“회귀”라는 이름의 기원
대체 무엇이 “회귀”하는가?
프랜시스 골턴(F.Galton)의 1885년 논문, “Regression toward Mediocrity in Hereditary Stature”
(유전에 의한, 평균 신장으로의 회귀)에서 유래한 이름입니다.
그런데 사실…
- 이 논문의 제목, 주장은 회귀분석 방법론과는 전혀 상관이 없습니다.
- 즉, 회귀모델은 그냥 우연히 이름만 이렇게 정해졌을 뿐,
- 분석 과정에서 아무것도 회귀하지 않습니다.
- (..분류처럼 좋은 이름이 아닙니다..)
그러면 회귀모델이란?
입력값이 무엇이든, 출력값이 연속형 변수인 모델을 사용하는 방법론
- 부모의 키 → 자녀의 키
- 오늘의 기온 → 내일의 기온
입력변수는 여러개거나 범주형이라도 상관없습니다.
- 거주지역과 나이, 성별 → 연간 소득 금액
- 특정 회사의 수익관련 지표들 → 1주일 후 주식의 가격
출력변수가 여러개인 경우도 있습니다.
- 사람 얼굴 이미지 → 눈,코,입 위치 좌표
회귀모델링 방법론의 세부 구분
입력번수가 여러개인가?
- 한개인 경우 → 단순 회귀분석
- 여러개인 경우 → 다중 회귀분석
출력변수는 여러개인가?
- 한개인 경우 → (단변량) 회귀분석
- 여러개인 경우 → 다변량 회귀분석
사용하는 모델이 선형 모델인가?
- 선형 회귀분석
- 비선형 회귀분석
다변량, 또는 비선형인 경우는 이 강의에서 다루지 않음
단순 선형 회귀모델
Line Fitting 관점에서의 선형회귀모델
직선의 기울기(a)와 y절편(b)을 조절해 데이터의(점들)와의 오차가 가장 작아지도록 만들기
MSE 손실함수
여기서 오차는 목펴값과 출력값 간 차이의 제곱으로 정의되는, MSE 손싨함수를 사용합니다.
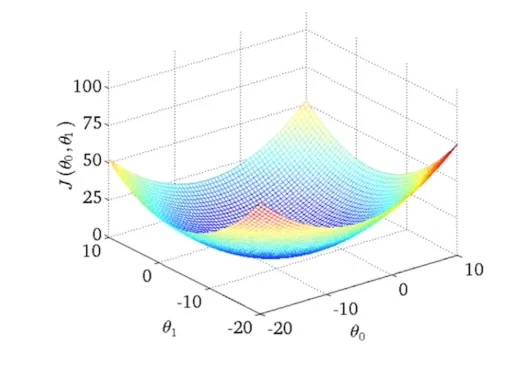
최적화 문제로서의 선형회귀
고정된 X,Y 데이터셋에서 a,b에 따라 손실함수의 값을 그려보면, 아래과 같은 convex함수가 됩니다.
이 관점에서 linear regression은 아래와 같은 손실함수의 argmin(최소값이 되는 a,b)값을 찾는 컨벡스 최족화 문제로 볼 수 있습니다.
최적화 문제의 해를 구하는 방법은 어떤 것들이 있을까?
최적화의 수치적 해법과 해석적 해법
수치적 해법
위와같은 f(x)가 x축과 만나는 지점을 찾는 문제라고 생각해보면,
- 임의의 x값을 출발점 x_0으로 설정
- (x_0, f(x_0))에서 f(x)와 접하는 직선식 찾기
- (2)의 직선식이 x축과 만나는 점을 x_1로 두고,
- 다시 (2), (3) 단계를 계속 반복하면,
x_n값이 f(x) = 0인 점으로 수렴한다는 사실이 증명되어있습니다.
이렇게 점진적으로, 근사적인 해를 찾는 방법을 수치적 해법이라고 합니다.
결과가 근사값으로 나오고, 여러 단계를 거쳐야해 시간이 많이 ㅍ리요한 경우가 많습니다. 대신 좀더 일반적으로, 많은 경우에 사용이 가능합니다.
