistic Regression)
(1) 필요성
- 선형회귀 문제점: 예측값이 0~1 범위를 벗어나 확률 해석 불가능.
- 해결책: 로지스틱 함수(sigmoid)를 적용 → 출력값을 확률로 해석 가능.
(2) 로지스틱 함수 (Sigmoid Function)
- 정의
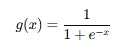
- 특징:
- 입력값 전체 실수 영역
R을 (0,1) 범위로 압축. - 곡선 형태는 "S자형" (Sigmoid).
- 입력값 전체 실수 영역
(3) 로지스틱 회귀 모델
- 기본 형태
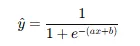
- 출력값
ŷ= 클래스 1일 확률.
(4) 손실 함수: 크로스엔트로피
- Binary Cross Entropy (BCE)
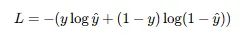
- MSE보다 BCE를 쓰는 이유
- 잘못 예측하면 큰 페널티 부여 (학습 안정화).
- 로지스틱 함수와 결합 시, 미분 결과가 단순해짐 (
ŷ - y).
3. 다중분류 (Multi-class Classification)
(1) 출력값
- 클래스 개수
k→ 출력은 확률 벡터(k차원) - 각 원소는 특정 클래스일 확률.
(2) 원-핫 인코딩 (One Hot Encoding)
- 정답 라벨
y를 0/1로 표시된 벡터로 표현. 예: 클래스=3, 정답=2 →[0, 1, 0].
(3) 소프트맥스 함수 (Softmax)
- 정의
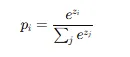
- 특징:
- 확률 분포 벡터 생성.
- 모든 원소 ∈ (0,1), 합=1.
(4) 손실 함수
- Cross Entropy (CE)
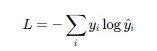
4. 데이터 타입과 문제 정의
- 범주형 변수
- 명목형: 성별, 지역 (순서 없음).
- 순위형: 시험 등급, 만족도 (순서 있음).
- 수치형 변수
- 이산형: 개수, 나이 (정수 단위).
- 연속형: 무게, 가격, 온도 (실수 단위).
👉 이미지 안의 사과 개수 예측은 "이산형 수치" 문제 → 분류보다 회귀 모델링이 더 적합할 수 있음.
5. 다양한 분류 알고리즘
(1) k-최근접 이웃 (kNN)
- 아이디어: 새로운 데이터가 들어오면, 학습 데이터 중 가장 가까운
k개의 라벨을 참고해 다수결로 분류. - 장점: 단순하고 직관적.
- 단점: 데이터 많아지면 계산량↑, 노이즈에 민감.
(2) 결정트리 (Decision Tree)
- 아이디어: "질문-답변"을 통해 데이터 분류 (스무고개 방식).
- 구성: Root node → 내부 노드 → 리프 노드.
- 불순도(Impurity) 지표: 분할 품질 평가.
- 엔트로피, 지니계수(Gini index).
(3) 랜덤 포레스트 (Random Forest)
- 여러 개의 결정트리를 랜덤하게 학습 후 결과를 종합하는 앙상블 기법.
- 장점: 과적합 방지, 안정적인 성능.
(4) 서포트 벡터 머신 (SVM)
- 아이디어: 두 클래스를 구분하는 최적의 결정경계(Hyperplane)를 찾음.
- 목표: 클래스와 경계선 사이의 마진(Margin)을 최대화.
(5) 커널 트릭 (Kernel Trick)
- 선형 분리가 불가능한 데이터를 커널 함수를 이용해 고차원으로 매핑 → 선형 분리 가능하게 변환.
- 대표적 커널: 다항식, RBF (Gaussian).