해석적 해법
데이터 X,y가 다음과 같이 정의되고, MSE 손실함수를 사용하는 다중 선형회귀 분석의 경우,
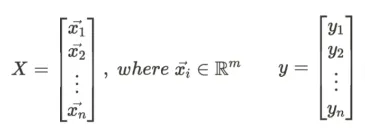
다음과 같은 해석적 해법을 사용해 파라미터 θ를 구할 수 있습니다.
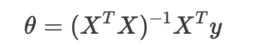
하지만 사실…중간에 들어가는 역행렬 구하는게 어려워서 이 부분만 수치적으로 풀기도 합니다.
직접적으로, 데이터의 값을 입력하는 것만으로 빠르고 간편하게 정확한 값을 구할 수 있지만, 미리 해법이 알려진 경우에만 사용할수 있어 사용 조건이 까다롭거나, 아예 쓸수 없는 경우도 많습니다.
상관분석과 상관계수
상관분석과 상관 계수
상관계수
한 변수가 변화할 때 다른 변수가 함께 변화하는 경향성을 보일 때 두 변수 사이의 관계를 상관관계라고 합니다.
인과관계
한 변수의 변화가 원인이 되어 그 결과로서 다른 변수를 변화시킬 때, 두 변수 사이의 관계를 인과관계라고 합니다.
- 인관관계가 있는 변수가 상관관계도 있지만, 역은 성립하지 않음
- 상관관계의 판단은 쉽지만 인관관계는 그렇지 않음
상관관계 분석
두변수 사이의 상관관계를 판단하기 위한 분석과정
피어슨 상관계수
상관 분석의 결과로, 두 변수 사이에 어느 정도로 강한 선형상관관계가 있는지를 -1에서 1범위의 숫자로 나타낸 것입니다.
상관관계 분석의 가정
선형성
두 변수 사이의 상관관계가 선형적인가? 오른쪽과 같은 데이터는 매우 강한 비선형적 상관관계가 있지만, 단순선형 회귀모델로 분석하면 0에 가까운 상관계수가 나옵니다.
등분산성
모든 입력범수의 범위에 대해 잔차의 분산이 동일해야 한다는 가정.
반의어 : 이분산성
정규분포성
각 변수는 모드 정규분포를 따라야합니다.
- 일반적으로 분석 전에 표준화 방식의 전처리를 진행해줍니다.
독립성
각 샘플들은 모두 독립적으로 추출 되었어야 했습니다.
상관계수 행렬의 시각화
상관행렬
입력 피쳐에 포함된 모든 변수 쌍의 조합에 대한 상관계수를 행렬의 형태로 나타낸 것입니다. 계산 결과는 대칭행렬로 나오지만, 일반적으로 의미가 없는 중복값과 대각선 원소를 제거한 후, 다음과 같은 하삼각행렬의 형태로 시각화 합니다.
- 데이터 탐색 시, 변수간의 상호 연관성을 파악하는데 유용합니다.
공선성과 다중공선성
상관행렬을 시각화했을 때 오른쪽과 같이 몇몇 변수들간의 상관계수가 1.0이나 -1.0으로 나타나는 경우가 있는데, 이런 경우 두 변수 사이에 공선성이 있다고 표현 합니다.
- 한 변수가 서로 다른 단위로 표기되어 데이터셋 내에 중복으로 포함되는 경우
비슷하게 다중공선성은 한 변수가 여러 변수들의 선형결합으로 나타나는
경우를 의미한다.
- 다른 여러 변수들의 평균값이 별도 변수로
데이터셋에 포함되어있는 경우
이러한 경우 공선성, 또는 다중공선성이 나타나지 않을 때까지
변수를 제거하는 방식의 전처리를 진행한다.
상관분석과 선형회귀의 관계
상관계수는 직선의 기울기가 아니다
상관계수는 상관관계의 강도를 나타낸 것이므로, 회귀 직선의 기울기가 변해도, 그 부호가 바뀌지 않는 한 값이 변하지 않습니다.
반면 회귀분석의 결과로 나오는 회귀계수(결정계수)는, 직선의 기울기 값 그 자체를 의미하므로 데이터의 기울기가 변하면 따라서 변화합니다.
참고로, 분석에 사용하는 변수들이 모두 평균 0, 표준편차 1인 표준정규분포를 따르는 경우에는, 상관계수와 회귀계수의 값이 일치하게 됩니다.
